
במאמר הזה מוסבר איך לשלוח שאילתות ולנתח את נתוני היומן והמעקב באמצעות Observability Analytics, שמספק ממשק שאילתות מבוסס SQL. בעזרת SQL אתם יכולים לבצע ניתוח מצטבר, שיכול לעזור לכם להפיק תובנות ולזהות מגמות. כדי לראות את תוצאות השאילתה, אפשר להשתמש בטופס הטבלאי או ליצור המחשה ויזואלית של הנתונים באמצעות תרשימים. אפשר גם לשמור את הטבלאות והתרשימים האלה במרכזי הבקרה המותאמים אישית.
מידע על מערכי נתונים מקושרים ב-BigQuery
לא צריך מערך נתונים מקושר של BigQuery כדי לבצע שאילתות על נתוני היומנים, על נתוני המעקב או על שני סוגי הנתונים האלה כשמשתמשים בדף Observability Analytics.
אתם צריכים מערכי נתונים מקושרים ב-BigQuery אם אתם רוצים לבצע את הפעולות הבאות:
- צירוף נתוני יומן או נתוני מעקב למערכי נתונים אחרים של BigQuery.
- להריץ שאילתות על נתוני היומן או המעקב משירות אחר, כמו הדף BigQuery Studio או Data Studio.
- כדי לשפר את הביצועים של השאילתות שאתם מריצים מתוך Observability Analytics, אתם יכולים להריץ אותן במשבצות שמורות ב-BigQuery.
- יוצרים מדיניות התראות שעוקבת אחרי התוצאה של שאילתת SQL. היכולת הזו נתמכת רק כשמבצעים שאילתות על נתוני יומן. מידע נוסף מופיע במאמר בנושא מעקב אחרי תוצאות של שאילתות SQL באמצעות מדיניות התראות.
במאמר הזה לא מתואר תהליך ליצירת קבוצת נתונים מקושרת, שנדרש עבורה תהליך ספציפי לסוג הנתונים. במאמרים שאילתת נתוני יומן באמצעות מערך נתונים מקושר ושאילתת נתוני מעקב באמצעות מערך נתונים מקושר מוסבר איך ליצור מערך נתונים מקושר.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Observability API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Observability API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
כדי לקבל את ההרשאות שדרושות לטעינת הדף Observability Analytics, לכתיבה, להרצה ולשמירה של שאילתות פרטיות בנתוני המעקב, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים:
- Observability View Accessor (
roles/observability.viewAccessor) בתצוגות הניראות שרוצים לשלוח אליהן שאילתות. התפקיד הזה תומך בתנאי IAM, שמאפשרים להגביל את ההרשאה לתצוגה ספציפית. אם לא מצרפים תנאי להענקת התפקיד, לחשבון המשתמש תהיה גישה לכל תצוגות הנתונים של יכולת התצפית. תצוגות ה-Observability זמינות ב-Public Preview. - Observability Analytics User (
roles/observability.analyticsUser) on your project. התפקיד הזה כולל את ההרשאות שנדרשות לשמירה ולהרצה של שאילתות פרטיות, ולהרצה של שאילתות משותפות. - מציג היומנים (
roles/logging.viewer) בפרויקט - בעל הרשאת גישה לתצוגת יומנים (
roles/logging.viewAccessor) בפרויקט שבו מאוחסנות תצוגות היומנים שרוצים להריץ עליהן שאילתות.
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שאפשר לקבל את ההרשאות הנדרשות גם באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש.
- Observability View Accessor (
שאילתות ביומן ונתוני מעקב
בקטע הזה מתוארות הגישות שבהן אפשר להשתמש כדי להריץ שאילתות על נתוני היומן והמעקב:
- טוענים שאילתה שהוגדרה על ידי המערכת, עורכים אותה ומריצים אותה.
- מזינים ומריצים שאילתה מותאמת אישית. לדוגמה, אפשר להדביק שאילתה קיימת או לכתוב שאילתה חדשה. שאילתות מותאמות אישית יכולות לכלול הצטרפויות, שאילתות מקוננות ומשפטי SQL מורכבים אחרים. דוגמאות אפשר לראות בשאילתות SQL לדוגמה.
- בוחרים אפשרויות בתפריט כדי ליצור שאילתה, ואז מריצים את השאילתה. הכלי Observability Analytics ממיר את הבחירות שלכם לשאילתת SQL, שאפשר גם לראות וגם לערוך.
טעינה, עריכה והרצה של השאילתה שמוגדרת על ידי המערכת
-
נכנסים לדף manage_search Observability Analytics במסוף Google Cloud :
עוברים אל Observability Analytics
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Logging.
בתפריט תצוגות, בוחרים תצוגה.
כדי למצוא את התצוגה שרוצים לשלוח לגביה שאילתה, משתמשים בסרגל filter_list Filter או גוללים ברשימה:
- הצפיות ביומן, שמופיעות בקטע Logs, מסודרות לפי מזהי הדלי והתצוגה.
- תצוגות מפורטות ב-Analytics, שמפורטות בקטע Analytics Views, מסודרות לפי מיקום ומזהה של התצוגה המפורטת. תצוגות ה-Observability זמינות ב-Public Preview.
- יש תצוגת מעקב אחת, שמופיעה בקטע
 Traces. תצוגות ה-Observability זמינות ב-Public Preview.
Traces. תצוגות ה-Observability זמינות ב-Public Preview.
אם לא מופיע תצוגה בשם
_Trace.Spans._AllSpans, סימן שהפרויקטGoogle Cloud לא מכיל קטגוריה של נתונים שניתנים לצפייה בשם_Trace. מידע על פתרון הכשל הזה מופיע במאמר Trace storage initialization fails.
מבצעים אחת מהפעולות הבאות:
כדי לטעון שאילתה שמוגדרת על ידי המערכת ומבוססת על הכלי ליצירת שאילתות, שמאפשר להגדיר את השאילתה באמצעות בחירות בתפריט, מוודאים שבחלונית שאילתה מוצג הכלי ליצירת שאילתות. אם מוצג עורך SQL, לוחצים על tune Builder.
כדי לטעון שאילתה שמוגדרת על ידי המערכת ומחלצת ערכי JSON, מוודאים שחלונית Query מציגה את עורך ה-SQL. אם בחלונית מוצג הכלי ליצירת שאילתות, לוחצים על code SQL.
בחלונית סכימה, בוחרים באפשרות שאילתה ולוחצים על החלפה.
בחלונית Query מוצגת שאילתה שמוגדרת על ידי המערכת. אם בחרתם במצב הכלי ליצירת שאילתות אבל אתם רוצים לראות את שאילתת ה-SQL, לוחצים על code SQL.
אופציונלי: משנים את השאילתה.
כדי להריץ את השאילתה, עוברים לסרגל הכלים ולוחצים על Run Query (הרצת שאילתה).
תוצאות השאילתה מוצגות בטבלה ב-Observability Analytics. עם זאת, אפשר ליצור תרשים, ואפשר גם לשמור את הטבלה או התרשים במרכז בקרה בהתאמה אישית. מידע נוסף זמין במאמר בנושא יצירת תרשים של תוצאות שאילתת SQL.
אם בסרגל הכלים מוצגת האפשרות Run in BigQuery, צריך להחליף את מנוע השאילתות של Observability Analytics למנוע ברירת המחדל. כדי לבצע את השינוי הזה, בסרגל הכלים של החלונית שאילתה, לוחצים על settings הגדרות ואז בוחרים באפשרות Analytics (ברירת מחדל).
הזנה והרצה של שאילתה בהתאמה אישית
כדי להזין שאילתת SQL, מבצעים את הפעולות הבאות:
-
נכנסים לדף manage_search Observability Analytics במסוף Google Cloud :
עוברים אל Observability Analytics
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Logging.
בחלונית Query, לוחצים על code SQL.
כדי לציין טווח זמן, מומלץ להשתמש בבורר time-range. אם מוסיפים פסקה
WHEREשמציינת את השדהtimestamp, הערך הזה מבטל את ההגדרה בבורר טווחי הזמן והבורר מושבת.דוגמאות אפשר לראות בשאילתות SQL לדוגמה.
התצוגה שאתם שולחים לגביה שאילתה קובעת את הפורמט של סעיף
FROM:נתוני יומן
אפשר לשלוח שאילתות על תצוגות של יומנים או על תצוגות של ניתוחים. צריך להשתמש בפורמט הבא לסעיף
FROM:- תצוגות ביומן:
FROM `PROJECT_ID.LOCATION.BUCKET_ID.LOG_VIEW_ID`
- תצוגות מפורטות ב-Analytics:
FROM `analytics_view.PROJECT_ID.LOCATION.ANALYTICS_VIEW_ID`
השדות בביטויים הקודמים מייצגים את המשמעויות הבאות:
- PROJECT_ID: מזהה הפרויקט.
- LOCATION: המיקום של תצוגת היומן או תצוגת ניתוח הנתונים.
- BUCKET_ID: השם או המזהה של קטגוריה ביומן.
- LOG_VIEW_ID: המזהה של תצוגת היומן, שמוגבל ל-100 תווים ויכול לכלול רק אותיות, ספרות, קווים תחתונים ומקפים.
- ANALYTICS_VIEW_ID: המזהה של תצוגת הניתוח, שמוגבל ל-100 תווים ויכול לכלול רק אותיות, ספרות, קווים תחתונים ומקפים.
אם בחלונית השאילתה מוצגת הודעת שגיאה שמתייחסת להצהרה
FROM, סימן שלא ניתן למצוא את התצוגה. מידע על פתרון הכשל הזה זמין במאמר בנושא הסעיף ErrorFROMחייב להכיל בדיוק תצוגת יומן אחת.נתוני מעקב
בעורך ה-SQL מוצג השם המוגדר במלואו של התצוגה, שמופיע בפורמט הבא:
_Trace.Spans._AllSpansFROM `PROJECT_ID.LOCATION._Trace.Spans._AllSpans`
השדות בביטוי הקודם מייצגים את המשמעויות הבאות:
- PROJECT_ID: מזהה הפרויקט.
- LOCATION: המיקום של קטגוריית ה-Observability.
אם בחלונית השאילתה מוצגת הודעת שגיאה שמתייחסת להצהרה
FROM, סימן שלא ניתן למצוא את התצוגה. מידע על פתרון הכשל הזה מופיע במאמר הודעת שגיאה שבה מצוין שתצוגה לא קיימת.- תצוגות ביומן:
כדי להריץ את השאילתה, עוברים לסרגל הכלים ולוחצים על Run Query (הרצת שאילתה).
תוצאות השאילתה מוצגות בטבלה ב-Observability Analytics. עם זאת, אפשר ליצור תרשים, ואפשר גם לשמור את הטבלה או התרשים במרכז בקרה בהתאמה אישית. מידע נוסף זמין במאמר בנושא יצירת תרשים של תוצאות שאילתת SQL.
אם בסרגל הכלים מוצגת האפשרות Run in BigQuery, צריך להחליף את מנוע השאילתות של Observability Analytics למנוע ברירת המחדל. כדי לבצע את השינוי הזה, בסרגל הכלים של החלונית שאילתה, לוחצים על settings הגדרות ואז בוחרים באפשרות Analytics (ברירת מחדל).
איך בונים, עורכים ומריצים שאילתה
בממשק של הכלי ליצירת שאילתות אפשר ליצור שאילתה על ידי בחירה מתוך תפריטים. הכלי Observability Analytics ממיר את הבחירות שלכם לשאילתת SQL, שאפשר לראות ולערוך. לדוגמה, אפשר להתחיל להשתמש בממשק של כלי ליצירת שאילתות ואז לעבור לעורך SQL כדי לשפר את השאילתה.
תמיד אפשר להמיר את הבחירות בתפריט מתוך הממשק של כלי בניית השאילתות לשאילתת SQL ב-Observability Analytics. עם זאת, לא כל שאילתות ה-SQL יכולות להיות מיוצגות בממשק של כלי ליצירת שאילתות. לדוגמה, אי אפשר לייצג בממשק הזה שאילתות עם הצטרפויות.
כדי ליצור שאילתה:
-
נכנסים לדף manage_search Observability Analytics במסוף Google Cloud :
עוברים אל Observability Analytics
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Logging.
אם בחלונית Query מוצג עורך SQL, בוחרים באפשרות tune Builder כדי לפתוח את החלונית הכלי ליצירת שאילתות.
בתפריט מקור בוחרים את התצוגה שרוצים לשלוח לגביה שאילתה. הבחירות שלכם ממופות לסעיף
FROMבשאילתת ה-SQL.אופציונלי: אפשר להשתמש בתפריטים הבאים כדי להגביל את טבלת התוצאות או לעצב אותה:
חיפוש בכל השדות: חיפוש מחרוזות תואמות. הבחירות שלכם ממופות לסעיף
WHEREבשאילתת ה-SQL.עמודות: בוחרים את העמודות שיופיעו בטבלת התוצאות. הבחירות שלכם ממופות לסעיפים
SELECTבשאילתת ה-SQL.כשבוחרים שם שדה בתפריט הזה, נפתחת תיבת דו-שיח. בתיבת הדו-שיח הזו אפשר לבצע את הפעולות הבאות:
משתמשים בתפריט כדי לצבור או לקבץ את הנתונים.
כדי למנוע שגיאות בתחביר, כל צבירה וקיבוץ שאתם מגדירים בעמודה אחת מוגדרים אוטומטית גם בעמודות אחרות. דוגמה לאופן צבירה וקיבוץ של רשומות מופיעה במאמר קיבוץ וצבירה של נתונים באמצעות הכלי ליצירת שאילתות.
המרת ערך מכל סוג לסוג נתונים אחר שצוין. מידע נוסף זמין במאמרי העזרה בנושא
CAST.חילוץ של מחרוזת משנה של ערכים באמצעות ביטויים רגולריים. מידע נוסף זמין במאמרי העזרה בנושא
REGEXP_EXTRACT.
מסננים: מוסיפים מסננים כשרוצים להגביל את השאילתה ליחידות לוגיות למעקב שמכילות מאפיין ספציפי או מזהה יחידה לוגית למעקב. בתפריט מפורטות כל אפשרויות הסינון הזמינות. הבחירות שלכם ממופות לסעיף
WHEREבשאילתת ה-SQL.מיון לפי: הגדרת העמודות למיון, וקביעה אם המיון הוא בסדר עולה או בסדר יורד. הבחירות שלכם ממופות לסעיף
ORDER BYבשאילתת ה-SQL.Limit (מגבלה): הגדרת מספר השורות המקסימלי בטבלת התוצאות. הבחירות שלכם ממופות לסעיף
LIMITבשאילתת ה-SQL.
כדי להריץ את השאילתה, עוברים לסרגל הכלים ולוחצים על Run Query (הרצת שאילתה).
תוצאות השאילתה מוצגות בטבלה ב-Observability Analytics. עם זאת, אפשר ליצור תרשים, ואפשר גם לשמור את הטבלה או התרשים במרכז בקרה בהתאמה אישית. מידע נוסף זמין במאמר בנושא יצירת תרשים של תוצאות שאילתת SQL.
אם בסרגל הכלים מוצגת האפשרות Run in BigQuery, צריך להחליף את מנוע השאילתות של Observability Analytics למנוע ברירת המחדל. כדי לבצע את השינוי הזה, בסרגל הכלים של החלונית שאילתה, לוחצים על settings הגדרות ואז בוחרים באפשרות Analytics (ברירת מחדל).
דוגמה: קיבוץ וצבירה של נתונים באמצעות הכלי ליצירת שאילתות
כשבוחרים עמודה בכלי ליצירת שאילתות, כל שדה כולל תפריט שבו אפשר להוסיף קיבוץ וצבירה. קיבוץ מאפשר לארגן את הנתונים בקבוצות על סמך הערך של עמודה אחת או יותר, וצבירה מאפשרת לבצע חישובים על הקבוצות האלה כדי להחזיר ערך יחיד.
לכל שדה שבוחרים ברכיב Columns יש תפריט מצורף עם האפשרויות הבאות:
- ללא: לא מתבצע קיבוץ או צבירה לפי השדה הזה.
- Aggregate: קיבוץ השדות שמופיעים ברכיב Columns, אלא אם השדה כולל בחירה של Aggregate. בשדות האלה, מחשבים את הערך על ידי ביצוע פעולה על כל הרשומות בכל קיבוץ. הפעולה יכולה להיות חישוב הממוצע של שדה מסוים, או פעולה כמו ספירת מספר הרשומות בכל קיבוץ.
- קיבוץ לפי: קיבוץ הרשומות לפי כל השדות שמופיעים ברכיב עמודות.
הדוגמאות הבאות ממחישות איך אפשר ליצור שאילתה שמקבצת רשומות ואז מבצעת סוג מסוים של צבירה.
דוגמה לצבירה של נתוני יומן
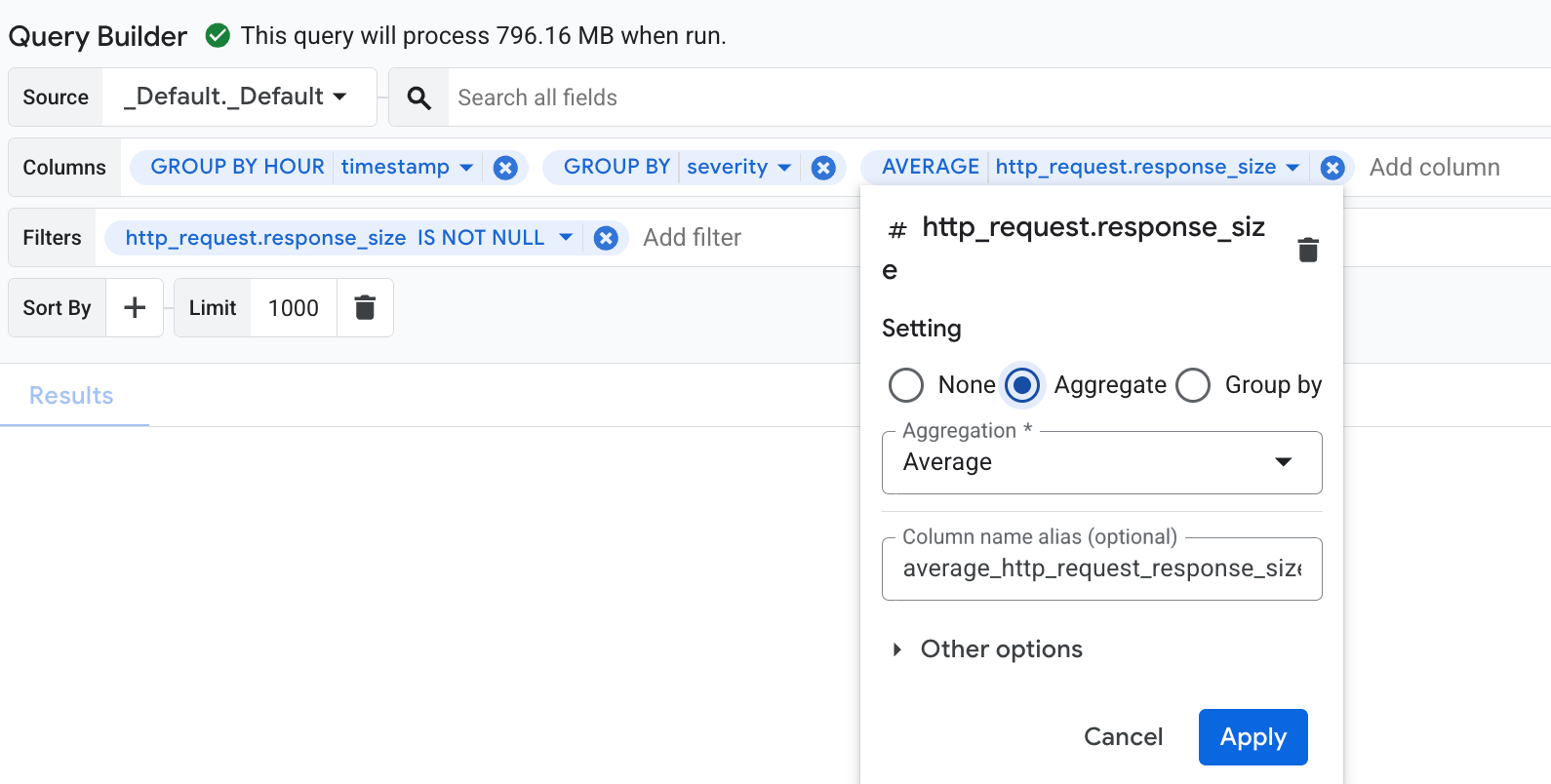
בדוגמה הזו מוסבר איך להשתמש בכלי ליצירת שאילתות כדי לקבץ רשומות ביומן לפי חומרה וחותמת זמן, ואז לחשב את הממוצע של השדה http_request.response_size לכל קבוצה:
בתפריט עמודות, בוחרים בשדות
timestamp,severityו-http_request.response_size.כדי לקבץ את הנתונים, לוחצים על השדה
timestampכדי לפתוח את תיבת הדו-שיח של ההגדרות. בתיבת הדו-שיח הזו, בוחרים באפשרות קיבוץ לפי ומגדירים את Truncation Granularity ל-HOUR. לאחר מכן, הקיבוץ מוחל באופן אוטומטי על כל השדות האחרים כדי למנוע שגיאות תחביר. אם יש שדות לא תקינים שלא ניתן להחיל עליהם קיבוץ, תופיע הודעת שגיאה. כדי לפתור את השגיאה הזו, צריך להסיר מהתפריט את השדות עם הערכים הלא תקינים.כדי לבצע צבירה בשדה
http_request.response_size, לוחצים על השדה כדי לפתוח את תיבת הדו-שיח של ההגדרות. בתיבת הדו-שיח, בוחרים באפשרות Aggregate (צבירה). בתפריט Aggregation (צבירה), לוחצים על Average (ממוצע).
בתפריט מסננים, מוסיפים את
http_request.response_sizeומגדירים את האופרטור להשוואה ל-IS NOT NULL. המסנן הזה מתאים לרשומות ביומן שמכילות ערךresponse_size.התפריטים בכלי ליצירת שאילתות ייראו בערך כך:
כדי להריץ את השאילתה, עוברים לסרגל הכלים ולוחצים על Run Query (הפעלת שאילתה).
התוצאות של השאילתה הזו אמורות להיראות כך:
+-----------------------------------+----------+---------------+ | Row | hour_timestamp | severity | response_size | | | TIMESTAMP | STRING | INTEGER | +-----+-----------------------------+----------+---------------+ | 1 | 2025-10-06 16:00:00.000 UTC | NOTICE | 3082 | | 2 | 2025-10-06 17:00:00.000 UTC | WARNING | 338 | | 3 | 2025-10-06 16:00:00.000 UTC | INFO | 149 |
שאילתת ה-SQL שמתאימה לדוגמה הקודמת היא:
SELECT
-- Truncate the timestamp by hour.
TIMESTAMP_TRUNC( timestamp, HOUR ) AS hour_timestamp,
severity,
-- Compute average response_size.
AVG( http_request.response_size ) AS average_http_request_response_size
FROM
`PROJECT_ID.LOCATION.BUCKET_ID.LOG_VIEW_ID`
WHERE
-- Matches log entries that have a response_size.
http_request.response_size IS NOT NULL
GROUP BY
-- Group log entries by timestamp and severity.
TIMESTAMP_TRUNC( timestamp, HOUR ),
severity
LIMIT
1000
דוגמה לצבירה של נתוני מעקב
בדוגמה הזו מוצג איך להשתמש בהכלי ליצירת שאילתות כדי לקבץ יחידות לוגיות למעקב לפי שעת התחלה, שם יחידה לוגית למעקב וסיווג, ואז לחשב את משך הזמן הממוצע בננו-שניות לכל קבוצה:
- בתפריט Columns (עמודות), בוחרים בשדות
start_time,name,kindו-duration_nano. - כדי לקצר את שעת ההתחלה לשעה, מרחיבים את התפריט בעמודה
start_timeובוחרים באפשרות Group By (קיבוץ לפי). מוודאים שהתפריט 'רמת הפירוט' מוגדר לשעה. לוחצים על אישור.
כשבוחרים באפשרות קיבוץ לפי עבור עמודה כלשהי, המערכת מקבצת את הרשומות לפי כל העמודות. בדוגמה הזו, הרשומות מקובצות לפי הערך הקטום של
start_time, שם היחידה הלוגית למעקב, סיווג היחידה הלוגית למעקב והערך של משך הזמן.עם זאת, המטרה בדוגמה הזו היא לקבץ את הרשומות לפי הזמן הקטום, שם הטווח וסוג הטווח, ואז לחשב את משך הזמן הממוצע לכל קבוצה. בשלב הבא משנים את הקיבוץ ומוסיפים צבירה.
מרחיבים את התפריט בשדה
duration_nano, בוחרים באפשרות Aggregate ואז מגדירים את השדה Aggregation לערך Average.כשמריצים את השאילתה, כל שורה מתאימה לקבוצה, שמורכבת מזמן קטום, שם טווח וסוג טווח. הערך האחרון בכל שורה הוא משך הזמן הממוצע של כל הערכים בקבוצה הזו.
התוצאות של השאילתה הזו אמורות להיראות כך:
+-----------------------------------+----------------+----------+-----------------------+ | Row | hour_timestamp | span_name | kind | average_duation_nano | | | TIMESTAMP | STRING | INTEGER | FLOAT | +-----+-----------------------------+-----------+---------------+-----------------------+ | 1 | 2025-10-09 13:00:00.000 EDT | http.receive | 3 | 122138.22813990474 | 2 | 2025-10-09 13:00:00.000 EDT | query.request | 1 | 6740819304.390297 | 3 | 2025-10-09 13:00:00.000 EDT | client.handler | 2 | 6739339098.409376השאילתה יכולה לכלול כמה צבירות. לדוגמה, כדי להוסיף עמודה שסופרת את מספר הערכים בכל קבוצה, מבצעים את הפעולות הבאות:
- ברכיב Columns (עמודות), לוחצים על Add column (הוספת עמודה).
- בוחרים באפשרות הכול (*).
- בתיבת הדו-שיח, בוחרים באפשרות צבירה, בוחרים באפשרות ספירה בשדה צבירה ואז בוחרים באפשרות החלה.
השינוי הזה לא משפיע על הקיבוץ. הערכים מקובצים לפי שעת ההתחלה הקצרה, שם הטווח וסוג הטווח. עם זאת, לכל קבוצה, השאילתה מחשבת את משך הזמן הממוצע ואת מספר הרשומות.
שאילתת ה-SQL שמתאימה לדוגמה הקודמת היא:
WITH
scope_query AS (
SELECT
*
FROM
`PROJECT_ID.us._Trace.Spans._AllSpans` )
SELECT
-- Report the truncated start time, span name, span kind, average duration and number
-- of entries for each group.
TIMESTAMP_TRUNC( start_time, HOUR ) AS hour_start_time,
name AS span_name,
kind,
AVG( duration_nano ) AS average_duration_nano,
COUNT( * ) AS count_all
FROM
scope_query
GROUP BY
TIMESTAMP_TRUNC( start_time, HOUR ),
name,
kind
LIMIT
100
הצגת הסכימה
הסכימה מגדירה איך הנתונים מאוחסנים, כולל השדות וסוגי הנתונים שלהם. המידע הזה חשוב לכם כי הסכימה קובעת את השדות שאתם שולפים ואם צריך להמיר שדות לסוגי נתונים שונים. לדוגמה, כדי לכתוב שאילתה שמחשבת את זמן האחזור הממוצע של בקשות HTTP, צריך לדעת איך לגשת לשדה זמן האחזור והאם הוא מאוחסן כמספר שלם כמו 100 או כמחרוזת כמו "100". אם נתוני ההשהיה מאוחסנים כמחרוזת, השאילתה צריכה להמיר את הערך לערך מספרי לפני חישוב הממוצע.
כדי לזהות את הסכימה:
-
נכנסים לדף manage_search Observability Analytics במסוף Google Cloud :
עוברים אל Observability Analytics
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Logging.
בתפריט תצוגות, בוחרים תצוגה.
החלונית סכימה מתעדכנת. התכונה 'ניתוח נתונים של יכולת התבוננות' מסיקה באופן אוטומטי את השדות של עמודה כשסוג הנתונים הוא JSON. כדי לראות כמה פעמים השדות האלה שנוצרו באמצעות הסקה מופיעים בנתונים, לוחצים על more_vert אפשרויות ובוחרים באפשרות הצגת מידע ותיאור.
נתוני יומן
בצפיות ביומן, הסכימה קבועה ותואמת ל
LogEntry. בתצוגות של ניתוח נתונים, אפשר לשנות את הסכימה על ידי שינוי שאילתת ה-SQL.נתוני מעקב
מידע על הסכימה זמין במאמר סכימת אחסון לנתוני מעקב.
אם לא מופיע תצוגה בשם
_Trace.Spans._AllSpans, סימן שהפרויקטGoogle Cloud לא מכיל קטגוריה של נתונים שניתנים לצפייה בשם_Trace. מידע על פתרון הכשל הזה מופיע במאמר Trace storage initialization fails.
הגבלות
אם רוצים לשלוח שאילתה לכמה תצוגות, התצוגות האלה צריכות להיות באותו מיקום. לדוגמה, אם מאחסנים שתי תצוגות במיקום us-east1, שאילתה אחת יכולה לשלוף נתונים משתי התצוגות. אפשר גם לשלוח שאילתה לשתי תצוגות שמאוחסנות בus מספר אזורים. עם זאת, אם המיקום של הצפייה הוא global, הצפייה יכולה להיות בכל מיקום פיזי. לכן, יכול להיות שפעולות הצטרפות בין שתי תצוגות שכוללות את המיקום global ייכשלו.
רשימת ההגבלות שחלות על נתוני יומן זמינה במאמר Observability Analytics: Restrictions.