
TPU v4
במאמר הזה מתוארת הארכיטקטורה של Cloud TPU v4 וההגדרות הנתמכות שלו.
ארכיטקטורת המערכת
כל שבב TPU v4 מכיל שני TensorCore. לכל TensorCore יש ארבע יחידות כפל מטריצות (MXU), יחידת וקטור ויחידה סקלרית. בטבלה הבאה מוצגים המפרטים העיקריים של TPU Pod מדור 4.
| מפרט | ערכים |
|---|---|
| שיא יכולת החישוב לכל שבב | 275 טרה-פלופס (bf16 או int8) |
| הקיבולת ורוחב הפס של HBM2 | 32GiB, 1,200GBps |
| הספק מינימלי/ממוצע/מקסימלי שנמדד | 90/170/192 ואט |
| גודל ה-TPU Pod | 4,096 צ'יפס |
| טופולוגיית Interconnect | רשת תלת-ממדית |
| שיא עוצמת החישוב לכל Pod | 1.1 אקסה-פלופס (bf16 או int8) |
| רוחב הפס של כל הפחתה לכל Pod | 1.1 PB/s |
| רוחב פס של חציית הגרף לכל Pod | 24TB/s |
התרשים הבא מדגים שבב TPU v4.
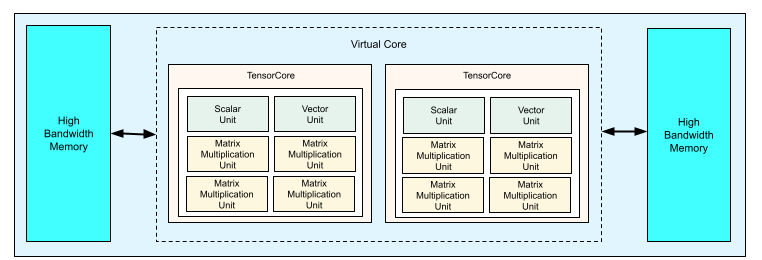
מידע נוסף על פרטי הארכיטקטורה ומאפייני הביצועים של TPU v4 זמין במאמר TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.
רשת תלת-ממדית וטורוס תלת-ממדי
ל-TPU מדור 4 יש חיבור ישיר לשבבים השכנים הקרובים ביותר ב-3 מימדים, וכך נוצרת רשת תלת-ממדית של חיבורי רשת. אפשר להגדיר את החיבורים כטורוס תלת-ממדי בפרוסות, כאשר הטופולוגיה, AxBxC, היא 2A=B=C או 2A=2B=C, וכל מימד הוא כפולה של 4. לדוגמה, 4x4x8, 4x8x8 או 12x12x24. באופן כללי, הביצועים של תצורת טורוס תלת-ממדית יהיו טובים יותר מאלה של תצורת רשת תלת-ממדית. מידע נוסף זמין במאמר בנושא Twisted torus topologies.
היתרונות של TPU v4 לעומת v3 מבחינת ביצועים
בקטע הזה מוצגת דרך יעילה מבחינת זיכרון להפעלת סקריפט לדוגמה של אימון ב-TPU v4, וגם שיפורי הביצועים ב-TPU v4 בהשוואה ל-TPU v3.
מערכת זיכרון
גישה לזיכרון לא אחיד (NUMA) היא ארכיטקטורה של זיכרון מחשב למכונות עם כמה מעבדים. לכל מעבד יש גישה ישירה לבלוק של זיכרון מהיר. מעבד והזיכרון שלו נקראים צומת NUMA. צמתי NUMA מחוברים לצמתי NUMA אחרים שנמצאים בסמיכות ישירה זה לזה. מעבד מתוך צומת NUMA אחד יכול לגשת לזיכרון בצומת NUMA אחר, אבל הגישה הזו איטית יותר מגישה לזיכרון בתוך צומת NUMA.
תוכנה שפועלת במחשב עם כמה מעבדים יכולה למקם נתונים שדרושים למעבד בתוך צומת ה-NUMA שלו, וכך להגדיל את קצב העברת הנתונים בזיכרון. מידע נוסף על NUMA זמין במאמר Non Uniform Memory Access (גישה לזיכרון לא אחיד) ב-Wikipedia.
כדי ליהנות מהיתרונות של NUMA-locality, אפשר לקשור את סקריפט האימון ל-NUMA Node 0.
כדי להפעיל את הקישור של צומת NUMA:
מתקינים את כלי שורת הפקודה numactl. בעזרת numactl אפשר להריץ תהליכים עם מדיניות תזמון NUMA ספציפית או מדיניות מיקום זיכרון.
$ sudo apt-get update $ sudo apt-get install numactl
מקשרים את קוד הסקריפט ל-NUMA Node 0. מחליפים את your-training-script בנתיב לסקריפט האימון.
$ numactl --cpunodebind=0 python3 your-training-script
הפעלת קישור של צומת NUMA אם:
- אם עומס העבודה שלכם תלוי מאוד בעומסי עבודה של מעבד (לדוגמה, סיווג תמונות, עומסי עבודה של המלצות) ללא קשר למסגרת.
- אם אתם משתמשים בגרסת TPU runtime ללא הסיומת -pod (לדוגמה,
tpu-vm-tf-2.10.0-v4).
הבדלים נוספים במערכת הזיכרון:
- לשבבי TPU מדור 4 יש זיכרון HBM מאוחד של 32 גיגה-בייט בכל השבב, מה שמאפשר תיאום טוב יותר בין שני ליבות TensorCore בשבב.
- שיפור הביצועים של HBM באמצעות תקני זיכרון ומהירויות עדכניים.
- פרופיל ביצועים משופר של DMA עם תמיכה מובנית בצעדים של 512B לביצועים גבוהים.
TensorCores
- מספר כפול של MXU וקצב שעון גבוה יותר שמספקים 275 TFLOPS מקסימליים.
- רוחב פס של 2x להחלפה ולתמורה.
- מודל גישה לזיכרון מסוג Load-store לזיכרון משותף (Cmem).
- רוחב פס מהיר יותר לטעינת משקלים של MXU ותמיכה במצב 8 ביט כדי לאפשר גדלים קטנים יותר של אצווה וזמן אחזור משופר של הסקה.
חיבור בין שבבים
שישה קישורים לחיבור בין שבבים כדי לאפשר טופולוגיות של רשתות עם קוטר רשת קטן יותר.
אחר
- ממשק x16 PCIE gen3 למארח (חיבור ישיר).
- מודל אבטחה משופר.
- שיפור היעילות האנרגטית.
הגדרות אישיות
פוד TPU v4 מורכב מ-4,096 שבבים שמחוברים ביניהם באמצעות קישורים מהירים שניתנים להגדרה מחדש. הגמישות של רשת TPU v4 מאפשרת לחבר את הצ'יפים בפרוסת TPU באותו גודל בכמה דרכים. כשיוצרים פרוסת TPU, מציינים את גרסת ה-TPU ואת מספר משאבי ה-TPU שנדרשים.
מגדירים טופולוגיית TPU באמצעות 3-tuple, AxBxC, כאשר A<=B<=C ו-A, B, C הם כולם <= 4 או כולם כפולות שלמות של 4. הערכים A, B ו-C הם מספרי השבבים בכל אחד משלושת המאפיינים.
בטופולוגיות שבהן 2A=B=C או 2A=2B=C יש גם וריאציות של טופולוגיות שמיועדות לתקשורת בין כל הרכיבים, למשל 4x4x8, 8x8x16 ו-12x12x24. הן נקראות טופולוגיות של טורוס מעוות.
באיורים הבאים מוצגות כמה טופולוגיות נפוצות של TPU v4.
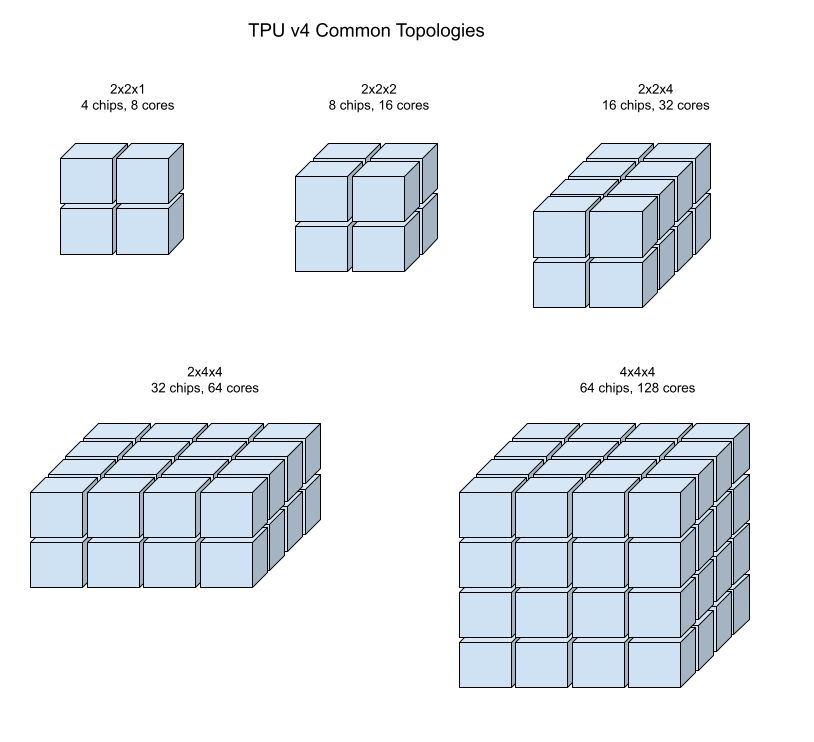
אפשר ליצור פרוסות גדולות יותר מ "קוביות" של שבבים בגודל 4x4x4.
מידע נוסף על ניהול TPU זמין במאמר ניהול TPU. מידע נוסף על ארכיטקטורת המערכת של Cloud TPU זמין במאמר ארכיטקטורת המערכת.
טופולוגיות של טורוס מעוות
בצורות מסוימות של פרוסות תלת-ממדיות, אפשר להשתמש בטופולוגיה של טורוס מעוות. הטופולוגיות האלה מציעות רוחב פס גבוה משמעותית של חציית הגרף. לדוגמה, טופולוגיה מעוותת של 4x4x8 מספקת עלייה תיאורטית של 70% ברוחב הפס של החיתוך בהשוואה לחיתוך לא מעוות של 4x4x8. רוחב הפס המוגדל הזה עוזר לעומסי עבודה שמשתמשים בדפוסי תקשורת גלובליים. טופולוגיות מסוג Twisted יכולות לשפר את הביצועים של רוב המודלים, והן מועילות במיוחד לעומסי עבודה גדולים של הטמעת TPU. תוכנת ה-TPU תומכת בטופולוגיות מעוותות בפרוסות שבהן כל מימד שווה למימד הקטן ביותר או גדול ממנו פי שניים. לדוגמה, 4x4x8, 4×8×8 או 12x12x24. טופולוגיות מסוג Twisted נתמכות ב-TPU v4 וב-TPU v5p דרך Cloud TPU API.
עבור עומסי עבודה שמשתמשים במקביליות נתונים כאסטרטגיית המקביליות היחידה, יכול להיות שטופולוגיות מעוותות יניבו ביצועים טובים יותר. במודלים גדולים של שפה (LLM), הביצועים של טופולוגיה מעוותת משתנים בהתאם לסוג ההקבלה שנעשה בה שימוש (לדוגמה, הקבלה של נתונים או הקבלה של מודלים). כדי להשיג את הביצועים הכי טובים של המודל, כדאי לאמן את מודל ה-LLM עם טופולוגיה מעוותת וגם בלי. חלק מהניסויים במודל FSDP MaxText הראו שיפורים של נקודת אחוז אחת עד שתיים בניצול FLOPs של המודל (MFU) כשמשתמשים בטופולוגיה מעוותת.
היתרון העיקרי של טופולוגיות מעוותות הוא שהן משנות טופולוגיה אסימטרית של טורוס (לדוגמה, 4×4×8) לטופולוגיה סימטרית. טופולוגיה סימטרית מציעה:
- איזון עומסים משופר
- רוחב פס גבוה יותר של חצייה
- מסלולים קצרים יותר של חבילות
היתרונות האלה מובילים לשיפור הביצועים בהרבה תרחישי תקשורת גלובליים.
לדוגמה, נניח שיש טופולוגיית טורוס בגודל 4x2 עם מעבדי TPU שמסומנים עם קואורדינטות X ו-Y בפלח:
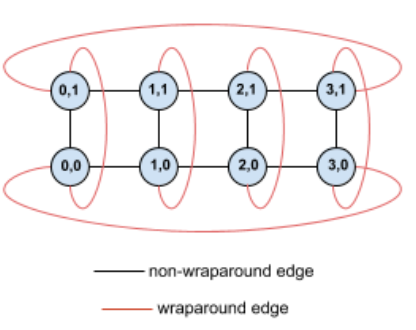
לשם הבהרה, בתרשים מוצגים החיבורים כקצוות לא מכוונים. בפועל, כל קצה הוא חיבור דו-כיווני בין מעבדי TPU. הקצוות בין צד אחד של הרשת הזו לבין הצד הנגדי הם קצוות שחוזרים על עצמם.
אם משנים את הטופולוגיה הזו, מקבלים טופולוגיית טורוס מעוות סימטרית של 4×2:
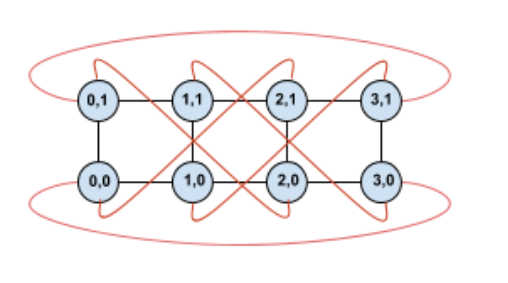
ההבדל בין הדיאגרמה המעוותת הזו לבין הדיאגרמה הלא מעוותת הוא בקצוות המעוגלים של ציר Y. במקום להתחבר ל-TPU אחר עם אותו קואורדינטה X, הקצוות האלה מתחברים ל-TPU בקואורדינטה X+2 mod 4.
העיקרון הזה חל על גדלים שונים של מאפיינים ועל מספרים שונים של מאפיינים. הרשת שמתקבלת היא סימטרית אם כל מימד שווה למימד הקטן ביותר או גדול ממנו פי שניים.
בטבלה הבאה מוצגות כמה טופולוגיות מעוותות נתמכות והגידול התיאורטי ברוחב הפס של החלוקה לשני חלקים שהן מספקות לעומת טופולוגיות לא מעוותות.
| טופולוגיה | עלייה תיאורטית ברוחב הפס של החיתוך בהשוואה לטורוס לא מסובב |
|---|---|
| 4×4×8 | ~70% |
| 8x8x16 | |
| 12×12×24 | |
| 4×8×8 | ~40% |
| 8×16×16 |
וריאציות של טופולוגיה ב-TPU v4
אפשר לסדר טופולוגיות מסוימות שמכילות את אותו מספר צ'יפים בדרכים שונות. לדוגמה, אפשר להגדיר פרוסת TPU עם 512 שבבים (1, 024 TensorCores) באמצעות הטופולוגיות הבאות: 4x4x32, 4x8x16 או 8x8x8. פרוסת TPU עם 2,048 שבבים (4,096 TensorCores) מציעה עוד יותר אפשרויות טופולוגיה: 4x4x128, 4x8x64, 4x16x32 ו-8x16x16.
טופולוגיית ברירת המחדל שמשויכת למספר נתון של שבבים היא זו שהכי דומה לקובייה. הצורה הזו היא כנראה הבחירה הטובה ביותר לאימון מקביל של למידת מכונה. טופולוגיות אחרות יכולות להיות שימושיות לעומסי עבודה עם כמה סוגים של מקביליות (לדוגמה, מקביליות של מודלים ונתונים, או חלוקה מרחבית של סימולציה). עומסי העבודה האלה מניבים את התוצאות הטובות ביותר אם הטופולוגיה תואמת למידת המקביליות שבה נעשה שימוש. לדוגמה, אם מציבים מקביליות של מודל 4-way במאפיין X ומקביליות של נתונים 256-way במאפיינים Y ו-Z, מתקבלת טופולוגיה של 4x16x16.
מודלים עם כמה מימדים של מקביליות פועלים בצורה הטובה ביותר כשמימדי המקביליות שלהם ממופים למימדי הטופולוגיה של TPU. בדרך כלל מדובר במודלים גדולים של שפה (LLM) שפועלים במקביל לנתונים ולמודלים. לדוגמה, עבור פרוסת TPU v4 עם טופולוגיה 8x16x16, המימדים של טופולוגיית ה-TPU הם 8, 16 ו-16. יעיל יותר להשתמש במקביליות של מודל 8-way או 16-way (שממופה לאחד מהממדים של טופולוגיית ה-TPU הפיזי). מקביליות מודל 4-way תהיה לא אופטימלית בטופולוגיה הזו, כי היא לא תואמת לאף אחד מהממדים של טופולוגיית ה-TPU, אבל היא תהיה אופטימלית בטופולוגיה 4x16x32 באותו מספר של שבבים.
תצורות TPU v4 מורכבות משתי קבוצות: תצורות עם טופולוגיות קטנות מ-64 שבבים (טופולוגיות קטנות) ותצורות עם טופולוגיות גדולות מ-64 שבבים (טופולוגיות גדולות).
טופולוגיות קטנות של v4
Cloud TPU תומך בפרוסות TPU v4 הבאות שקטנות מ-64 שבבים, קובייה בגודל 4x4x4. אפשר ליצור את הטופולוגיות הקטנות האלה של v4 באמצעות השם שלהן שמבוסס על TensorCore (לדוגמה, v4-32) או באמצעות הטופולוגיה שלהן (לדוגמה, 2x2x4):
| שם (מבוסס על מספר ליבות Tensor) | מספר הצ'יפים | טופולוגיה |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
טופולוגיות גדולות מגרסה 4
פרוסות TPU v4 זמינות במרווחים של 64 שבבים, עם צורות שהן כפולות של 4 בכל שלושת הממדים. המידות צריכות להיות בסדר עולה. בטבלה הבאה מוצגות כמה דוגמאות. חלק מהטופולוגיות האלה הן טופולוגיות 'מותאמות אישית' שאפשר ליצור רק באמצעות הדגלים --type ו---topology, כי יש יותר מדרך אחת לסדר את הצ'יפים.
| שם (מבוסס על מספר ליבות Tensor) | מספר הצ'יפים | טופולוגיה |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
טופולוגיה בהתאמה אישית: חובה להשתמש בדגלים --type ו---topology |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
טופולוגיה בהתאמה אישית: חובה להשתמש בדגלים --type ו---topology |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |