
סקירה כללית על Cloud TPU Multislice
Cloud TPU Multislice היא טכנולוגיה מלאה להרחבת הביצועים, שמאפשרת לעבודת אימון להשתמש בכמה TPU slices בתוך פוד יחיד או ב-slices בכמה Pods עם מקביליות נתונים רגילה. בצ'יפים של TPU v4, המשמעות היא שעבודות אימון יכולות להשתמש ביותר מ-4,096 צ'יפים בהרצה אחת. למשימות אימון שדורשות פחות מ-4,096 שבבים, פרוסה אחת יכולה להציע את הביצועים הכי טובים. עם זאת, יש יותר נתונים זמינים בפרוסות קטנות יותר, ולכן זמן ההפעלה מהיר יותר כשמשתמשים ב-Multislice עם פרוסות קטנות יותר.
כשפריסת ה-TPU מתבצעת בתצורות Multislice, שבבי ה-TPU בכל slice מתקשרים באמצעות חיבור בין השבבים (ICI). שבבי TPU בפרוסות שונות מתקשרים ביניהם באמצעות העברת נתונים למעבדי CPU (מארחים), שמעבירים את הנתונים בתורם ברשת מרכז הנתונים (DCN). מידע נוסף על שינוי קנה מידה באמצעות Multislice זמין במאמר איך משנים את קנה המידה של אימון AI לעשרות אלפי שבבי Cloud TPU באמצעות Multislice.
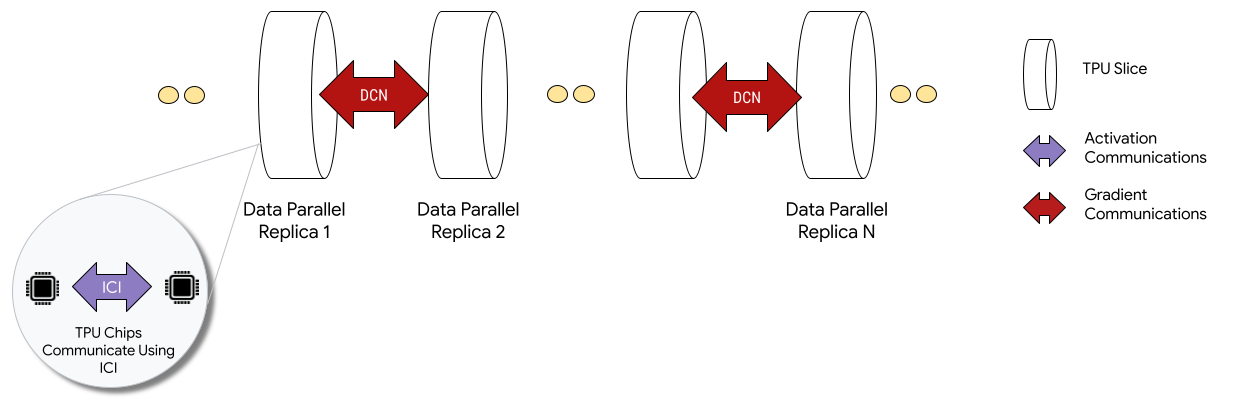
מפתחים לא צריכים לכתוב קוד כדי להטמיע תקשורת DCN בין פרוסות. הקומפיילר XLA יוצר את הקוד הזה בשבילכם, ומבצע חפיפה בין התקשורת לבין החישוב כדי להשיג ביצועים מקסימליים.
מושגים
- סוג המאיץ
- הצורה של כל פרוסת TPU
שמרכיבה Multislice. כל פרוסה בבקשה של כמה פרוסות היא מאותו סוג של מאיץ. סוג המאיץ מורכב מסוג TPU (גרסה 4 ואילך) ואחריו מספר ליבות TensorCore.
לדוגמה,
v5litepod-128מציין TPU v5e עם 128 TensorCores. - תיקון אוטומטי
- אם פרוסת TPU נתקלת באירוע תחזוקה, בהקדמה או בכשל בחומרה, Cloud TPU יוצר פרוסת TPU חדשה. אם אין מספיק משאבים ליצירת פרוסה חדשה, היצירה לא תושלם עד שהחומרה תהיה זמינה. אחרי שיוצרים את הפרוסה החדשה, כל הפרוסות האחרות בסביבת Multislice יופעלו מחדש כדי שאפשר יהיה להמשיך את האימון. אם סקריפט ההפעלה מוגדר בצורה נכונה, סקריפט האימון יכול להפעיל מחדש את האימון באופן אוטומטי ללא התערבות המשתמש, לטעון את נקודת הבדיקה האחרונה ולהמשיך ממנה.
- Data Center Networking (DCN)
- רשת עם זמן אחזור ארוך יותר וקצב העברת נתונים נמוך יותר (בהשוואה ל-ICI) שמחברת פרוסות TPU בהגדרה של Multislice.
- תזמון קבוצתי
- כשכל פרוסות ה-TPU מוקצות יחד, בו-זמנית, כך שמובטח שכולן יוקצו בהצלחה או שאף אחת מהן לא תוקצה.
- Interchip interconnect (ICI)
- קישורים פנימיים במהירות גבוהה ובזמן אחזור נמוך שמקשרים בין יחידות TPU בתוך TPU Pod.
- Multislice
- שני חלקי שבב TPU או יותר שיכולים לתקשר באמצעות DCN.
- צומת
- בהקשר של Multislice, המונח 'צומת' מתייחס לTPU slice יחיד. לכל פרוסת TPU ב-Multislice מוקצה מזהה צומת.
- סקריפט לטעינה בזמן ההפעלה
- סקריפט הפעלה של Compute Engine שמופעל בכל פעם שמכונה וירטואלית מופעלת או מופעלת מחדש. בMultislice, הוא מצוין בבקשה ליצירת קוד ה-QR. מידע נוסף על סקריפטים להפעלה של Cloud TPU זמין במאמר ניהול משאבי TPU.
- Tensor
- מבנה נתונים שמשמש לייצוג נתונים רב-ממדיים במודל של למידת מכונה.
- סוגים של קיבולת Cloud TPU
אפשר ליצור יחידות TPU מסוגים שונים של קיבולת (ראו את האפשרויות לשימוש במאמר איך מתבצע התמחור של TPU):
הזמנה: כדי להשתמש בהזמנה, צריך להיות לכם הסכם הזמנה עם Google. משתמשים בדגל
--reservedכשיוצרים את המשאבים.Spot: מכוון למכסות זמניות באמצעות מכונות וירטואליות (VM) במודל Spot. יכול להיות שהמשאבים שלכם יידחקו כדי לפנות מקום לבקשות של משימה עם עדיפות גבוהה יותר. משתמשים בדגל
--spotכשיוצרים את המשאבים.על פי דרישה: מכוון למכסת יעד על פי דרישה, שלא צריך להזמין מראש ולא תהיה לו עדיפות קודמת. בקשת ה-TPU תתווסף לתור של מכסת משאבים על פי דרישה שמוצעת על ידי Cloud TPU, אבל אין ערובה לזמינות המשאבים. האפשרות הזו מסומנת כברירת מחדל, ולא צריך להוסיף לה סימונים.
קדימה, מתחילים
-
-
במסוף Google Cloud , מפעילים את Cloud Shell.
בחלק התחתון של Google Cloud המסוף יתחיל סשן של Cloud Shell ותופיע הודעה של שורת הפקודה. Cloud Shell היא סביבת מעטפת שבה ה-CLI של Google Cloud מותקן ומוגדרים ערכים לפרויקט הקיים. הסשן יופעל תוך כמה שניות.
כדי להשתמש ב-Multislice, צריך לנהל את משאבי ה-TPU בתור משאבים בתור.
דוגמה להודעה מתפרצת
במדריך הזה נעשה שימוש בקוד ממאגר GitHub של MaxText. MaxText הוא מודל LLM בסיסי בקוד פתוח, שניתן להרחבה באופן שרירותי, בעל ביצועים גבוהים ונבדק היטב. הוא נכתב ב-Python וב-Jax. MaxText תוכנן להתאמן ביעילות ב-Cloud TPU.
הקוד ב-shardings.py נועד לעזור לכם להתחיל להתנסות באפשרויות שונות של מקביליות. לדוגמה, מקביליות נתונים, מקביליות נתונים עם חלוקה מלאה (FSDP) ומקביליות טנסור. הקוד ניתן להרחבה מסביבות של פרוסה אחת לסביבות של כמה פרוסות.
מקביליות של ICI
ICI הוא קיצור של Interchip Interconnect, חיבור מהיר בין שבבים שמקשר בין יחידות ה-TPU בפרוסת TPU אחת. חלוקת נתונים (sharding) ב-ICI תואמת לחלוקת נתונים בתוך פרוסה. shardings.py
מספק שלושה פרמטרים של מקביליות ICI:
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelism
הערכים שאתם מציינים לפרמטרים האלה קובעים את מספר הרסיסים לכל שיטת מקביליות.
הקלט צריך להיות מוגבל כך ש-ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism יהיה שווה למספר הצ'יפים בפרוסה.
בטבלה הבאה מוצגות דוגמאות לקלט משתמשים עבור מקביליות ICI לארבעת השבבים שזמינים ב-v4-8:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| 4-way FSDP | 1 | 4 | 1 |
| מקביליות טנסור ב-4 כיוונים | 1 | 1 | 4 |
| 2-way FSDP + 2-way Tensor parallelism | 1 | 2 | 2 |
הערה: ברוב המקרים צריך להשאיר את ici_data_parallelism כ-1, כי רשת ה-ICI מהירה מספיק כדי להעדיף כמעט תמיד FSDP על פני מקביליות נתונים.
בדוגמה הזו אנחנו מניחים שאתם יודעים איך להריץ קוד בפלח TPU יחיד, כמו בדוגמה הרצת חישוב במכונה וירטואלית של Cloud TPU באמצעות JAX.
בדוגמה הזו אפשר לראות איך מריצים את shardings.py על פרוסה אחת.
מגדירים את הסביבה:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
תיאורי משתנים
-
QR_ID: המזהה שהמשתמש הקצה למשאב בתור. -
TPU_NAME: השם שהמשתמש הקצה ל-TPU. -
PROJECT: Google Cloud שם הפרויקט -
ZONE: מציין את האזור שבו ייצרו את המשאבים. -
NETWORK_NAME: השם של רשת ה-VPC. -
SUBNETWORK_NAME: השם של תת-הרשת ברשת ה-VPC -
RUNTIME_VERSION: גרסת התוכנה של Cloud TPU. -
ACCELERATOR_TYPE: סוג המאיץ מציין את הגרסה והגודל של Cloud TPU שרוצים ליצור. -
EXAMPLE_TAG_1, EXAMPLE_TAG_2 …: תגים שמשמשים לזיהוי מקורות או יעדים תקפים לחומות אש ברשת -
SLICE_COUNT: מספר הפרוסות. מוגבל ל-256 פלחים לכל היותר. -
STARTUP_SCRIPT: אם מציינים סקריפט לטעינה בזמן ההפעלה, הסקריפט יפעל כשפרוסת ה-TPU תוקצה או תופעל מחדש.
-
יוצרים מפתחות SSH ל-
gcloud. מומלץ להשאיר סיסמה ריקה (צריך להקיש על מקש Enter פעמיים אחרי הרצת הפקודה הבאה). אם מופיעה הודעה שהקובץgoogle_compute_engineכבר קיים, מחליפים את הגרסה הקיימת.$ ssh-keygen -f ~/.ssh/google_compute_engine
הקצאת מעבדי TPU:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI לא תומך בכל האפשרויות ליצירת קודי QR, כמו תגים. למידע נוסף, אפשר לעיין במאמר יצירת קודי QR.
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על יצירת TPU.
בשדה שם, מזינים שם ל-TPU.
בתיבה תחום, בוחרים את התחום שבו רוצים ליצור את ה-TPU.
בתיבה TPU type, בוחרים סוג של מאיץ. סוג המאיץ מציין את הגרסה והגודל של Cloud TPU שרוצים ליצור. מידע נוסף על סוגי המאיצים הנתמכים לכל גרסת TPU זמין במאמר גרסאות TPU.
בתיבה TPU software version (גרסת התוכנה של ה-TPU), בוחרים גרסת תוכנה. כשיוצרים מכונת TPU וירטואלית ב-Cloud TPU, גרסת התוכנה של ה-TPU מציינת את גרסת זמן הריצה של ה-TPU שמותקנת. מידע נוסף זמין במאמר בנושא גרסאות תוכנה של TPU.
לוחצים על המתג הפעלת הוספה לתור.
נותנים לבקשה שם בשדה Queued resource name.
לוחצים על יצירה כדי ליצור את בקשת המשאבים בתור.
ממתינים עד שהמשאב בתור יהיה במצב
ACTIVE, כלומר צמתי העובדים יהיו במצבREADY. אחרי שהקצאת המשאבים בתור מתחילה, יכול להיות שיעברו בין דקה לחמש דקות עד שהיא תסתיים, בהתאם לגודל המשאב בתור. אפשר לבדוק את הסטטוס של בקשה למשאב שנמצאת בתור באמצעות ה-CLI של gcloud או מסוף Google Cloud :gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על הכרטיסייה משאבים בתור.
לוחצים על השם של בקשת המשאב שנמצאת בתור.
מתחברים למכונת ה-TPU הווירטואלית באמצעות SSH:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
משכפלים את MaxText (שכולל את
shardings.py) ל-TPU VM:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
מתקינים את Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
יוצרים ומפעילים סביבה וירטואלית:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
בתוך ספריית המאגר MaxText, מריצים את סקריפט ההגדרה כדי להתקין את JAX ואת יחסי התלות האחרים בפרוסת ה-TPU. הפעלת סקריפט ההגדרה נמשכת כמה דקות.
$ bash setup.sh
מריצים את הפקודה הבאה כדי להפעיל את
shardings.pyבפלח ה-TPU.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
אפשר לראות את התוצאות ביומנים. יחידות ה-TPU שלכם צריכות להגיע ל-260 TFLOP בשנייה או לניצול מרשים של 90%ומעלה של FLOP. במקרה הזה, בחרנו בערך את גודל האצווה המקסימלי שמתאים לזיכרון ברוחב פס גבוה (HBM) של TPU.
אתם יכולים לבדוק אסטרטגיות אחרות של חלוקה לשברים ב-ICI, למשל את השילוב הבא:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
בסיום, מוחקים את המשאב ואת פרוסת ה-TPU שהוכנסו לתור. צריך להריץ את שלבי הניקוי האלה מהסביבה שבה הגדרתם את הפרוסה (קודם מריצים את הפקודה
exitכדי לצאת מסשן ה-SSH). תהליך המחיקה יימשך בין שתי לחמש דקות. אם משתמשים ב-CLI של gcloud, אפשר להריץ את הפקודה הזו ברקע באמצעות הדגל האופציונלי--async.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על הכרטיסייה משאבים בתור.
מסמנים את התיבה לצד בקשת המשאב שנמצאת בתור.
לוחצים על מחיקה.
חלוקת נתונים (sharding) של ריבוי-פרוסות (Multislice) באמצעות מקביליות של DCN
סקריפט shardings.py מקבל שלושה פרמטרים שמציינים את המקביליות של DCN, בהתאם למספר הרסיסים של כל סוג של מקביליות נתונים:
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
הערכים של הפרמטרים האלה צריכים להיות מוגבלים כך ש-dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism יהיה שווה למספר הפלחים.
לדוגמה, כדי ליצור שני פלחים, משתמשים ב---dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | מספר הפרוסות | |
| מקביליות נתונים דו-כיוונית | 2 | 1 | 1 | 2 |
הערך של dcn_tensor_parallelism צריך להיות תמיד 1 כי DCN לא מתאים לחלוקה כזו. בדרך כלל, בעומסי עבודה של LLM על שבבי v4, צריך להגדיר את dcn_fsdp_parallelism ל-1, ולכן צריך להגדיר את dcn_data_parallelism למספר הפרוסות, אבל זה תלוי באפליקציה.
ככל שמגדילים את מספר הפלחים (בהנחה שגודל הפלח והגודל של כל אצווה נשארים קבועים), כך גדלה כמות המקביליות של הנתונים.
הפעלת shardings.py בסביבת Multislice
אפשר להריץ את shardings.py בסביבת Multislice באמצעות multihost_runner.py או באמצעות הרצת shardings.py בכל מכונת TPU וירטואלית. כאן אנחנו משתמשים ב-multihost_runner.py. השלבים הבאים דומים מאוד לאלה שמופיעים במאמר תחילת העבודה: ניסויים מהירים בכמה פלחים ממאגר MaxText, אלא שכאן מריצים את shardings.py במקום את ה-LLM המורכב יותר ב-train.py.
הכלי multihost_runner.py מותאם לניסויים מהירים, שבהם נעשה שימוש חוזר באותם מעבדי TPU. הסקריפט multihost_runner.py מסתמך על חיבורי SSH לטווח ארוך, ולכן אנחנו לא ממליצים להשתמש בו למשימות שפועלות לאורך זמן.
אם רוצים להריץ עבודה ארוכה יותר (למשל, שעות או ימים), מומלץ להשתמש ב-multihost_job.py.
במדריך הזה, המונח runner מתייחס למכונה שבה מריצים את הסקריפט multihost_runner.py. אנחנו משתמשים במונח workers כדי לציין את מכונות ה-VM של TPU שמרכיבות את הפרוסות. אפשר להריץ את multihost_runner.py במחשב מקומי או בכל מכונה וירטואלית של Compute Engine באותו פרויקט שבו נמצאים הפלחים. אין תמיכה בהרצת multihost_runner.py על עובד.
multihost_runner.py מתחבר אוטומטית לעובדי TPU באמצעות SSH.
בדוגמה הזו, מריצים את shardings.py על שני חלקי v5e-16, כלומר על סך הכול ארבע מכונות וירטואליות ו-16 שבבי TPU. אפשר לשנות את הדוגמה כדי להריץ אותה על יותר יחידות TPU.
מגדירים את הסביבה
משכפלים את MaxText במכונת ה-Runner:
$ git clone https://github.com/AI-Hypercomputer/maxtext
עוברים לספריית המאגר.
$ cd maxtext
יוצרים מפתחות SSH עבור
gcloud. מומלץ להשאיר סיסמה ריקה (לוחצים על Enter פעמיים אחרי שמריצים את הפקודה הבאה). אם מוצגת הודעה שהקובץgoogle_compute_engineכבר קיים, בוחרים שלא לשמור את הגרסה הקיימת.$ ssh-keygen -f ~/.ssh/google_compute_engine
מוסיפים משתנה סביבה כדי להגדיר את מספר חלקי ה-TPU ל-
2.$ export SLICE_COUNT=2
יוצרים סביבת Multislice באמצעות הפקודה
queued-resources createאו באמצעות מסוף Google Cloud .gcloud
הפקודה הבאה מראה איך ליצור TPU v5e Multislice. כדי להשתמש בגרסה אחרת של TPU, צריך לציין
accelerator-typeו-runtime-versionאחרים.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על יצירת TPU.
בשדה שם, מזינים שם ל-TPU.
בתיבה תחום, בוחרים את התחום שבו רוצים ליצור את ה-TPU.
בתיבה TPU type, בוחרים סוג של מאיץ. סוג המאיץ מציין את הגרסה והגודל של Cloud TPU שרוצים ליצור. האפשרות Multislice נתמכת רק ב-Cloud TPU v4 ובגרסאות TPU חדשות יותר. מידע נוסף על גרסאות TPU זמין במאמר בנושא גרסאות TPU.
בתיבה TPU software version (גרסת התוכנה של ה-TPU), בוחרים גרסת תוכנה. כשיוצרים מכונת TPU וירטואלית ב-Cloud TPU, גרסת התוכנה של ה-TPU מציינת את גרסת זמן הריצה של ה-TPU שמותקנת במכונות ה-TPU הווירטואליות. מידע נוסף זמין במאמר בנושא גרסאות תוכנה של TPU.
לוחצים על המתג הפעלת הוספה לתור.
נותנים לבקשה שם בשדה Queued resource name.
לוחצים על תיבת הסימון Make this a Multislice TPU (הגדרת TPU מרובה).
בשדה מספר הפלחים מזינים את מספר הפלחים שרוצים ליצור.
לוחצים על יצירה כדי ליצור את בקשת המשאבים בתור.
כשמתחילה הקצאת המשאבים בתור, יכולות לעבור עד חמש דקות עד שהיא תושלם, בהתאם לגודל המשאב בתור. מחכים עד שהמשאב בתור יהיה במצב
ACTIVE. כדי לבדוק את הסטטוס של בקשה למשאב שנמצא בתור, אפשר להשתמש ב-CLI של gcloud או במסוף Google Cloud :gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
הפלט שיתקבל אמור להיראות כך:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על הכרטיסייה משאבים בתור.
לוחצים על השם של בקשת המשאב שנמצאת בתור.
אם הסטטוס של קוד ה-QR הוא
WAITING_FOR_RESOURCESאוPROVISIONINGבמשך יותר מ-15 דקות, צריך לפנות לאיש הקשר האחראי לחשבון. Google Cloudמתקינים יחסי תלות.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
מריצים את
shardings.pyבכל עובד באמצעותmultihost_runner.py.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
בקבצי היומן יופיעו נתוני ביצועים של כ-230 TFLOPs לשנייה.
מידע נוסף על הגדרת מקביליות זמין במאמרים בנושא Multislice sharding using DCN parallelism ו-
shardings.py.בסיום, מוחקים את ה-TPU ואת המשאב שהוכנס לתור. תהליך המחיקה יימשך בין שתי לחמש דקות. אם משתמשים ב-CLI של gcloud, אפשר להריץ את הפקודה הזו ברקע עם הדגל האופציונלי
--async.
שינוי קנה מידה של עומס עבודה ל-Multislice
לפני שמריצים את המודל בסביבת Multislice, צריך לבצע את שינויי הקוד הבאים:
- כשיוצרים את הרשת, צריך להשתמש ב-jax.experimental.mesh_utils.create_hybrid_device_mesh במקום ב-jax.experimental.mesh_utils.create_device_mesh.
אלה השינויים היחידים בקוד שצריך לבצע כשעוברים ל-Multislice. כדי להשיג ביצועים גבוהים, צריך למפות את DCN לצירים של מקביליות נתונים, מקביליות נתונים עם חלוקה מלאה או מקביליות צינורות. במאמר Sharding With Multislice for Maximum Performance (חלוקה למקטעים עם Multislice לביצועים מקסימליים) מוסבר ביתר פירוט על שיקולי ביצועים ועל אסטרטגיות של חלוקה למקטעים.
כדי לוודא שלקוד יש גישה לכל המכשירים, אפשר להצהיר ש-len(jax.devices()) שווה למספר השבבים בסביבת Multislice. לדוגמה, אם משתמשים בארבעה פלחים של v4-16, יש שמונה שבבים לכל פלח * 4 פלחים, ולכן הפונקציה len(jax.devices()) צריכה להחזיר 32.
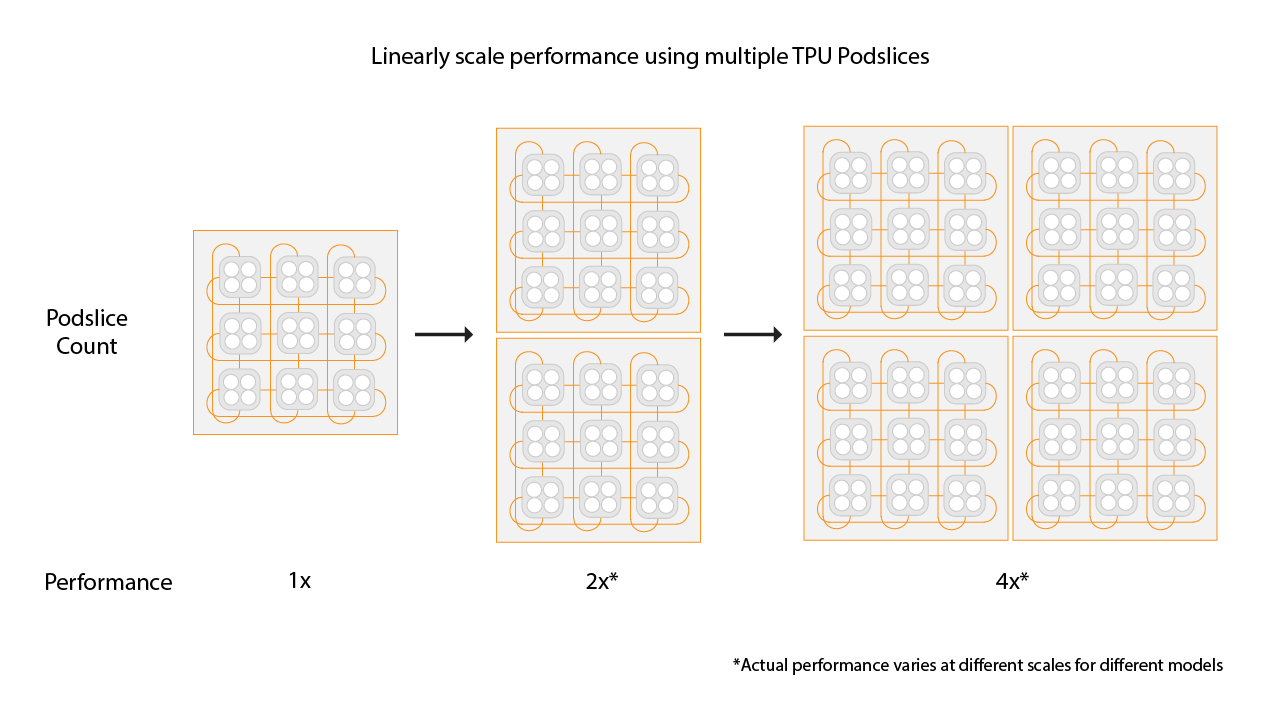
בחירת גודל הפרוסה בסביבות Multislice
כדי לקבל האצה ליניארית, מוסיפים פרוסות חדשות באותו גודל של הפרוסות הקיימות. לדוגמה, אם משתמשים בפרוסת v4-512, התכונה Multislice תשיג ביצועים טובים פי שניים בערך על ידי הוספה של פרוסת v4-512 שנייה והכפלת גודל האצווה הגלובלי. מידע נוסף זמין במאמר בנושא Sharding With Multislice for Maximum Performance.
הפעלת העבודה בכמה פרוסות
יש שלוש גישות שונות להרצת עומס עבודה מותאם אישית בסביבת Multislice:
- באמצעות סקריפט להרצת ניסויים,
multihost_runner.py - שימוש בסקריפט להרצת ייצור,
multihost_job.py - שימוש בגישה ידנית
סקריפט להפעלת ניסויים
הסקריפט multihost_runner.py מפיץ קוד לסביבת Multislice קיימת, מריץ את הפקודה בכל מארח, מעתיק את היומנים בחזרה ועוקב אחרי סטטוס השגיאה של כל פקודה. הסקריפט multihost_runner.py מתועד בקובץ ה-README של MaxText.
multihost_runner.py שומר על חיבורי SSH קבועים, ולכן הוא מתאים רק לניסויים קצרים יחסית בהיקף קטן. אפשר להתאים את השלבים במדריך multihost_runner.py להגדרת עומס העבודה והחומרה.
סקריפט להרצת ייצור
לגבי משימות ייצור שצריכות להיות עמידות בפני כשלים בחומרה ושיבושים אחרים, מומלץ לבצע אינטגרציה ישירות עם ה-API של Create Queued Resource. אפשר להשתמש ב-multihost_job.py כדוגמה מעשית שמפעילה את הקריאה ל-API של Created Queued Resource עם סקריפט ההפעלה המתאים כדי להריץ את האימון ולהמשיך אותו אחרי קדימות. הסקריפט multihost_job.py מתועד בקובץ MaxText README.
מכיוון ש-multihost_job.py צריך להקצות משאבים לכל הרצה, מחזור האיטרציה שלו לא מהיר כמו של multihost_runner.py.
גישה ידנית
מומלץ להשתמש ב-multihost_runner.py או ב-multihost_job.py או להתאים אותם כדי להריץ את עומס העבודה המותאם אישית בהגדרת Multislice. עם זאת, אם אתם מעדיפים להקצות ולנהל את הסביבה שלכם באמצעות פקודות QR ישירות, תוכלו לעיין במאמר בנושא ניהול סביבת Multislice.
ניהול סביבת Multislice
כדי להקצות ולנהל קודי QR באופן ידני בלי להשתמש בכלים שמופיעים במאגר MaxText, כדאי לקרוא את הקטעים הבאים.
יצירת משאבים בתור
gcloud
יוצרים בקשה למשאב בתור באמצעות הפקודה הבאה:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
לפני שבוחרים באפשרות --reserved,
--spot או במכסת ברירת המחדל לפי דרישה, צריך לוודא שיש לכם את המכסה המתאימה. מידע על סוגי המכסות זמין במאמר בנושא מדיניות מכסות.
curl
יוצרים קובץ בשם
queued-resource-req.jsonומעתיקים אליו את קובץ ה-JSON הבא.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
מחליפים את הערכים הבאים:
- your-project-number: מספר הפרויקט ב- Google Cloud
- your-zone: האזור שבו רוצים ליצור את המשאב בתור
- accelerator-type: הגרסה והגודל של פרוסה אחת. התכונה Multislice נתמכת רק ב-Cloud TPU v4 ובגרסאות TPU מאוחרות יותר.
- tpu-vm-runtime-version: גרסת זמן הריצה של TPU VM שרוצים להשתמש בה.
- your-network-name: אופציונלי, רשת שאליה יצורף המשאב בתור
- your-subnetwork-name: אופציונלי, רשת משנה שאליה יצורף המשאב בתור
- example-tag-1: מחרוזת תג שרירותית (אופציונלי)
- your-startup-script: סקריפט לטעינה בזמן ההפעלה שיפעל כשהמשאב בתור יוקצה
- slice-count: מספר פרוסות ה-TPU בסביבת Multislice
- your-queued-resource-id: המזהה שסופק על ידי המשתמש למשאב בתור
מידע נוסף על כל האפשרויות הזמינות מופיע במאמרי העזרה בנושא REST Queued Resource API.
כדי להשתמש בקיבולת של Spot, מחליפים את:
"guaranteed": { "reserved": true }עם"spot": {}כדי להשתמש בקיבולת ברירת המחדל לפי דרישה, צריך להסיר את השורה.
שולחים את בקשת יצירת המשאב שהוכנסה לתור עם מטען ייעודי (payload) בפורמט JSON:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
מחליפים את הערכים הבאים:
- your-project-id: מזהה הפרויקט ב- Google Cloud
- your-zone: האזור שבו רוצים ליצור את המשאב בתור
- your-queued-resource-id: המזהה שסופק על ידי המשתמש למשאב בתור
התגובה אמורה להיראות כך:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
כדי לקבל מידע על בקשת המשאב שנמצאת בתור, צריך להשתמש בערך GUID בסוף ערך המחרוזת של המאפיין name.
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על יצירת TPU.
בשדה שם, מזינים שם ל-TPU.
בתיבה תחום, בוחרים את התחום שבו רוצים ליצור את ה-TPU.
בתיבה TPU type, בוחרים סוג של מאיץ. סוג המאיץ מציין את הגרסה והגודל של Cloud TPU שרוצים ליצור. Multislice נתמך רק ב-Cloud TPU v4 ובגרסאות TPU מתקדמות יותר. מידע נוסף על סוגי המאיצים הנתמכים בכל גרסת TPU זמין במאמר בנושא גרסאות TPU.
בתיבה TPU software version (גרסת התוכנה של ה-TPU), בוחרים גרסת תוכנה. כשיוצרים מכונת TPU וירטואלית ב-Cloud TPU, גרסת התוכנה של ה-TPU מציינת את גרסת זמן הריצה של ה-TPU שמותקנת. מידע נוסף זמין במאמר בנושא גרסאות תוכנה של TPU.
לוחצים על המתג הפעלת הוספה לתור.
נותנים לבקשה שם בשדה Queued resource name.
לוחצים על תיבת הסימון Make this a Multislice TPU (הגדרת TPU מרובה).
בשדה מספר הפלחים מזינים את מספר הפלחים שרוצים ליצור.
לוחצים על יצירה כדי ליצור את בקשת המשאבים בתור.
אחזור הסטטוס של משאב שנמצא בתור
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
אם המשאב בתור נמצא במצב ACTIVE, הפלט ייראה כך:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
אם המשאב בתור נמצא במצב ACTIVE, הפלט ייראה כך:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על הכרטיסייה משאבים בתור.
לוחצים על השם של בקשת המשאב שנמצאת בתור.
אחרי שהוקצה לכם TPU, תוכלו גם לראות פרטים על בקשת המשאב שהוכנסה לתור. לשם כך, צריך להיכנס אל הדף TPUs, למצוא את ה-TPU וללחוץ על השם של בקשת המשאב התואמת שהוכנסה לתור.
בתרחיש נדיר, יכול להיות שהמשאב שהוספתם לתור יהיה במצב FAILED, בזמן שחלק מהפרוסות יהיו במצב ACTIVE. במקרה כזה, צריך למחוק את המשאבים שנוצרו ולנסות שוב בעוד כמה דקות, או לפנות אל Google Cloud התמיכה.
SSH והתקנת יחסי תלות
במאמר הרצת קוד JAX על חלקי TPU מוסבר איך להתחבר למכונות וירטואליות של TPU באמצעות SSH בחלק אחד. כדי להתחבר לכל מכונות ה-TPU בסביבת Multislice באמצעות SSH ולהתקין תלות, משתמשים בפקודה הבאה של gcloud:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
הפקודה gcloud שולחת את הפקודה שצוינה לכל העובדים והצמתים ב-QR באמצעות SSH. הפקודה מחולקת לקבוצות של ארבע ונשלחת בו-זמנית. קבוצת הפקודות הבאה נשלחת כשהקבוצה הנוכחית מסיימת את הביצוע. אם אחת מהפקודות נכשלת, העיבוד נפסק ולא נשלחים עוד אצווה. מידע נוסף מופיע בהפניית ה-API של משאבים בתור.
אם מספר הפרוסות שבהן אתם משתמשים חורג ממגבלת השרשור של המחשב המקומי (נקראת גם מגבלת אצווה), תיתקלו במצב של קיפאון. לדוגמה,
נניח שמגבלת האצווה במחשב המקומי היא 64. אם תנסו להריץ סקריפט אימון על יותר מ-64 פרוסות, למשל 100, פקודת ה-SSH תחלק את הפרוסות לקבוצות. הסקריפט יופעל על קבוצת הנתונים הראשונה של 64 פרוסות, וימתין לסיום הפעלת הסקריפטים לפני הפעלת הסקריפט על קבוצת הנתונים הנותרת של 36 פרוסות. עם זאת, אי אפשר להשלים את קבוצת 64 הפרוסות הראשונה עד ש-36 הפרוסות הנותרות יתחילו להריץ את הסקריפט, מה שגורם לקיפאון.
כדי למנוע את התרחיש הזה, אפשר להריץ את סקריפט ההדרכה ברקע בכל מכונת VM על ידי הוספת אמפרסנד (&) לפקודת הסקריפט שמציינים באמצעות הדגל --command. כשעושים את זה, אחרי שמפעילים את סקריפט האימון באצווה הראשונה של הפרוסות, השליטה חוזרת מיד לפקודת ה-SSH. אחרי זה, פקודת ה-SSH יכולה להתחיל להריץ את סקריפט האימון על קבוצת המשנה הנותרת של 36 פרוסות. כשמריצים את הפקודות ברקע, צריך להפנות את הזרמים stdout ו-stderr בצורה מתאימה. כדי להגדיל את רמת המקביליות באותו קוד QR, אפשר לבחור פרוסות ספציפיות באמצעות הפרמטר --node.
הגדרת רשת
כדי לוודא שפרוסות ה-TPU יכולות לתקשר ביניהן, צריך לבצע את השלבים הבאים.
צריך להתקין את JAX בכל פרוסה. מידע נוסף זמין במאמר בנושא הרצת קוד JAX בפרוסות TPU. צריך לוודא ש-len(jax.devices()) שווה למספר הצ'יפים בסביבת ה-Multislice. כדי לעשות זאת, מריצים את הפקודה הבאה בכל פרוסה:
$ python3 -c 'import jax; print(jax.devices())'
אם מריצים את הקוד הזה על ארבעה חלקי v4-16's, יש שמונה שבבים לכל חלק וארבעה חלקים, כך שצריך לקבל סך של 32 שבבים (מכשירים) מ-jax.devices().
הצגת רשימת המשאבים בתור
gcloud
אפשר לראות את הסטטוס של המשאבים בתור באמצעות הפקודה queued-resources list:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
הפלט אמור להיראות כך:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על הכרטיסייה משאבים בתור.
התחלת העבודה בסביבה שהוקצתה
אפשר להריץ עומסי עבודה באופן ידני על ידי התחברות לכל המארחים בכל פרוסה באמצעות SSH והרצת הפקודה הבאה בכל המארחים.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
איפוס תגובות מהירות
אפשר להשתמש ב-API ResetQueuedResource כדי לאפס את כל המכונות הווירטואליות ב-ACTIVE QR. איפוס המכונות הווירטואליות מוחק בכוח את הזיכרון של המכונה ומאפס את המכונה הווירטואלית למצב ההתחלתי שלה. כל הנתונים שמאוחסנים באופן מקומי יישארו ללא שינוי, וסקריפט לטעינה בזמן ההפעלה יופעל אחרי האיפוס. ה-API ResetQueuedResource יכול להיות שימושי כשרוצים להפעיל מחדש את כל ה-TPU. לדוגמה, אם האימון נתקע וקל יותר לאפס את כל מכונות ה-VM מאשר לבצע ניפוי באגים.
האיפוסים של כל המכונות הווירטואליות מתבצעים במקביל, והשלמת הפעולה נמשכת דקה עד שתיים.ResetQueuedResource כדי להפעיל את ה-API, משתמשים בפקודה הבאה:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
מחיקת משאבים בתור
כדי לשחרר משאבים בסיום סשן האימון, צריך למחוק את המשאב שנמצא בתור. תהליך המחיקה יימשך בין שתי לחמש דקות. אם אתם משתמשים ב-CLI של gcloud, אתם יכולים להריץ את הפקודה הזו ברקע באמצעות הדגל האופציונלי --async.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
המסוף
נכנסים לדף TPUs במסוף Google Cloud .
לוחצים על הכרטיסייה משאבים בתור.
מסמנים את התיבה לצד בקשת המשאב שנמצאת בתור.
לוחצים על מחיקה.
שחזור אוטומטי של כשלים
במקרה של שיבוש, Multislice מציע תיקון של הפרוסה המושפעת ללא התערבות, ואיפוס של כל הפרוסות לאחר מכן. הפרוסה המושפעת מוחלפת בפרוסה חדשה, והפרוסות הבריאות שנותרו מאופסות. אם אין קיבולת זמינה להקצאת פרוסת החלפה, האימון נפסק.
כדי להמשיך את האימון באופן אוטומטי אחרי הפרעה, צריך לציין סקריפט לטעינה בזמן ההפעלה שבודק את נקודות הביקורת האחרונות שנשמרו וטוען אותן. סקריפט לטעינה בזמן ההפעלה שלכם מופעל אוטומטית בכל פעם שמקצים מחדש פרוסה (slice) או מאפסים מכונה וירטואלית. מציינים סקריפט הפעלה במטען הייעודי (payload) של JSON ששולחים ל-API של בקשת יצירת קוד QR.
הסקריפט הבא לטעינה בזמן ההפעלה (שמשמש ביצירת קודי QR) מאפשר לכם להתאושש אוטומטית מכשלים ולהמשיך את האימון מנקודות ביקורת שמאוחסנות בקטגוריה של Cloud Storage במהלך אימון MaxText:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
לפני שמנסים את הפעולה הזו, צריך לשכפל את מאגר MaxText.
יצירת פרופילים וניפוי באגים
הפרופילים זהים בסביבות של פרוסות יחידות ובסביבות של פרוסות מרובות. מידע נוסף זמין במאמר בנושא יצירת פרופילים של תוכניות JAX.
אופטימיזציה של ההדרכה
בקטעים הבאים מוסבר איך לבצע אופטימיזציה של אימון Multislice.
חלוקה למקטעים באמצעות Multislice לביצועים מקסימליים
כדי להשיג ביצועים מקסימליים בסביבות Multislice, צריך לחשוב איך לבצע שרדינג בכמה פרוסות. בדרך כלל יש שלוש אפשרויות (מקבילות נתונים, מקבילות נתונים עם חלוקה מלאה ומקבילות צינורות). אנחנו לא ממליצים על חלוקת ההפעלות בין הממדים של המודל (לפעמים נקראת מקביליות טנסור) כי היא דורשת רוחב פס גדול מדי בין החלקים. בכל האסטרטגיות האלה, אפשר להשתמש באותה אסטרטגיית חלוקה לשברים בתוך פרוסה שעבדה בשבילכם בעבר.
מומלץ להתחיל עם מקביליות נתונים טהורה. שימוש במקביליות נתונים עם חלוקה מלאה לשברים (fully-sharded data parallelism) יכול לעזור לכם לפנות מקום בזיכרון. החיסרון הוא שהתקשורת בין הפרוסות מתבצעת באמצעות רשת ה-DCN, ולכן עומס העבודה יהיה איטי יותר. משתמשים במקביליות של צינורות רק כשצריך, על סמך גודל האצווה (כפי שמנותח בהמשך).
מתי כדאי להשתמש במקביליות נתונים
מקביליות נתונים טהורה תפעל היטב במקרים שבהם יש עומס עבודה שפועל היטב, אבל רוצים לשפר את הביצועים שלו על ידי שינוי קנה המידה בכמה פרוסות.
כדי להשיג שינוי קנה מידה חזק בכמה פרוסות, כמות הזמן שנדרשת לביצוע all-reduce ב-DCN צריכה להיות קטנה מכמות הזמן שנדרשת לביצוע מעבר לאחור. DCN משמש לתקשורת בין פרוסות והוא גורם מגביל בנפח העבודה.
כל שבב TPU מדגם v4 מבצע עד 275 * 1012 FLOPS בשנייה.
יש ארבעה שבבים לכל מארח TPU, ולכל מארח יש רוחב פס מקסימלי של 50Gbps.
כלומר, העוצמה האריתמטית היא 4 * 275 * 1012 FLOPS / 50 Gbps = 22000 FLOPS / bit.
המודל ישתמש ברוחב פס של 32 עד 64 ביטים של DCN לכל פרמטר לכל שלב. אם משתמשים בשני פלחים, המודל ישתמש ב-32 ביטים של רוחב פס DCN. אם משתמשים ביותר משני פלחים, הקומפיילר יבצע פעולת צמצום מלאה של ערבוב כללי, ותשתמשו ברוחב פס של עד 64 ביט של DCN לכל פרמטר לכל שלב. כמות ה-FLOPS שנדרשת לכל פרמטר משתנה בהתאם למודל. באופן ספציפי, במודלים של שפה שמבוססים על טרנספורמרים, מספר ה-FLOPS שנדרש להעברה קדימה ולהעברה אחורה הוא בערך 6 * B * P, כאשר:
- B הוא גודל האצווה בטוקנים
- P הוא מספר הפרמטרים
מספר ה-FLOPS לכל פרמטר הוא 6 * B ומספר ה-FLOPS לכל פרמטר במהלך המעבר לאחור הוא 4 * B.
כדי להבטיח שינוי קנה מידה יעיל בכמה פלחים, צריך לוודא שעוצמת הפעולה עולה על העוצמה האריתמטית של חומרת ה-TPU. כדי לחשב את עוצמת הפעולה, מחלקים את מספר ה-FLOPS לכל פרמטר במהלך המעבר לאחור ברוחב הפס של הרשת (בביטים) לכל פרמטר לכל שלב:
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
לכן, במודל שפה שמבוסס על טרנספורמר, אם משתמשים בשני פלחים:
Operational intensity = 4 * B / 32
אם משתמשים ביותר משני פלחים: Operational intensity = 4 * B/64
ההצעה היא להשתמש בגודל אצווה מינימלי של 176,000 עד 352,000 עבור מודלים של שפה שמבוססים על Transformer. מכיוון שרשת ה-DCN יכולה להפיל מנות נתונים לזמן קצר, מומלץ לשמור על מרווח שגיאה משמעותי, ולפרוס מקביליות נתונים רק אם גודל האצווה לכל Pod הוא לפחות 350,000 (שני Pods) עד 700,000 (הרבה Pods).
בארכיטקטורות אחרות של מודלים, תצטרכו להעריך את זמן הריצה של המעבר לאחור לכל פרוסה (על ידי מדידת הזמן באמצעות פרופילר או על ידי ספירת FLOPS). אחר כך תוכלו להשוות את זה לזמן הריצה הצפוי כדי לצמצם את כל ה-DCN ולקבל הערכה טובה לגבי מידת ההתאמה של מקביליות נתונים לצרכים שלכם.
מתי כדאי להשתמש בנתונים מקבילים עם חלוקה מלאה (FSDP)
מקביליות נתונים עם חלוקה מלאה (FSDP) משלבת מקביליות נתונים (חלוקת הנתונים בין הצמתים) עם חלוקת המשקלים בין הצמתים. בכל פעולה במעברים קדימה ואחורה, המשקלים נאספים כך שלכל פרוסה יש את המשקלים שהיא צריכה. במקום לסנכרן את הגרדיאנטים באמצעות all-reduce, הגרדיאנטים מפוזרים (reduce-scattered) כשהם נוצרים. כך, כל פרוסה מקבלת רק את הגרדיאנטים של המשקלים שהיא אחראית להם.
בדומה ל-data parallelism, FSDP ידרוש שינוי של גודל האצווה הגלובלי באופן לינארי בהתאם למספר הפרוסות. העומס על הזיכרון יפחת ככל שתגדילו את מספר הפרוסות. הסיבה לכך היא שמספר המשקלים ומצב האופטימיזציה לכל פרוסה קטן יותר, אבל זה קורה במחיר של עלייה בתנועת הרשת והסיכוי הגבוה יותר לחסימה בגלל עיכוב בחישוב הממוצע.
בפועל, FSDP על פני פרוסות הוא הכי טוב אם מגדילים את גודל האצווה לכל פרוסה, מאחסנים יותר הפעלות כדי למזער את החומרים מחדש במהלך המעבר לאחור או מגדילים את מספר הפרמטרים ברשת נוירונים.
הפעולות all-gather ו-all-reduce ב-FSDP דומות לאלה ב-DP, כך שאפשר לקבוע אם עומס העבודה ב-FSDP מוגבל על ידי ביצועי ה-DCN באותו אופן שמתואר בקטע הקודם.
מתי כדאי להשתמש בהרצת תהליכים מקבילית בצינור
השימוש בטכניקת הצינורות המקבילים רלוונטי כשרוצים להשיג ביצועים גבוהים באמצעות אסטרטגיות מקביליות אחרות שדורשות גודל אצווה גלובלי גדול יותר מגודל האצווה המקסימלי המועדף. מקביליות בצינור מאפשרת לפרוסות שמרכיבות צינור "לשתף" אצווה. עם זאת, יש שני חסרונות משמעותיים לשימוש במקביליות של צינורות:
- היא גורמת ל'בועת פייפליין' שבה השבבים בלי פעילות כי הם מחכים לנתונים.
- הוא דורש מיקרו-אצווה, שמקטינה את גודל האצווה האפקטיבי, את עוצמת החישוב ובסופו של דבר את ניצול ה-FLOP של המודל.
כדאי להשתמש במקביליות של צינורות רק אם אסטרטגיות המקביליות האחרות דורשות גודל אצווה גלובלי גדול מדי. לפני שמנסים מקביליות של צינורות, כדאי לבצע ניסוי כדי לבדוק באופן אמפירי אם ההתכנסות לכל דגימה מאטה בגודל האצווה שנדרש כדי להשיג ביצועים גבוהים של FSDP. בדרך כלל, FSDP משיג ניצול גבוה יותר של FLOP במודל, אבל אם ההתכנסות לכל דגימה מאטה ככל שגודל האצווה גדל, יכול להיות שעדיין כדאי לבחור במקביליות של צינורות. רוב עומסי העבודה יכולים להתמודד עם גדלים גדולים מספיק של אצווה, כך שהם לא נהנים מביצוע מקבילי של צינורות, אבל יכול להיות שעומס העבודה שלכם שונה.
אם יש צורך בהקבלת צינורות, מומלץ לשלב אותה עם הקבלת נתונים או עם FSDP. כך תוכלו למזער את עומק צינור העיבוד ולהגדיל את גודל האצווה לכל צינור עיבוד, עד שזמן האחזור של DCN יהפוך לגורם פחות משמעותי בנפח התפוקה. לדוגמה, אם יש לכם N פרוסות, כדאי להשתמש בצינורות (pipeline) עם עומק 2 ו-N/2 רפליקות של מקביליות נתונים, ואז בצינורות עם עומק 4 ו-N/4 רפליקות של מקביליות נתונים, ולהמשיך באותו אופן עד שהגודל של כל אצווה בצינור יהיה מספיק גדול כדי שהמערכת תוכל להסתיר את פעולות ה-DCN מאחורי החישובים במעבר לאחור. כך תוכלו לצמצם את ההאטה שנובעת משימוש במקביל בצינורות, ועדיין להגדיל את קנה המידה מעבר למגבלת גודל האצווה הגלובלית.
שיטות מומלצות לשימוש ב-Multislice
בקטעים הבאים מפורטות שיטות מומלצות לאימון Multislice.
טעינת נתונים
במהלך האימון אנחנו טוענים שוב ושוב אצוות ממערך נתונים כדי להזין אותן למודל. כדי למנוע מצב שבו יחידות ה-TPU לא מקבלות מספיק עבודה, חשוב להשתמש בכלי יעיל לטעינת נתונים אסינכרוני שמחלק את האצווה בין המארחים. בטוען הנתונים הנוכחי ב-MaxText, כל מארח טוען קבוצת משנה שווה של הדוגמאות. הפתרון הזה מתאים לטקסט, אבל נדרש פיצול מחדש בתוך המודל. בנוסף, MaxText עדיין לא מציע צילום תמונת מצב דטרמיניסטי, שיאפשר לאיטרטור של הנתונים לטעון את אותם נתונים לפני ואחרי ההדחה.
Checkpointing
ספריית ה-checkpointing Orbax מספקת פרימיטיבים ל-checkpointing של JAX PyTrees לאחסון מקומי או לאחסון Google Cloud .
אנחנו מספקים שילוב לדוגמה עם שמירת נקודות ציון סינכרוניות ב-MaxText בכתובת checkpointing.py.
הגדרות נתמכות
בקטעים הבאים מתוארים הצורות הנתמכות של פרוסות, תזמור, מסגרות והקבלת נתונים ב-Multislice.
צורות
לכל הפרוסות צריכה להיות צורה זהה (לדוגמה, אותו AcceleratorType).
צורות פרוסות הטרוגניות לא אפשריות.
תזמור
יש תמיכה בתזמור ב-GKE. מידע נוסף זמין במאמר בנושא TPU ב-GKE.
Frameworks
התכונה Multislice תומכת רק בעומסי עבודה של JAX ו-PyTorch.
מקביליות
מומלץ למשתמשים לבדוק את Multislice עם מקביליות נתונים. כדי לקבל מידע נוסף על הטמעה של מקביליות צינורות באמצעות Multislice, אפשר לפנות אלGoogle Cloud נציג החשבון.
תמיכה ומשוב
נשמח לקבל משוב! כדי לשתף משוב או לבקש תמיכה, אפשר לפנות אלינו באמצעות טופס התמיכה או המשוב של Cloud TPU.