
您可以搭配使用 spark-bigquery-connector 與 Managed Service for Apache Spark,在 BigQuery 中讀取和寫入資料。本教學課程會示範使用 spark-bigquery-connector 的 PySpark 應用程式。
確認連接器版本
如要判斷批次工作負載或互動式工作階段執行階段版本中安裝的 BigQuery 連接器版本,請參閱「Managed Service for Apache Spark 執行階段版本」。如果未列出連接器,請參閱「讓應用程式可使用連接器」。
視需要讓應用程式使用連接器
所有支援的 Managed Service for Apache Spark 執行階段版本都會安裝 BigQuery 連接器。如果您使用不支援的執行階段版本,系統不會安裝連接器 (Spark runtime 1.0),您可以透過下列任一方式,讓應用程式使用連接器:
- 提交 Managed Service for Apache Spark 批次工作負載或執行互動式工作階段時,請使用
jars參數指向連接器 jar 檔案。下列批次工作負載範例會指定連接器 JAR 檔案 (如需可用連接器 JAR 檔案的清單,請參閱 GitHub 上的 GoogleCloudDataproc/spark-bigquery-connector 存放區)。- Google Cloud CLI 範例:
gcloud dataproc batches submit pyspark \ --region=REGION \ --jars=spark-3.5-bigquery-version.jar \ ... other args
- Google Cloud CLI 範例:
計算費用
本教學課程使用 Google Cloud的計費元件,包括:
- Managed Service for Apache Spark
- BigQuery
- Cloud Storage
使用 Pricing Calculator 可根據您的預測使用量來產生預估費用。
設定帳單
根據預設,系統會向與憑證或服務帳戶相關聯的專案收取 API 使用費用。如要向其他專案收費,請設定以下設定屬性:spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>")。
您也可以將這項屬性新增至讀取或寫入作業,如下所示:
.option("parentProject", "<BILLED-GCP-PROJECT>")。
提交 PySpark 字數統計批次工作負載
這個範例會使用標準資料來源 API,將 BigQuery 中的資料讀取到 Spark DataFrame,以執行字數計算。
連接器會依下列作業順序,將字數統計輸出內容寫入 BigQuery:
將資料緩衝到 Cloud Storage 值區中的暫時檔案
透過單一作業,將資料從 Cloud Storage bucket 複製到 BigQuery
BigQuery 載入作業完成後,刪除 Cloud Storage 中的臨時檔案 (Spark 應用程式終止後,也會刪除臨時檔案)。如果刪除失敗,您需要刪除任何不需要的臨時 Cloud Storage 檔案,這些檔案通常會放在
gs://BUCKET_NAME/.spark-bigquery-JOB_ID-UUID中。
執行 wordcount 工作負載的步驟
- 開啟本機終端機或 Cloud Shell。
- 使用 bq 指令列工具,在本機終端機或 Cloud Shell 中建立
wordcount_dataset。bq mk wordcount_dataset
- 使用 Google Cloud CLI 建立 Cloud Storage bucket。
gcloud storage buckets create gs://BUCKET_NAME
BUCKET_NAME替換為您建立的 Cloud Storage bucket 名稱。 - 在文字編輯器中複製下列 PySpark 程式碼,以在本機建立
wordcount.py檔案。#!/usr/bin/python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('spark-bigquery-demo') \ .getOrCreate() # Cloud Storage bucket used by the connector for temporary BigQuery # export data. bucket = "BUCKET_NAME" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data.samples.shakespeare') \ .load() words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- 提交 PySpark 批次工作負載:
gcloud dataproc batches submit pyspark wordcount.py \ --region=REGION \ --deps-bucket=BUCKET_NAME
... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
如要在 Google Cloud 控制台中預覽輸出資料表,請開啟「BigQuery」BigQuery頁面,選取wordcount_output資料表,然後按一下「預覽」。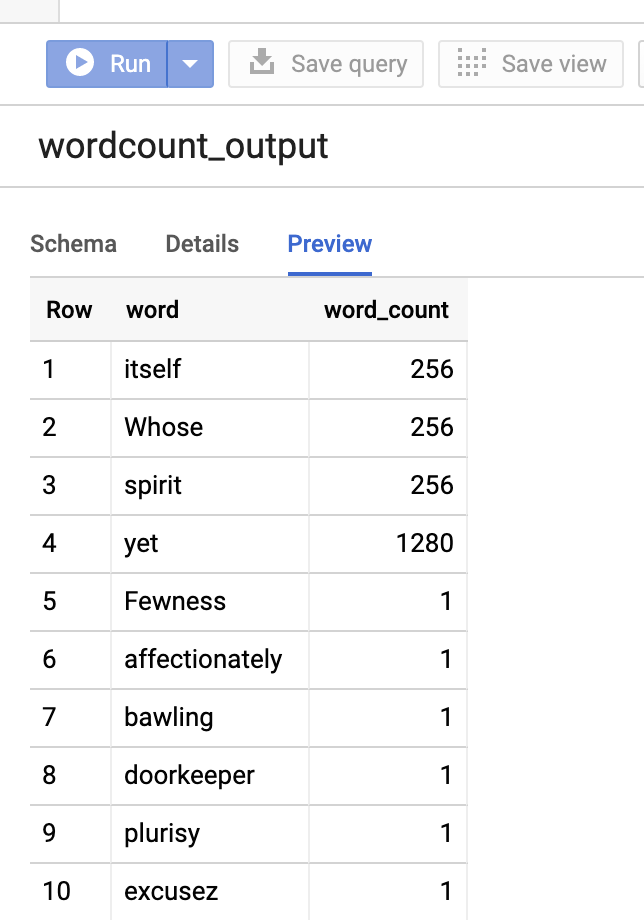
圖 1:在 BigQuery 中預覽輸出資料表