

Der Gen AI Evaluation Service bietet Tools auf Unternehmensniveau für eine objektive, datengestützte Bewertung von generativen KI-Modellen. Es unterstützt und informiert über eine Reihe von Entwicklungsaufgaben wie Modellmigrationen, Bearbeitung von Prompts und Feinabstimmung.
Funktionen des Gen AI Evaluation Service
Das entscheidende Merkmal des Gen AI Evaluation Service ist die Möglichkeit, adaptive Bewertungsschemas zu verwenden. Das sind maßgeschneiderte Tests, die für jeden einzelnen Prompt bestehen oder nicht bestehen. Bewertungsschemas ähneln Unittests in der Softwareentwicklung und zielen darauf ab, die Modellleistung bei einer Vielzahl von Aufgaben zu verbessern.
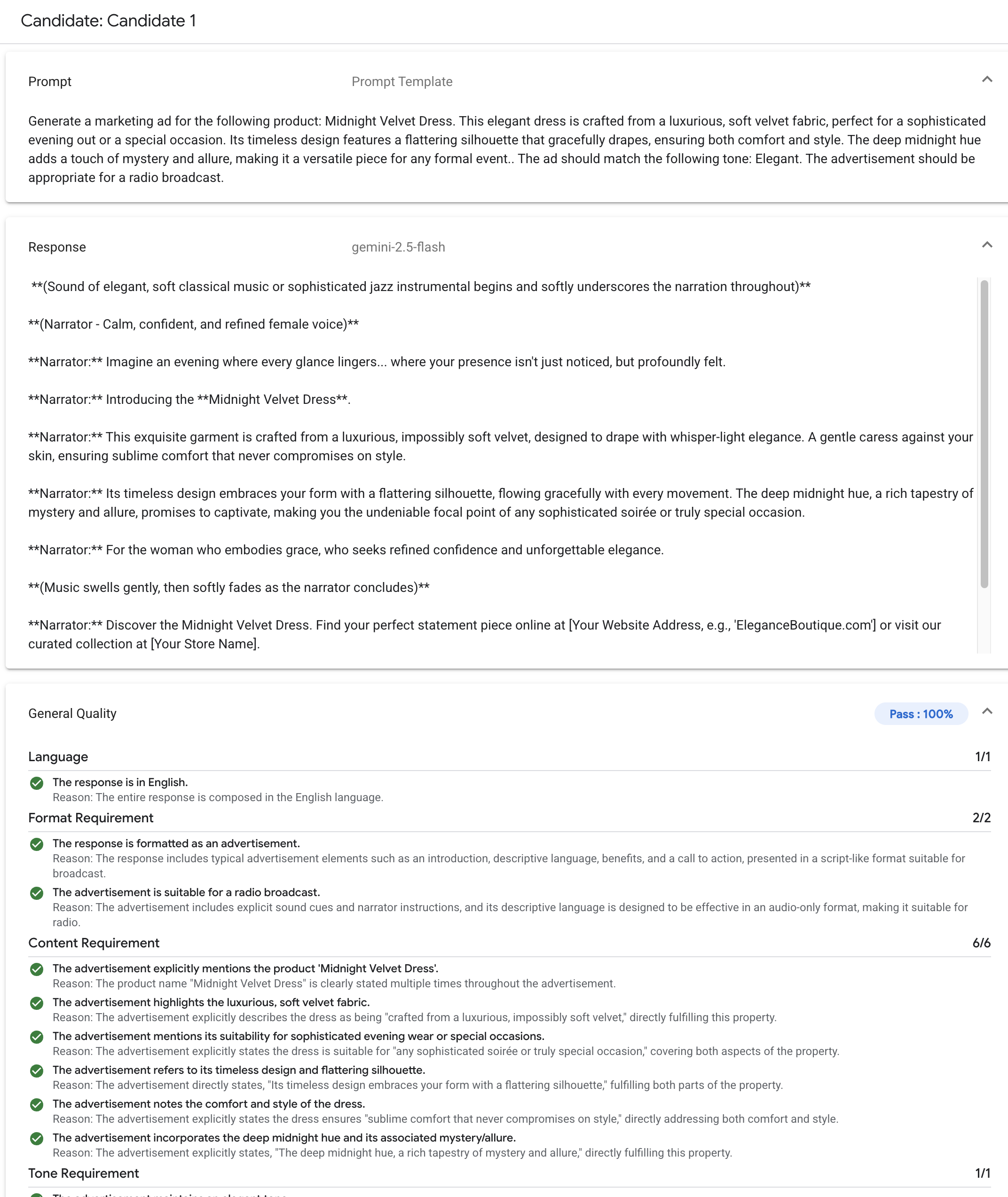
Der Gen AI Evaluation Service unterstützt die folgenden gängigen Bewertungsmethoden:
Adaptive Rubriken (empfohlen): Generiert für jeden einzelnen Prompt in Ihrem Dataset einen eindeutigen Satz von Rubriken für „Bestanden“ oder „Nicht bestanden“.
Statische Rubriken: Wenden Sie für alle Prompts einen festen Satz von Bewertungskriterien an.
Berechnungsbasierte Messwerte: Verwenden Sie deterministische Algorithmen wie
ROUGEoderBLEU, wenn eine Grundwahrheit verfügbar ist.Benutzerdefinierte Funktionen: Definieren Sie Ihre eigene Auswertungslogik in Python für spezielle Anforderungen.
Generierung von Bewertungs-Datasets
Sie haben folgende Möglichkeiten, ein Bewertungs-Dataset zu erstellen:
Laden Sie eine Datei mit vollständigen Prompt-Instanzen hoch oder stellen Sie eine Prompt-Vorlage zusammen mit einer entsprechenden Datei mit Variablenwerten bereit, um die vollständigen Prompts zu generieren.
Direkt aus Produktionslogs Stichproben ziehen, um die tatsächliche Nutzung Ihres Modells zu bewerten.
Synthetische Daten generieren, um eine große Anzahl konsistenter Beispiele für eine beliebige Promptvorlage zu erstellen.
Unterstützte Schnittstellen
Sie können Ihre Tests über die folgenden Schnittstellen definieren und ausführen:
Google Cloud -Konsole: Eine Webbenutzeroberfläche mit einem geführten End-to-End-Workflow. Datasets verwalten, Auswertungen durchführen und interaktive Berichte und Visualisierungen analysieren Weitere Informationen finden Sie unter Bewertung mit der Console durchführen.
Python SDK: Sie können Bewertungen programmatisch ausführen und nebeneinanderliegende Modellvergleiche direkt in Ihrer Colab- oder Jupyter-Umgebung rendern. Weitere Informationen finden Sie unter Bewertung mit dem GenAI-Client im Agent Platform SDK durchführen.
Anwendungsfälle
Mit dem Gen AI Evaluation Service können Sie sehen, wie ein Modell bei Ihren spezifischen Aufgaben und anhand Ihrer eigenen Kriterien abschneidet. So erhalten Sie wertvolle Informationen, die nicht aus öffentlichen Bestenlisten und allgemeinen Benchmarks abgeleitet werden können. Dies unterstützt wichtige Entwicklungsaufgaben, darunter:
Modellmigrationen: Vergleichen Sie Modellversionen, um Verhaltensunterschiede zu erkennen und Ihre Prompts und Einstellungen entsprechend anzupassen.
Bestes Modell finden: Führen Sie direkte Vergleiche von Google- und Drittanbietermodellen mit Ihren Daten durch, um eine Leistungs-Baseline zu erstellen und das beste Modell für Ihren Anwendungsfall zu ermitteln.
Prompt-Verbesserung: Nutzen Sie die Auswertungsergebnisse, um Ihre Anpassungsbemühungen zu steuern. Wenn Sie eine Auswertung noch einmal ausführen, entsteht eine enge Feedback-Schleife, die sofortiges, quantifizierbares Feedback zu Ihren Änderungen liefert.
Modelloptimierung: Bewerten Sie die Qualität eines optimierten Modells, indem Sie bei jedem Lauf konsistente Bewertungskriterien anwenden.
Agentenbewertung: Bewerten Sie die Leistung eines Agenten anhand von agentspezifischen Messwerten wie Agenten-Traces und Antwortqualität.
Bewertungs-Workflow
Für die Durchführung einer Bewertung sind in der Regel die folgenden Schritte erforderlich:
Bewertungs-Dataset erstellen: Stellen Sie ein Dataset mit Prompt-Instanzen zusammen, die Ihren spezifischen Anwendungsfall widerspiegeln. Wenn Sie berechnungsbasierte Messwerte verwenden möchten, können Sie Referenzantworten (Ground Truth) einfügen.
Bewertungsmesswerte definieren: Wählen Sie die Messwerte aus, mit denen Sie die Modellleistung messen möchten.
Modellantworten generieren: Wählen Sie ein oder mehrere Modelle aus, um Antworten für Ihr Dataset zu generieren. Das Agent Platform SDK unterstützt alle Modelle, die über
LiteLLMaufgerufen werden können, während die Console Google Gemini-Modelle unterstützt.Bewertung ausführen: Führen Sie den Bewertungsjob aus, bei dem die Antworten der einzelnen Modelle anhand der von Ihnen ausgewählten Messwerte bewertet werden.
Ergebnisse interpretieren: Sehen Sie sich die aggregierten Werte und einzelnen Antworten an, um die Modellleistung zu analysieren.
Bewertungsmesswerte
Im Folgenden finden Sie die wichtigsten Konzepte im Zusammenhang mit Bewertungsmetriken:
Rubriken: Die Kriterien für die Bewertung der Antwort eines LLM-Modells oder einer Anwendung.
Messwerte: Eine Punktzahl, mit der die Modellausgabe anhand der Bewertungskriterien gemessen wird.
Der Gen AI Evaluation Service bietet die folgenden Kategorien von Messwerten:
Auf Bewertungsschemas basierte Messwerte: Binden LLMs in Bewertungs-Workflows ein, um die Qualität der Antworten von Modellen zu bewerten. Rubrikbasierte Bewertungen eignen sich für eine Vielzahl von Aufgaben, insbesondere für die Bewertung von Schreibqualität, Sicherheit und Befolgung von Anweisungen, die oft schwer mit deterministischen Algorithmen zu bewerten sind.
Adaptive Bewertungsschemas (empfohlen): Bewertungsschemas werden für jede Eingabeaufforderung dynamisch generiert, ähnlich wie Unittests. Antworten werden mit einer Reihe von Tests bewertet, die für jeden einzelnen Prompt in Ihrem Dataset eindeutig sind. Die Bewertungsschemas sorgen dafür, dass die Bewertung für die angeforderte Aufgabe relevant ist, und zielen darauf ab, objektive, erklärbare und konsistente Ergebnisse zu liefern.
Adaptive Rubriken sind in der Regel die schnellste Möglichkeit, mit der Bewertung zu beginnen. Sie sorgen dafür, dass jede Bewertung für die jeweilige Aufgabe relevant ist.
Statische Rubriken: Rubriken werden explizit definiert und dieselbe Rubrik wird auf alle Prompts angewendet. Antworten werden mit denselben numerischen, auf Punktzahlen basierenden Evaluatoren bewertet. Eine einzelne numerische Bewertung (z. B. 1–5) pro Prompt. Verwenden Sie statische Bewertungsschemata, wenn eine Bewertung für eine sehr spezifische Dimension erforderlich ist oder wenn für alle Prompts genau dasselbe Bewertungsschema erforderlich ist.
Berechnungsbasierte Messwerte: Antworten werden mit deterministischen Algorithmen bewertet, in der Regel anhand von Ground Truth. Eine numerische Punktzahl (z.B.0,0–1,0) pro Prompt. Wenn eine Ground Truth verfügbar ist und mit einer deterministischen Methode abgeglichen werden kann.
Benutzerdefinierte Funktionsmesswerte (nur Agent Platform SDK): Definieren Sie Ihren eigenen Messwert über eine Python-Funktion.
Beispiel für ein adaptives Bewertungsschema
Der Bewertungsprozess für jeden Prompt umfasst zwei Schritte:
Rubrik-Generierung: Der Dienst analysiert zuerst Ihren Prompt und generiert eine Liste mit spezifischen, überprüfbaren Tests – den Rubriken –, die eine gute Antwort erfüllen sollte.
Rubric-Validierung: Nachdem Ihr Modell eine Antwort generiert hat, bewertet der Dienst die Antwort anhand der einzelnen Rubrics und liefert ein klares
Pass- oderFail-Ergebnis sowie eine Begründung.
Das Endergebnis ist eine aggregierte Bestehensrate und eine detaillierte Aufschlüsselung der Rubriken, die das Modell bestanden hat. So erhalten Sie umsetzbare Informationen, um Probleme zu diagnostizieren und Verbesserungen zu messen.
Wenn Sie von allgemeinen, subjektiven Bewertungen zu detaillierten, objektiven Testergebnissen wechseln, können Sie einen bewertungsgesteuerten Entwicklungszyklus einführen und die Best Practices für Softwareentwicklung in den Prozess der Entwicklung von Anwendungen mit generativer KI einbringen.
Das folgende Beispiel zeigt adaptive Rubriken, die für eine Reihe von Prompts generiert wurden:
Nutzer-Prompt: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Für diesen Prompt könnten im Schritt Bewertungsschema generieren die folgenden Bewertungsschemas erstellt werden:
Bewertungsschema 1: Die Antwort ist eine Zusammenfassung des bereitgestellten Artikels.
Bewertungsschema 2: Die Antwort enthält genau vier Sätze.
Bewertungsschema 3: Die Antwort ist optimistisch formuliert.
Ihr Modell gibt möglicherweise die folgende Antwort aus: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Bei der Rubrikvalidierung wird die Antwort vom Gen AI Evaluation Service anhand jeder Rubrik bewertet:
Bewertungsschema 1: Die Antwort ist eine Zusammenfassung des bereitgestellten Artikels.
Urteil:
PassGrund: In der Antwort werden die wichtigsten Punkte korrekt zusammengefasst.
Bewertungsschema 2: Die Antwort enthält genau vier Sätze.
Urteil:
PassGrund: Die Antwort besteht aus vier verschiedenen Sätzen.
Bewertungsschema 3: Die Antwort ist optimistisch formuliert.
Urteil:
FailGrund: Im letzten Satz wird ein negativer Punkt eingeführt, der den optimistischen Ton beeinträchtigt.
Die endgültige Bestehensrate für diese Antwort beträgt 66,7%. Um zwei Modelle zu vergleichen, können Sie ihre Antworten anhand derselben Gruppe generierter Tests bewerten und ihre allgemeinen Bestehensraten vergleichen.
Erste Schritte mit Bewertungen
Erste Schritte mit der Console
Alternativ können Sie die Bewertung auch mit dem GenAI-Client im Agent Platform SDK durchführen. Der entsprechende Code ist unten zu sehen:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Agent Platform",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Der Gen AI Evaluation Service bietet zwei Agent Platform SDK-Schnittstellen:
GenAI-Client im Agent Platform SDK (empfohlen) (Vorabversion)
from vertexai import clientDer GenAI-Client ist die neuere, empfohlene Schnittstelle für die Bewertung, auf die über die einheitliche Client-Klasse zugegriffen wird. Es unterstützt alle Bewertungsmethoden und ist für Workflows konzipiert, die Modellvergleich, Visualisierung im Notebook und Statistiken für die Modellanpassung umfassen.
Bewertungsmodul im Agent Platform SDK (GA)
from vertexai.evaluation import EvalTaskDas Bewertungsmodul ist die ältere Schnittstelle, die zur Abwärtskompatibilität mit bestehenden Arbeitsabläufen beibehalten wird, aber nicht mehr aktiv weiterentwickelt wird. Der Zugriff erfolgt über die Klasse
EvalTask. Diese Methode unterstützt standardmäßige LLM-as-a-Judge- und rechenbasierte Messwerte, aber keine neueren Bewertungsmethoden wie adaptive Rubriken.
Unterstützte Regionen
Der Gen AI Evaluation Service wird in den folgenden Regionen unterstützt:
Iowa (
us-central1)South Carolina (
us-east1)Virginia (
us-east4)Columbus, Ohio-
us-east5Dallas, Texas (
us-south1)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Warschau, Polen (
europe-central2)Finnland (
europe-north1)Madrid, Spanien (
europe-southwest1)Belgien (
europe-west1)Niederlande (
europe-west4)Mailand, Italien (
europe-west8)Paris, Frankreich (
europe-west9)Landesweit (
global)
Verfügbare Notebooks
| Notebook-Links | Beschreibung |
|---|---|
| Erste Schritte: Schnelle Bewertung generativer KI | Bietet eine Einführung in den Gen AI Evaluation Service. |
| Drittanbietermodelle mit dem Gen AI Evaluation Service bewerten | Hier wird gezeigt, wie Sie mit dem **Agent Platform SDK** verschiedene Arten von Drittanbietermodellen bewerten, darunter Modelle, auf die über die API zugegriffen wird (z. B. OpenAI, Anthropic), Model as a Service (MaaS) aus dem Vertex Model Garden und Bring Your Own Model (BYOM)-Endpunkte. |
| Modellmigration mit dem Gen AI Evaluation Service | Hier wird gezeigt, wie Sie das **Agent Platform SDK** für den Gen AI Evaluation Service verwenden, um zwei eigene Modelle (z. B. Gemini 2.0 Flash und Gemini 2.5 Flash) zu vergleichen. Es wird erläutert, wie Sie vordefinierte adaptive rubric-basierte Messwerte verwenden und wie die Bewertungsergebnisse zur Optimierung von Prompts beitragen können. Wichtige Funktionen wie die Bewertung mehrerer Kandidaten, die Visualisierung im Notebook und die asynchrone Batchbewertung werden ebenfalls behandelt. |
| Bewerten der Text-zu-Bild-Qualität mit dem Gen AI Evaluation Service | Hier wird gezeigt, wie Sie mit dem Vertex AI SDK für den Gen AI Evaluation Service die Qualität generierter Bilder anhand von Textprompts bewerten. Darin wird die Verwendung des vordefinierten adaptiven rubric-basierten Gecko-Messwerts demonstriert. |
| Bewerten der Text-zu-Video-Qualität mit dem Gen AI Evaluation Service | Hier wird gezeigt, wie Sie das **Agent Platform SDK** für den Gen AI Evaluation Service verwenden, um die Qualität generierter Videos anhand von Textprompts zu bewerten. Darin wird die Verwendung des vordefinierten adaptiven rubric-basierten Gecko-Messwerts demonstriert. |