
אתם יכולים ליצור התראה ב-Monitoring שתשלח לכם הודעה אם מדד של אשכול או משימה ב-Managed Service for Apache Spark חורג מסף שצוין.
יצירת התראה
פותחים את הדף Alerting במסוף Google Cloud .
לוחצים על + Create Policy כדי לפתוח את הדף יצירת מדיניות התראות.
- לוחצים על בחירת מדד.
- בתיבת הקלט 'סינון לפי שם המשאב או המדד', מקלידים 'dataproc' כדי להציג רשימה של מדדים של Managed Service for Apache Spark. אפשר לנווט בהיררכיה של מדדים של Cloud Managed Service for Apache Spark כדי לבחור מדד של אשכול, משימה, אצווה או סשן.
- לוחצים על אישור.
- לוחצים על הבא כדי לפתוח את החלונית הגדרת טריגר להתראה.
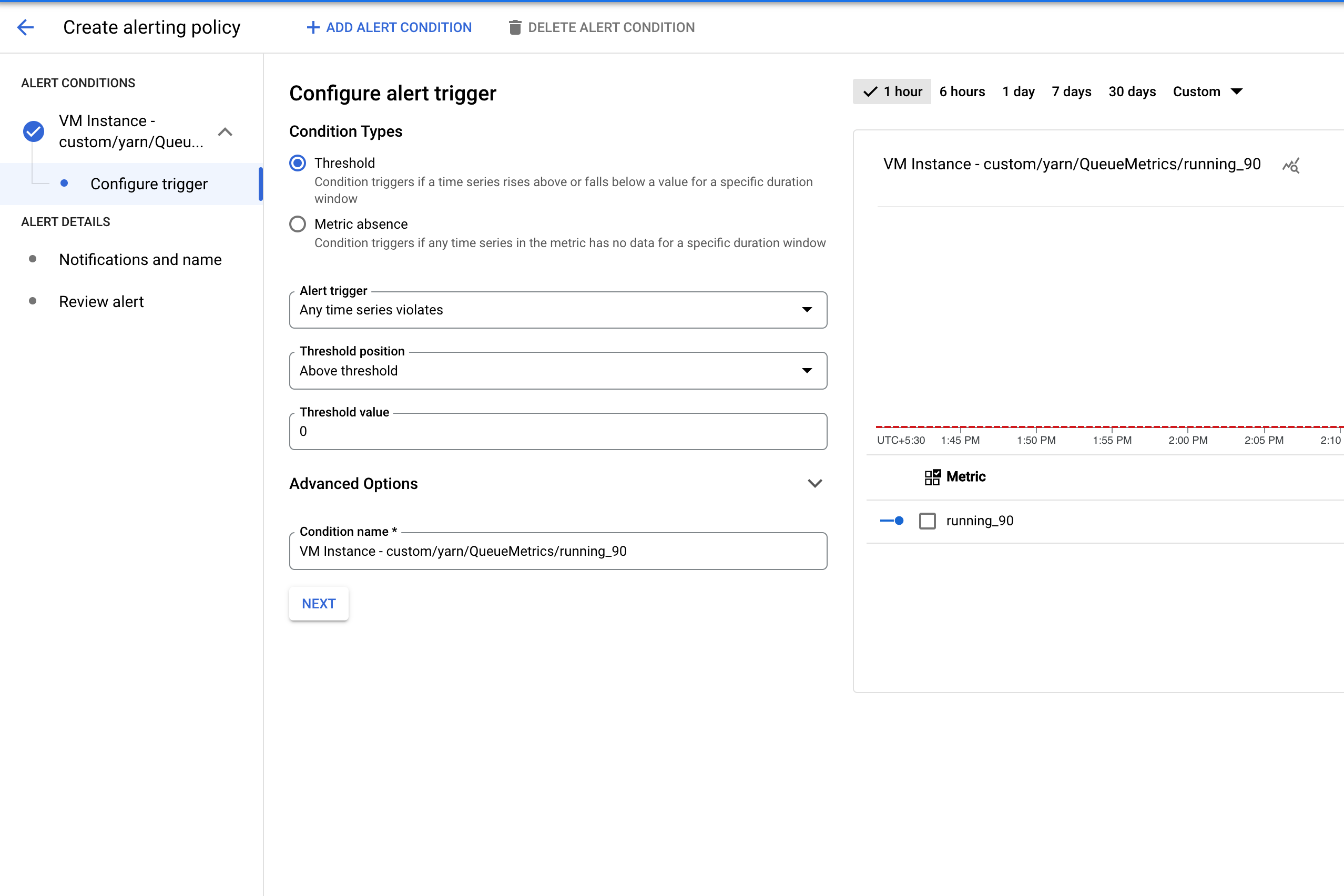
- מגדירים ערך סף להפעלת ההתראה.
- לוחצים על הבא כדי לפתוח את החלונית הגדרת התראות והשלמת ההתראה.
- הגדרת ערוצי התראות, תיעוד ושם מדיניות ההתראות.
- לוחצים על הבא כדי לבדוק את מדיניות ההתראות.
- לוחצים על Create Policy כדי ליצור את ההתראה.
התראות לדוגמה
בקטע הזה מתוארת דוגמה להתראה על משימה שנשלחה אל Managed Service for Apache Spark, ודוגמה להתראה על משימה שמופעלת כאפליקציית YARN.
התראה על משימה ארוכה של Managed Service for Apache Spark
Managed Service for Apache Spark פולט את המדד dataproc.googleapis.com/job/state, שמתעד כמה זמן עבודה נמצאת במצבים שונים. המדד הזה נמצא ב-Metrics Explorer במסוף, בקטע Cloud Managed Service for Apache Spark Job (cloud_dataproc_job). Google Cloud
אתם יכולים להשתמש במדד הזה כדי להגדיר התראה שתשלח לכם כשהמצב של העבודה RUNNINGחורג מסף משך הזמן (מגבלת הסף המקסימלית : 7 ימים).
כדי להגדיר התראה על משימה שצפויה לפעול יותר מ-7 ימים, אפשר לעיין במאמר בנושא התראה על אפליקציית YARN שפועלת במשך זמן רב.
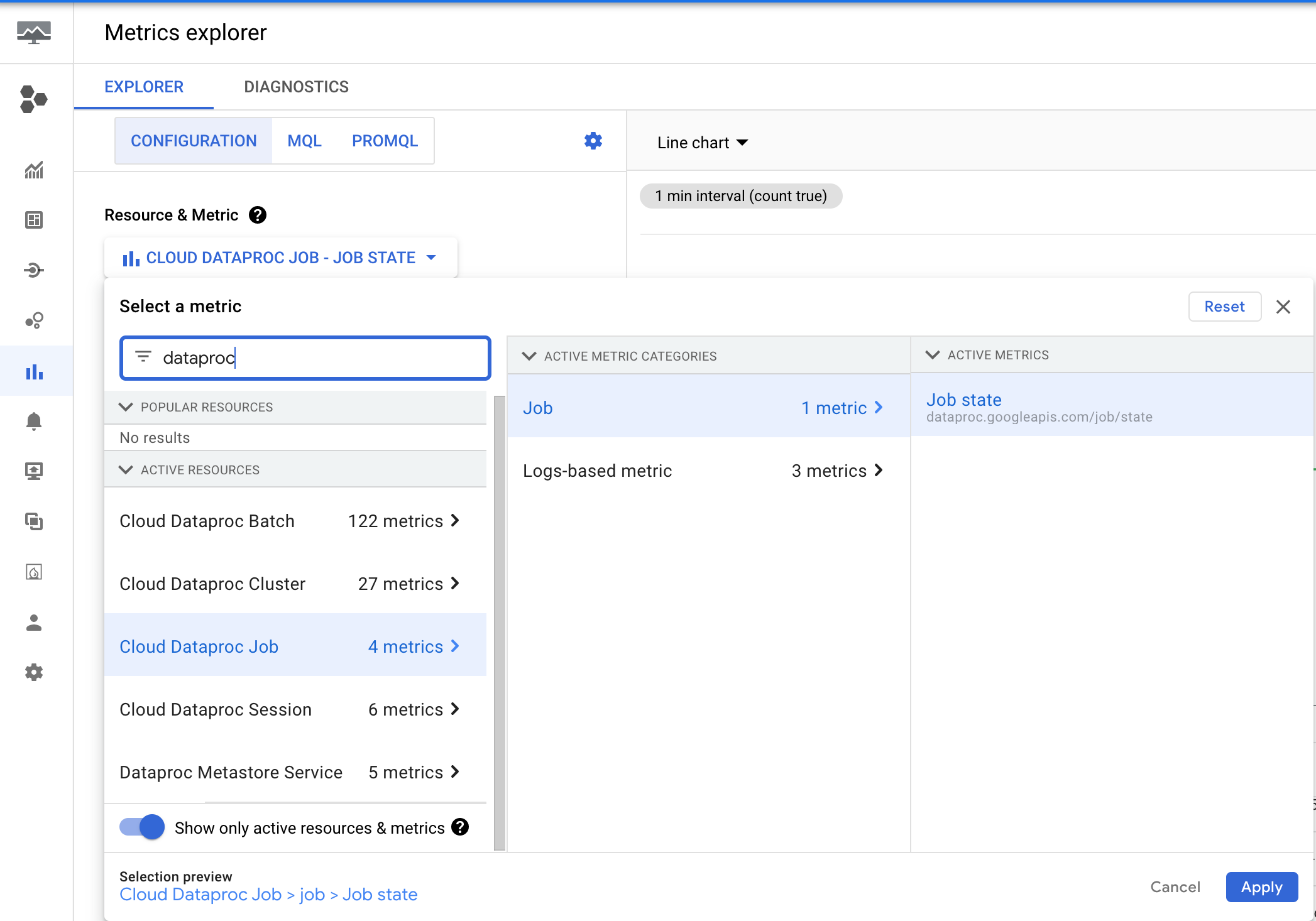
הגדרת התראה על משך העבודה
בדוגמה הזו נעשה שימוש בשפת השאילתות של Prometheus (PromQL) כדי ליצור מדיניות התראות. מידע נוסף זמין במאמר בנושא יצירת מדיניות התראות מבוססת-PromQL (מסוף).
sum by (job_id, state) ({
"__name__"="dataproc.googleapis.com/job/state",
"monitored_resource"="cloud_dataproc_job",
"state"="RUNNING"
}) != 0
כדי שההתראה הזו תופעל כשעבודה פועלת יותר מ-30 דקות, בכרטיסייה Configure trigger (הגדרת טריגר) מגדירים את Evaluation Interval (מרווח הערכה) ל-30 דקות.
אפשר לשנות את השאילתה על ידי סינון לפי job_id כדי להחיל אותה על משרה ספציפית:
sum by (job_id) ({
"__name__"="dataproc.googleapis.com/job/state",
"monitored_resource"="cloud_dataproc_job",
"state"="RUNNING",
"job_id"="1234567890"
}) != 0
התראה על אפליקציית YARN שפועלת במשך זמן רב
בדוגמה הקודמת מוצגת התראה שמופעלת כשמשימה של Managed Service for Apache Spark פועלת יותר זמן מהמשך שצוין, אבל היא רלוונטית רק למשימות שנשלחות לשירות Managed Service for Apache Spark באמצעות מסוף Google Cloud , Google Cloud CLI או קריאות ישירות ל-API של Managed Service for Apache Spark jobs. אפשר גם להשתמש במדדי OSS כדי להגדיר התראות דומות למעקב אחרי זמן הריצה של אפליקציות YARN.
קודם כל, קצת רקע. מערכת YARN פולטת מדדים של זמן ריצה לכמה קטגוריות.
כברירת מחדל, YARN שומר על 60, 300 ו-1,440 דקות כסף חצייה של דליים, ופולט 4 מדדים, running_0, running_60, running_300 ו-running_1440:
running_0מתעדת את מספר המשימות עם זמן ריצה בין 0 ל-60 דקות.
running_60מתעד את מספר המשימות עם זמן ריצה בין 60 ל-300 דקות.הפונקציה
running_300מתעדת את מספר המשימות עם זמן ריצה בין 300 ל-1,440 דקות.
running_1440מתעד את מספר העבודות עם זמן ריצה של יותר מ-1,440 דקות.
לדוגמה, משימה שפועלת במשך 72 דקות תתועד ב-running_60, אבל לא ב-running_0.
אפשר לשנות את ערכי הסף של דלי ברירת המחדל על ידי העברת ערכים חדשים אל מאפיין האשכול yarn:yarn.resourcemanager.metrics.runtime.bucketsבמהלך יצירת אשכול Managed Service for Apache Spark. כשמגדירים ערכי סף מותאמים אישית של משבצות, צריך להגדיר גם החלפות של מדדים. לדוגמה, כדי לציין ספי חלוקה לקטגוריות של 30, 60 ו-90 דקות, הפקודה gcloud dataproc clusters create צריכה לכלול את הדגלים הבאים:
ערכי הסף של הדלי:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90שינויים במדדים:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
המדדים האלה מופיעים ב-Metrics Explorer במסוף Google Cloud , במשאב VM Instance (gce_instance).
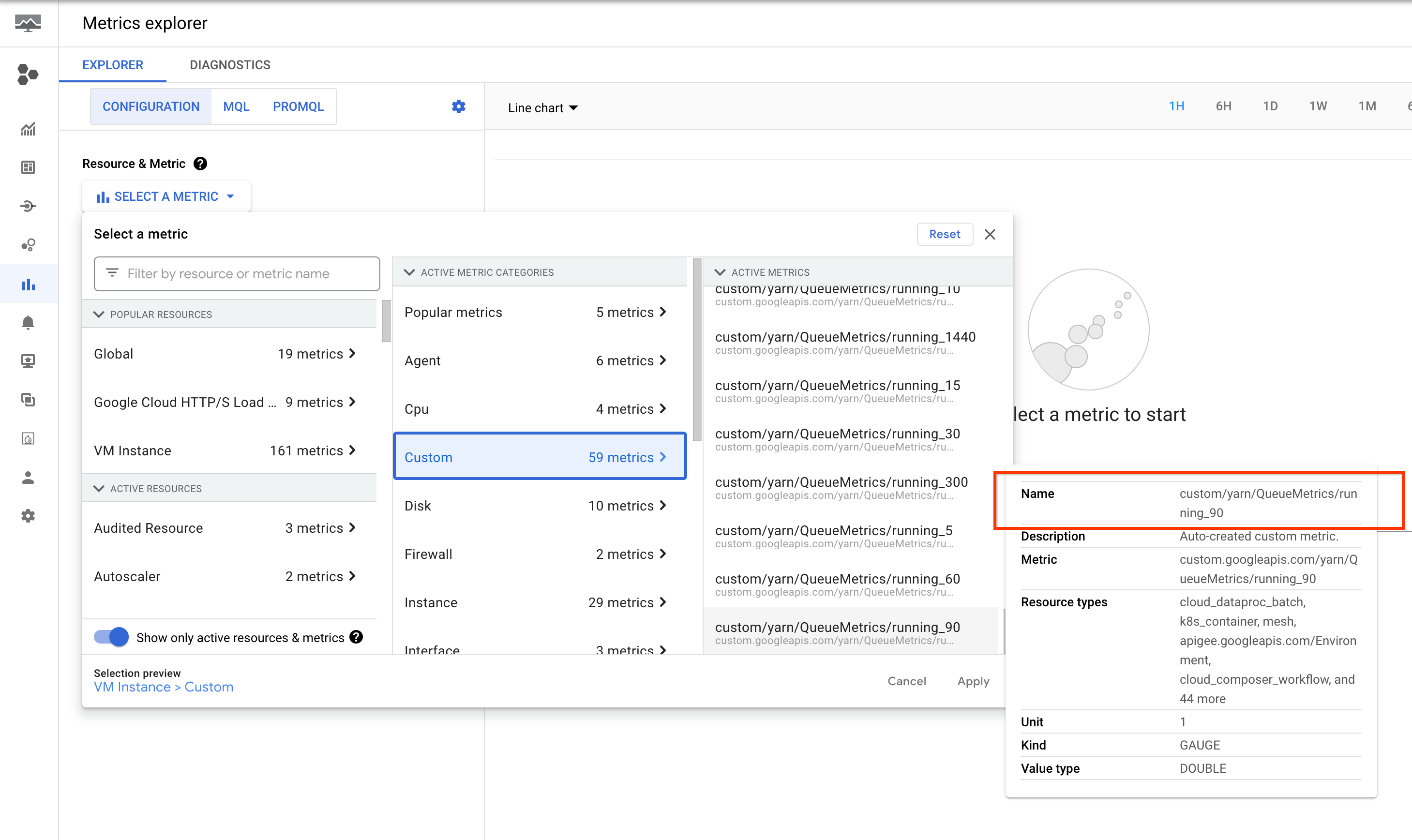
הגדרת התראות באפליקציית YARN
יוצרים מדיניות התראות שמופעלת כשמספר האפליקציות בדלי של מדד YARN חורג מסף שצוין.
אופציונלי, מוסיפים מסנן כדי לקבל התראה על אשכולות שתואמים לתבנית.
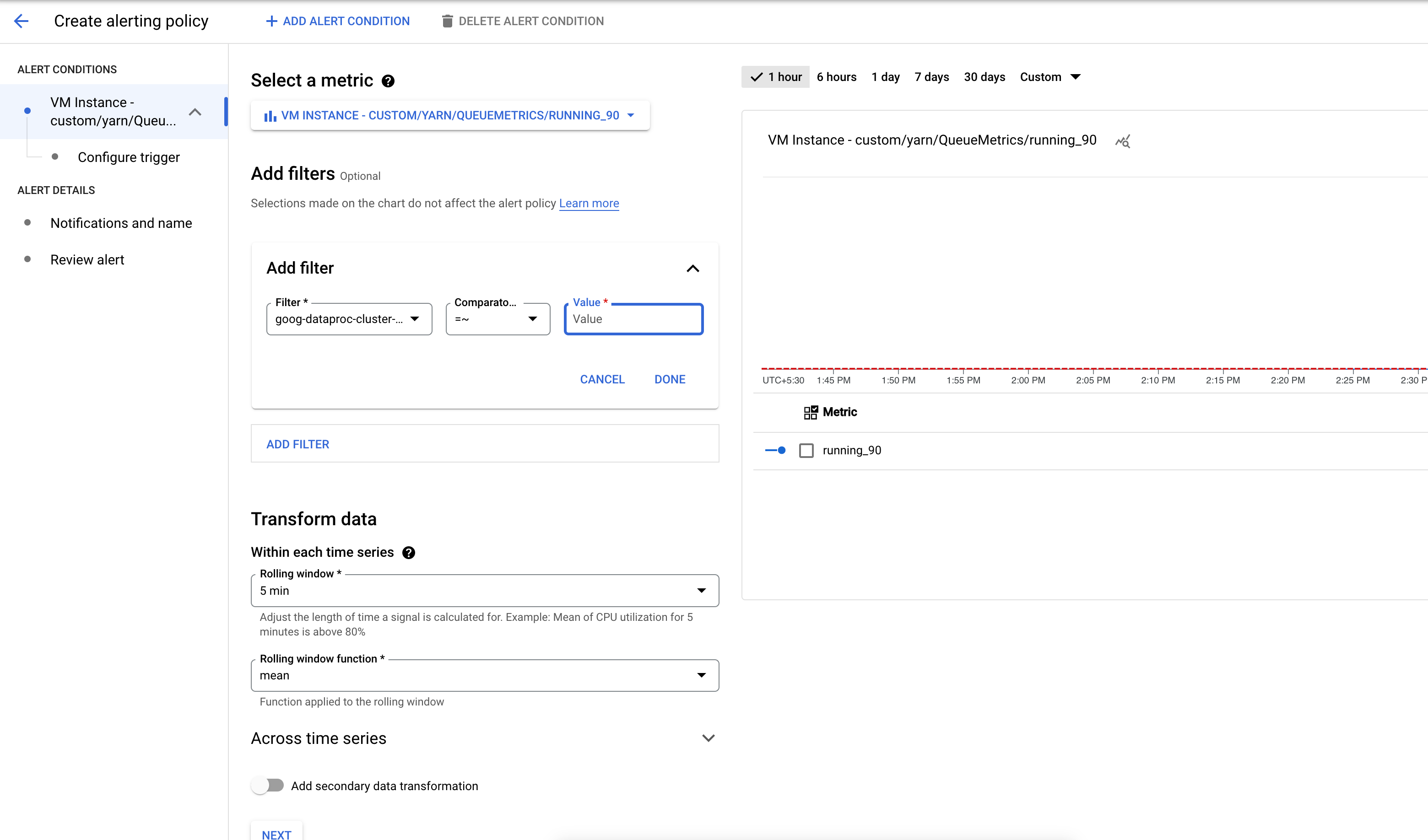
מגדירים את הסף להפעלת ההתראה.
התראה על משימה שנכשלה ב-Managed Service for Apache Spark
אפשר גם להשתמש במדד dataproc.googleapis.com/job/state (ראו התראה על משימה ארוכה של Managed Service for Apache Spark) כדי לקבל התראה כשמשימה של Managed Service for Apache Spark נכשלת.
ההגדרה של ההתראה על משרה נכשלה
בדוגמה הזו נעשה שימוש בשפת השאילתות של Prometheus (PromQL) כדי ליצור מדיניות התראות. מידע נוסף זמין במאמר בנושא יצירת מדיניות התראות מבוססת-PromQL (מסוף).
Alert PromQL
sum by (job_id, state) ({
"__name__"="dataproc.googleapis.com/job/state",
"monitored_resource"="cloud_dataproc_job",
"state"="ERROR"
}) != 0
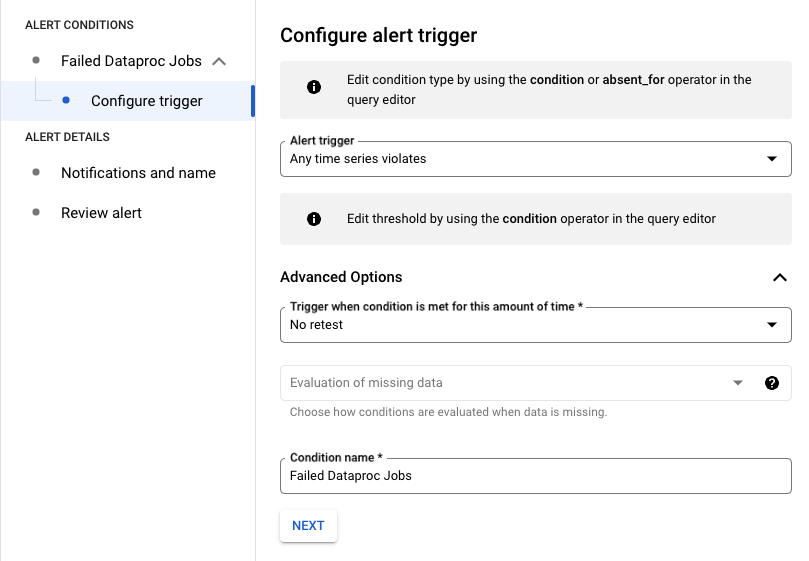
הגדרת טריגר להתראה
בדוגמה הבאה, ההתראה מופעלת כשכל עבודה של Managed Service for Apache Spark נכשלת בפרויקט.
אפשר לשנות את השאילתה על ידי סינון לפי job_id כדי להחיל אותה על משרה ספציפית:
sum by (job_id) ({
"__name__"="dataproc.googleapis.com/job/state",
"monitored_resource"="cloud_dataproc_job",
"state"="ERROR",
"job_id"="1234567890"
}) != 0
התראה על חריגה מקיבולת האשכול
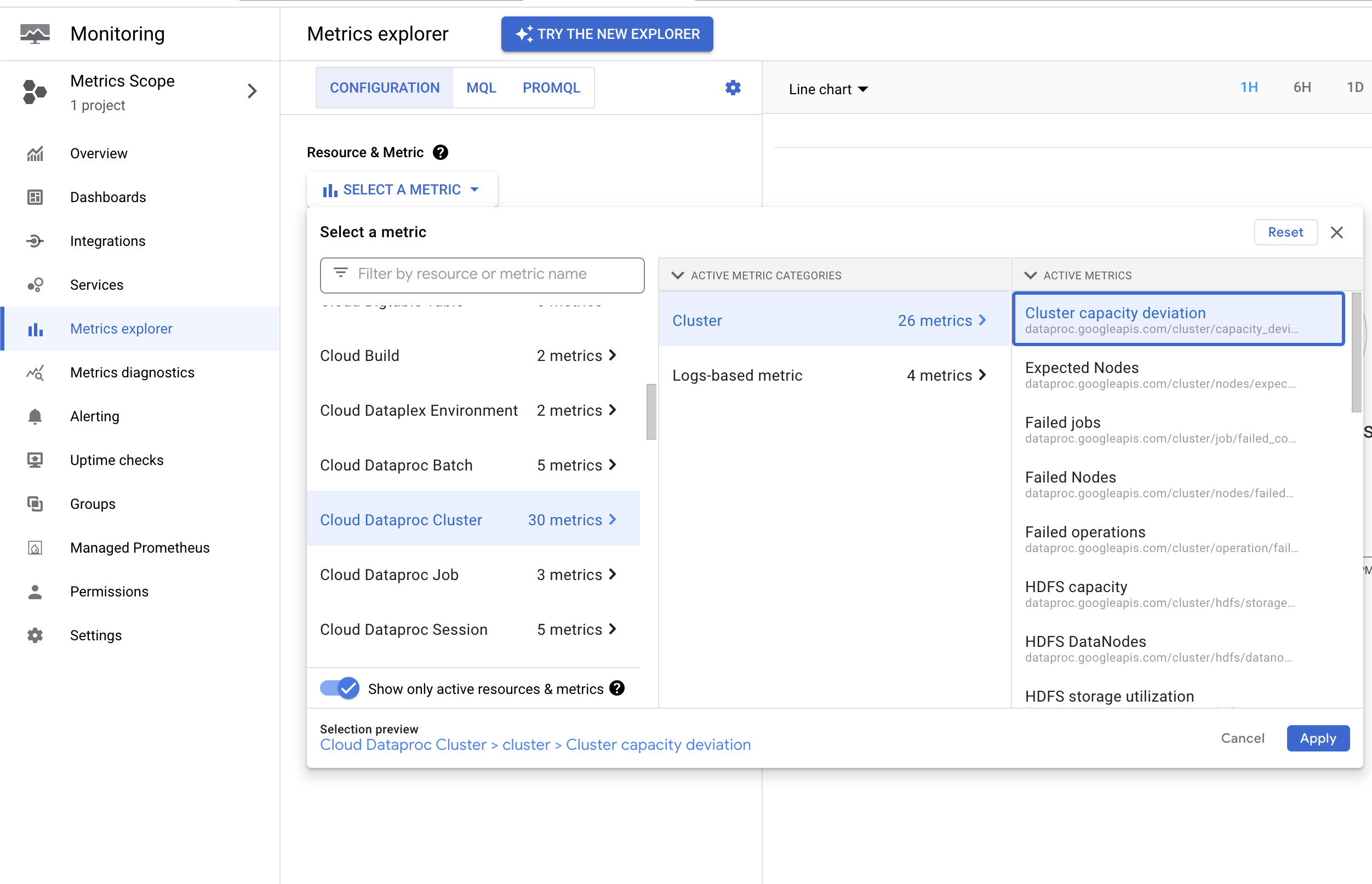
Managed Service for Apache Spark פולט את המדד dataproc.googleapis.com/cluster/capacity_deviation, שמדווח על ההבדל בין מספר הצמתים הצפוי באשכול לבין מספר הצמתים הפעילים ב-YARN. אפשר למצוא את המדד הזה בGoogle Cloud מסוף Metrics Explorer במשאב Cloud Managed Service for Apache Spark Cluster. אתם יכולים להשתמש במדד הזה כדי ליצור התראה שתשלח לכם הודעה כשהקיבולת של האשכול חורגת מהקיבולת הצפויה למשך זמן ארוך יותר מסף שצוין.
הפעולות הבאות עלולות לגרום לדיווח חלקי זמני של צמתי אשכול במדד capacity_deviation. כדי למנוע התראות חיוביות כוזבות, צריך להגדיר את סף ההתראה על מדד כך שיביא בחשבון את הפעולות הבאות:
יצירה ועדכונים של אשכולות: המדד
capacity_deviationלא מופק במהלך פעולות של יצירה או עדכון של אשכולות.פעולות אתחול של אשכול: פעולות אתחול מתבצעות אחרי הקצאת צומת.
עדכונים של עובדים משניים: עובדים משניים מתווספים באופן אסינכרוני, אחרי שפעולת העדכון מסתיימת.
הגדרת התראה על חריגה מהקיבולת
בדוגמה הזו נעשה שימוש בשפת השאילתות של Prometheus (PromQL) כדי ליצור מדיניות התראות. מידע נוסף זמין במאמר בנושא יצירת מדיניות התראות מבוססת-PromQL (מסוף).
{
"__name__"="dataproc.googleapis.com/cluster/capacity_deviation",
"monitored_resource"="cloud_dataproc_cluster"
} != 0
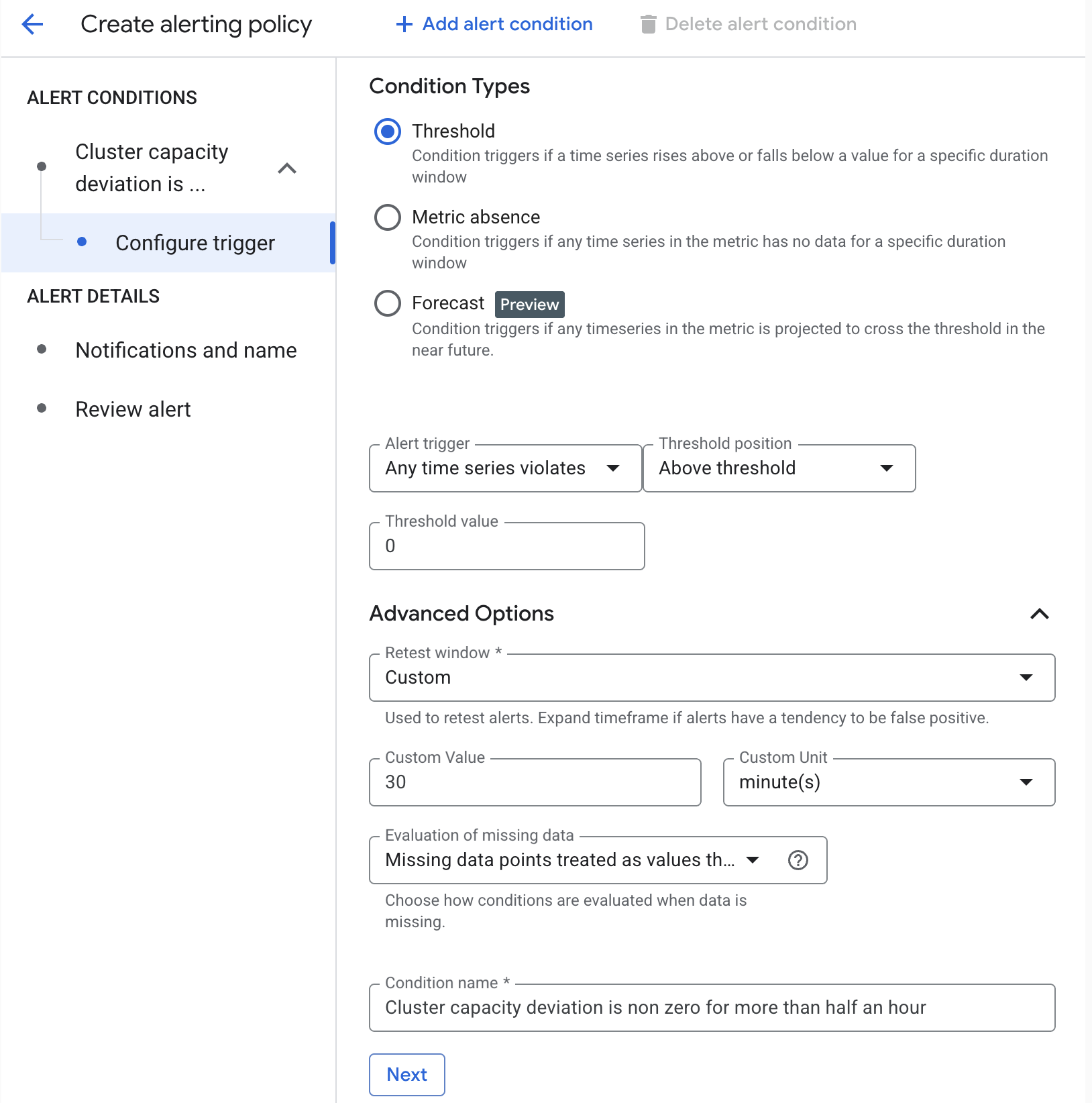
בדוגמה הבאה, ההתראה מופעלת כשהסטייה בקיבולת של האשכול לא אפסית במשך יותר מ-30 דקות.
הצגת ההתראות
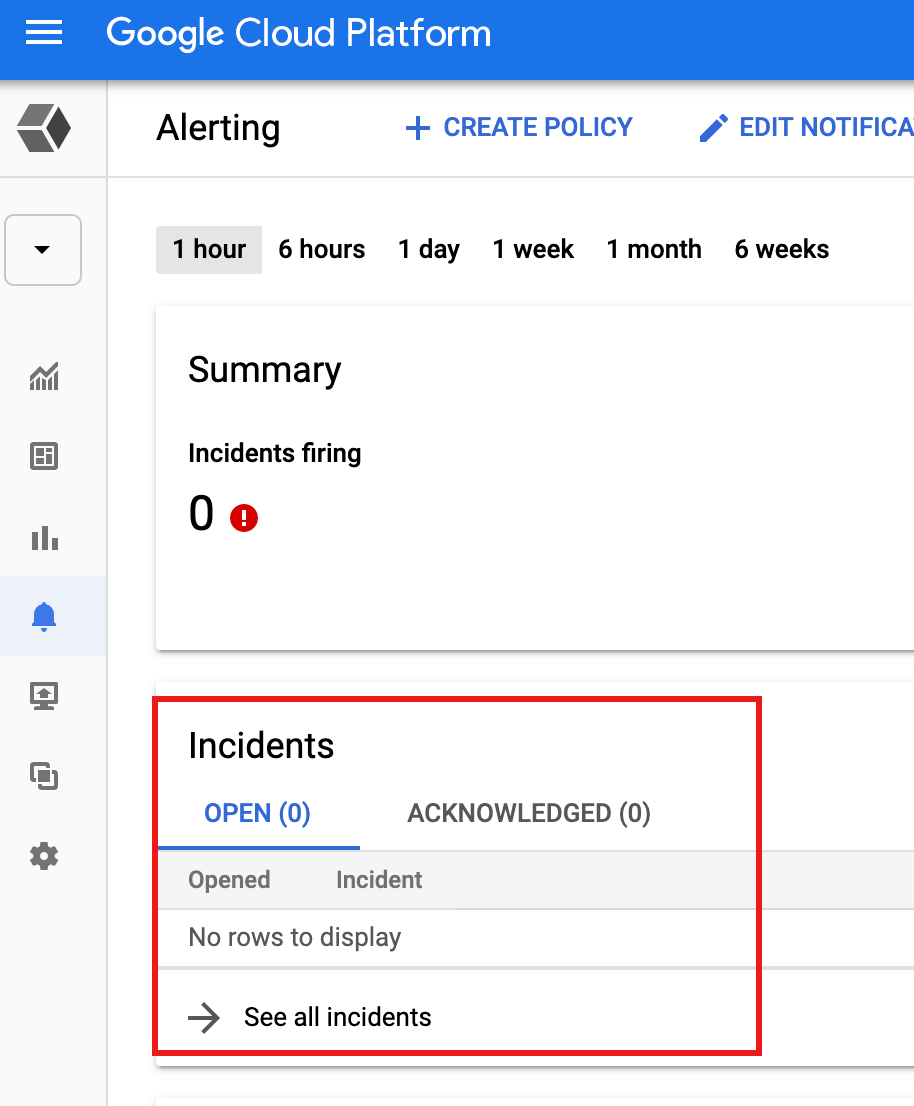
כשמתקבלת התראה בעקבות תנאי של סף מדד, המערכת של Monitoring יוצרת אירוע ואירוע תואם. אפשר לראות את האירועים בדף Monitoring alerting במסוף Google Cloud .
אם הגדרתם במדיניות ההתראות מנגנון התראה, כמו התראה באימייל או ב-SMS, מערכת Monitoring שולחת התראה על האירוע.
המאמרים הבאים
- מידע נוסף מופיע במאמר מבוא להתראות.