
אופרטורים מבוזרים פועלים על פני כמה שרתים, בניגוד לאופרטורים מסוג עלה, אונרי, בינארי או n-ארי.
האופרטורים הבאים הם אופרטורים מבוזרים:
סכימת מסד נתונים
השאילתות ותוכניות הביצוע בדף הזה מבוססות על סכימת מסד הנתונים הבאה:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
אפשר להשתמש בהצהרות הבאות של שפת טיפול בנתונים (DML) כדי להוסיף נתונים לטבלאות האלה:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
האופרטור המאוחד המבוזר הוא האופרטור הפרימיטיבי שממנו נגזרים האופרטורים distributed cross apply ו-distributed outer apply.
אופרטורים מבוזרים מופיעים בתוכניות ביצוע עם וריאציה של איחוד מבוזר מעל וריאציה אחת או יותר של איחוד מבוזר מקומי. וריאציה של איחוד מבוזר מבצעת את ההפצה מרחוק של תוכניות משנה.
וריאציה של איחוד מבוזר מקומי מופיעה מעל כל הסריקות שבוצעו עבור השאילתה. הווריאציות המקומיות של איחוד מבוזר מבטיחות הרצה יציבה של שאילתות כשמתרחלים הפעלות מחדש של גבולות פיצול שמשתנים באופן דינמי. למרות שהאופרטור הזה מוסתר מהתוכנית החזותית, הוא תמיד קיים.
כשאפשר, וריאנט של איחוד מבוזר משתמש בפרדיקט מפוצל לגיזום מפוצל. המשמעות של חלוקה לגיזום היא שהשרתים המרוחקים מבצעים תוכניות משנה רק בחלוקות שמספקות את התנאי, וכך משפרים את זמן האחזור ואת ביצועי השאילתות.
איחוד מבוזר
מבחינה רעיונית, אופרטור איחוד מבוזר מחלק טבלה אחת או יותר לכמה פיצולים, מעריך מרחוק שאילתת משנה באופן עצמאי בכל פיצול, ואז מאחד את כל התוצאות.
השאילתה הבאה מדגימה את האופרטור הזה:
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
תוכנית הביצוע מוצגת כך:
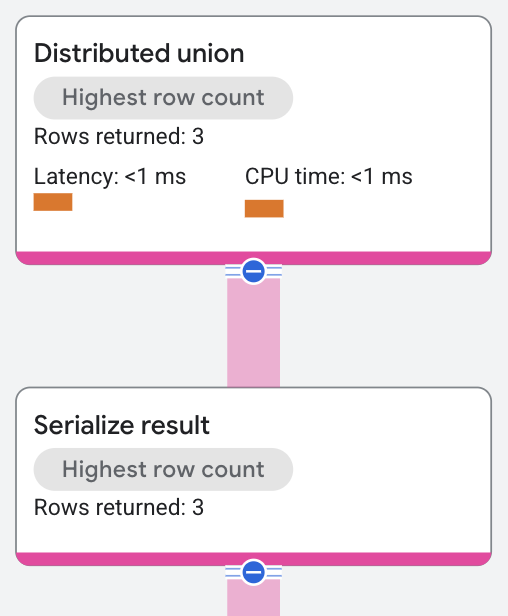
אופרטור האיחוד המבוזר שולח תוכניות משנה לשרתים מרוחקים, שמבצעים סריקה של טבלה על פני פיצולים שעומדים בפרדיקט של השאילתה WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK'.
אופרטור serialize result
מחשב את הערכים SongName ו-SongGenre
מהשורות שמוחזרות על ידי סריקות הטבלה. אחר כך, אופרטור האיחוד המבוזר מחזיר את התוצאות המשולבות מהשרתים המרוחקים כתוצאות של שאילתת ה-SQL.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
לאופרטור Distributed union יש נתונים סטטיסטיים נוספים של ביצועים נפרדים.מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| ביצועים מקבילים מקומיים | מספר שאילתות המשנה שמופעלות במקביל. |
| שיחות מרחוק | מספר שאילתות המשנה המרוחקות שהופעלו. |
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |
בדרך כלל, ההרצה מתבצעת במקביל, בניגוד להרצה של cross apply. לכן, מספרי השהייה באופרטורים מבוזרים הם מצטברים, בניגוד לרוב האופרטורים שמדווחים על השהייה שהאופרטור הוסיף. מספר ההרצות של איחוד מבוזר מבוסס על גבולות הפיצול של הטבלה, שבתורם תלויים בגודל הנתונים ובטעינה, ועשויים לכלול את רמז ההצהרה use_additional_parallelism. הגישה הזו לסטטיסטיקות חלה על כל האופרטורים המבוזרים.
החלה מבוזרת
אופרטור distributed apply (DA) מרחיב את אופרטור apply join על ידי ביצוע פעולות בכמה שרתים. הקלט מצד שמאל מקבץ שורות לקבוצות (בניגוד לאופרטור רגיל של cross apply, שפועל על שורת קלט אחת בכל פעם). הצד של מפת ה-DA הוא קבוצה של אופרטורים פשוטים של צירוף שמופעלים בשרתים מרוחקים. הפעולה distributed apply join תומכת באותן שיטות של הפעולה apply join.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
לאופרטור Distributed apply יש נתונים סטטיסטיים נוספים של ביצועים נפרדים.מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| ביצועים מקבילים מקומיים | מספר שאילתות המשנה שמופעלות במקביל. |
| שיחות מרחוק | מספר שאילתות המשנה המרוחקות שהופעלו. |
| מספר אצוות | חבילה היא אוסף דינמי של שורות שעוברות עיבוד באותו הזמן. המדד הזה מראה את מספר האצוות של פעולת הצלבה מבוזרת שנשלחו מהקלט לצד המיפוי. |
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |
Distributed cross apply
השאילתה הבאה מדגימה את האופרטור הזה:
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
תוכנית הביצוע מוצגת כך:
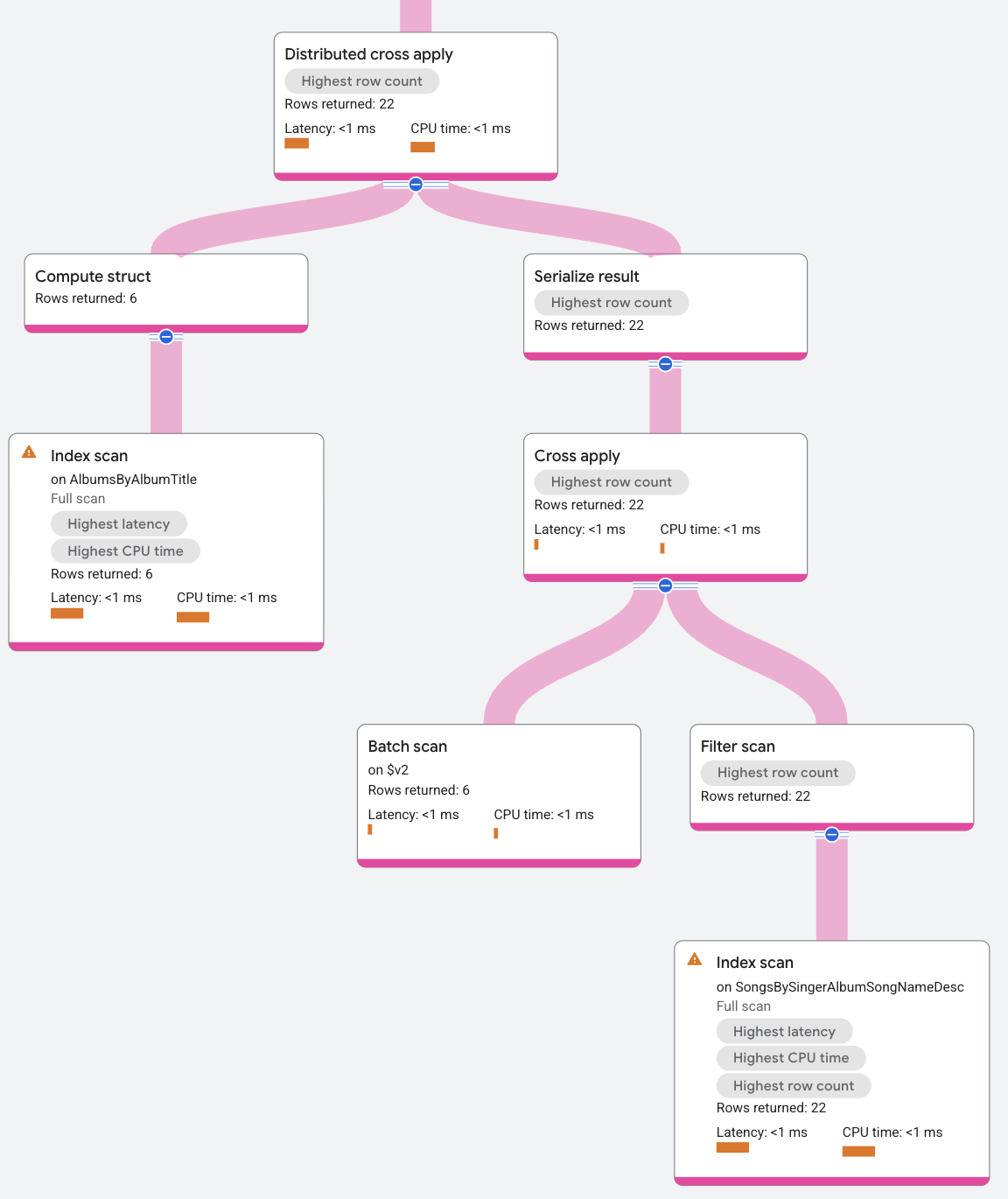
הקלט של ה-DCA מכיל סריקה של האינדקס SongsBySingerAlbumSongNameDesc, שמקבץ שורות של AlbumId. הצד של המיפוי ב-DCA הוא פעולת הצלבה רגילה, שבה הקלט הוא קבוצת שורות, והצד של המיפוי הוא סריקת אינדקס באינדקס AlbumsByAlbumTitle, בכפוף לתנאי AlbumId בשורת הקלט שתואם למפתח AlbumId באינדקס AlbumsByAlbumTitle. המיפוי מחזיר את SongName עבור הערכים SingerId בשורות הקלט של האצווה.
לסיכום תהליך ה-DCA בדוגמה הזו, הקלט של ה-DCA הוא שורות באצ' מתוך הטבלה Albums, והפלט של ה-DCA הוא היישום של השורות האלה על המפה של סריקת האינדקס.
החלת outer apply מבוזרת
Distributed outer apply הוא DA עם סמנטיקה של איחוד חיצוני שמאלי. פרטים על הסמנטיקה מופיעים במאמר בנושא outer apply.
השאילתה הבאה מדגימה את האופרטור הזה:
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
תוכנית הביצוע מוצגת כך:
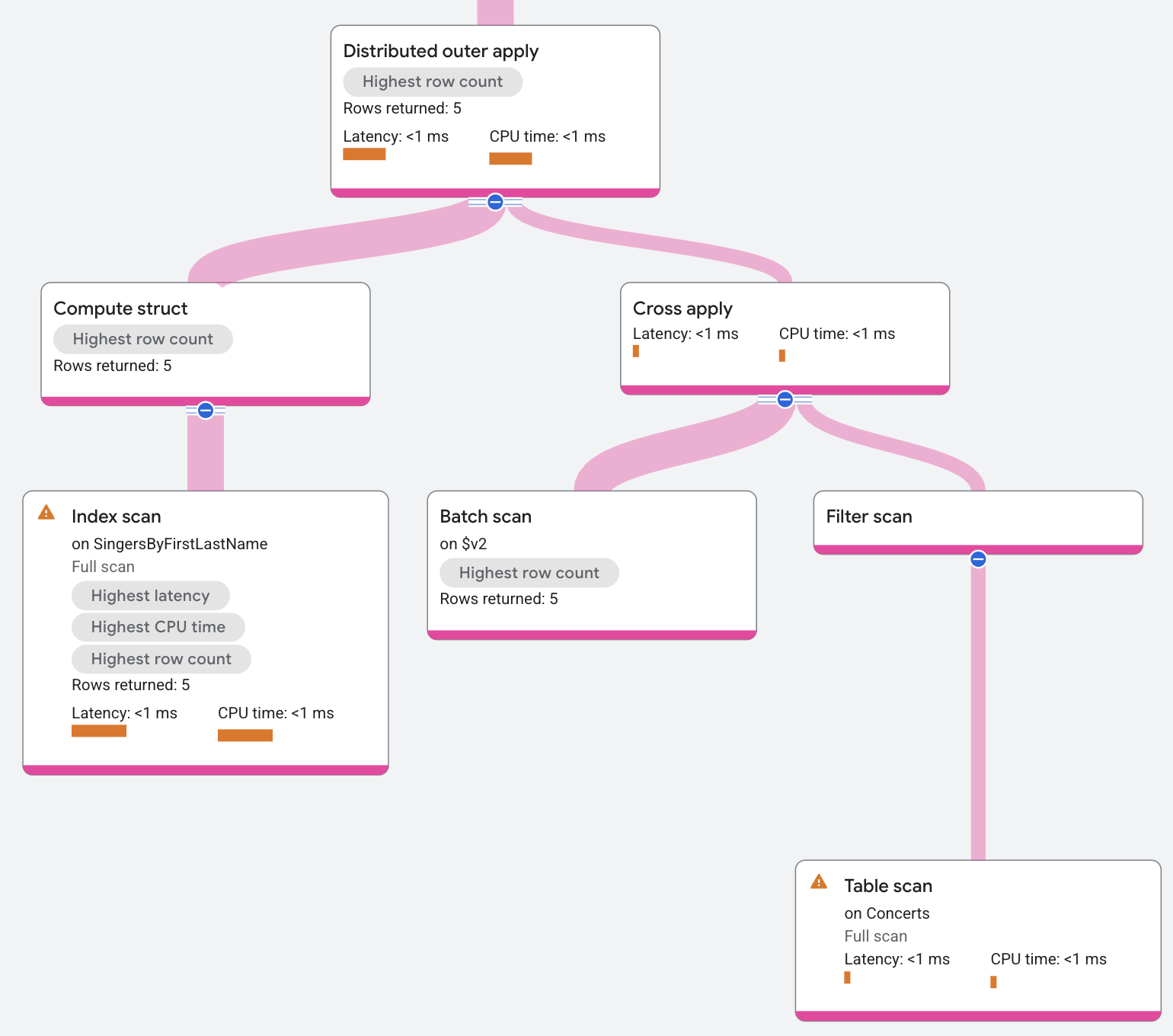
החלה חלקית של חלוקה
הפעלת חצי הצטרפות מבוזרת היא DA עם סמנטיקה של חצי הצטרפות. פרטים על הסמנטיקה מופיעים במאמר בנושא semi apply.
Distributed anti-semi apply
הצטרפות אנטי-סמי מבוזרת היא הצטרפות מבוזרת עם סמנטיקה של הצטרפות אנטי-סמי. פרטים על הסמנטיקה מופיעים במאמר בנושא החלת אנטי-סמנטיקה.
איחוד מפוזר
האופרטור distributed merge union מפזר שאילתה בין כמה שרתים מרוחקים. לאחר מכן, המערכת משלבת את תוצאות השאילתה כדי ליצור תוצאה ממוינת, שנקראת מיון מיזוג מבוזר.
מיזוג מבוזר מבצע את השלבים הבאים:
שרת הבסיס שולח שאילתת משנה לכל שרת מרוחק שמארח פיצול של הנתונים שנכללים בשאילתה. שאילתת המשנה כוללת הוראות למיון התוצאות בסדר מסוים.
כל שרת מרוחק מריץ את שאילתת המשנה על החלק שלו, ואז שולח את התוצאות בחזרה לפי הסדר המבוקש.
שרת הבסיס ממזג את שאילתת המשנה הממוינת כדי ליצור תוצאה ממוינת לחלוטין.
האיחוד המבוזר של מיזוג מופעל כברירת מחדל ב-Spanner בגרסה 3 ואילך.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
לאופרטור Distributed apply יש נתונים סטטיסטיים נוספים של ביצועים נפרדים.מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| ביצועים מקבילים מקומיים | מספר שאילתות המשנה שמופעלות במקביל. |
| שיחות מרחוק | מספר שאילתות המשנה המרוחקות שהופעלו. |
| מספר אצוות | חבילה היא אוסף דינמי של שורות שעוברות עיבוד באותו הזמן. המדד הזה מראה את מספר האצוות של פעולת הצלבה מבוזרת שנשלחו מהקלט לצד המיפוי. |
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |
הצטרפות לגיבוב (Hash) של שידור דחיפה
אופרטור push broadcast hash join הוא הטמעה מבוזרת של שאילתות איחוד (join) ב-SQL שמבוססת על hash join. האופרטור push broadcast hash join קורא שורות מצד הקלט כדי ליצור אצווה של נתונים. המפעיל משדר את האצווה הזו לכל השרתים שמכילים נתונים של צד המפה. בשרתי היעד שבהם מתקבלת אצווה של נתונים, האופרטור יוצר הצטרפות גיבוב באמצעות האצווה כנתוני הצד של הגיבוב, וסורק את הנתונים המקומיים כצד הבדיקה של הצטרפות הגיבוב.
ל-Push broadcast hash join יש את היתרונות הבאים:
- אם טבלת ה-build קטנה, אפשר לשלוח אותה לכל החלקים של המפה.
- אפשר לסרוק את הטבלה הצדדית של המפה, עם או בלי מסננים שיוריים. המצב הזה קורה כשמפתחות הצירוף לא זהים למפתחות הראשיים של טבלת המיפוי.
האפשרות Push broadcast hash join לא נבחרת אוטומטית על ידי הכלי לאופטימיזציה. כדי להשתמש באופרטור הזה, צריך להגדיר את שיטת הצירוף ל-PUSH_BROADCAST_HASH_JOIN ברמז לשאילתה, כמו בדוגמה הבאה:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
תוכנית הביצוע מוצגת כך:
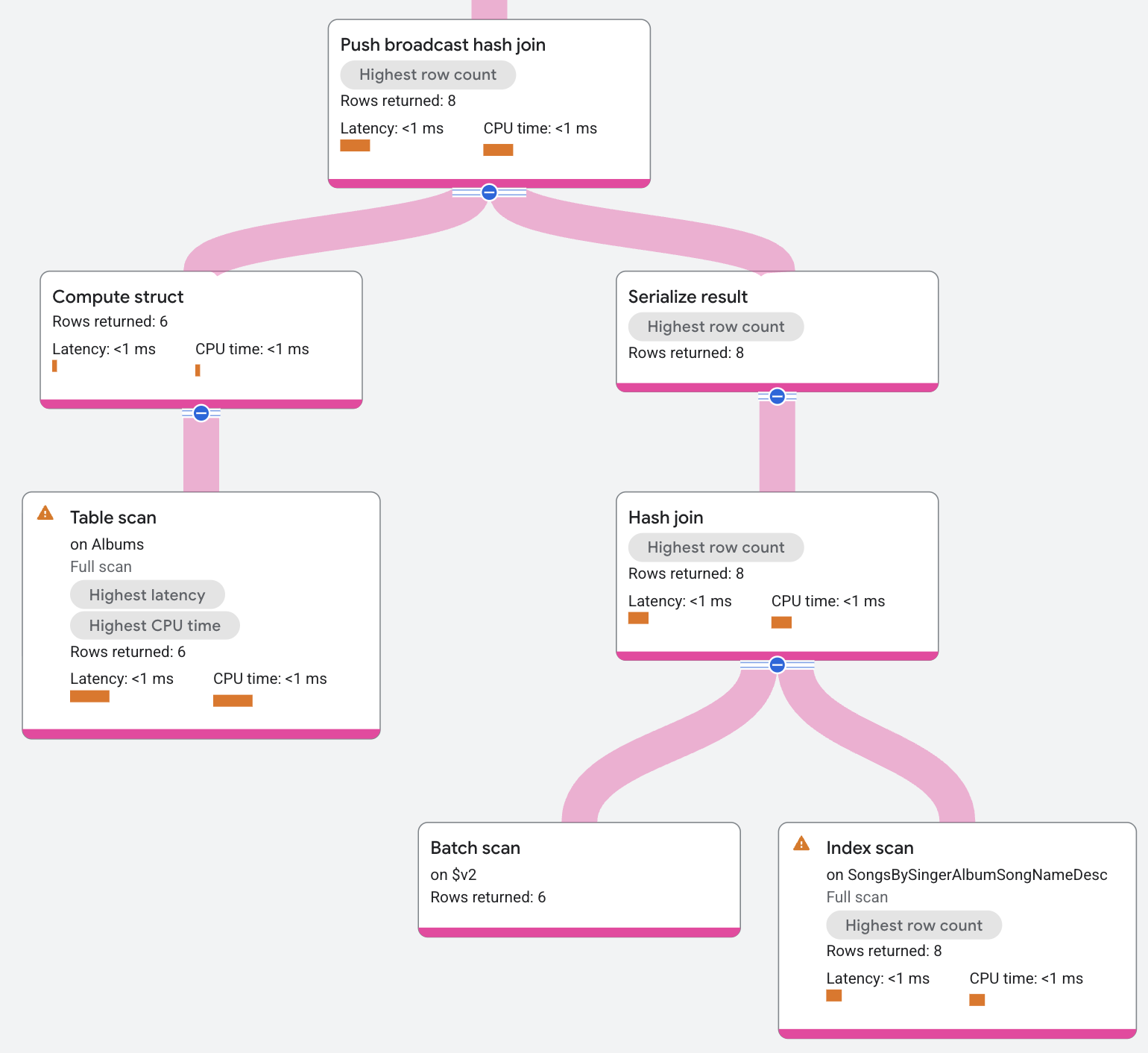
הקלט ל-Push broadcast hash join הוא אינדקס AlbumsByAlbumTitle.
המפעיל מבצע סריאליזציה של הקלט הזה לחבילת נתונים. המפעיל שולח את האצווה לכל הפיצולים המקומיים של האינדקס SongsBySingerAlbumSongNameDesc, שבהם המפעיל מבטל את הסריאליזציה של האצווה ובונה אותה בטבלת גיבוב. לאחר מכן, טבלת הגיבוב משתמשת בנתוני האינדקס המקומי כבדיקה שמחזירה התאמות כתוצאה.
יכול להיות שגם התוצאות התואמות יסוננו לפי תנאי שיורי לפני שהן יוחזרו. (דוגמה למקום שבו מופיעים תנאים שיוריים היא בחיבורים של אי-שוויון).
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
לאופרטור Distributed apply יש נתונים סטטיסטיים נוספים של ביצועים נפרדים.מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| ביצועים מקבילים מקומיים | מספר שאילתות המשנה שמופעלות במקביל. |
| שיחות מרחוק | מספר שאילתות המשנה המרוחקות שהופעלו. |
| מספר אצוות | חבילה היא אוסף דינמי של שורות שעוברות עיבוד באותו הזמן. המדד הזה מראה את מספר האצוות של פעולת הצלבה מבוזרת שנשלחו מהקלט לצד המיפוי. |
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |