
En esta página se explica cómo funciona el rendimiento aprovisionado, cómo controlar los excesos o evitar el rendimiento aprovisionado y cómo monitorizar el uso.
Cómo funciona la capacidad de procesamiento reservada
En esta sección se explica cómo funciona el throughput aprovisionado mediante la comprobación de cuotas durante el periodo de aplicación de cuotas.
Comprobación de la cuota de capacidad de procesamiento reservada
Tu cuota máxima de rendimiento aprovisionado es un múltiplo del número de unidades de escalado de IA generativa (GSUs) compradas y del rendimiento por GSU. Se comprueba cada vez que haces una solicitud dentro de tu periodo de aplicación de la cuota, que es la frecuencia con la que se aplica la cuota máxima de rendimiento aprovisionado.
En el momento en que se recibe una solicitud, se desconoce el tamaño real de la respuesta. Como priorizamos la velocidad de respuesta de las aplicaciones en tiempo real, el rendimiento aprovisionado estima el tamaño del token de salida. Si la estimación inicial supera la cuota máxima de capacidad de proceso aprovisionada disponible, la solicitud se procesa con la modalidad de pago por uso. De lo contrario, se procesa con la modalidad de capacidad de proceso aprovisionada. Para ello, se compara la estimación inicial con la cuota máxima de capacidad de procesamiento aprovisionada.
Cuando se genera la respuesta y se conoce el tamaño real del token de salida, el uso y la cuota reales se concilian añadiendo la diferencia entre la estimación y el uso real a la cantidad de cuota de capacidad de procesamiento aprovisionada disponible.
Ventanas de aplicación de la cuota de capacidad de procesamiento reservada
Vertex AI aplica una ventana dinámica al aplicar la cuota de rendimiento aprovisionado para los modelos de Gemini. De esta forma, se consigue una estabilidad óptima para el tráfico propenso a picos. En lugar de una ventana fija, Vertex AI aplica la cuota en una ventana flexible que se ajusta automáticamente en función del tipo de modelo y del número de unidades de programación de GPU que hayas aprovisionado. Por lo tanto, en algunos casos, es posible que experimentes temporalmente un tráfico priorizado que supere la cantidad de tu cuota por segundo. Sin embargo, no debes superar tu cuota durante la duración de la ventana. Estos periodos se basan en la hora del reloj interno de Vertex AI y son independientes del momento en que se realicen las solicitudes.
Cómo funciona el periodo de aplicación de la cuota
La ventana de aplicación determina cuánto puedes superar tu límite por segundo antes de que se limite tu velocidad. Esta ventana se aplica automáticamente. Ten en cuenta que estas ventanas están sujetas a cambios para optimizar el rendimiento y la fiabilidad.
Asignaciones pequeñas de GSUs (3 GSUs o menos): el periodo puede oscilar entre 40 y 120 segundos para permitir que se procesen solicitudes individuales más grandes sin interrupciones.
Por ejemplo, si compras 1 unidad de servicio de Google de
gemini-2.5-flash, obtendrás una media de 2690 tokens por segundo de rendimiento continuo. El uso total en cualquier ventana de 120 segundos no puede superar los 322.800 tokens (2690 tokens por segundo * 120 segundos). Por lo tanto, si envías una solicitud que usa 70.000 tokens por segundo, pero el uso total durante 120 segundos sigue siendo inferior a 322.800 tokens, la ráfaga de 70.000 tokens por segundo seguirá contando como rendimiento aprovisionado, ya que el uso medio no supera los 2690 tokens por segundo.Asignaciones de GSU estándar (tamaño medio) (más de 3 GSUs): en las implementaciones de GSU de tamaño medio (por ejemplo, menos de 50 GSUs), el periodo puede oscilar entre 5 y 30 segundos. Los umbrales de GSU y las ventanas de contexto varían en función del modelo.
Por ejemplo, si compras 25 GSUs de
gemini-2.5-flash, obtendrás una media de 67.250 tokens por segundo (2690 tokens por segundo * 25) de rendimiento continuo. El uso total en cualquier periodo de 30 segundos no puede superar los 2.017.500 tokens (67.250 tokens por segundo * 30 segundos). Por lo tanto, si envía una solicitud que usa 1.000.000 tokens por segundo, pero el uso total durante 30 segundos se mantiene dentro de los 2.017.500 tokens, la ráfaga de 1.000.000 tokens por segundo seguirá contando como rendimiento aprovisionado, ya que el uso medio no supera los 67.250 tokens por segundo.Asignaciones de GSU de alta precisión (a gran escala): en las implementaciones de GSU a gran escala (por ejemplo, 50 GSUs o más), el periodo puede oscilar entre 1 y 5 segundos para asegurar que las solicitudes de alta frecuencia se procesen con la máxima precisión en toda la infraestructura.
Por ejemplo, si compras 250 GSUs de
gemini-2.5-flash, obtendrás una media de 672.500 tokens por segundo (2690 tokens por segundo * 250) de rendimiento continuo. El uso total durante cualquier periodo de 5 segundos no puede superar los 3.362.500 tokens (672.500 tokens por segundo * 5 segundos). Por lo tanto, si envías una solicitud que usa 5.000.000 tokens por segundo, no se procesará como rendimiento aprovisionado, ya que el uso total de 5.000.000 tokens supera el límite de 3.362.500 tokens en un periodo de 5 segundos. Por otro lado, una solicitud que use 1.000.000 tokens por segundo se puede procesar como throughput aprovisionado si el uso medio durante el periodo de 5 segundos no supera los 672.500 tokens por segundo.
Controlar los excesos o evitar la capacidad de procesamiento reservada
Usa la API para controlar los excesos cuando superes el rendimiento que has comprado o para omitir el rendimiento aprovisionado por solicitud.
Lee cada opción para determinar qué debes hacer para cumplir tu caso práctico.
Comportamiento predeterminado
Si una solicitud supera la cuota de capacidad de procesamiento aprovisionada restante, se procesará como una solicitud bajo demanda de forma predeterminada y se facturará según la tarifa de pago por uso. Cuando esto ocurre, el tráfico aparece como desbordamiento en los paneles de monitorización. Para obtener más información sobre cómo monitorizar el uso del throughput aprovisionado, consulta Monitorizar el throughput aprovisionado.
Una vez que tu pedido de rendimiento aprovisionado esté activo, el comportamiento predeterminado se aplicará automáticamente. No tienes que cambiar el código para empezar a usar tu pedido, siempre que lo hagas en la región aprovisionada.
Usar solo la capacidad de procesamiento reservada
Si quieres gestionar los costes evitando los cargos bajo demanda, usa solo el throughput aprovisionado. Las solicitudes que superen el importe de pedidos de rendimiento aprovisionado devuelven un error 429.
Al enviar solicitudes a la API, define el encabezado HTTP X-Vertex-AI-LLM-Request-Type en dedicated.
Usar solo la opción de pago por uso
También se conoce como uso bajo demanda. Las solicitudes omiten el orden de la capacidad de procesamiento aprovisionada y se envían directamente al modelo de pago por uso. Esto puede ser útil para experimentos o aplicaciones que estén en fase de desarrollo.
Cuando envíes solicitudes a la API, define el encabezado HTTP X-Vertex-AI-LLM-Request-Type como shared.
Ejemplo
Python
Instalar
pip install --upgrade google-genai
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Consulta cómo instalar o actualizar Go.
Para obtener más información, consulta la documentación de referencia del SDK.
Define variables de entorno para usar el SDK de IA generativa con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Después de configurar tu entorno, puedes usar REST para probar una petición de texto. En el siguiente ejemplo se envía una solicitud al endpoint del modelo del editor.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Usar el throughput aprovisionado con una clave de API
Si has comprado un rendimiento aprovisionado para un proyecto, un modelo de Google y una región específicos, y quieres usarlo para enviar una solicitud con una clave de API, debes incluir el ID del proyecto, el modelo, la ubicación y la clave de API como parámetros en tu solicitud.
Para obtener información sobre cómo crear una Google Cloud clave de API vinculada a una cuenta de servicio, consulta Obtener una clave de API Google Cloud . Para saber cómo enviar solicitudes a la API de Gemini con una clave de API, consulta la guía de inicio rápido de la API de Gemini en Vertex AI.
Por ejemplo, en el siguiente ejemplo se muestra cómo enviar una solicitud con una clave de API mientras se usa el throughput aprovisionado:
REST
Después de configurar tu entorno, puedes usar REST para probar una petición de texto. En el siguiente ejemplo se envía una solicitud al endpoint del modelo del editor.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Monitorizar la capacidad de procesamiento aprovisionada
Puedes monitorizar tu uso de Provisioned Throughput mediante un conjunto de métricas que se miden en el tipo de recurso aiplatform.googleapis.com/PublisherModel.
La monitorización del tráfico de rendimiento aprovisionado es una función de Vista Previa Pública.
Dimensiones
Puede filtrar por métricas mediante las siguientes dimensiones:
| Dimensión | Valores |
|---|---|
type |
inputoutput |
request_type |
|
Prefijo de ruta
El prefijo de ruta de una métrica es aiplatform.googleapis.com/publisher/online_serving.
Por ejemplo, la ruta completa de la métrica /consumed_throughput es aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Métricas
Las siguientes métricas de Cloud Monitoring están disponibles en el recurso aiplatform.googleapis.com/PublisherModel para los modelos de Gemini. Usa los tipos de solicitud dedicated para filtrar el uso de
Provisioned Throughput.
| Métrica | Nombre visible | Descripción |
|---|---|---|
/dedicated_gsu_limit |
Límite (GSU) | Límite específico en las GSUs. Usa esta métrica para conocer tu cuota máxima de rendimiento aprovisionado en GSUs. |
/tokens |
Tokens | Distribución del recuento de tokens de entrada y salida. |
/token_count |
Número de tokens | Recuento acumulado de tokens de entrada y salida. |
/consumed_token_throughput |
Rendimiento de tokens | Uso del rendimiento, que tiene en cuenta la tasa de consumo de tokens e incorpora la conciliación de cuotas. Consulta Comprobación de la cuota de rendimiento aprovisionado. Usa esta métrica para saber cómo se ha usado tu cuota de rendimiento aprovisionado. |
/dedicated_token_limit |
Límite (tokens por segundo) | Límite dedicado en tokens por segundo. Usa esta métrica para conocer la cuota máxima de rendimiento aprovisionado de los modelos basados en tokens. |
/characters |
Caracteres | Distribución del número de caracteres de entrada y salida. |
/character_count |
Número de caracteres | Número acumulado de caracteres de entrada y salida. |
/consumed_throughput |
Rendimiento de caracteres | Uso del rendimiento, que tiene en cuenta la tasa de consumo en caracteres e incorpora la conciliación de cuotas Comprobación de cuotas de rendimiento aprovisionado. Usa esta métrica para saber cómo se ha usado tu cuota de rendimiento aprovisionado. En los modelos basados en tokens, esta métrica equivale al rendimiento consumido en tokens multiplicado por 4. |
/dedicated_character_limit |
Límite (caracteres por segundo) | Límite específico de caracteres por segundo. Usa esta métrica para conocer la cuota máxima de rendimiento aprovisionado de los modelos basados en caracteres. |
/model_invocation_count |
Número de invocaciones del modelo | Número de invocaciones de modelos (solicitudes de predicción). |
/model_invocation_latencies |
Latencias de invocación de modelos | Latencias de invocación del modelo (latencias de predicción). |
/first_token_latencies |
Latencias del primer token | Duración desde que se recibe la solicitud hasta que se devuelve el primer token. |
Los modelos de Anthropic también tienen un filtro para el rendimiento aprovisionado, pero solo para tokens y token_count.
Paneles de control
Los paneles de control de monitorización predeterminados de Provisioned Throughput proporcionan métricas que te permiten comprender mejor tu uso y la utilización de Provisioned Throughput. Para acceder a los paneles, siga estos pasos:
En la Google Cloud consola, ve a la página Rendimiento aprovisionado.
Para ver la utilización del rendimiento aprovisionado de cada modelo en tus pedidos, selecciona la pestaña Resumen de utilización.
En la tabla Utilización del throughput aprovisionado por modelo, puede ver lo siguiente en el periodo seleccionado:
Número total de GSUs que tenías.
Uso del rendimiento máximo en términos de GSUs.
Uso medio de GSU.
Número de veces que has alcanzado el límite de throughput aprovisionado.
Seleccione un modelo de la tabla Utilización del throughput aprovisionado por modelo para ver más métricas específicas del modelo seleccionado.
Cómo interpretar los paneles de control de monitorización
El ajuste de rendimiento aprovisionado comprueba la cuota disponible en tiempo real a nivel de milisegundo para las solicitudes a medida que se realizan, pero compara estos datos con un periodo de aplicación de la cuota continuo, según la hora del reloj interno de Vertex AI. Esta comparación es independiente del momento en que se realicen las solicitudes. Los paneles de control de monitorización muestran las métricas de uso después de que se haya llevado a cabo la conciliación de cuotas. Sin embargo, estas métricas se agregan para proporcionar medias de los periodos de alineación del panel de control en función del intervalo de tiempo seleccionado. La granularidad más baja que admiten los paneles de control de monitorización es a nivel de minuto. Además, la hora de los paneles de control de monitorización es diferente a la de Vertex AI.
Estas diferencias en los tiempos pueden provocar ocasionalmente discrepancias entre los datos de los paneles de monitorización y el rendimiento en tiempo real. Esto puede deberse a cualquiera de los siguientes motivos:
La cuota se aplica en tiempo real, pero los gráficos de monitorización agregan los datos en periodos de alineación de los paneles de control de 1 minuto o más, en función del intervalo de tiempo especificado en los paneles de control de monitorización.
Vertex AI y los paneles de control de monitorización se ejecutan en relojes del sistema diferentes.
Si un pico de tráfico durante un periodo de 1 segundo supera tu cuota de rendimiento aprovisionado, toda la solicitud se procesará como tráfico de desbordamiento. Sin embargo, la utilización general del rendimiento aprovisionado puede parecer baja cuando los datos de monitorización de ese segundo se promedian en el periodo de alineación de 1 minuto, ya que la utilización media en todo el periodo de alineación puede no superar el 100%. Si ve tráfico de desbordamiento, significa que su cuota de rendimiento aprovisionado se utilizó por completo durante el periodo de aplicación de la cuota en el que se hicieron esas solicitudes específicas. Esto ocurre independientemente de la utilización media que se muestre en los paneles de control de monitorización.
Ejemplo de posible discrepancia en los datos de monitorización
En este ejemplo se ilustran algunas de las discrepancias que se producen debido a la desalineación de las ventanas. En la figura 1 se representa el uso del rendimiento durante un periodo específico. En esta figura:
Las barras azules representan el tráfico admitido como Rendimiento aprovisionado.
La barra naranja representa el tráfico que supera el límite de GSU y se procesa como tráfico adicional.
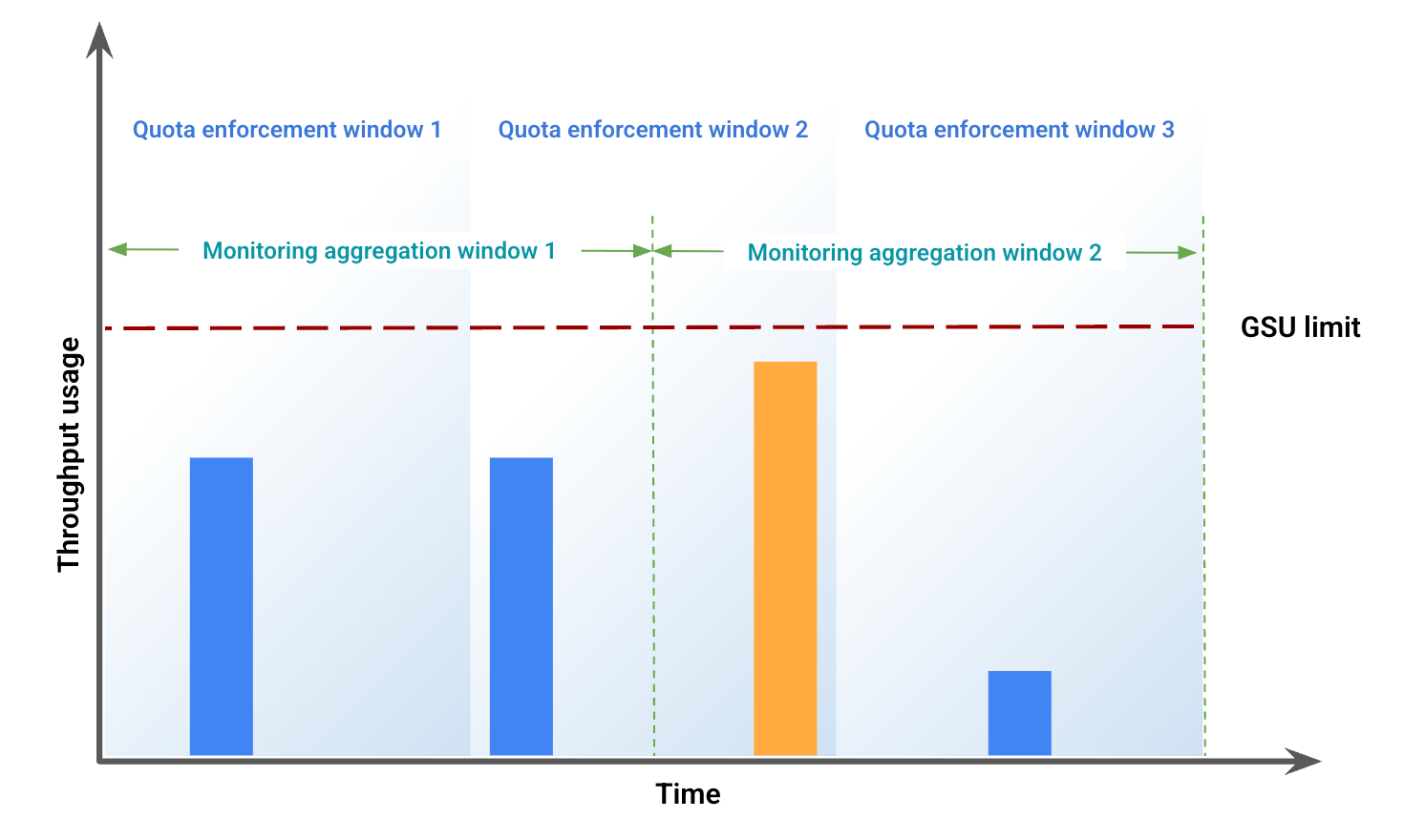
En función del uso del rendimiento, la figura 2 representa posibles discrepancias visuales debido a un desajuste de las ventanas. En esta figura:
La línea azul representa el tráfico de capacidad de procesamiento reservada.
La línea naranja representa el tráfico de cobertura.
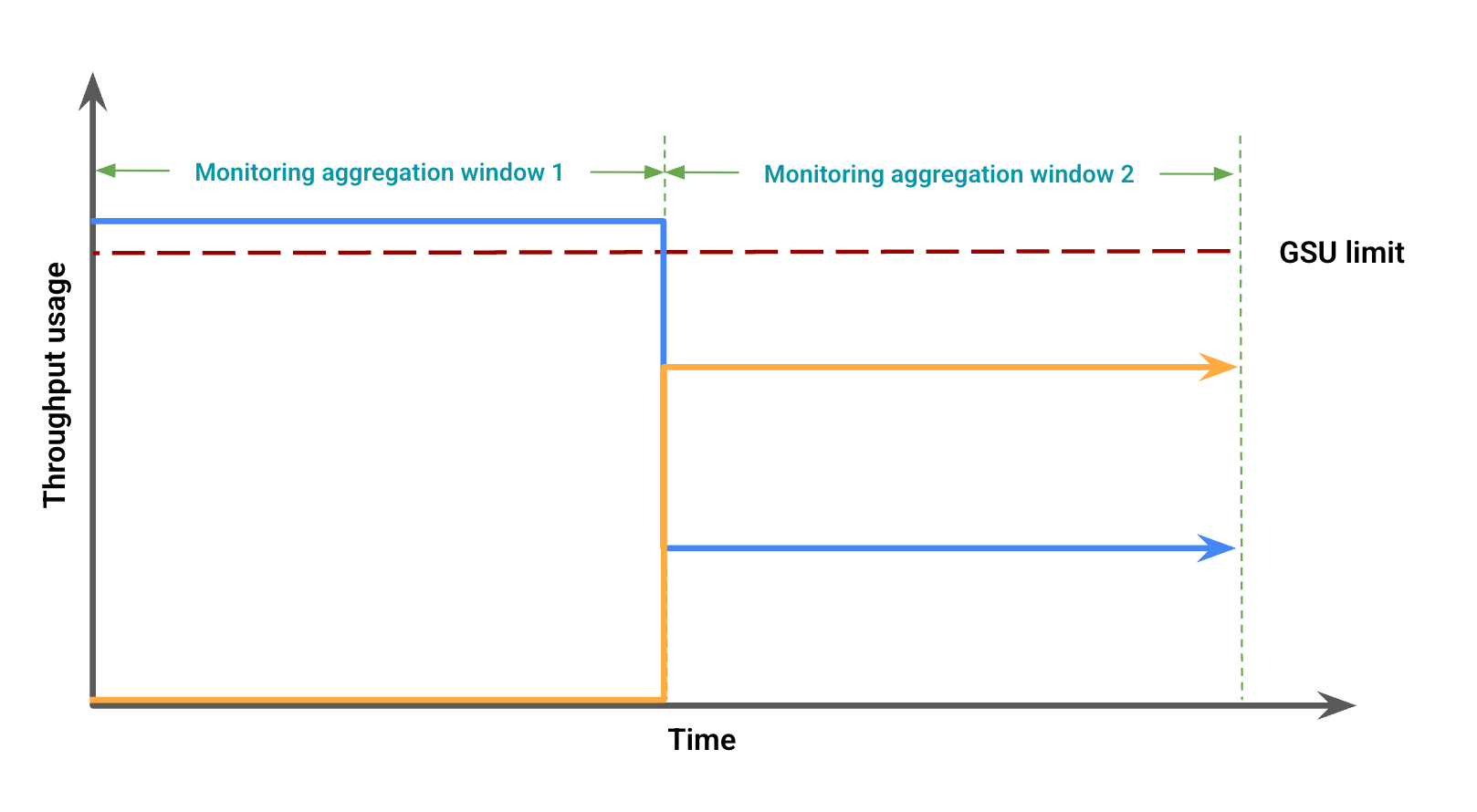
En este caso, los datos de monitorización pueden mostrar el uso del throughput aprovisionado sin desbordamiento en un periodo de agregación de monitorización, mientras que, al mismo tiempo, se observa el uso del throughput aprovisionado por debajo del límite de GSU, lo que coincide con un desbordamiento en otro periodo de agregación de monitorización.
Solucionar problemas de paneles de control de monitorización
Para solucionar problemas de desbordamiento inesperado en tus paneles de control o errores 429, sigue estos pasos:
Acercar: define el intervalo de tiempo del panel de control en 12 horas o menos para obtener el periodo de alineación más granular, que es de 1 minuto. Los intervalos de tiempo grandes suavizan los picos que provocan la limitación y aumentan las medias del periodo de alineación.
Comprueba el tráfico total: en los paneles de control específicos de tu modelo, el tráfico dedicado y el de desbordamiento se muestran en dos líneas independientes, lo que puede llevar a la conclusión incorrecta de que la cuota de capacidad de procesamiento aprovisionada no se utiliza por completo y se desborda prematuramente. Si tu tráfico supera la cuota disponible, toda la solicitud se procesará como excedente. Para obtener otra visualización útil, añade una consulta al panel de control con el explorador de métricas e incluye el rendimiento de tokens del modelo y la región específicos. No incluya ninguna agregación ni filtro adicional para ver el tráfico total de todos los tipos de tráfico (dedicado, de respaldo y compartido).
Monitorizar modelos de Genmedia
La monitorización del rendimiento aprovisionado no está disponible en los modelos Veo 3 e Imagen.
Alertas
Una vez que hayas habilitado las alertas, configura alertas predeterminadas para gestionar tu uso del tráfico.
Habilitar alertas
Para habilitar las alertas en el panel de control, siga estos pasos:
En la Google Cloud consola, ve a la página Rendimiento aprovisionado.
Para ver la utilización del rendimiento aprovisionado de cada modelo en tus pedidos, selecciona la pestaña Resumen de utilización.
Selecciona Alertas recomendadas. Se mostrarán las siguientes alertas:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Consulta las alertas que te ayudan a gestionar el tráfico.
Ver más detalles de la alerta
Para ver más información sobre las alertas, siga estos pasos:
Ve a la página Integraciones.
Introduce vertex en el campo Filtro y pulsa Intro. Google Vertex AI.
Para ver más información, haz clic en Ver detalles. Se muestra el panel Detalles de Google Vertex AI.
Selecciona la pestaña Alertas y, a continuación, una plantilla de Política de alertas.
Siguientes pasos
- Soluciona el problema Error code
429.