
Trino (舊稱 Presto) 是分散式 SQL 查詢引擎,可查詢分散在一個或多個異質資料來源的大型資料集。Trino 可以透過連接器查詢 Hive、MySQL、Kafka 和其他資料來源。本教學課程將示範如何:
- 在 Managed Service for Apache Spark 叢集上安裝 Trino 服務
- 從本機電腦上安裝的 Trino 用戶端查詢公開資料,該用戶端會與叢集上的 Trino 服務通訊
- 透過 Trino Java JDBC 驅動程式,從與叢集上 Trino 服務通訊的 Java 應用程式執行查詢。
目標
- 從 BigQuery 擷取資料
- 以 CSV 檔案的形式將資料載入 Cloud Storage
- 轉換資料:
- 將資料公開為 Hive 外部資料表,讓 Trino 可查詢資料
- 將資料從 CSV 格式轉換為 Parquet 格式,加快查詢速度
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
請建立 Google Cloud 專案和 Cloud Storage bucket,用來存放本教學課程使用的資料。1. 設定專案- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
安裝 Google Cloud CLI。
-
若您採用的是外部識別資訊提供者 (IdP),請先使用聯合身分登入 gcloud CLI。
-
執行下列指令,初始化 gcloud CLI:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
安裝 Google Cloud CLI。
-
若您採用的是外部識別資訊提供者 (IdP),請先使用聯合身分登入 gcloud CLI。
-
執行下列指令,初始化 gcloud CLI:
gcloud init
- 前往 Google Cloud 控制台的 Cloud Storage「Buckets」(值區) 頁面。
- 點選 「Create」(建立)。
- 在「建立 bucket」頁面中,輸入 bucket 資訊。如要前往下一個步驟,請按一下「繼續」。
- 在「開始使用」部分,執行下列操作:
-
在「Choose where to store your data」(選擇資料的儲存位置) 專區中,執行下列操作:
- 選取「位置類型」。
- 從「位置類型」下拉式選單中,選擇要永久儲存 bucket 資料的位置。
- 如果您選取「雙區域」位置類型,也可以使用相關核取方塊啟用強化型複製。
- 如要設定跨值區複製,請選取「透過 Storage 移轉服務新增跨值區複製作業」,然後按照下列步驟操作:
設定跨 bucket 複製作業
- 在「Bucket」選單中選取 bucket。
在「複製設定」部分,按一下「設定」,設定複製作業的設定。
畫面上會顯示「Configure cross-bucket replication」窗格。
- 如要依物件名稱前置字串篩選要複製的物件,請輸入要納入或排除物件的前置字串,然後按一下「新增前置字串」。
- 如要為複製的物件設定儲存空間級別,請從「儲存空間級別」選單中選取儲存空間級別。如果略過這個步驟,複製的物件預設會使用目標值區的儲存空間級別。
- 按一下 [完成]。
- 在「選擇資料儲存方式」部分,執行下列操作:
- 在「選取如何控制物件的存取權」部分,選取 bucket 是否要強制執行禁止公開存取,並為 bucket 的物件選取存取控管方法。
-
在「選擇保護物件資料的方式」部分,執行下列操作:
- 選取「資料保護」下方的任何選項,為 bucket 設定所需項目。
- 如要啟用虛刪除,請按一下「虛刪除政策 (用於資料復原)」核取方塊,並指定要保留物件的天數 (刪除後)。
- 如要設定「物件版本管理」,請勾選「物件版本管理 (用於版本管控)」核取方塊,並指定每個物件的版本數量上限,以及非現行版本失效的天數。
- 如要為物件和 bucket 啟用資料保留政策,請勾選「保留 (符合法規)」核取方塊,然後執行下列操作:
- 如要啟用 Object Retention Lock,請按一下「啟用物件保留功能」核取方塊。
- 如要啟用 Bucket Lock,請按一下「Set bucket retention policy」(設定值區資料保留政策) 核取方塊,然後選擇保留期限的時間單位和長度。
- 如要選擇物件資料的加密方式,請展開「資料加密」部分 (),然後選取「資料加密」方法。
- 選取「資料保護」下方的任何選項,為 bucket 設定所需項目。
- 點選「建立」。
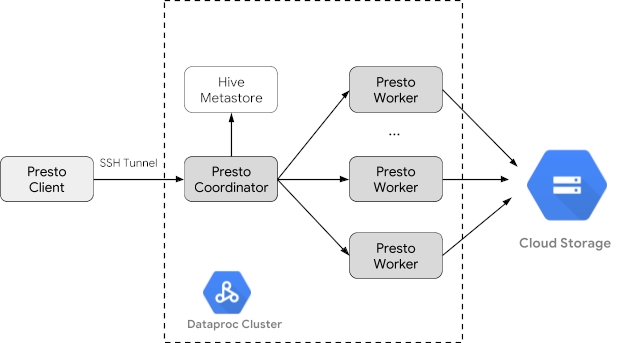
建立 Managed Service for Apache Spark 叢集
使用 optional-components 旗標 (適用於 2.1 以上版本的映像檔) 建立 Managed Service for Apache Spark 叢集,在叢集上安裝 Trino 選用元件,並使用 enable-component-gateway 旗標啟用元件閘道,即可從 Google Cloud 控制台存取 Trino Web UI。
- 設定環境變數:
- PROJECT:您的專案 ID
- BUCKET_NAME:您在「事前準備」中建立的 Cloud Storage bucket 名稱
- REGION:本教學課程所用叢集的建立區域,例如「us-west1」
- WORKERS:建議使用 3 到 5 個 worker 進行本教學課程
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- 在本機電腦上執行 Google Cloud CLI,建立叢集。
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
準備資料
將 bigquery-public-data chicago_taxi_trips 資料集匯出至 Cloud Storage 做為 CSV 檔案,然後建立 Hive 外部資料表以參照資料。
- 在本機上執行下列指令,將 BigQuery 中的計程車資料匯出為不含標題的 CSV 檔案,並匯入您在「事前準備」建立的 Cloud Storage bucket。
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - 建立 Hive 外部資料表,並以 Cloud Storage bucket 中的 CSV 和 Parquet 檔案做為備份。
- 建立 Hive 外部資料表
chicago_taxi_trips_csv。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - 確認 Hive 外部資料表已建立。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - 使用相同的資料欄建立另一個 Hive 外部資料表
chicago_taxi_trips_parquet,但以 Parquet 格式儲存資料,以提升查詢效能。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - 將 Hive CSV 資料表中的資料載入 Hive Parquet 資料表。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - 確認資料已正確載入。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- 建立 Hive 外部資料表
執行查詢
您可以透過 Trino CLI 或應用程式在本機執行查詢。
Trino CLI 查詢
本節將示範如何使用 Trino CLI 查詢 Hive Parquet 計程車資料集。
- 在本機執行下列指令,以使用 SSH 連結至叢集的主節點。執行指令時,本機終端機會停止回應。
gcloud compute ssh trino-cluster-m
- 在叢集主節點的 SSH 終端機視窗中,執行 Trino CLI,連線至主節點上執行的 Trino 伺服器。
trino --catalog hive --schema default
- 在
trino:default提示時,確認 Trino 可以找到 Hive 資料表。show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- 從
trino:default提示執行查詢,並比較查詢 Parquet 與 CSV 資料的效能。- Parquet 資料查詢
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV 資料查詢
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet 資料查詢
Java 應用程式查詢
如要透過 Trino Java JDBC 驅動程式從 Java 應用程式執行查詢,請按照下列步驟操作:
1. 下載 Trino Java JDBC 驅動程式。1. 在 Maven pom.xml 中新增 trino-jdbc 依附元件。
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}記錄和監控
記錄
Trino 記錄位於叢集主節點和 worker 節點的 /var/log/trino/。
網路使用者介面
如要在本機瀏覽器中開啟在叢集主節點上執行的 Trino Web UI,請參閱「查看及存取元件閘道網址」。
監控
Trino 會透過執行階段資料表公開叢集執行階段資訊。在 Trino 工作階段 (從 trino:default 提示字元) 中,執行下列查詢以查看執行階段資料表資料:
select * FROM system.runtime.nodes;
清除所用資源
完成教學課程後,您可以清除所建立的資源,這樣資源就不會繼續使用配額,也不會產生費用。下列各節將說明如何刪除或關閉這些資源。
刪除專案
如要避免付費,最簡單的方法就是刪除您為了本教學課程所建立的專案。
刪除專案的方法如下:
- 前往 Google Cloud 控制台的「Manage resources」(管理資源) 頁面。
- 在專案清單中選取要刪除的專案,然後點選「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下 [Shut down] (關閉) 以刪除專案。
刪除叢集
- 刪除叢集的方法如下:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
刪除值區
- 如要刪除您在「事前準備」中建立的 Cloud Storage bucket,包括儲存在 bucket 中的資料檔案,請按照下列步驟操作:
gcloud storage rm gs://${BUCKET_NAME} --recursive