
ארכיטקטורת TPU
יחידות לעיבוד טנסורים (TPU) הן מעגלים משולבים לאפליקציות ספציפיות (ASIC) שפותחו על ידי Google כדי להאיץ עומסי עבודה של למידת מכונה. אפשר להשתמש ב-TPU דרך Compute Engine, Google Kubernetes Engine ו-Vertex AI.
ה-TPU מיועדים לביצוע מהיר של פעולות מטריצה, ולכן הם אידיאליים לעומסי עבודה של למידת מכונה. אתם יכולים להריץ עומסי עבודה של למידת מכונה ב-TPU באמצעות מסגרות כמו PyTorch ו-JAX.
איך מעבדי TPU פועלים?
כדי להבין איך יחידות TPU פועלות, כדאי להבין איך מאיצים אחרים מתמודדים עם האתגרים החישוביים של אימון מודלים של ML.
איך מעבד עובד
מעבד הוא מעבד למטרות כלליות שמבוסס על ארכיטקטורת פון נוימן. כלומר, מעבד (CPU) עובד עם תוכנה וזיכרון באופן הבא:
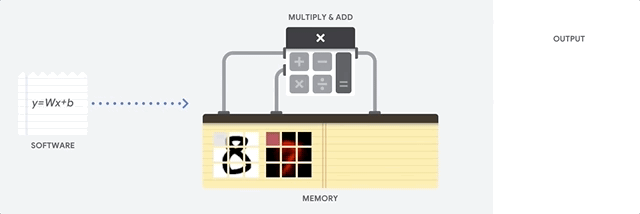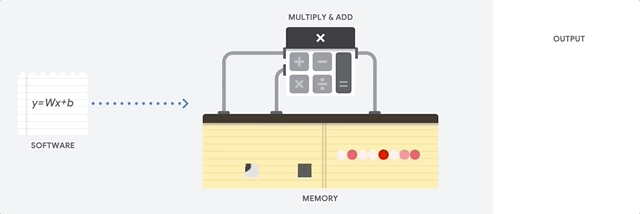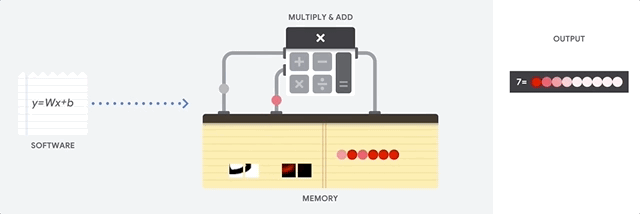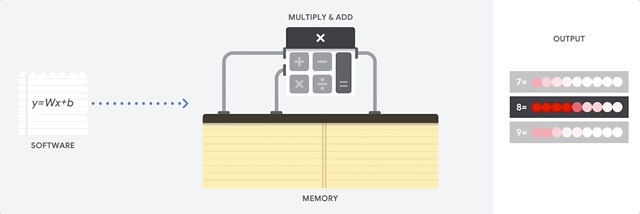
היתרון הכי גדול של מעבדים הוא הגמישות שלהם. אפשר לטעון כל סוג של תוכנה במעבד למגוון רחב של סוגי אפליקציות. לדוגמה, אפשר להשתמש במעבד כדי לעבד מילים במחשב, לשלוט במנועי רקטות, לבצע עסקאות בנקאיות או לסווג תמונות באמצעות רשת נוירונים.
מעבד טוען ערכים מהזיכרון, מבצע חישוב על הערכים ומאחסן את התוצאה בחזרה בזיכרון לכל חישוב. הגישה לזיכרון איטית בהשוואה למהירות החישוב, ויכולה להגביל את התפוקה הכוללת של המעבדים. הבעיה הזו נקראת לעיתים קרובות צוואר הבקבוק של פון נוימן.
איך GPU עובד
כדי להשיג תפוקה גבוהה יותר, מעבדי GPU מכילים אלפי יחידות לוגיות אריתמטיות (ALU) במעבד אחד. בדרך כלל, מעבד GPU מודרני מכיל בין 2,500 ל-5,000 יחידות ALU. מספר המעבדים הגדול מאפשר לבצע אלפי פעולות כפל וחיבור בו-זמנית.

ארכיטקטורת ה-GPU הזו מתאימה לאפליקציות עם מקביליות מסיבית, כמו פעולות מטריצה ברשת נוירונים. למעשה, בעומס עבודה אופייני של אימון ללמידה עמוקה, ה-GPU יכול לספק תפוקה גבוהה יותר מסדר גודל של CPU.
אבל ה-GPU הוא עדיין מעבד למטרות כלליות שצריך לתמוך בהרבה אפליקציות ותוכנות שונות. לכן, ל-GPU יש את אותה בעיה כמו ל-CPU. לכל חישוב באלפי יחידות ALU, יחידת GPU צריכה לגשת לאוגרים או לזיכרון משותף כדי לקרוא אופרנדים ולאחסן את תוצאות החישוב הביניים.
איך TPU עובד
Google תכננה את Cloud TPUs כמעבד מטריצות שמתמחה בעומסי עבודה של רשתות עצביות. אי אפשר להשתמש ב-TPU כדי להריץ מעבדי תמלילים, לשלוט במנועי רקטות או לבצע עסקאות בנקאיות, אבל אפשר להשתמש בהם כדי לבצע במהירות פעולות מטריצה מסיביות שמשמשות ברשתות עצביות.
המשימה העיקרית של יחידות TPU היא עיבוד מטריצות, שכולל שילוב של פעולות הכפלה וצבירה. יחידות TPU מכילות אלפי יחידות של מכפילים מצטברים שמחוברות ישירות זו לזו ויוצרות מטריצה פיזית גדולה. הארכיטקטורה הזו נקראת מערך סיסטולי. Cloud TPU v3, מכיל שני מערכים סיסטוליים של 128 x 128 יחידות ALU, במעבד יחיד.
מארח ה-TPU מעביר נתונים בסטרימינג לתור של נתונים נכנסים. ה-TPU טוען נתונים מתור ה-infeed ומאחסן אותם בזיכרון עם רוחב פס גבוה (HBM). כשהחישוב מסתיים, ה-TPU טוען את התוצאות לתור של ה-outfeed. לאחר מכן, מארח ה-TPU קורא את התוצאות מתור הנתונים היוצאים ומאחסן אותן בזיכרון של המארח.
כדי לבצע את פעולות המטריצה, ה-TPU טוען את הפרמטרים מ-HBM אל Matrix Multiplication Unit (MXU).

לאחר מכן, ה-TPU טוען נתונים מ-HBM. בזמן הביצוע של כל פעולת כפל, התוצאה מועברת אל יחידת הכפל והצבירה הבאה. הפלט הוא סכום כל תוצאות הכפל בין הנתונים לפרמטרים. אין צורך בגישה לזיכרון במהלך תהליך הכפל של המטריצה.
כתוצאה מכך, יחידות TPU יכולות להשיג תפוקת מחשוב גבוהה בחישובים של רשתות נוירונים.
ארכיטקטורת מערכת TPU
בקטעים הבאים מוסברים המושגים המרכזיים של מערכת TPU. מידע נוסף על מונחים נפוצים בתחום למידת המכונה זמין במילון המונחים של למידת המכונה.
אם אתם חדשים ב-Cloud TPU, כדאי לעיין בדף הבית של התיעוד בנושא TPU.
שבב TPU
שבב TPU מכיל ליבת Tensor אחת או יותר. מספר ליבות ה-Tensor תלוי בגרסה של שבב ה-TPU. כל TensorCore מורכב מיחידה אחת או יותר של כפל מטריצות (MXU), יחידת וקטור ויחידה סקלרית. מידע נוסף על TensorCores זמין במאמר A Domain-Specific Supercomputer for Training Deep Neural Networks.
יחידת MXU מורכבת מ-256 x 256 (TPU v6e ו-TPU7x) או מ-128 x 128 (גרסאות TPU לפני v6e) של יחידות הצטברות כפל במערך סיסטולי. יחידות MXU מספקות את רוב כוח המחשוב ב-TensorCore. כל MXU יכול לבצע 16,000 פעולות של הכפלה וצבירה בכל מחזור. כל פעולות הכפל מקבלות קלט בפורמט bfloat16, אבל כל הצבירות מתבצעות בפורמט המספרי FP32.
יחידת הווקטור משמשת לחישובים כלליים כמו הפעלות ו-softmax. היחידה הסקלרית משמשת לבקרת זרימה, לחישוב כתובות בזיכרון ולפעולות תחזוקה אחרות.
TPU Pod
TPU Pod הוא קבוצה רציפה של יחידות TPU שמקובצות יחד ברשת מיוחדת. מספר שבבי ה-TPU באשכול TPU Pod תלוי בגירסת ה-TPU.
פרוסה
פרוסת TPU היא אוסף של שבבים שנמצאים כולם באותו TPU Pod ומחוברים באמצעות חיבורים מהירים בין השבבים (ICI). הפרוסות מתוארות במונחים של צ'יפים או TensorCores, בהתאם לגרסת ה-TPU.
טופולוגיה
הטופולוגיה מגדירה את הסידור הפיזי של יחידות ה-TPU בפריסת TPU. ל-TPU slices יש טופולוגיות דו-ממדיות (2D) או תלת-ממדיות (3D), בהתאם לגרסת ה-TPU. מגדירים טופולוגיה כמספר שבבי ה-TPU בכל מימד באופן הבא:
- טופולוגיות תלת-ממדיות: מגדירים את הטופולוגיה כטופל של 3 (
{A}x{B}x{C}), לדוגמה,4x4x4. המוצר של{A}x{B}x{C}מגדיר את מספר שבבי ה-TPU בפרוסת ה-TPU. אם משתמשים בטופולוגיה עם יותר מ-64 שבבים, הערכים שמוקצים למאפיינים{A},{B}ו-{C}צריכים לעמוד בתנאים הבאים:- הערכים
{A},{B}ו-{C}חייבים להיות כפולות של ארבע. - הערכים שמוקצים צריכים להיות בפורמט הבא:
{A}≤{B}≤{C}. לדוגמה,4x4x8או8x8x8.
- הערכים
- טופולוגיות דו-ממדיות: מגדירים את הטופולוגיה כ-2-tuple (
{A}x{B}), לדוגמה,2x4. המוצר של{A}x{B}מגדיר את מספר שבבי ה-TPU בפרוסת ה-TPU.
טופולוגיה של מארח יחיד היא טופולוגיה עם שבבי TPU ממארח חישוב יחיד. לדוגמה, ב-TPU7x, כל מארח מחובר לארבעה שבבים. לפרוסת 2x2x1 יש ארבעה שבבים שמחוברים למארח יחיד, ולכן 2x2x1 היא טופולוגיה של מארח יחיד.
טופולוגיה מרובת מארחים היא טופולוגיה עם שבבי TPU מיותר ממארח מחשוב אחד. לדוגמה, ב-TPU7x, 2x2x2 (שמונה שבבים משני מארחים) ופלחים גדולים יותר הם טופולוגיות של כמה מארחים.
פרוסות מרובות לעומת פרוסה אחת
Multislice היא קבוצה של slices, שמרחיבה את הקישוריות של TPU מעבר לחיבורים של inter-chip interconnect (ICI) וממנפת את הרשת של מרכז הנתונים (DCN) להעברת נתונים מעבר ל-slice. הנתונים בכל פלח עדיין מועברים על ידי ICI. באמצעות הקישוריות ההיברידית הזו, Multislice מאפשרת מקביליות בין חלקי TPU ומאפשרת לכם להשתמש במספר גדול יותר של ליבות TPU למשימה אחת מאשר מה שחלק TPU יחיד יכול להכיל.
אפשר להשתמש ב-TPU כדי להריץ עבודה בפרוסת TPU אחת או בכמה פרוסות. פרטים נוספים זמינים במאמר מבוא ל-Multislice.
TPU cube
טופולוגיה של 4x4x4 של שבבי TPU מחוברים. ההגדרה הזו רלוונטית רק לטופולוגיות תלת-ממדיות (החל מ-TPU v4).
SparseCore
ליבות Sparse הן מעבדי Dataflow שמאיצים מודלים באמצעות פעולות Sparse. תרחיש שימוש עיקרי הוא האצת מודלים של המלצות, שמסתמכים במידה רבה על הטמעות. ל-v5p ול-TPU7x יש ארבע ליבות SparseCore לכל שבב, ול-v6e יש שתי ליבות SparseCore לכל שבב. הסבר מפורט על השימוש ב-SparseCore זמין במאמר A deep dive into SparseCore for Large Embedding Models (LEM). אתם קובעים איך מהדר XLA משתמש ב-SparseCores באמצעות דגלי XLA. מידע נוסף זמין במאמר בנושא דגלים של TPU XLA.
עמידות של Cloud TPU ICI
התכונה ICI resiliency עוזרת לשפר את עמידות התקלות של קישורים אופטיים ומפסקי מעגלים אופטיים (OCS) שמחברים בין יחידות TPU בתוך קוביות. (חיבורי ICI בתוך קובייה משתמשים בקישורי נחושת שלא מושפעים). הגמישות של ICI מאפשרת לנתב חיבורי ICI מסביב ל-OCS ולתקלות אופטיות ב-ICI. כתוצאה מכך, משתפרת הזמינות של פריסות TPU לתזמון, אבל יש פשרה: ירידה זמנית בביצועים של ICI.
ב-Cloud TPU v4, v5p ו-TPU7x, חוסן ICI מופעל כברירת מחדל עבור פרוסות בגודל קובייה אחת ומעלה, למשל:
- v5p-128 כשמציינים את סוג המאיץ
- 4x4x4 כשמציינים את תצורת המאיץ
גרסאות TPU
הארכיטקטורה המדויקת של שבב TPU תלויה בגרסת ה-TPU שבה אתם משתמשים. כל גרסת TPU תומכת גם בגדלים ובהגדרות שונים של פרוסות. מידע נוסף על ארכיטקטורת המערכת וההגדרות הנתמכות זמין בדפים הבאים:
ארכיטקטורת ענן TPU
Google Cloud TPU זמינים כמשאבי מחשוב באמצעות מכונות וירטואליות של TPU. אפשר להשתמש ב-TPU לעומסי העבודה דרך Compute Engine, Google Kubernetes Engine ו-Vertex AI. בקטעים הבאים מתוארים רכיבים מרכזיים בארכיטקטורת הענן של TPU.
ארכיטקטורת TPU VM
ארכיטקטורת TPU VM מאפשרת להתחבר ישירות למכונה הווירטואלית שמחוברת פיזית למכשיר ה-TPU באמצעות SSH. מכונת TPU VM, שנקראת גם worker, היא מכונה וירטואלית שמריצה Linux ויש לה גישה ל-TPU הבסיסי. יש לכם גישת root למכונה הווירטואלית, כך שאתם יכולים להריץ קוד שרירותי. אתם יכולים לגשת ליומני ניפוי באגים ולהודעות שגיאה של מהדר ושל זמן ריצה.

מארח יחיד, כמה מארחים ומארח משנה
מארח TPU הוא מכונה וירטואלית (VM) שפועלת במחשב פיזי שמחובר לחומרת TPU. עומסי עבודה של TPU יכולים להשתמש במארח אחד או יותר.
עומס עבודה במארח יחיד מוגבל למכונת TPU וירטואלית אחת. עומס עבודה עם כמה מארחים מחלק את האימון בין כמה מכונות וירטואליות של TPU. עומס עבודה של תת-מארח לא משתמש בכל הצ'יפים במכונה וירטואלית של TPU.
כלי להמחשת טופולוגיית TPU
כלי ההדמיה של טופולוגיית TPU מאפשר לכם להציג באופן חזותי את הפריסה הפיזית של יחידות TPU ואת תשתית הרשת המשויכת שלהן במרכז נתונים פיזי. אפשר להשתמש בכלי כדי להבין את פריסת התשתית הפיזית לדורות ולטופולוגיות שונים של TPU.