
השירות המנוהל של Google Cloud ל-Prometheus מחייב על מספר הדגימות שנקלטו ב-Cloud Monitoring ועל בקשות קריאה ל-Monitoring API. מספר הדגימות שהמערכת מעכלת הוא הגורם העיקרי לעלות.
במאמר הזה מוסבר איך אפשר לשלוט בעלויות שקשורות להוספת מדדים, ואיך לזהות מקורות של הוספה בנפח גבוה.
למידע נוסף על התמחור של שירות מנוהל ל-Prometheus, אפשר לעיין בסעיפים בנושא Cloud Monitoring בדף התמחור של Google Cloud Observability.
צפייה בחשבונית
כדי לראות את Google Cloud החיוב:
נכנסים לדף Billing במסוף Google Cloud .
אם יש לכם יותר מחשבון אחד לחיוב, לוחצים על Go to linked billing account כדי לראות את החשבון לחיוב של הפרויקט הנוכחי. כדי למצוא חשבון אחר לחיוב, לוחצים על Manage billing accounts ובוחרים את החשבון שרוצים לקבל לגביו דוחות שימוש.
בקטע Cost management בתפריט הניווט Billing, בוחרים באפשרות Reports.
בתפריט Services (שירותים), בוחרים באפשרות Cloud Monitoring.
בתפריט SKUs, בוחרים באפשרויות הבאות:
- Prometheus Samples Ingested
- מעקב אחרי בקשות API
בצילום המסך הבא מוצג דוח החיוב של שירות מנוהל ל-Prometheus מפרויקט אחד:
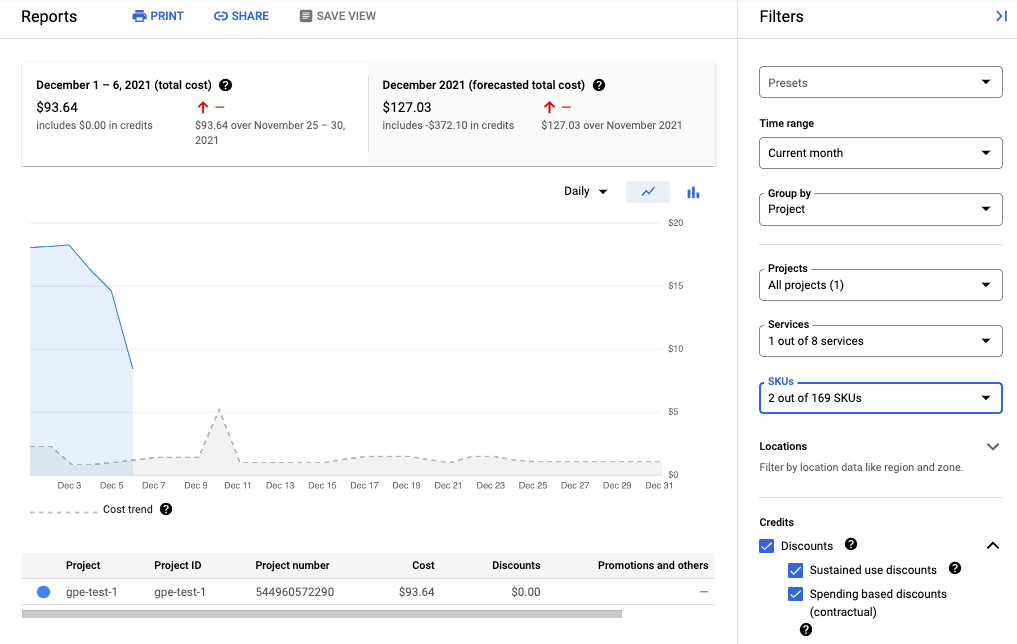
הפחתת העלויות
כדי להפחית את העלויות שקשורות לשימוש בשירות מנוהל ל-Prometheus, אפשר לבצע את הפעולות הבאות:
- כדי לצמצם את מספר סדרות הזמן שאתם שולחים לשירות המנוהל, אתם יכולים לסנן את נתוני המדדים שאתם יוצרים.
- כדי לצמצם את מספר הדגימות שאתם אוספים, אתם יכולים לשנות את מרווח הזמן בין הסריקות.
- הגבלת מספר הדגימות ממדדים בעלי עוצמה גבוהה שעלולים להיות מוגדרים בצורה שגויה.
צמצום מספר סדרות הזמן
במסמכי התיעוד של Prometheus בקוד פתוח, נדיר למצוא המלצות לסינון נפח המדדים, וזה הגיוני כשעלויות מוגבלות לעלויות של מכונות. אבל כשמשלמים לספק שירותים מנוהלים על בסיס יחידה, שליחת נתונים ללא הגבלה עלולה לגרום לחשבונות גבוהים שלא לצורך.
הכלי לייצוא שכלול בפרויקט kube-prometheus – ובמיוחד בשירות kube-state-metrics – יכול להפיק הרבה נתוני מדדים.
לדוגמה, שירות kube-state-metrics פולט מאות מדדים, ורבים מהם לא רלוונטיים לכם כצרכנים. אשכול חדש עם שלושה צמתים בפרויקט kube-prometheus שולח כ-900 דגימות בשנייה לשירות המנוהל ל-Prometheus.
יכול להיות שסינון המדדים החיצוניים האלה יספיק כדי להקטין את החשבון לרמה מקובלת.
כדי לצמצם את מספר המדדים, אפשר:
- משנים את הגדרות הסקריפט כדי לגרד פחות יעדים.
- מסננים את המדדים שנאספו כמו שמתואר בהמשך:
- סינון מדדים מיוצאים כשמשתמשים באיסוף מנוהל.
- סינון מדדים מיוצאים כשמשתמשים באיסוף שמוטמע באופן עצמאי.
אם אתם משתמשים בשירות kube-state-metrics, אתם יכולים להוסיף כלל לשינוי תוויות ב-Prometheus עם פעולה של keep. במקרה של אוסף מנוהל, הכלל הזה מופיע בהגדרה של PodMonitoring או ClusterPodMonitoring. באיסוף שמוגדר באופן עצמאי, הכלל הזה מופיע בהגדרות הסקריפט של Prometheus או בהגדרה של ServiceMonitor (במקרה של prometheus-operator).
לדוגמה, שימוש במסנן הבא באשכול חדש עם שלושה צמתים מקטין את נפח הדגימה בכ-125 דגימות לשנייה:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
המסנן הקודם משתמש בביטוי רגולרי כדי לציין אילו מדדים לשמור על סמך שם המדד. לדוגמה, מדדים שהשם שלהם מתחיל ב-kube_daemonset_ נשמרים.
אפשר גם לציין פעולה של drop, שמסננת את המדדים שתואמים לביטוי הרגולרי.
לפעמים יכול להיות שתגלו שאין חשיבות לכלל הנתונים שמועברים. לדוגמה, חבילת kube-prometheus מתקינה כברירת מחדל את כלי המעקב הבאים אחרי שירותים, שרבים מהם לא נחוצים בסביבה מנוהלת:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
כדי לצמצם את מספר המדדים שמייצאים, אפשר למחוק, להשבית או להפסיק את הסקריפט של המדדים של כלי המעקב אחרי שירותים שלא צריך. לדוגמה, השבתה של kube-apiserver שירות המעקב באשכול חדש עם שלושה צמתים מפחיתה את נפח הדגימה בכ-200 דגימות לשנייה.
צמצום מספר הדגימות שנאספות
החיוב בשירות המנוהל ל-Prometheus מתבצע לפי דגימה. אפשר להקטין את מספר הדגימות שנקלטות על ידי הארכת משך תקופת הדגימה. לדוגמה:
- שינוי תקופת הדגימה מ-10 שניות ל-30 שניות יכול להפחית את נפח הדגימה ב-66%, בלי לאבד הרבה מידע.
- שינוי תקופת הדגימה מ-10 שניות ל-60 שניות יכול להקטין את נפח הדגימה ב-83%.
מידע על אופן הספירה של הדגימות ועל ההשפעה של תקופת הדגימה על מספר הדגימות זמין במאמר נתוני מדדים שחויבו לפי דגימות שהועלו.
בדרך כלל אפשר להגדיר את מרווח הזמן בין סריקות לכל משימה או לכל יעד.
באיסוף מנוהל, מגדירים את מרווח הזמן בין סריקות במשאב PodMonitoring באמצעות השדה interval.
באיסוף שמוטמע עצמאית, מגדירים את מרווח הדגימה בהגדרות הסקריפינג, בדרך כלל על ידי הגדרת השדה interval או scrape_interval.
הגדרת צבירה מקומית (רק באיסוף שמוטמע באופן עצמאי)
אם אתם מגדירים את השירות באמצעות איסוף שמתבצע באופן עצמאי, למשל באמצעות kube-prometheus, prometheus-operator או באמצעות פריסה ידנית של התמונה, אתם יכולים לצמצם את מספר הדגימות שנשלחות לשירות המנוהל ל-Prometheus על ידי צבירה של מדדים עם קרדינליות גבוהה באופן מקומי. אפשר להשתמש בכללי הקלטה כדי לצבור תוויות כמו instance, ולהשתמש בדגל --export.match או במשתנה הסביבה EXTRA_ARGS כדי לשלוח רק נתונים מצטברים ל-Monarch.
לדוגמה, נניח שיש לכם שלושה מדדים: high_cardinality_metric_1, high_cardinality_metric_2 ו-low_cardinality_metric. אתם רוצים לצמצם את הדגימות שנשלחות עבור high_cardinality_metric_1 ולבטל את כל הדגימות שנשלחות עבור high_cardinality_metric_2, תוך שמירה של כל הנתונים הגולמיים שמאוחסנים באופן מקומי (אולי למטרות התראות). ההגדרה שלכם יכולה להיראות כך:
- פורסים את האימג' של השירות המנוהל ל-Prometheus.
- מגדירים את קובצי ההגדרות של הגירוד כך שיגרדו את כל הנתונים הגולמיים לשרת המקומי (באמצעות כמה שפחות מסננים).
כדאי להגדיר את כללי ההקלטה כך שיפעילו צבירות מקומיות על
high_cardinality_metric_1ועלhigh_cardinality_metric_2, אולי על ידי צבירה של התוויתinstanceאו של מספר תוויות מדדים, בהתאם למה שמספק את ההפחתה הטובה ביותר במספר סדרות הזמן שלא נחוצות. יכול להיות שתפעילו כלל שנראה כך, שמסיר את התוויתinstanceומסכם את ציר הזמן שמתקבל לפי התוויות שנותרו:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
אפשר לעיין באופרטורים של צבירה במסמכי התיעוד של Prometheus כדי לראות עוד אפשרויות צבירה.
פורסים את תמונת שירות מנוהל ל-Prometheus עם דגל המסנן הבא, שמונע את שליחת הנתונים הגולמיים מהמדדים שמופיעים ברשימה אל Monarch:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'בדוגמה הזו, התג
export.matchמשתמש בסלקטורים מופרדים בפסיקים עם האופרטור!=כדי לסנן נתונים גולמיים לא רצויים. אם מוסיפים כללי תיעוד נוספים כדי לצבור מדדים אחרים עם עוצמה גבוהה, צריך גם להוסיף בורר__name__חדש למסנן כדי שהנתונים הגולמיים יימחקו. אם משתמשים בדגל יחיד שמכיל כמה בוררים עם האופרטור!=כדי לסנן נתונים לא רצויים, צריך לשנות את המסנן רק כשיוצרים צבירה חדשה, ולא בכל פעם שמשנים או מוסיפים הגדרות גירוד.בשיטות פריסה מסוימות, כמו prometheus-operator, יכול להיות שתצטרכו להשמיט את המירכאות היחידות שמקיפות את הסוגריים.
יכול להיות שיהיה צורך בהשקעת משאבים מסוימת בתהליך העבודה הזה כדי ליצור ולנהל כללי הקלטה ודגלים של export.match, אבל סביר להניח שאפשר לצמצם את נפח הנתונים באופן משמעותי אם מתמקדים רק במדדים עם קרדינליות גבוהה במיוחד. מידע על זיהוי מדדים שיכולים להפיק תועלת רבה מחישוב מראש של נתונים מקומיים זמין במאמר זיהוי מדדים עם נפח גבוה.
אל תטמיעו איחוד כשאתם משתמשים בשירות מנוהל ל-Prometheus. תהליך העבודה הזה מייתר את השימוש בשרתי איחוד, כי שרת Prometheus אחד שמוגדר באופן עצמאי יכול לבצע כל צבירת נתונים ברמת האשכול שנדרשת לכם. יכול להיות שפדרציה תגרום להשפעות לא צפויות כמו מדדים מסוג 'לא ידוע' ונפח בליעה כפול.
הגבלת דגימות ממדדים בעלי עוצמה גבוהה (רק באיסוף שמוטמע באופן עצמאי)
אפשר ליצור מדדים עם עוצמה גבוהה מאוד על ידי הוספת תוויות עם מספר גדול של ערכים פוטנציאליים, כמו מזהה משתמש או כתובת IP. מדדים כאלה יכולים ליצור מספר גדול מאוד של דגימות. שימוש בתוויות עם מספר גדול של ערכים הוא בדרך כלל הגדרה שגויה. כדי למנוע מדדים בעלי עוצמה גבוהה במאספים שפרסתם בעצמכם, אתם יכולים להגדיר ערך sample_limit בהגדרות הסקראפינג.
אם אתם משתמשים במגבלה הזו, מומלץ להגדיר אותה לערך גבוה מאוד, כדי שהיא תזהה רק מדדים עם הגדרה שגויה באופן ברור. דוגמאות שחורגות מהמגבלה מושמטות, ויכול להיות שיהיה קשה מאוד לאבחן בעיות שנגרמות כתוצאה מחריגה מהמגבלה.
שימוש במגבלת דגימה לא מומלץ לניהול של קליטת דגימות, אבל המגבלה יכולה להגן עליכם מפני טעויות בהגדרות. מידע נוסף מופיע במאמר בנושא שימוש ב-sample_limit כדי למנוע עומס יתר.
זיהוי עלויות ושיוך שלהן
אפשר להשתמש ב-Cloud Monitoring כדי לזהות את מדדי Prometheus שכותבים את המספרים הגדולים ביותר של דגימות. המדדים האלה תורמים הכי הרבה לעלויות שלכם. אחרי שתזהו את המדדים הכי יקרים, תוכלו לשנות את הגדרות הסקריפינג כדי לסנן את המדדים האלה בצורה מתאימה.
בדף Metrics Management ב-Cloud Monitoring יש מידע שיכול לעזור לכם לשלוט בסכום שאתם מוציאים על מדדים שניתנים לחיוב, בלי לפגוע ביכולת הצפייה. בדף Metrics Management מופיע המידע הבא:
- נפחי ההטמעה לחיוב על בסיס בייט ועל בסיס דגימה, בדומיינים של מדדים ובמדדים נפרדים.
- נתונים על תוויות ועוצמה של מדדים.
- מספר הקריאות לכל מדד.
- שימוש במדדים במדיניות התראות ובמרכזי בקרה בהתאמה אישית.
- שיעור השגיאות בכתיבת מדדים.
אפשר גם להשתמש בדף ניהול מדדים כדי להחריג מדדים לא נחוצים, וכך לבטל את העלות של ההטמעה שלהם.
כדי להציג את הדף ניהול מדדים:
-
נכנסים לדף Metrics management במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Monitoring.
- בסרגל הכלים, בוחרים את חלון הזמן. כברירת מחדל, בדף ניהול מדדים מוצג מידע על המדדים שנאספו ביום הקודם.
מידע נוסף על הדף ניהול מדדים זמין במאמר איך רואים ומנהלים את השימוש במדדים.
בקטעים הבאים מתוארות דרכים לנתח את מספר הדגימות שאתם שולחים אל שירות מנוהל ל-Prometheus ולשייך נפח גבוה למדדים ספציפיים, למרחבי שמות של Kubernetes ולאזורים. Google Cloud
זיהוי מדדים עם נפח גבוה
כדי לזהות את מדדי Prometheus עם נפחי ההטמעה הגדולים ביותר, מבצעים את הפעולות הבאות:
-
נכנסים לדף Metrics management במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Monitoring.
- בכרטיס המידע דוגמאות לחיוב שהמערכת עיבדה, לוחצים על הצגת תרשימים.
- מחפשים את התרשים Namespace Volume Ingestion ולוחצים על more_vert More chart options (אפשרויות נוספות לתרשים).
- בוחרים באפשרות התרשים View in Metrics Explorer (הצגה בכלי לבדיקת מדדים).
- בחלונית Builder של Metrics Explorer, משנים את השדות באופן הבא:
- בשדה Metric, מוודאים שסוג המשאב והמדד הבאים נבחרו:
Metric Ingestion Attributionו-Samples written by attribution id. - בשדה Aggregation (צבירת נתונים), בוחרים באפשרות
sum. - בשדה by, בוחרים את התוויות הבאות:
attribution_dimensionmetric_type
- בשדה Filter, משתמשים בערך
attribution_dimension = namespace. צריך לעשות את זה אחרי צבירה לפי התוויתattribution_dimension.
בתרשים שמתקבל מוצגים נפחי ההטמעה של כל סוג מדד.
- בשדה Metric, מוודאים שסוג המשאב והמדד הבאים נבחרו:
- כדי לראות את נפח ההטמעה של כל אחד מהמדדים, במתג עם התווית Chart Table Both, בוחרים באפשרות Both. הנפח של כל מדד שנקלט מוצג בטבלה בעמודה ערך.
- לוחצים פעמיים על כותרת העמודה ערך כדי למיין את המדדים לפי נפח ההטמעה בסדר יורד.
התרשים שמתקבל, שבו מוצגים המדדים המובילים לפי נפח, מדורגים לפי ממוצע, נראה כמו צילום המסך הבא:
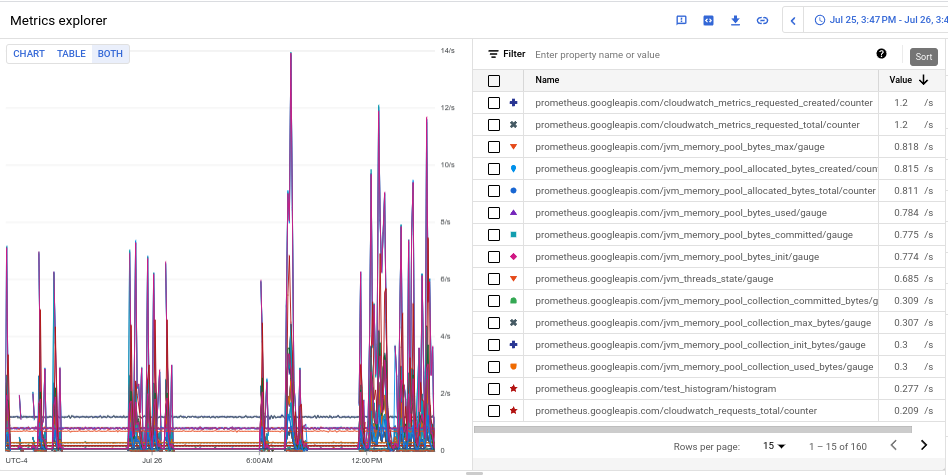
זיהוי מרחבי שמות עם נפח גבוה
כדי לשייך את נפח ההטמעה למרחבי שמות ספציפיים של Kubernetes:
-
נכנסים לדף Metrics management במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שכותרת המשנה שלה היא Monitoring.
- בכרטיס המידע דוגמאות לחיוב שהמערכת עיבדה, לוחצים על הצגת תרשימים.
- מחפשים את התרשים Namespace Volume Ingestion ולוחצים על more_vert More chart options (אפשרויות נוספות לתרשים).
- בוחרים באפשרות התרשים View in Metrics Explorer (הצגה בכלי לבדיקת מדדים).
- בחלונית Builder ב-Metrics Explorer, משנים את השדות באופן הבא:
- בשדה Metric, מוודאים שסוג המשאב והמדד הבאים נבחרו:
Metric Ingestion Attributionו-Samples written by attribution id. - מגדירים את שאר הפרמטרים של השאילתה לפי הצורך:
- כדי ליצור קורלציה בין נפח ההטמעה הכולל לבין מרחבי שמות:
- בשדה Aggregation (צבירת נתונים), בוחרים באפשרות
sum. - בשדה by, בוחרים את התוויות הבאות:
attribution_dimensionattribution_id
- בשדה Filter, משתמשים ב-
attribution_dimension = namespace.
- בשדה Aggregation (צבירת נתונים), בוחרים באפשרות
- כדי ליצור קורלציה בין נפח ההטמעה של מדדים נפרדים לבין מרחבי שמות:
- בשדה Aggregation (צבירת נתונים), בוחרים באפשרות
sum. - בשדה by, בוחרים את התוויות הבאות:
attribution_dimensionattribution_idmetric_type
- בשדה Filter, משתמשים ב-
attribution_dimension = namespace.
- בשדה Aggregation (צבירת נתונים), בוחרים באפשרות
- כדי לזהות את מרחבי השמות שאחראים למדד ספציפי של נפח גבוה:
- כדי לזהות את סוג המדד של המדד עם נפח גבוה, אפשר להשתמש באחת מהדוגמאות האחרות כדי לזהות סוגי מדדים עם נפח גבוה. סוג המדד הוא המחרוזת בתצוגת הטבלה שמתחילה ב-
prometheus.googleapis.com/. מידע נוסף זמין במאמר זיהוי מדדים עם נפח גבוה. - כדי להגביל את נתוני התרשים לסוג המדד שזוהה, מוסיפים מסנן לסוג המדד בשדה מסנן. לדוגמה:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - בשדה Aggregation (צבירת נתונים), בוחרים באפשרות
sum. - בשדה by, בוחרים את התוויות הבאות:
attribution_dimensionattribution_id
- בשדה Filter, משתמשים בערך
attribution_dimension = namespace.
- כדי לזהות את סוג המדד של המדד עם נפח גבוה, אפשר להשתמש באחת מהדוגמאות האחרות כדי לזהות סוגי מדדים עם נפח גבוה. סוג המדד הוא המחרוזת בתצוגת הטבלה שמתחילה ב-
- כדי לראות את ההטמעה לפי Google Cloud אזור, מוסיפים את התווית
locationלשדה by. - כדי לראות את ההטמעה לפי Google Cloud פרויקט, מוסיפים את התווית
resource_containerלשדה by.
- כדי ליצור קורלציה בין נפח ההטמעה הכולל לבין מרחבי שמות:
- בשדה Metric, מוודאים שסוג המשאב והמדד הבאים נבחרו: