
משאב של Managed Service for Apache Spark NodeGroup הוא קבוצה של צמתים באשכול Managed Service for Apache Spark
שמבצעים תפקיד שהוקצה להם. בדף הזה מתואר קבוצת צומתי דרייבר, שהיא קבוצה של מכונות וירטואליות ב-Compute Engine שהוקצה להן התפקיד Driver לצורך הפעלת מנהלי התקנים של משימות באשכול Managed Service for Apache Spark.
מתי כדאי להשתמש בקבוצות של צמתי דרייבר
- משתמשים בקבוצות של צומתי דרייבר רק כשצריך להריץ הרבה משימות בו-זמנית באשכול משותף.
- כדי להימנע ממגבלות על קבוצות של צמתי דרייבר, כדאי להגדיל את המשאבים של הצומת הראשי לפני שמשתמשים בקבוצות של צמתי דרייבר.
איך צמתי דרייבר עוזרים להריץ עבודות בו-זמנית
Managed Service for Apache Spark מפעיל תהליך של מנהל משימות בצומת הראשי של אשכול Managed Service for Apache Spark לכל משימה. תהליך הדרייבר, בתורו,
מריץ דרייבר של אפליקציה, כמו spark-submit, כתהליך צאצא.
עם זאת, מספר המשימות המקבילות שפועלות בצומת הראשי מוגבל על ידי המשאבים שזמינים בצומת הראשי. מכיוון שלא ניתן לשנות את גודל הצמתים הראשיים של Managed Service for Apache Spark, יכול להיות שמשימה תיכשל או שקצב ההעברה שלה יוגבל אם המשאבים בצומת הראשי לא יספיקו להרצת המשימה.
קבוצות של צמתי דרייבר הן קבוצות צמתים מיוחדות שמנוהלות על ידי YARN, כך שהבו-זמניות של העבודות לא מוגבלת על ידי משאבי הצומת הראשי. באשכולות עם קבוצת צמתים של מנהלי התקנים, מנהלי ההתקנים של האפליקציות פועלים בצמתים של מנהלי ההתקנים. כל צומת דרייבר יכול להריץ כמה מנהלי התקן של אפליקציות, אם יש לצומת מספיק משאבים.
יתרונות
שימוש באשכול Managed Service for Apache Spark עם קבוצת צמתים של מנהל התקן מאפשר לכם:
- הגדלת משאבים של מנהל העבודה באופן אופקי כדי להריץ יותר עבודות בו-זמנית
- הגדלת משאבי ה-driver בנפרד ממשאבי ה-worker
- קיצור משך ההקטנה של אשכולות של תמונות בגרסה 2.0 ואילך של Managed Service for Apache Spark. באשכולות האלה, האפליקציה הראשית פועלת בתוך Spark driver בקבוצת צמתים של driver (הערך של
spark.yarn.unmanagedAM.enabledמוגדר ל-trueכברירת מחדל). - התאמה אישית של הפעלת צומת דרייבר. אפשר להוסיף את
{ROLE} == 'Driver'לסקריפט הפעלה כדי שהסקריפט יבצע פעולות עבור קבוצת צומתי דרייבר בבחירת צומת.
מגבלות
- אין תמיכה בקבוצות צמתים בתבניות של זרימות עבודה ב-Managed Service for Apache Spark.
- אי אפשר לעצור, להפעיל מחדש או להגדיר שינוי גודל אוטומטי של אשכולות של קבוצות צמתים.
- האפליקציה הראשית של MapReduce פועלת בצמתי עובד. אם מפעילים הוצאה משימוש הדרגתית, יכול להיות שהקטנת מספר הצמתים של העובדים תהיה איטית.
- ההפעלה המקבילית של משימות מושפעת מ
dataproc:agent.process.threads.job.maxמאפיין האשכול. לדוגמה, אם יש שלושה מאסטרים והמאפיין הזה מוגדר לערך ברירת המחדל100, מספר המשימות המקסימלי שניתן להריץ בו-זמנית ברמת האשכול הוא300.
השוואה בין קבוצת צומתי דרייבר לבין מצב אשכול של Spark
| תכונה | מצב אשכול Spark | קבוצת צמתים של מנהל התקן |
|---|---|---|
| הקטנת מספר צמתי העובדים | מנהלי התקנים לטווח ארוך פועלים באותם צמתי עובדים כמו קונטיינרים לטווח קצר, ולכן צמצום מספר העובדים באמצעות השבתה הדרגתית הוא תהליך איטי. | צמתי עובדים מצטמצמים מהר יותר כשמריצים מנהלי התקנים בקבוצות צמתים. |
| פלט של מנהל התקן בסטרימינג | כדי למצוא את הצומת שבו תזמנו את הדרייבר, צריך לחפש ביומני YARN. | הפלט של הדרייבר מועבר בסטרימינג אל Cloud Storage, ואפשר לראות אותו Google Cloud במסוף ובפלט של הפקודה gcloud dataproc jobs wait אחרי שהעבודה מסתיימת. |
הרשאות IAM של קבוצת צמתים של מנהל התקן
ההרשאות הבאות של IAM משויכות לפעולות שקשורות לקבוצת הצמתים של Managed Service for Apache Spark.
| הרשאה | פעולה |
|---|---|
dataproc.nodeGroups.create
|
יצירת קבוצות צמתים של Managed Service for Apache Spark. אם למשתמש יש הרשאה dataproc.clusters.create בפרויקט, ההרשאה הזו ניתנת לו. |
dataproc.nodeGroups.get |
קבלת פרטים של קבוצת צמתים ב-Managed Service for Apache Spark. |
dataproc.nodeGroups.update |
שינוי הגודל של קבוצת צמתים ב-Managed Service for Apache Spark. |
פעולות בקבוצת צמתים של מנהלי התקנים
אתם יכולים להשתמש ב-CLI של gcloud וב-API של Managed Service for Apache Spark כדי ליצור, לקבל, לשנות את הגודל, למחוק ולהגיש עבודה לקבוצת צמתים של דרייבר ב-Managed Service for Apache Spark.
יצירת אשכול של קבוצת צמתים של מנהלי התקנים
קבוצת צמתים של מנהל התקן משויכת לאשכול אחד של Managed Service for Apache Spark. יוצרים קבוצת צמתים כחלק מיצירת אשכול Managed Service for Apache Spark. אפשר להשתמש ב-CLI של gcloud או ב-API בארכיטקטורת REST של Managed Service for Apache Spark כדי ליצור אשכול של Managed Service for Apache Spark עם קבוצת צמתים של צומת דרייבר.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
הדגלים הנדרשים:
- CLUSTER_NAME: שם האשכול, שחייב להיות ייחודי בתוך פרויקט. השם חייב להתחיל באות קטנה, ויכול להכיל עד 51 אותיות קטנות, מספרים ומקפים. הוא לא יכול להסתיים במקף. אפשר לעשות שימוש חוזר בשם של אשכול שנמחק.
- REGION: האזור שבו האשכול ימוקם.
- SIZE: מספר צמתי הדרייבר בקבוצת הצמתים. מספר הצמתים שנדרשים תלוי בעומס העבודה ובסוג המכונה של מאגר הדרייברים. מספר הצמתים של קבוצת הדרייברים המינימלית שווה לזיכרון הכולל או למעבדים הווירטואליים שנדרשים לדרייברים של העבודות, חלקי הזיכרון או המעבדים הווירטואליים של המכונות בכל מאגר דרייברים.
- NODE_GROUP_ID: אופציונלי ומומלץ. המזהה חייב להיות ייחודי באשכול. אפשר להשתמש במזהה הזה כדי לזהות את קבוצת הדרייברים בפעולות עתידיות, כמו שינוי הגודל של קבוצת הצמתים. אם לא מציינים את מזהה קבוצת הצמתים, Managed Service for Apache Spark יוצר אותו.
הדיווח המומלץ:
-
--enable-component-gateway: מוסיפים את הדגל הזה כדי להפעיל את Managed Service for Apache Spark Component Gateway, שמאפשר גישה לממשק האינטרנט של YARN. בדפים Application ו-Scheduler בממשק המשתמש של YARN מוצגים סטטוס האשכול והמשימה, זיכרון תור האפליקציה, קיבולת ליבה ומדדים אחרים.
דגלים נוספים: אפשר להוסיף את הדגלים האופציונליים הבאים driver-pool לפקודה gcloud dataproc clusters create כדי להתאים אישית את קבוצת הצמתים.
| דגל | ערך ברירת המחדל |
|---|---|
--driver-pool-id |
מזהה מחרוזת שנוצר על ידי השירות אם לא הוגדר על ידי הדגל. אפשר להשתמש במזהה הזה כדי לזהות את קבוצת הצמתים כשמבצעים פעולות עתידיות במאגר הצמתים, כמו שינוי הגודל של קבוצת הצמתים. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
אין ברירת מחדל. כשמציינים מאיץ, חובה לציין את סוג ה-GPU, ומספר ה-GPU הוא אופציונלי. |
--num-driver-pool-local-ssds |
ללא ברירת מחדל |
--driver-pool-local-ssd-interface |
ללא ברירת מחדל |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
השלמת AuxiliaryNodeGroup כחלק מבקשה של Managed Service for Apache Spark API cluster.create.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_ID: שדה חובה. מזהה הפרויקט ב-Google Cloud.
- REGION: שדה חובה. האזור של אשכול Dataproc.
- CLUSTER_NAME: שדה חובה. שם האשכול, שחייב להיות ייחודי בפרויקט. השם צריך להתחיל באות קטנה באנגלית, ויכול לכלול עד 51 אותיות קטנות, ספרות ומקפים. הוא לא יכול להסתיים במקף. אפשר לעשות שימוש חוזר בשם של אשכול שנמחק.
- SIZE: שדה חובה. מספר הצמתים בקבוצת הצמתים.
- NODE_GROUP_ID: אופציונלי ומומלץ. המזהה חייב להיות ייחודי בתוך האשכול. אפשר להשתמש במזהה הזה כדי לזהות את קבוצת הדרייברים בפעולות עתידיות, כמו שינוי הגודל של קבוצת הצמתים. אם לא מציינים את המזהה, Managed Service for Apache Spark יוצר אותו.
אפשרויות נוספות: ראו NodeGroup.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
תוכן בקשת JSON:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
אחזור מטא-נתונים של אשכול קבוצות של צמתי דרייבר
אפשר להשתמש בפקודה gcloud dataproc node-groups describe או ב-Managed Service for Apache Spark API כדי לקבל מטא-נתונים של קבוצת צומתי דרייבר.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
הדגלים הנדרשים:
- NODE_GROUP_ID: אפשר להריץ את הפקודה
gcloud dataproc clusters describe CLUSTER_NAMEכדי לראות את המזהה של קבוצת הצמתים. - CLUSTER_NAME: שם האשכול.
- REGION: האזור של האשכול.
REST
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_ID: שדה חובה. מזהה הפרויקט ב-Google Cloud.
- REGION: שדה חובה. האזור של האשכול.
- CLUSTER_NAME: שדה חובה. שם האשכול.
- NODE_GROUP_ID: שדה חובה. אפשר להריץ את הפקודה
gcloud dataproc clusters describe CLUSTER_NAMEכדי לראות את המזהה של קבוצת הצמתים.
ה-method של ה-HTTP וכתובת ה-URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
שינוי הגודל של קבוצת צומתי דרייבר
אפשר להשתמש בפקודה gcloud dataproc node-groups resize או ב-Managed Service for Apache Spark API כדי להוסיף או להסיר צמתי דרייבר מקבוצת צמתי דרייבר באשכול.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
הדגלים הנדרשים:
- NODE_GROUP_ID: אפשר להריץ את הפקודה
gcloud dataproc clusters describe CLUSTER_NAMEכדי לראות את המזהה של קבוצת הצמתים. - CLUSTER_NAME: שם האשכול.
- REGION: האזור של האשכול.
- SIZE: מציינים את המספר החדש של צמתי ה-driver בקבוצת הצמתים.
דגל אופציונלי:
-
--graceful-decommission-timeout=TIMEOUT_DURATION: כשמצמצמים את קבוצת הצמתים, אפשר להוסיף את הדגל הזה כדי לציין הוצאה משירות בצורה מסודרת TIMEOUT_DURATION כדי למנוע את הסיום המיידי של מנהלי משימות. המלצה: צריך להגדיר משך זמן קצוב לתפוגה ששווה לפחות למשך הזמן של העבודה הכי ארוכה שמופעלת בקבוצת הצמתים (אין תמיכה בשחזור של מנהלי התקנים שנכשלו).
דוגמה: פקודת הגדלת הקיבולת ב-CLI של gcloud:NodeGroup
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
דוגמה: פקודת הקטנת הקיבולת ב-CLI של gcloud: NodeGroup
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_ID: שדה חובה. מזהה הפרויקט ב-Google Cloud.
- REGION: שדה חובה. האזור של האשכול.
- NODE_GROUP_ID: שדה חובה. אפשר להריץ את הפקודה
gcloud dataproc clusters describe CLUSTER_NAMEכדי לראות את המזהה של קבוצת הצמתים. - SIZE: שדה חובה. מספר הצמתים החדש בקבוצת הצמתים.
- TIMEOUT_DURATION: אופציונלי. כשמצמצמים את גודל קבוצת הצמתים, אפשר להוסיף
gracefulDecommissionTimeoutלגוף הבקשה כדי למנוע את הסיום המיידי של מנהלי העבודות. המלצה: מגדירים משך זמן קצוב ששווה לפחות למשך העבודה הכי ארוכה שמתבצעת בקבוצת הצמתים (לא נתמכת שחזור של מנהלי התקנים שנכשלו).דוגמה:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
ה-method של ה-HTTP וכתובת ה-URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
תוכן בקשת JSON:
{
"size": SIZE,
}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
מחיקת אשכול של קבוצת צמתים של מנהלי התקנים
כשמוחקים אשכול של Managed Service for Apache Spark, נמחקים גם קבוצות הצמתים שמשויכות לאשכול.
שליחת משרה
אפשר להשתמש בפקודה gcloud dataproc jobs submit או ב-Managed Service for Apache Spark API כדי לשלוח משימה לאשכול עם קבוצת צמתים של מנהלי התקנים.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
הדגלים הנדרשים:
- JOB_COMMAND: ציון פקודת העבודה.
- CLUSTER_NAME: שם האשכול.
- DRIVER_MEMORY: כמות הזיכרון של מנהלי המשימות ב-MB שנדרשת להרצת משימה (ראו אמצעי בקרה על הזיכרון ב-Yarn).
- DRIVER_VCORES: מספר המעבדים הווירטואליים שנדרשים להרצת משימה.
דגלים נוספים:
- DATAPROC_FLAGS: מוסיפים פלאגים נוספים של gcloud dataproc jobs submit שקשורים לסוג העבודה.
- JOB_ARGS: מוסיפים ארגומנטים (אחרי
--) כדי להעביר אותם לעבודה.
דוגמאות: אפשר להריץ את הדוגמאות הבאות מתוך סשן של מסוף SSH באשכול של קבוצת צמתי דרייבר של Managed Service for Apache Spark.
עבודת Spark לאומדן הערך של
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
משימה של ספירת מילים ב-Spark:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
עבודת PySpark להערכת הערך של
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
משימת מיפוי וצמצום של Hadoop TeraGen:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_ID: שדה חובה. מזהה הפרויקט ב-Google Cloud.
- REGION: שדה חובה. אזור של אשכול Dataproc
- CLUSTER_NAME: שדה חובה. שם האשכול, שחייב להיות ייחודי בפרויקט. השם צריך להתחיל באות קטנה באנגלית, ויכול לכלול עד 51 אותיות קטנות, ספרות ומקפים. הוא לא יכול להסתיים במקף. אפשר לעשות שימוש חוזר בשם של אשכול שנמחק.
- DRIVER_MEMORY: שדה חובה. נפח הזיכרון (ב-MB) של מנהלי המשימות שנדרש להרצת משימה (ראו Yarn Memory Controls).
- DRIVER_VCORES: שדה חובה. מספר המעבדים הווירטואליים שנדרשים להרצת משימה.
pi).
ה-method של ה-HTTP וכתובת ה-URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
תוכן בקשת JSON:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- התקנה של ספריית הלקוח
- הגדרת Application Default Credentials
- מריצים את הקוד
- עבודת Spark להערכת הערך של פאי:
- משימת PySpark להדפסת 'hello world':
צפייה ביומני המשימות
כדי לראות את סטטוס העבודה ולעזור בניפוי באגים בבעיות בעבודה, אפשר לראות את יומני מנהלי ההתקנים באמצעות ה-CLI של gcloud או Google Cloud המסוף.
gcloud
יומני מנהל העבודה מועברים בסטרימינג לפלט של ה-CLI של gcloud או למסוףGoogle Cloud במהלך ביצוע העבודה. יומני מנהלי ההתקנים נשמרים במאגר הזמני של אשכול Managed Service for Apache Spark ב-Cloud Storage.
מריצים את הפקודה הבאה ב-CLI של gcloud כדי לקבל רשימה של מיקומי יומני הרישום של מנהלי ההתקנים ב-Cloud Storage:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
המיקום של יומני הנהגים ב-Cloud Storage מופיע כ-driverOutputResourceUri בפלט של הפקודה בפורמט הבא:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
המסוף
כדי לראות את יומני האשכול של קבוצת הצמתים:
כדי למצוא יומנים, אפשר להשתמש בפורמט השאילתה הבא של Logs Explorer:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud מזהה הפרויקט.
- CLUSTER_NAME: שם האשכול.
- LOG_TYPE:
- יומני משתמש של Yarn:
yarn-userlogs - יומני מנהל המשאבים של Yarn:
hadoop-yarn-resourcemanager - יומנים של Yarn Node Manager:
hadoop-yarn-nodemanager
- יומני משתמש של Yarn:
מעקב אחרי מדדים
מנהלי המשימות של קבוצת הצמתים של Managed Service for Apache Spark פועלים בתור dataproc-driverpool-driver-queue תור צאצא במחיצה dataproc-driverpool.
מדדים של קבוצת צמתים של מנהל התקן
בטבלה הבאה מפורטים מדדי הדרייבר של קבוצת הצמתים המשויכת, שנאספים כברירת מחדל עבור קבוצות צמתים של דרייברים.
| מדד של קבוצת צמתים של מנהל התקן | תיאור |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
נפח הזיכרון הזמין במביבייט במחיצה dataproc-driverpool-driver-queue מתחת למחיצה dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
מספר מאגרי התגים בהמתנה (בתור) ב-dataproc-driverpool-driver-queue במחיצה dataproc-driverpool. |
מדדים של תור לילדים
בטבלה הבאה מפורטים המדדים של תור המשנה. המדדים נאספים כברירת מחדל עבור קבוצות של צומתי דרייבר, ואפשר להפעיל את האיסוף שלהם בכל אשכול של Managed Service for Apache Spark.
| מדד תור ההמתנה של הצאצא | תיאור |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
נפח הזיכרון שזמין בתור הזה במביבייט במחיצה שמוגדרת כברירת מחדל. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
מספר המאגרי התגים בהמתנה (בתור) בתור הזה במחיצה שמוגדרת כברירת מחדל. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
מספר העבודות עם זמן ריצה בין 0 ל-60 דקות
בתור הזה בכל המחיצות. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
מספר העבודות עם זמן ריצה בין 60 ל-300 דקות
בתור הזה בכל המחיצות. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
מספר העבודות עם זמן ריצה בין 300 ל-1440 דקות
בתור הזה בכל המחיצות. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
מספר המשימות עם זמן ריצה גדול מ-1440 דקות
בתור הזה בכל המחיצות. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
מספר הבקשות שנשלחו לתור הזה בכל המחיצות. |
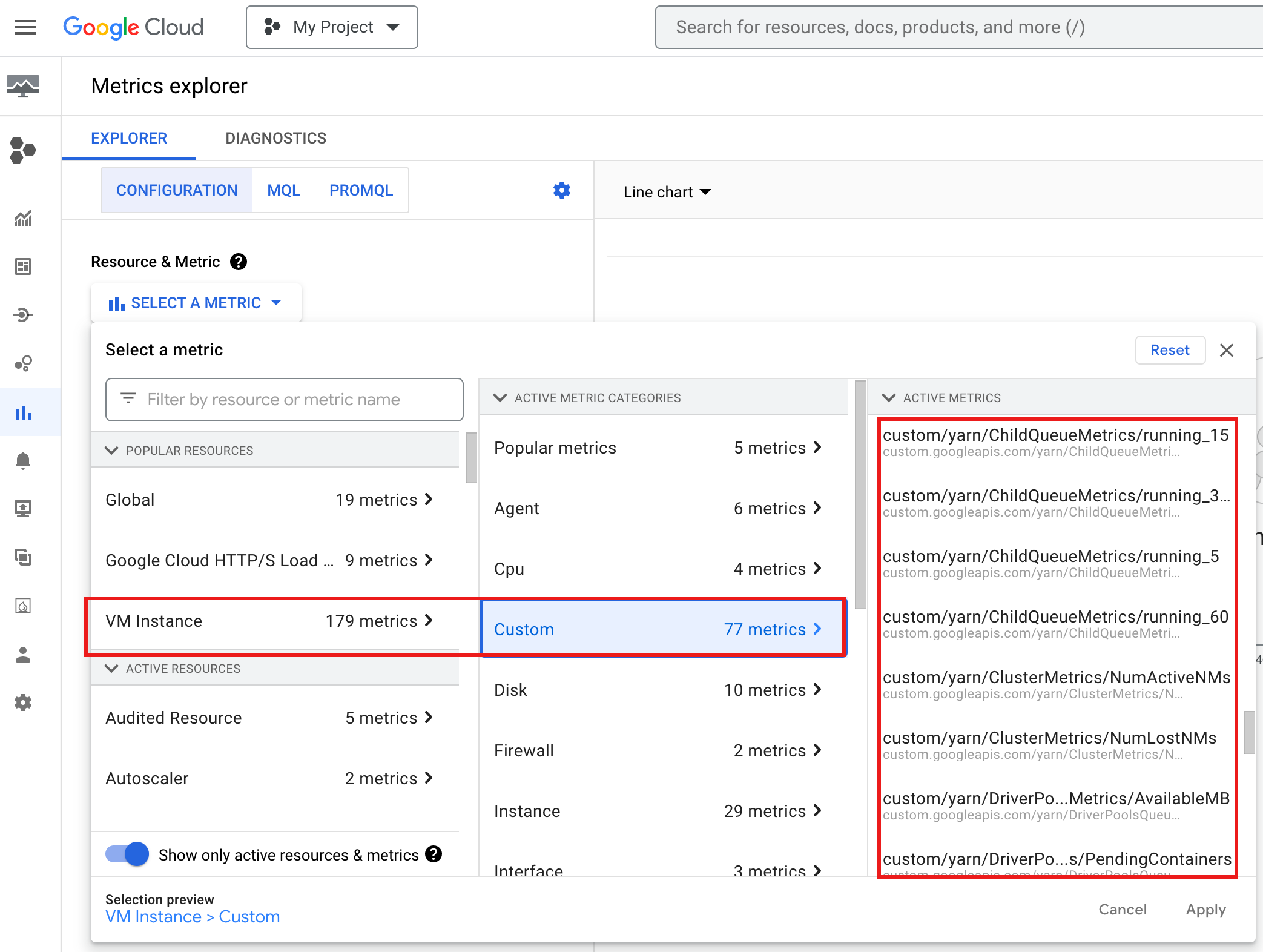
כדי לראות את YARN ChildQueueMetrics ואת DriverPoolsQueueMetrics במסוףGoogle Cloud :
בוחרים באפשרות VM Instance → Custom במשאבים של Metrics Explorer.
ניפוי באגים של מנהל המשימות של קבוצת צמתים
בקטע הזה מפורטים תנאים ושגיאות של קבוצת צמתים של מנהלי התקנים, עם המלצות לתיקון התנאי או השגיאה.
תנאים
תנאי:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBמתקרב ל-0. ההודעה הזו מציינת שמאגרי מנהלי ההתקנים של האשכולות עומדים לאבד את הזיכרון.המלצה:: הגדלת מספר הנהגים בבריכת הנהגים.
Condition:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersis larger than 0. יכול להיות שמאגרי מנהלי ההתקנים של האשכולות נגמרים בזיכרון, ו-YARN מכניס את העבודות לתור.המלצה:: הגדלת מספר הנהגים בבריכת הנהגים.
שגיאות
שגיאה:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.המלצה: מגדירים את
driver-required-memory-mbואתdriver-required-vcoresעם מספרים חיוביים.שגיאה:
Container exited with a non-zero exit code 137.המלצה: כדאי להגדיל את
driver-required-memory-mbלשימוש בזיכרון של העבודה.