
Google Cloud Observability include servizi di osservabilità che ti aiutano a comprendere il comportamento, l'integrità e le prestazioni delle tue applicazioni, incluse quelle agentiche. Comprendere il comportamento delle applicazioni e il modo in cui i componenti si connettono ti aiuta ad anticipare, identificare e rispondere rapidamente ed efficacemente ai cambiamenti imprevisti.
Questo documento include le seguenti informazioni:
- Definizioni di termini come osservabilità, osservabilità dell'agente e osservabilità dell'applicazione e APM.
- I vantaggi dei servizi di osservabilità per lo sviluppo e la manutenzione di applicazioni affidabili.
- In che modo Google Cloud Observability ti aiuta a monitorare e mantenere l'integrità di applicazioni e infrastrutture.
- Passaggi per iniziare a utilizzare l'osservabilità in Google Cloud.
Osservabilità
L'osservabilità è un approccio completo alla raccolta e all'analisi dei dati di telemetria per aiutarti a comprendere lo stato delle tue applicazioni, incluse quelle agentiche, e del loro ambiente operativo. I dati di telemetria includono dati di log, dati delle metriche e dati di traccia. Può includere anche altri dati generati dalle tue applicazioni, come prompt e risposte. I dati di telemetria forniscono le informazioni necessarie per comprendere l'integrità e le prestazioni delle tue applicazioni.
- Dati delle metriche
- I dati delle metriche sono dati numerici relativi all'integrità o alle prestazioni che il sistema misura a intervalli regolari, ad esempio l'utilizzo della CPU e la latenza delle richieste. Modifiche impreviste ai dati delle metriche potrebbero indicare un problema che devi esaminare. Nel tempo, puoi anche analizzare i pattern per comprendere i pattern di utilizzo e anticipare le esigenze di risorse.
- Dati di log
Un log è un record generato dell'attività di sistema o dell'applicazione nel tempo. Ogni log è una raccolta di voci di log con timestamp e ogni voce di log descrive un evento specifico.
I dati di log spesso contengono informazioni dettagliate e complete che ti aiutano a capire cosa è successo in una parte specifica della tua applicazione. Tuttavia, i dati di log non mostrano in modo efficace la relazione tra una modifica in un componente dell'applicazione e l'attività in altri componenti. I dati di Trace possono colmare questa lacuna.
- Dati di Trace
Una traccia rappresenta il percorso di una richiesta nei componenti della tua applicazione distribuita. ovvero ogni traccia rappresenta una singola operazione end-to-end. Poiché le tracce sono composte da intervalli, che sono record per una singola funzione o operazione, ti consentono di seguire il flusso delle richieste ed esaminare i dati sulla latenza. Queste informazioni possono aiutarti a identificare la causa principale di un problema.
Per le applicazioni con agenti, le tracce acquisiscono le azioni eseguite dall'agente. Ad esempio, una traccia può acquisire le chiamate MCP.
- Altri dati
Puoi ottenere ulteriori approfondimenti analizzando i dati dei log, i dati delle metriche e i dati di traccia insieme ad altre informazioni pertinenti. Ad esempio, un'etichetta che indica la gravità di un incidente o un ID cliente nei dati di log fornisce un contesto utile per la risoluzione dei problemi e il debug.
Osservabilità dell'agente
L'osservabilità degli agenti si riferisce ai metodi per comprendere lo stato interno e il comportamento degli agenti software, in particolare degli agenti basati sull'AI creati utilizzando modelli linguistici di grandi dimensioni (LLM). Gli agenti AI sono non deterministici e complessi. Pertanto, l'osservabilità è fondamentale per comprendere, eseguire il debug, valutare e migliorare le loro prestazioni, sicurezza e affidabilità.
Google Cloud supporta l'osservabilità delle applicazioni con Application Monitoring, che crea dashboard che mostrano dati di telemetria, dati delle metriche delle risorse AI e informazioni come gli incidenti aperti. Per saperne di più, consulta la sezione Osservabilità di agenti e applicazioni in Google Cloud di questo documento.
Osservabilità delle applicazioni e APM
Il monitoraggio delle prestazioni delle applicazioni (APM) monitora, diagnostica e gestisce le prestazioni, la disponibilità e l'esperienza utente delle applicazioni software, incluse le applicazioni con agenti. Un sistema APM in genere fornisce dashboard che mostrano i dati di telemetria e i servizi che li monitorano. Questi sistemi ti aiutano a identificare gli errori.
L'osservabilità delle applicazioni utilizza i dati di telemetria per generare approfondimenti che ti aiutano a comprendere il comportamento delle tue applicazioni.
Google Cloud supporta l'osservabilità delle applicazioni con Application Monitoring, che crea dashboard che mostrano dati di telemetria, dati delle metriche delle risorse AI e informazioni come gli incidenti aperti. Per saperne di più, consulta la sezione Osservabilità di agenti e applicazioni in Google Cloud di questo documento.
Servizi di osservabilità
I servizi di osservabilità raccolgono, analizzano e correlano i dati di telemetria, come log, metriche e tracce. Forniscono le seguenti funzionalità per aiutarti a mantenere l'affidabilità dell'applicazione:
- Rileva in modo proattivo i problemi prima che si ripercuotano sugli utenti.
- Risolvi i problemi noti e quelli nuovi.
- Eseguire il debug delle applicazioni durante lo sviluppo.
- Comprendere l'impatto delle modifiche alle tue applicazioni.
- Scopri nuovi insight tramite l'esplorazione dei dati.
Per saperne di più sulle pratiche di affidabilità, inclusi principi e pratiche relativi all'osservabilità, leggi il libro Site Reliability Engineering: How Google Runs Production Systems. Gli argomenti includono Monitoraggio dei sistemi distribuiti, Avvisi e Risoluzione dei problemi.
Google Cloud Observability
I servizi di Google Cloud Observability ti aiutano a raccogliere, analizzare e correlare i dati di telemetria, sia dalle tue applicazioni sia dall'infrastruttura sottostante. Questi servizi forniscono anche valori predefiniti integrati per aiutarti a iniziare. Ad esempio, Application Monitoring crea dashboard e mappe della topologia per le applicazioni, i servizi e i workload registrati in App Hub.
Raccolta automatica dei dati di telemetria
Monitoring, Logging e Trace sono servizi abilitati per impostazione predefinita quando crei un progetto Google Cloud . Questi servizi forniscono le funzionalità di base per raccogliere, analizzare e visualizzare i dati di telemetria:
- Raccogli automaticamente i dati di telemetria per la maggior parte dei servizi Google Cloud .
- Raccogli automaticamente i log di controllo per la maggior parte dei servizi Google Cloud.
- Fornire servizi di visualizzazione, inclusi esploratori di dashboard e telemetria, che ti consentono di visualizzare ed esaminare i dati di telemetria. Ad esempio, l'Esplora tracce ti consente di visualizzare tracce, intervalli e metadati, inclusi prompt e risposte multimodali. Per maggiori informazioni, vedi Eseguire query e visualizzare i dati di telemetria.
- Fornisci servizi di analisi basati su SQL per i dati di log e di traccia. Ad esempio, puoi utilizzare BigQuery per confrontare gli URL nei dati di log con un set di dati pubblico di URL dannosi noti.
- Fornire il monitoraggio delle applicazioni e della telemetria. Ad esempio, puoi creare criteri di avviso che ti avvisano quando i dati di log o delle metriche soddisfano le condizioni che specifichi. Puoi anche utilizzare il monitoraggio sintetico per testare le prestazioni delle tue applicazioni.
Raccogli i dati di telemetria dalle applicazioni instrumentate. L'instrumentazione è un codice che aggiungi a un'applicazione per emettere dati di telemetria.
Per instrumentare l'applicazione, ti consigliamo di utilizzare un framework di instrumentazione open source indipendente dal fornitore, come OpenTelemetry, anziché API o librerie client specifiche del fornitore e del prodotto. Per informazioni su questi framework, vedi Instrumentazione e osservabilità e Scegliere un approccio di instrumentazione.
Osservabilità di agenti e applicazioni
Application Monitoring in Google Cloud fornisce l'osservabilità sia dell'agente che dell'applicazione. Questo servizio fornisce dashboard e mappe della topologia che ti consentono di comprendere l'integrità e le prestazioni di applicazioni, servizi e carichi di lavoro di App Hub. Genera e mostra anche metriche come percentuali di errore e utilizzo dei token per le risorse di AI. Per generare queste metriche, Application Monitoring filtra e aggrega i dati di traccia utilizzando etichette ed eventi specifici dell'applicazione che seguono le convenzioni semantiche OpenTelemetry GenAI.
Per l'osservabilità degli agenti, ti consigliamo di crearli con il framework Agent Development Kit (ADK). Poiché ADK si basa su OpenTelemetry, la telemetria generata da ADK è coerente con le convenzioni semantiche di OpenTelemetry GenAI.
Per eseguire il debug degli errori, monitorare i costi o analizzare il comportamento degli agenti, inclusi quelli di Gemini Enterprise Agent Platform, Agent Gateway e Model Armor, sono necessari dati di log, metriche e tracce:
- I log forniscono informazioni su eventi ed errori.
- Le metriche ti consentono di monitorare la latenza e l'utilizzo dei token.
- Le tracce forniscono informazioni sui percorsi di esecuzione e vengono analizzate per derivare metriche come il numero di chiamate al modello o l'utilizzo totale dei token. Queste metriche derivate forniscono visibilità sul rendimento e sul comportamento degli agenti. Per maggiori informazioni, consulta Visualizzare le risorse AI.
- I dati di prompt e risposta ti consentono di valutare la qualità e il processo decisionale dell'agente utilizzando Gen AI evaluation service.
La dashboard Monitoraggio applicazioni per un'applicazione mostra un elenco dei servizi e dei carichi di lavoro dell'applicazione, ad esempio app Gemini Enterprise, agenti della piattaforma agentica Gemini Enterprise e server MCP:
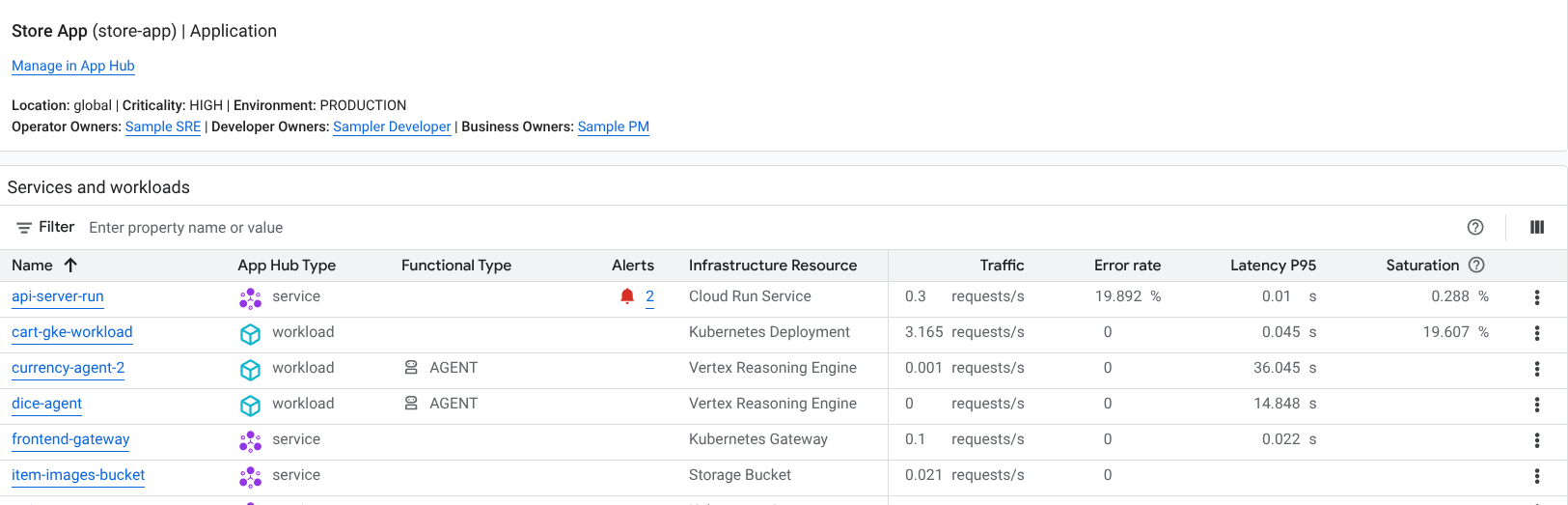
Puoi identificare i servizi e i workload agentic utilizzando il tipo di infrastruttura o il tipo funzionale di App Hub. La colonna del tipo funzionale è nascosta per impostazione predefinita.
Per esempi di codice, vedi quanto segue:
- Instrumentare le applicazioni di AI generativa.
- Raccogliere e visualizzare prompt e risposte multimodali.
Supporto per l'identificazione degli errori
Error Reporting analizza le voci di log di Cloud Logging per trovare gli errori. Quando Error Reporting rileva errori, annota le voci di log associate e crea un gruppo di errori. Esplora questi gruppi di errori per identificare la causa e la cronologia dell'errore.
Supporto per la profilazione
Cloud Profiler ti consente di analizzare l'utilizzo di CPU e memoria utilizzata per le tue applicazioni per identificare le opportunità di migliorare le prestazioni.
Inizia
Questa sezione descrive i passaggi che puoi seguire per acquisire familiarità con le funzionalità di osservabilità in Google Cloud.
Prova le guide rapide
Prova le guide rapide per acquisire familiarità con i servizi disponibili.
Visualizzare i dati raccolti automaticamente
La maggior parte dei Google Cloud servizi genera automaticamente dati di log e metriche. Ciò significa che puoi iniziare a visualizzare alcuni dati di osservabilità per i servizi Google Cloud supportati senza configurazioni aggiuntive.
- Alcuni Google Cloud servizi come Google Kubernetes Engine (GKE), Compute Engine e Cloud SQL forniscono dashboard predefinite nella console Google Cloud per visualizzare i dati di osservabilità nel contesto del servizio.
- Compute Engine, GKE e Cloud Run generano dati delle metriche di sistema e dati di log per impostazione predefinita. Configuri la raccolta di dati aggiuntivi.
- Le funzioni Cloud Run e App Engine generano automaticamente dati delle metriche, dati di log e dati di traccia.
Puoi anche creare grafici dei dati delle metriche raccolti in Esplora metriche, visualizzare i dati di log in Esplora log o visualizzare i dati di traccia in Trace. Per esaminare insieme i dati correlati, crea dashboard personalizzate. Ad esempio, puoi creare un dashboard che includa dati di log, dati delle metriche sul rendimento e criteri di avviso per le macchine virtuali.
Configura le VM di Compute Engine per raccogliere dati aggiuntivi
Per impostazione predefinita, le VM Compute Engine raccolgono solo dati di base sulle metriche di sistema e dati di log. Tuttavia, puoi installare Ops Agent per raccogliere dati di telemetria aggiuntivi dalle tue istanze e applicazioni Compute Engine per la risoluzione dei problemi, il monitoraggio delle prestazioni e la generazione di avvisi. L'Ops Agent non è un'applicazione agentica. Si tratta invece di un software deterministico che raccoglie dati di telemetria.
- Raccogli automaticamente i dati delle metriche host, come i dati delle metriche di CPU, GPU, memoria e processi.
- Raccogli automaticamente i dati dei log di sistema, come syslog dalle VM Linux e il log eventi di Windows dalle VM Windows.
- Puoi osservare le tue applicazioni con quanto segue:
- Integrazioni di applicazioni di terze parti per software diffusi, come Postgres, MongoDB e Java Virtual Machine. Queste integrazioni includono dashboard e policy di avviso preconfigurate.
- Dati delle metriche Prometheus
- Dati delle metriche e dati di traccia OpenTelemetry Protocol (OTLP)
- Dati dei log delle applicazioni
- Per un riepilogo dei dati di telemetria raccolti, consulta la panoramica dell'Ops Agent.
Configura i cluster GKE per raccogliere dati aggiuntivi
Per impostazione predefinita, i cluster GKE inviano i dati di log di sistema e i dati delle metriche di sistema a Logging e Monitoring. Google Cloud Managed Service per Prometheus gestisce la raccolta dei dati delle metriche di terze parti e dei dati delle metriche definite dall'utente.
- Utilizza i pacchetti di dati delle metriche di osservabilità per comprendere lo stato delle tue applicazioni e delle risorse del cluster. Ad esempio, i dati delle metriche del control plane sono utili per creare SLO per monitorare la disponibilità e la latenza del servizio.
- Monitora applicazioni di terze parti come Postgres, MongoDB e Redis. Queste integrazioni forniscono dashboard e criteri di avviso preconfigurati.
Configura Cloud Run per raccogliere dati personalizzati
Se hai un servizio Cloud Run che scrive dati delle metriche Prometheus, puoi utilizzare il sidecar Prometheus per inviare i dati delle metriche a Cloud Monitoring.
Se il tuo servizio Cloud Run scrive dati delle metriche OTLP, puoi utilizzare un sidecar OpenTelemetry. Per un esempio, consulta il tutorial per la raccolta dei dati delle metriche OTLP utilizzando il sidecar.