
Google Cloud Observability 包含觀測服務,可協助您瞭解應用程式 (包括代理程式應用程式) 的行為、健康狀態和效能。瞭解應用程式的行為方式和元件的連線方式,有助於預測、識別及因應非預期變更,並迅速採取有效措施。
這份文件包含下列資訊:
- 定義「可觀測性」、「代理程式可觀測性」和「應用程式可觀測性與 APM」等字詞。
- 說明可觀測性服務在開發及維護可靠應用程式時的優點。
- 瞭解 Google Cloud Observability 如何協助您監控及維護應用程式和基礎架構的健康狀態。
- 請按照這篇文章的步驟,開始在Google Cloud中使用可觀測性功能。
觀測能力
可觀測性是一種全方位的做法,可收集及分析遙測資料,協助您瞭解應用程式 (包括代理程式應用程式) 的狀態及其作業環境。遙測資料包括記錄資料、指標資料和追蹤記錄資料。也可能包含應用程式產生的其他資料,例如提示和回覆。遙測資料可提供您所需的資訊,瞭解應用程式的健康狀態和效能。
- 指標資料
- 指標資料是系統定期測量的健康狀態或效能相關數值資料,例如 CPU 使用率和要求延遲時間。如果指標資料出現非預期的變化,可能表示有問題需要調查。您也可以長期分析模式,瞭解用量模式並預測資源需求。
- 記錄檔資料
記錄檔是系統或應用程式活動在一段時間內產生的記錄。每份記錄檔都是記錄項目的集合,並附上時間戳記,每個記錄項目都說明特定事件。
記錄資料通常包含豐富的詳細資訊,有助於瞭解應用程式特定部分的事件。不過,記錄資料無法有效顯示一個應用程式元件的變更,與其他元件活動的關聯。追蹤資料可以消弭這個落差。
- 追蹤資料
追蹤記錄代表要求在分散式應用程式元件間的路徑。也就是說,每項追蹤記錄都代表單一端對端作業。由於追蹤記錄是由「spans」(時距) 組成,而時距是單一函式或作業的記錄,因此您可以追蹤要求流程並檢查延遲時間資料。這項資訊有助於找出問題的根本原因。
如果是代理程式應用程式,追蹤記錄會擷取代理程式執行的動作。 舉例來說,追蹤記錄可以擷取 MCP 呼叫。
- 其他資料
您可以分析記錄資料、指標資料和追蹤資料,以及其他相關資訊,進一步取得洞察資料。舉例來說,指出事件嚴重程度的標籤,或記錄檔資料中的客戶 ID,可提供有助於疑難排解和偵錯的背景資訊。
代理可觀測性
代理程式可觀測性是指瞭解軟體代理程式 (尤其是使用大型語言模型 (LLM) 建構的 AI 輔助代理程式) 內部狀態和行為的方法。AI 代理具有非確定性和複雜性,因此,可觀測性對於瞭解、偵錯、評估及提升效能、安全性和可靠性至關重要。
Google Cloud 支援應用程式可觀測性,提供應用程式監控功能,可建立資訊主頁,顯示遙測資料、AI 資源指標資料,以及未結事件等資訊。詳情請參閱本文件的「代理程式和應用程式可觀測性 Google Cloud」一節。
應用程式可觀測性和 APM
應用程式效能監控 (APM) 可監控、診斷及管理軟體應用程式 (包括代理程式應用程式) 的效能、可用性和使用者體驗。APM 系統通常會提供資訊主頁,顯示遙測資料和監控遙測資料的服務。這些系統可協助您找出故障。
應用程式觀測功能會使用遙測資料產生洞察資訊,協助您瞭解應用程式的行為。
Google Cloud 支援應用程式可觀測性,提供應用程式監控功能,可建立資訊主頁,顯示遙測資料、AI 資源指標資料,以及未結事件等資訊。詳情請參閱本文件的「代理程式和應用程式可觀測性 Google Cloud」一節。
可觀測性服務
觀測能力服務會收集、分析及關聯遙測資料,例如記錄資料、指標資料和追蹤記錄資料。這些功能可協助您維持應用程式的穩定性:
- 主動偵測問題,避免使用者受到影響。
- 排解已知和新問題。
- 在開發期間偵錯應用程式。
- 瞭解應用程式變更的影響。
- 透過資料探索發掘新的洞察資訊。
如要進一步瞭解可靠性做法,包括與可觀測性相關的原則和做法,請參閱《網站可靠性工程:Google 如何執行正式版群組系統》一書。主題包括監控分散式系統、快訊和疑難排解。
Google Cloud Observability
Google Cloud Observability 服務可協助您收集、分析及關聯應用程式和基礎架構的遙測資料。這些服務也提供內建預設值,可協助您順利上手。舉例來說,應用程式監控會為應用程式中心註冊的應用程式、服務和工作負載建立資訊主頁和拓撲地圖。
自動收集遙測資料
建立 Google Cloud 專案時,系統會依預設啟用「監控」、「記錄」和「追蹤記錄」服務。這些服務提供核心功能,可收集、分析及以圖表呈現遙測資料:
- 自動收集大多數 Google Cloud 服務的遙測資料。
- 自動收集大多數服務的稽核記錄。 Google Cloud
- 提供視覺化服務,包括資訊主頁和遙測探索工具,方便您查看及檢查遙測資料。舉例來說,您可以使用追蹤記錄探索器查看追蹤記錄、範圍和中繼資料,包括多模態提示和回覆。詳情請參閱「查詢及查看遙測資料」。
- 為記錄資料和追蹤資料提供以 SQL 為基礎的分析服務。舉例來說,您可以使用 BigQuery,將記錄檔資料中的網址與已知惡意網址的公開資料集進行比較。
- 提供應用程式監控和遙測監控功能。舉例來說,您可以建立快訊政策,在記錄資料或指標資料符合指定條件時收到通知。您也可以使用綜合監控測試應用程式的效能。
從已插碼的應用程式收集遙測資料。檢測機制:您在應用程式中加入的程式碼,用於發出遙測資料。
如要檢測應用程式,建議您使用開放原始碼的廠商中立檢測架構 (例如 OpenTelemetry),而非廠商和產品專屬的 API 或用戶端程式庫。如要瞭解這些架構,請參閱「 檢測和觀測能力」和「選擇檢測方法」。
代理程式和應用程式可觀測性
應用程式監控 Google Cloud 提供代理程式觀測和應用程式觀測功能。這項服務提供資訊主頁和拓撲地圖,可協助您瞭解 App Hub 應用程式、服務和工作負載的健康狀態和效能。此外,也會產生並顯示 AI 資源的錯誤率和權杖用量等指標。如要產生這些指標,應用程式監控會使用應用程式專屬標籤和事件,按照 OpenTelemetry 生成式 AI 語意慣例篩選及彙整追蹤資料。
如要觀察代理,建議使用 Agent Development Kit (ADK) 架構建構代理。由於 ADK 採用 OpenTelemetry,因此 ADK 產生的遙測資料會符合 OpenTelemetry GenAI 語意慣例。
如要偵錯失敗情形、監控費用或分析代理程式行為 (包括來自 Gemini Enterprise 代理程式平台、代理程式閘道和 Model Armor 代理程式的行為),您需要記錄、指標和追蹤資料:
- 記錄檔會提供事件和錯誤的相關資訊。
- 您可以透過指標監控延遲和權杖用量。
- 追蹤記錄提供執行路徑的相關資訊,並經過分析,可得出模型呼叫次數或權杖總用量等指標。這些衍生指標可讓您掌握代理程式的效能和行為。詳情請參閱「查看 AI 資源」一文。
- 您可以透過 Gen AI Evaluation Service,使用提示和回覆資料評估代理程式品質和決策。
應用程式的「應用程式監控」資訊主頁會顯示應用程式的服務和工作負載清單,例如 Gemini Enterprise 應用程式、Gemini Enterprise Agent Platform 代理程式和 MCP 伺服器:
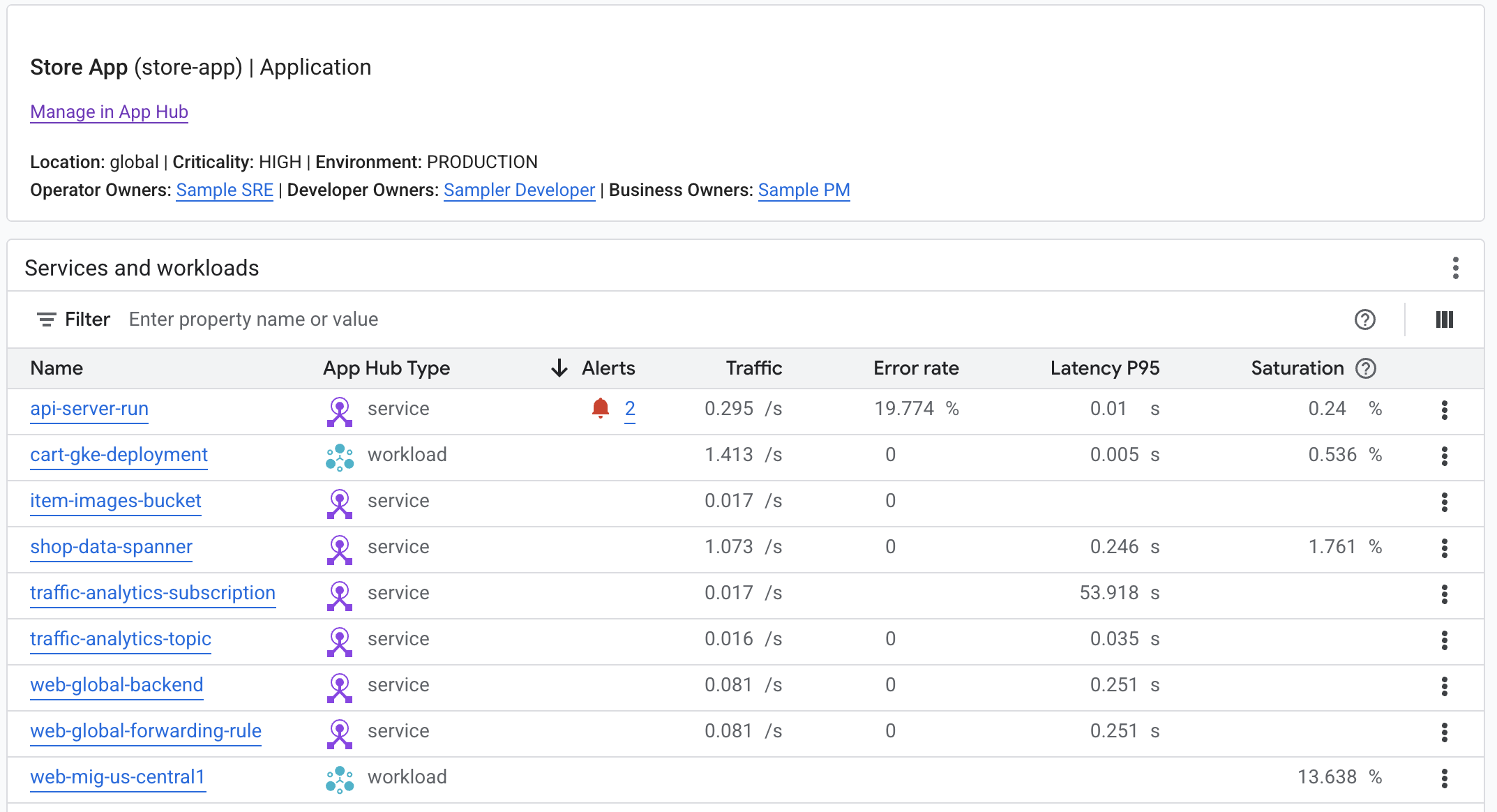
您可以透過基礎架構類型或 App Hub 功能類型,識別代理程式服務和工作負載。功能類型欄預設為隱藏。
如需程式碼範例,請參閱下列內容:
支援找出錯誤
Error Reporting 會分析 Cloud Logging 中的記錄項目,找出錯誤。Error Reporting 發現錯誤時,會註解相關聯的記錄檔項目,並建立錯誤群組。您可以探索這些錯誤群組,找出錯誤的原因和記錄。
剖析支援
Cloud Profiler 可分析應用程式的 CPU 和記憶體用量,找出提升效能的機會。
開始使用
本節說明如何熟悉 Google Cloud的可觀測性功能。
嘗試快速入門導覽課程
試用快速入門導覽課程,熟悉可用的服務。
查看自動收集的資料
大多數 Google Cloud 服務會自動產生記錄檔資料和指標資料。也就是說,您無須額外設定,即可開始查看支援 Google Cloud 服務的部分可觀測性資料。
- 部分 Google Cloud 服務 (例如 Google Kubernetes Engine (GKE)、Compute Engine 和 Cloud SQL) 會在 Google Cloud 控制台中提供預設資訊主頁,方便您查看服務相關的觀測資料。
- Compute Engine、GKE 和 Cloud Run 預設會產生系統指標資料和記錄檔資料。設定收集其他資料。
- Cloud Run 函式和 App Engine 會自動產生指標資料、記錄資料和追蹤記錄資料。
您也可以在 Metrics Explorer 中繪製收集到的指標資料圖表,在 Logs Explorer 中查看記錄資料,或在 Trace 中查看追蹤記錄資料。如要一併查看相關資料,請建立自訂資訊主頁。舉例來說,您可以建立資訊主頁,其中包含虛擬機器的記錄資料、效能指標資料和快訊政策。
設定 Compute Engine VM,收集額外資料
根據預設,Compute Engine VM 只會收集基本系統指標資料和記錄資料。不過,您可以安裝作業套件代理程式,從 Compute Engine 執行個體和應用程式收集其他遙測資料,以進行疑難排解、效能監控及傳送快訊。Ops Agent 並非具備代理功能的應用程式。而是收集遙測資料的決定性軟體。
- 自動收集主機指標資料,例如 CPU、GPU、記憶體和程序指標資料。
- 自動收集系統記錄資料,例如 Linux VM 的 syslog 和 Windows VM 的 Windows 事件記錄。
- 您可以透過下列方式觀察應用程式:
- 整合第三方應用程式,以便搭配熱門軟體使用,例如 Postgres、MongoDB 和 Java 虛擬機器等。這些整合功能包括預先設定的資訊主頁和快訊政策。
- Prometheus 指標資料
- OpenTelemetry Protocol (OTLP) 指標資料和追蹤記錄資料
- 應用程式記錄資料
- 如需收集到的遙測資料摘要,請參閱 Ops Agent 總覽。
設定 GKE 叢集以收集其他資料
根據預設,GKE 叢集會將系統記錄資料和系統指標資料傳送至 Logging 和 Monitoring。Google Cloud Managed Service for Prometheus 會處理第三方指標資料和使用者定義指標資料的收集作業。
- 使用可觀測性指標資料套件,瞭解應用程式和叢集資源的狀態。舉例來說,控制層指標資料可用於建立服務等級目標,監控服務可用性和延遲情形。
- 監控第三方應用程式,例如 Postgres、MongoDB 和 Redis。這些整合服務提供預先設定的資訊主頁和快訊政策。
設定 Cloud Run 以收集自訂資料
如果您有寫入 Prometheus 指標資料的 Cloud Run 服務,則可以使用 Prometheus 補充資訊將指標資料傳送至 Cloud Monitoring。
如果 Cloud Run 服務改為寫入 OTLP 指標資料,則可以使用 OpenTelemetry Sidecar。如需範例,請參閱使用 Sidecar 收集 OTLP 指標資料的教學課程。