
לאופרטור בינארי יש שני צאצאים יחסיים. האופרטורים הבאים הם אופרטורים בינאריים:
סכימת מסד נתונים
השאילתות ותוכניות הביצוע בדף הזה מבוססות על סכימת מסד הנתונים הבאה:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
אפשר להשתמש בהצהרות הבאות של שפת טיפול בנתונים (DML) כדי להוסיף נתונים לטבלאות האלה:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
החלת הצטרפות
apply join הוא אופרטור הצירוף הראשי שמשמש את Spanner. אופרטורים של Apply join מבצעים עיבוד לפי שורות, בניגוד לאופרטורים שמבצעים עיבוד מבוסס-קבוצות כמו hash join. לאופרטור apply יש שני קלטים: input (צאצא שמאלי) ו-map (צאצא ימני). האופרטור apply מחיל כל שורה בצד הקלט על הצד של המיפוי באמצעות שיטת apply: cross, outer, semi או anti-semi. בנוסף, גרסה של apply join מופיעה גם בצד המפה של Distributed apply.
האופרטור Apply join הכי יעיל כש:
- הקרדינליות של הקלט נמוכה.
- מפתח האיחוד הוא קידומת של המפתח הראשי בצד המפה.
- השאילתה מצטרפת לשתי טבלאות משולבות.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |
החלה מוצלבת
הפעולה Cross apply מבצעת צירוף פנימי שבו מוחזרות רק שורות תואמות.
השאילתה הבאה מדגימה את האופרטור הזה:
השאילתה מבקשת את השם הפרטי של כל זמר, יחד עם השם של רק אחד מהשירים של הזמר.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
השאילתה מאכלסת את העמודה הראשונה מהטבלה Singers ואת העמודה השנייה מהטבלה Songs. אם SingerId מסוים היה קיים בטבלה Singers אבל לא היה SingerId תואם בטבלה Songs, בעמודה השנייה יופיע הערך NULL.
תוכנית הביצוע מתחילה כך:
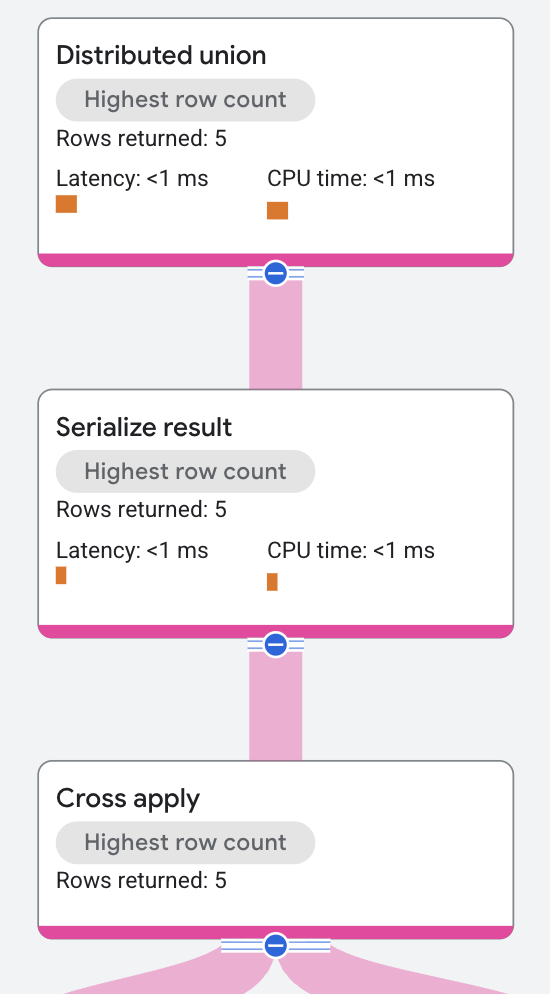
הצומת ברמה העליונה הוא אופרטור של איחוד מבוזר. אופרטור האיחוד המבוזר מחלק תוכניות משנה לשרתים מרוחקים. תת-התוכנית מכילה את האופרטור serialize result שמחשב את השם הפרטי של הזמר ואת השם של אחד מהשירים של הזמר, ומבצע סריאליזציה של כל שורה בפלט.
אופרטור התוצאה של serialize מקבל את הקלט שלו מאופרטור cross apply.
הקלט של אופרטור ההצבה הוא סריקה של הטבלה Singers.
תוכנית הביצוע ממשיכה כך:
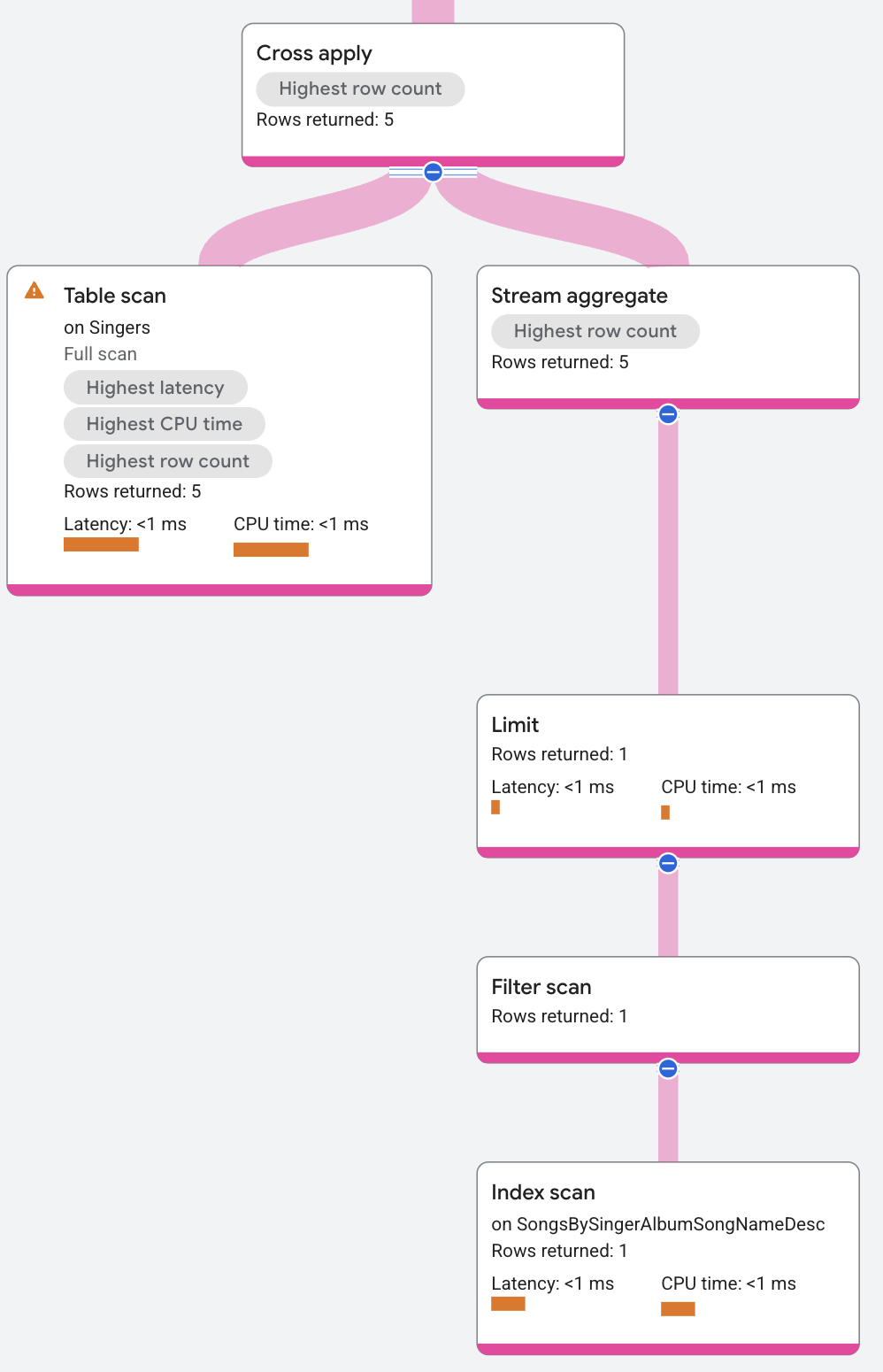
הצד של המיפוי בפעולת ההחלה הצולבת מכיל את הרכיבים הבאים (מלמעלה למטה):
- אופרטור מצטבר שמחזיר
Songs.SongName. - אופרטור limit שמגביל את מספר השירים שמוחזרים לאחד לכל זמר.
- סריקת אינדקס באינדקס
SongsBySingerAlbumSongNameDesc.
האופרטור cross apply ממפה כל שורה מצד הקלט לשורה בצד המיפוי עם אותו SingerId. הפלט של האופרטור cross apply הוא הערך FirstName משורת הקלט והערך SongName משורת המיפוי.
(הערך SongName הוא NULL אם אין שורת מיפוי שתואמת ל-SingerId). אופרטור האיחוד המבוזר בחלק העליון של תוכנית הביצוע משלב את כל שורות הפלט מהשרתים המרוחקים ומחזיר אותן כתוצאות השאילתה.
החלה חיצונית
outer apply מספק סמנטיקה של איחוד חיצוני שמאלי. היא מוודאת שכל הרצה בצד המפה מחזירה לפחות שורה אחת על ידי הוספת ריפוד NULL אם צריך.
הפעלת בלימה
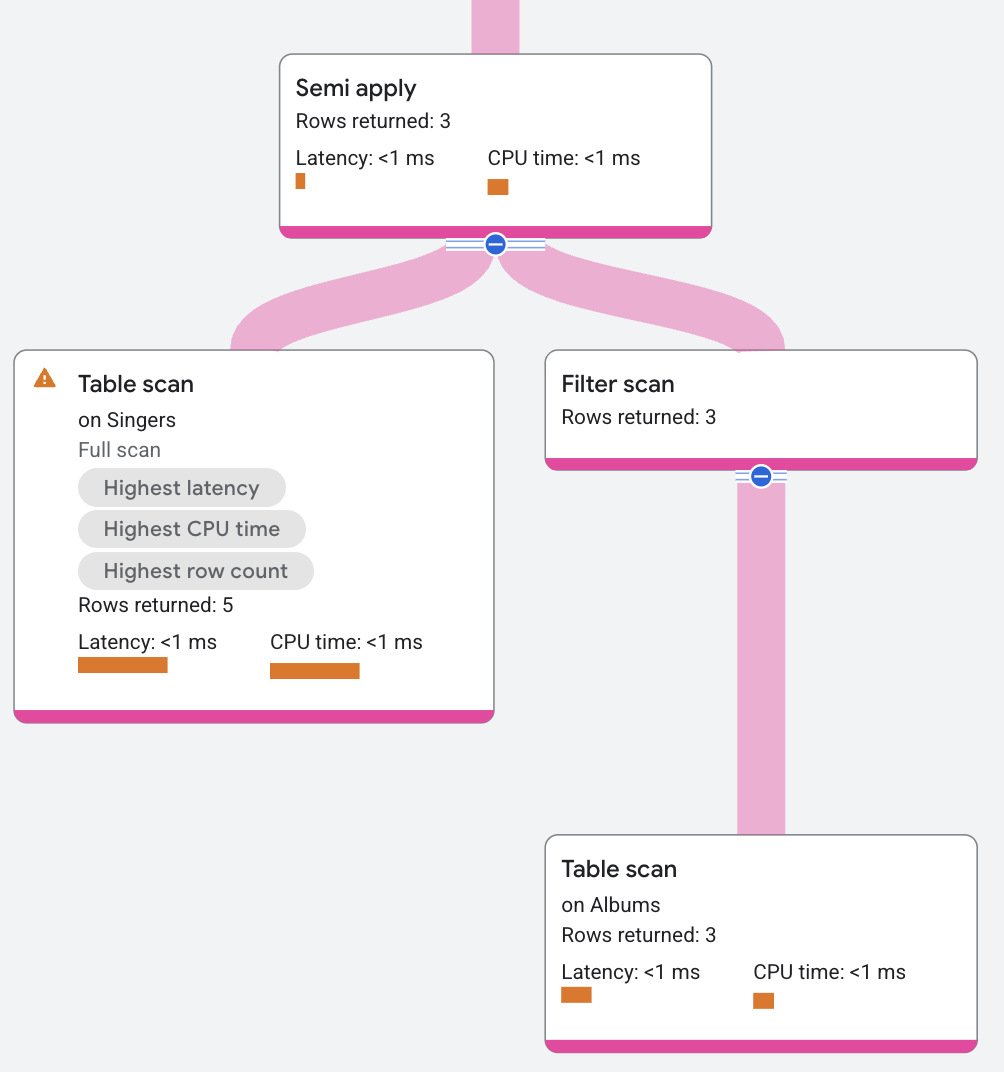
האופרטור semi apply מחזיר עמודות קלט רק אם יש התאמה בצד המיפוי.
השאילתה הבאה משתמשת ב-semi join כדי למצוא אילו זמרים יש להם אלבום:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
פלח התוכנית יופיע כך:
החלת אנטי-סמי
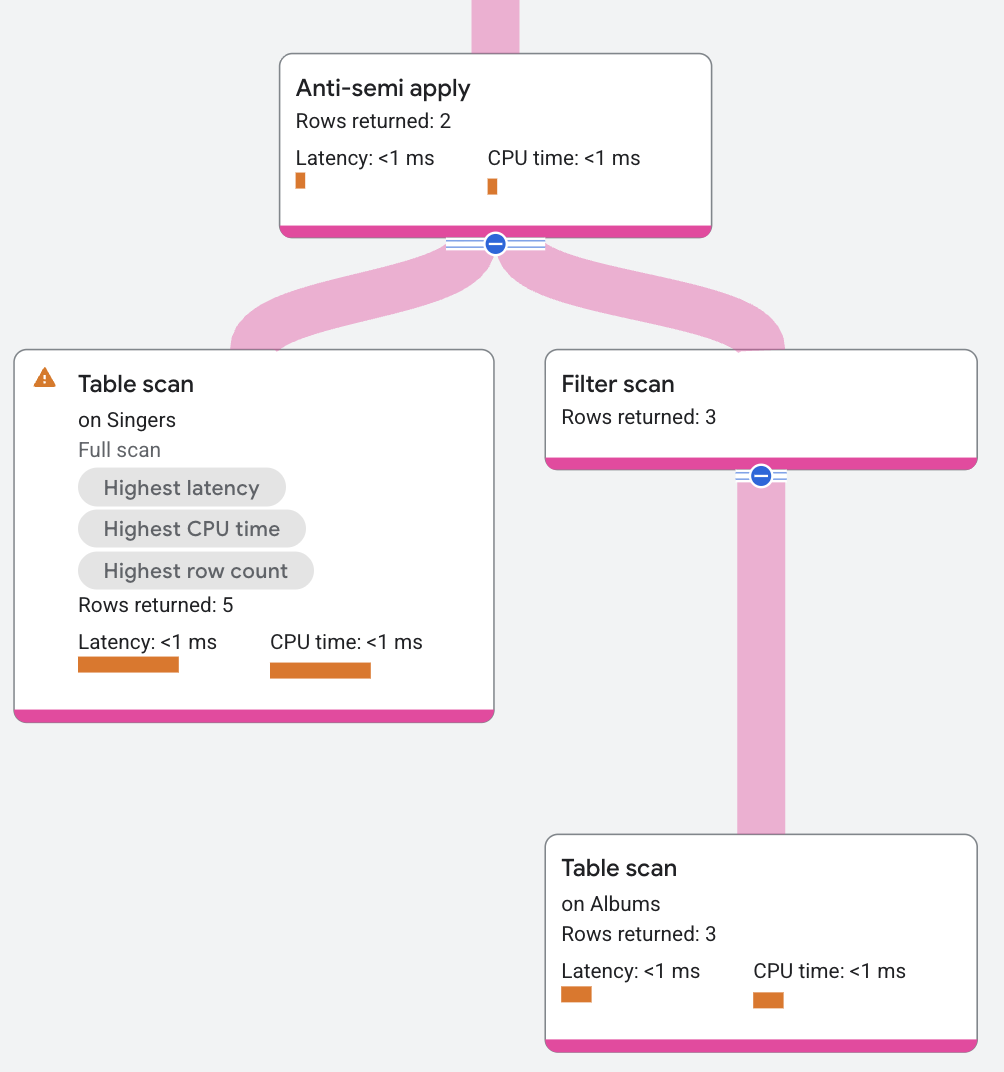
אופרטור Anti-semi apply דומה לאופרטור semi apply, רק שהוא מחזיר את העמודות של טבלת הקלט רק כשאין התאמה בצד המיפוי.
השאילתה הבאה משתמשת ב-anti-semi join כדי למצוא אילו זמרים לא מופיעים בטבלה Album:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
פלח התוכנית יופיע כך:
Hash join
אופרטור hash join הוא הטמעה מבוססת-גיבוב של שאילתות איחוד (join) ב-SQL. הצטרפות גיבוב מבצעת עיבוד מבוסס-קבוצה. האופרטור hash join קורא שורות מקלט שמסומן כ-build (צאצא שמאלי) ומכניס אותן לטבלת hash על סמך תנאי הצטרפות. לאחר מכן, אופרטור ה-hash join קורא שורות מהקלט שמסומן כ-probe (צאצא ימני). לכל שורה שנקראת מקלט הבדיקה, אופרטור ה-hash join מחפש שורות תואמות בטבלת הגיבוב. אופרטור ה-hash join מחזיר את השורות התואמות כתוצאה.
ל-Hash join יש את היתרונות הבאים:
- לא נדרש מיון של נתוני הקלט
- הוא מחשב מסנן בלום כשיוצרים את טבלת הגיבוב. האופרטור משתמש במסנן כדי להחריג מהצד של הבדיקה שורות שאין להן התאמות. הערה: זהו מסנן שיורי, ולא מסנן חיפוש.
השאילתה הבאה מדגימה את האופרטור הזה:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
פלח תוכנית הביצוע מופיע כך:
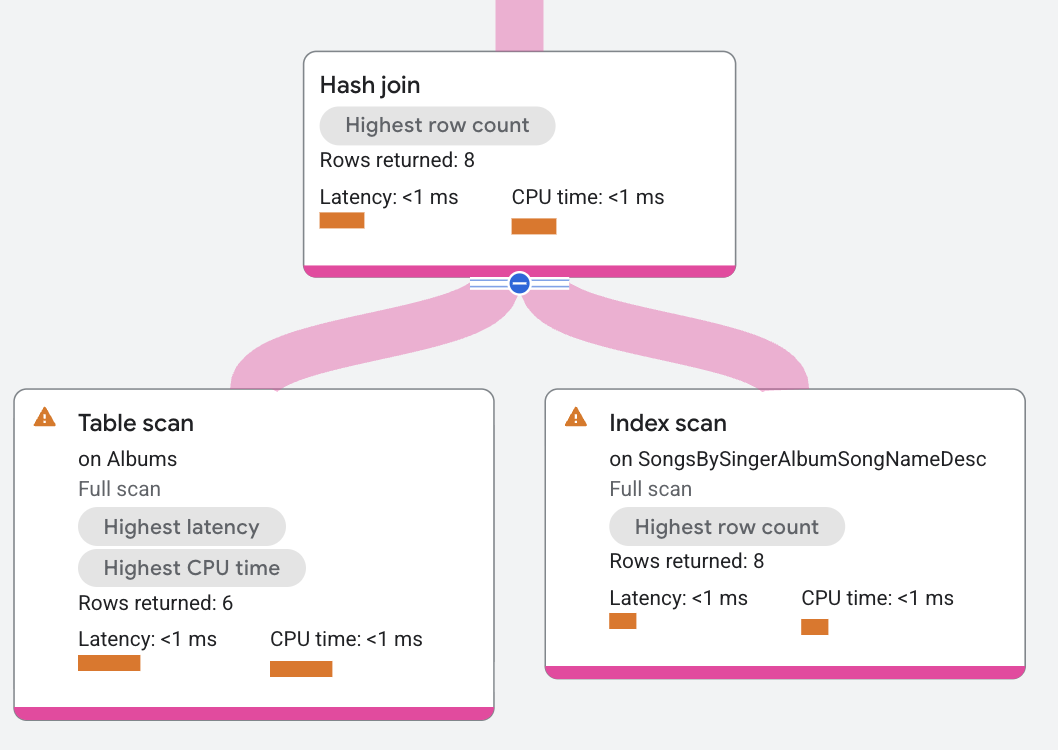
בתוכנית הביצוע, build הוא distributed union שמפיץ scans בטבלה Albums. Probe הוא אופרטור איחוד מבוזר שמפיץ סריקות באינדקס SongsBySingerAlbumSongNameDesc.
האופרטור hash join קורא את כל השורות מהצד של ה-build. כל שורת build מוצבת בטבלת hash על סמך העמודות בתנאי a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId. לאחר מכן, אופרטור ה-hash join קורא את כל השורות מצד הבדיקה. לכל שורת בדיקה, אופרטור ה-hash join מחפש התאמות בטבלת הגיבוב. ההתאמות שמתקבלות מוחזרות על ידי אופרטור ה-hash join.
יכול להיות שגם התאמות שמתקבלות בטבלת הגיבוב יסוננו לפי תנאי שיורי לפני שהן יוחזרו. (דוגמה למקרים שבהם מופיעים תנאים שיוריים היא במקרים של צירופים שאינם שוויון). תוכניות ביצוע של Hash join יכולות להיות מורכבות בגלל ניהול הזיכרון והווריאציות של ה-join. אלגוריתם ה-hash join הראשי מותאם לטיפול בגרסאות של inner join, semi join, anti join ו-outer join.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |
מיזוג
אופרטור merge join הוא הטמעה מבוססת-מיזוג של SQL join. שני הצדדים של הצירוף יוצרים שורות שממוינות לפי העמודות שמשמשות בתנאי הצירוף. הפעולה
merge join צורכת את שני זרמי הקלט בו-זמנית ומפיקה שורות כשהתנאי
join מתקיים. אם הקלט לא ממוין, האופטימיזציה מוסיפה לתוכנית אופרטורים מפורשים של Sort.
ל-Merge join יש את היתרונות הבאים:
- אם הנתונים כבר ממוינים, לא נדרש זיכרון.
- גם אם הנתונים לא ממוינים, עבור הצטרפות מבוזרת, המערכת יכולה לבצע את המיון בכל פיצול בנפרד, במקום ליצור טבלת גיבוב גדולה בשורש.
האפשרות Merge join לא נבחרת אוטומטית על ידי הכלי לאופטימיזציה. כדי להשתמש באופרטור הזה, צריך להגדיר את שיטת הצירוף ל-MERGE_JOIN ברמז לשאילתה, כמו בדוגמה הבאה:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
תוכנית הביצוע מוצגת כך:
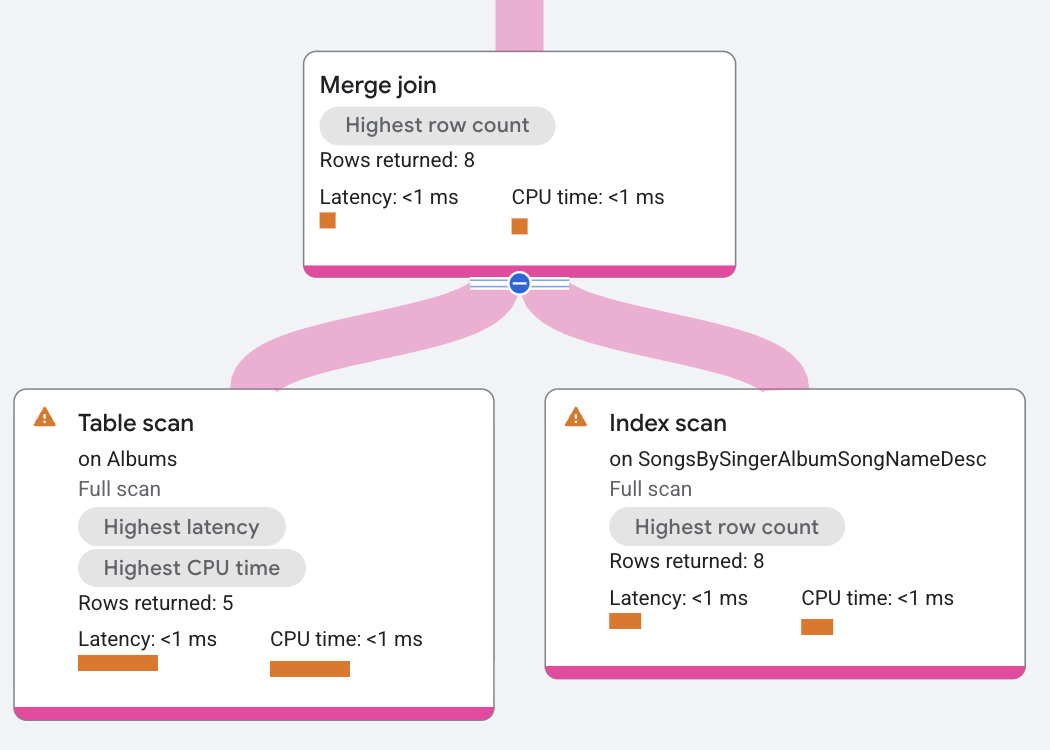
בתוכנית הביצוע הזו, מיזוג ההצטרפות מפוזר כך שההצטרפות מתבצעת במקום שבו הנתונים נמצאים. בנוסף, זה מאפשר לאיחוד המיזוג בדוגמה הזו לפעול ללא אופרטורי מיון נוספים, כי שני סריקות הטבלה כבר ממוינות לפי SingerId, AlbumId, שהוא תנאי האיחוד. בתוכנית הזו, הסריקה השמאלית של הטבלה Albums מתקדמת בכל פעם שהערכים SingerId ו-AlbumId שלה קטנים מהערכים SingerId_1 ו-AlbumId_1 של הסריקה הימנית. באופן דומה, הסריקה מימין מתקדמת בכל פעם שהערכים שלה קטנים מהערכים של הסריקה משמאל. המיזוג המתקדם ממשיך לחפש שורות מקבילות כדי להחזיר שורות תואמות.
דוגמה נוספת למיזוג באמצעות הצטרפות באמצעות השאילתה הבאה:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
תוכנית הביצוע מוצגת כך:
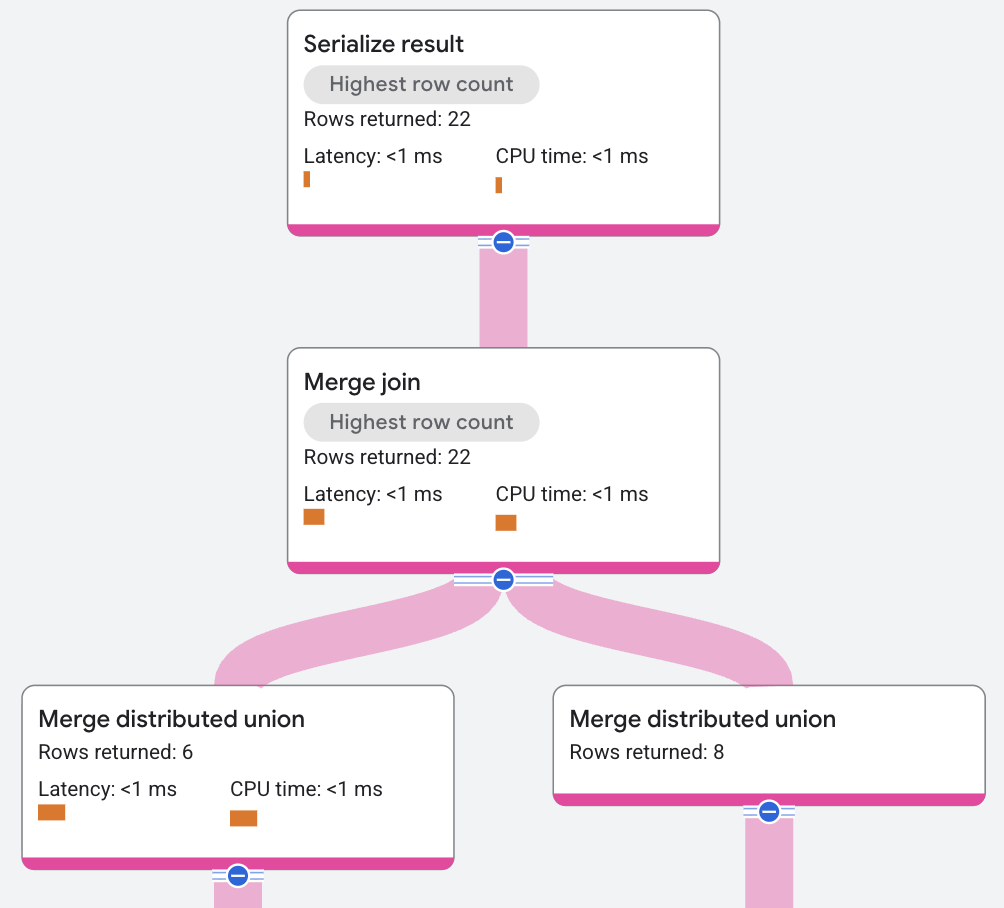
בתוכנית הביצוע הקודמת, האופטימיזציה של השאילתה הציגה אופרטורים נוספים של מיון כדי לבצע את מיזוג ההצטרפות. התנאי JOIN בשאילתת הדוגמה הזו
מוגדר רק על AlbumId, אבל הנתונים לא מאוחסנים כך, ולכן צריך להוסיף מיון. מנוע השאילתות תומך באלגוריתם Distributed Merge, שמאפשר לבצע את המיון באופן מקומי במקום באופן גלובלי, וכך לחלק את עלות השימוש במעבד ולהריץ אותה במקביל.
יכול להיות שההתאמות שיתקבלו יסוננו גם לפי תנאי שיורי. לדוגמה, תנאים שיוריים מופיעים בצירופים של אי-שוויון. תוכניות ביצוע של מיזוג הצטרפות יכולות להיות מורכבות בגלל דרישות מיון נוספות. האלגוריתם העיקרי של מיזוג הצטרפות מטפל בגרסאות של הצטרפות פנימית, חצי הצטרפות, הצטרפות נגדית והצטרפות חיצונית.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |
איחוד רקורסיבי
אופרטור recursive union מבצע איחוד של שני קלטים, אחד שמייצג מקרה base והשני שמייצג מקרה recursive. הוא משמש בשאילתות של גרפים עם מעברים כמותיים בנתיבים. הקלט הבסיסי מעובד קודם ופעם אחת בלבד. הקלט הרקורסיבי מעובד עד שהרקורסיה מסתיימת. הרקורסיה מסתיימת כשמגיעים לגבול העליון, אם הוא צוין, או כשהרקורסיה לא מניבה תוצאות חדשות. בדוגמה הבאה, הטבלה Collaborations נוספת לסכימה, ונוצר גרף מאפיינים בשם MusicGraph.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
שאילתת הגרף הבאה מוצאת זמרים ששיתפו פעולה עם זמר נתון או ששיתפו פעולה עם שותפי העריכה שלו.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
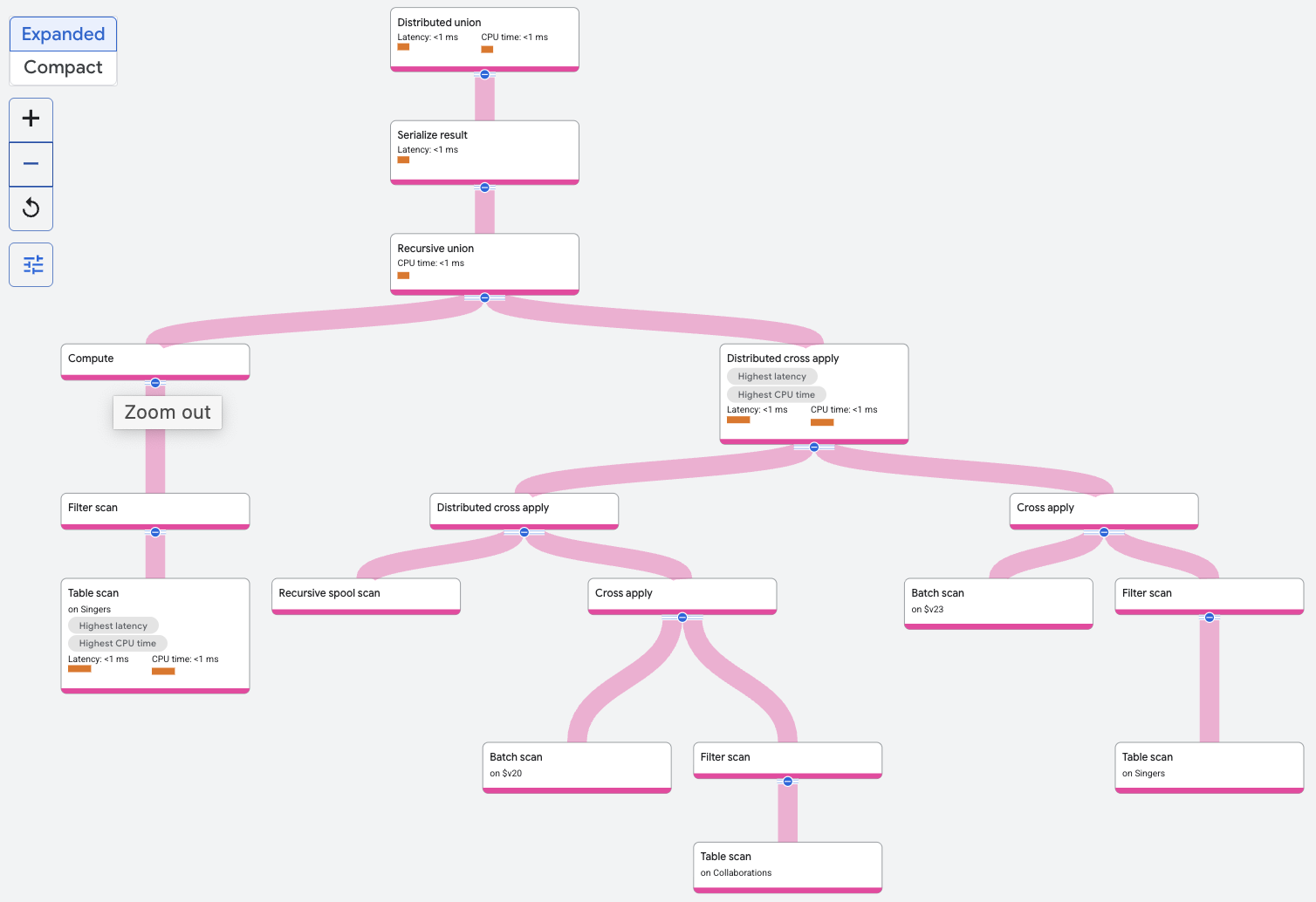
האופרטור recursive union מסנן את הטבלה Singers כדי למצוא את הזמר עם הערך SingerId. זהו קלט הבסיס לאיחוד רקורסיבי. הקלט הרקורסיבי לאיחוד הרקורסיבי כולל הצטרפות צולבת מבוזרת או אופרטור אחר של הצטרפות לשאילתות אחרות שמצטרפות שוב ושוב לטבלה Collaborations עם התוצאות של האיטרציה הקודמת של ההצטרפות. השורות מטופס הקלט הבסיסי יוצרות את האיטרציה האפסית.
בכל איטרציה, הפלט של האיטרציה מאוחסן על ידי recursive spool
scan. השורות מסריקת הסלילים הרקורסיבית מצורפות לטבלה Collaborations ב-spoolscan.featuredSingerId = Collaborations.SingerId. הרקרוסיה מסתיימת אחרי שתי איטרציות, כי זה הגבול העליון שצוין בשאילתה.
מאפיינים ונתונים סטטיסטיים של הרצה
מאפיין של אופרטור מתאר תכונה שמשמשת כשהאופרטור מופעל. סטטיסטיקת ביצוע היא ערך שנאסף במהלך ביצוע השאילתה כדי לעזור לכם להעריך את הביצועים של האופרטור.
מאפיינים
| שם | תיאור |
|---|---|
| שיטת הביצוע | בביצוע שורה, האופרטור מעבד שורה אחת בכל פעם. בביצוע באצ'ים, האופרטור מעבד באצ' של שורות בבת אחת. |
נתוני ביצוע
| שם | תיאור |
|---|---|
| זמן אחזור | הזמן שחלף מאז ההפעלה הראשונה של האופרטור. |
| זמן אחזור מצטבר | הזמן הכולל של האופרטור הנוכחי והצאצאים שלו. |
| זמן CPU (מעבד) | סכום הזמן שהמעבד השקיע בהרצת האופרטור. |
| זמן מצטבר של CPU (יחידת עיבוד מרכזית) | הזמן הכולל של השימוש במעבד (CPU) במהלך ההפעלה של האופרטור ושל צאצאיו. |
| זמן הביצוע | הזמן הכולל שנדרש להרצת השאילתה ולעיבוד התוצאות. |
| שורות שהוחזרו | מספר השורות שהאופרטור הזה מוציא |
| מספר ההפעלות | מספר הפעמים שהאופרטור הופעל. חלק מההרצות יכולות לפעול במקביל. |