
במאמר הזה מוסבר איך להגדיר סביבה שמשלבת בין אמצעי איסוף שמוצבים באופן עצמאי לבין אמצעי איסוף מנוהלים, בפרויקטים ובאשכולות שונים שלGoogle Cloud .
מומלץ מאוד להשתמש באוסף מנוהל בכל סביבות Kubernetes. כך אפשר למעשה לבטל את התקורה של הפעלת אוספי Prometheus באשכול. אפשר להפעיל אוספים מנוהלים ואוספים שמוצבים באופן עצמאי באותו אשכול. מומלץ להשתמש בגישה עקבית למעקב, אבל יכול להיות שתבחרו לשלב שיטות פריסה מסוימות לתרחישי שימוש ספציפיים, כמו אירוח של שער לדחיפה, כפי שמודגם במסמך הזה.
התרשים הבא ממחיש הגדרה שבה נעשה שימוש בשניGoogle Cloud פרויקטים, בשלושה אשכולות ובשילוב של איסוף מנוהל ואיסוף בהטמעה עצמית. אם אתם משתמשים רק באיסוף מנוהל או באיסוף שמוטמע באופן עצמאי, התרשים עדיין רלוונטי. פשוט מתעלמים מסגנון האיסוף שבו אתם לא משתמשים:
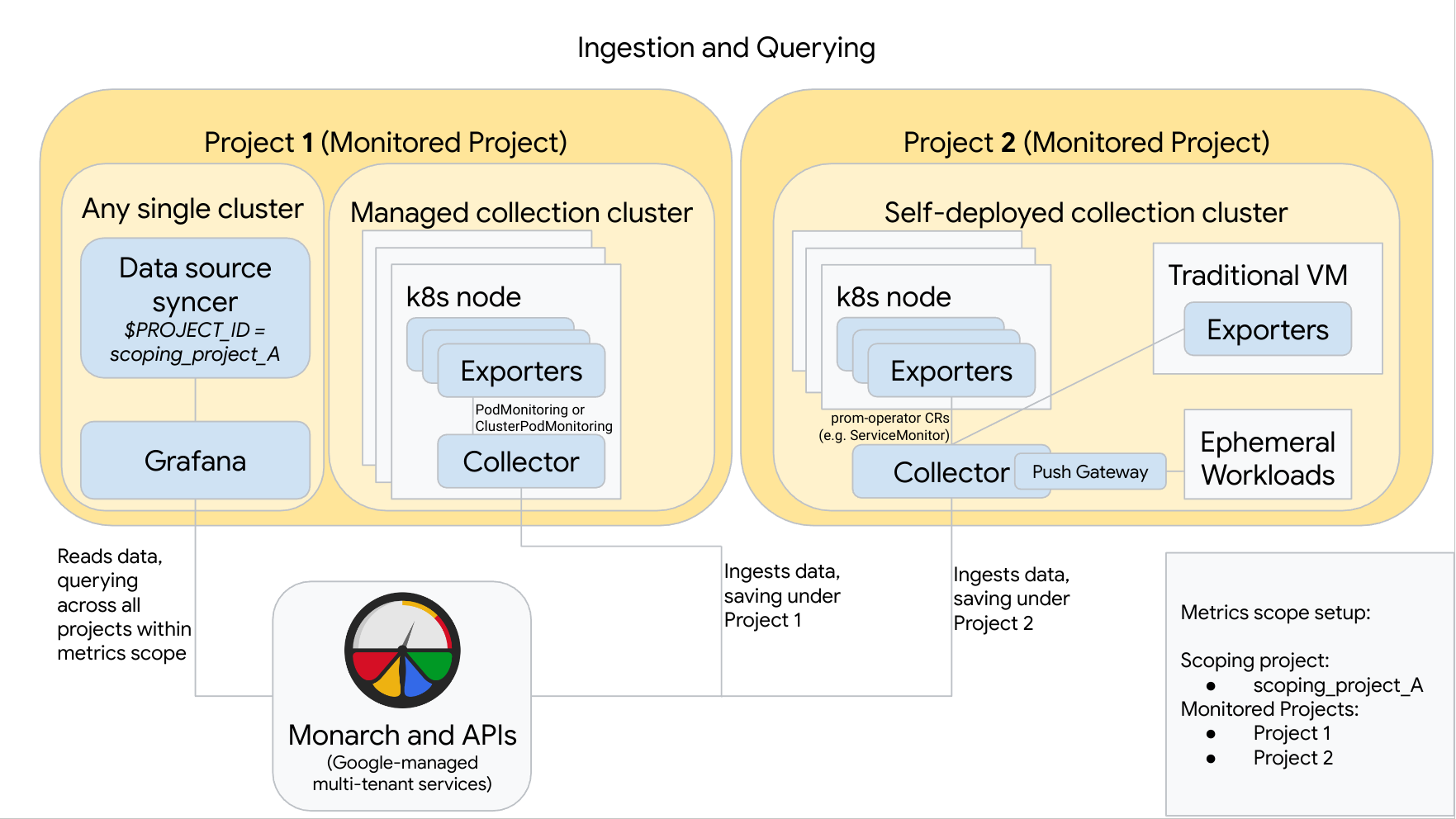
כדי להגדיר ולהשתמש בתצורה כמו זו שבדיאגרמה, חשוב לשים לב לנקודות הבאות:
צריך להתקין את כל הכלי לייצוא הנדרש באשכולות. השירות המנוהל של Google Cloud ל-Prometheus לא מתקין אף כלי לייצוא נתונים בשמכם.
בפרויקט 1 פועל אשכול של איסוף מנוהל, שפועל כסוכן צומת. ההגדרות של האוספים מתבצעות באמצעות משאבי PodMonitoring כדי לבצע גירוד של יעדים במרחב שמות, ומשאבי ClusterPodMonitoring כדי לבצע גירוד של יעדים באשכול. צריך להחיל PodMonitorings בכל מרחב שמות שבו רוצים לאסוף מדדים. ההגדרות של ClusterPodMonitorings מוחלות פעם אחת לכל אשכול.
כל הנתונים שנאספים בפרויקט 1 נשמרים ב-Monarch בקטע Project 1. הנתונים האלה מאוחסנים כברירת מחדל באזור Google Cloud שממנו הם נשלחו.
בפרויקט 2 יש אשכול שפועל בו איסוף שבוצע בהגדרה עצמית באמצעות prometheus-operator, והוא פועל כשירות עצמאי. האשכול הזה מוגדר לשימוש ב-PodMonitors או ב-ServiceMonitors של prometheus-operator כדי לגרד נתונים ממודולי exporter ב-pods או במכונות וירטואליות.
בפרויקט 2 מתארח גם קובץ sidecar של שער push כדי לאסוף מדדים מעומסי עבודה זמניים.
כל הנתונים שנאספים בפרויקט 2 נשמרים ב-Monarch בקטע Project 2. הנתונים האלה מאוחסנים כברירת מחדל באזור Google Cloud שממנו הם נשלחו.
בפרויקט 1 פועל גם אשכול של Grafana ושל data source syncer. בדוגמה הזו, הרכיבים האלה מתארחים באוסף עצמאי, אבל הם יכולים להתארח בכל אוסף יחיד.
הכלי לסנכרון מקורות נתונים מוגדר לשימוש ב-scoping_project_A, ולחשבון השירות הבסיסי שלו יש הרשאות Monitoring Viewer ל-scoping_project_A.
כשמשתמש מריץ שאילתות מ-Grafana, Monarch מרחיב את scoping_project_A לפרויקטים המנוטרים שמרכיבים אותו ומחזיר תוצאות גם עבור Project 1 וגם עבור Project 2 בכל האזורים Google Cloud . כל המדדים שומרים על התוויות המקוריות שלהם
project_idו-location(Google Cloud אזור) למטרות קיבוץ וסינון.
אם האשכול לא פועל בתוך Google Cloud, צריך להגדיר ידנית את התוויות project_id ו-location. מידע על הגדרת הערכים האלה זמין במאמר בנושא הפעלת שירות מנוהל ל-Prometheus מחוץ ל-Google Cloud.
אין לבצע איחוד כשמשתמשים בשירות מנוהל ל-Prometheus. כדי לצמצם את הקרדינליות ואת העלות על ידי צבירת נתונים לפני שליחתם ל-Monarch, כדאי להשתמש בצבירה מקומית. למידע נוסף, קראו את המאמר הגדרת צבירה מקומית.