
當您使用 Managed Service for Apache Spark 建立叢集並且在叢集上執行工作時,服務就會在專案中設定必要的 Managed Service for Apache Spark 角色和權限,以存取和使用完成工作所需的 Google Cloud 資源。但是,如果您執行跨專案工作 (例如需要存取另一個專案的資料),則需要設定必要的角色和權限以存取跨專案資源。
為了協助您成功完成跨專案工作,本文件列出使用 Managed Service for Apache Spark 的不同主體,以及這些主體存取和使用 Google Cloud 資源所需的角色和相關權限。
有三個主體 (身分) 會存取及使用 Managed Service for Apache Spark:
- 使用者身分
- 控制層身分
資料層身分
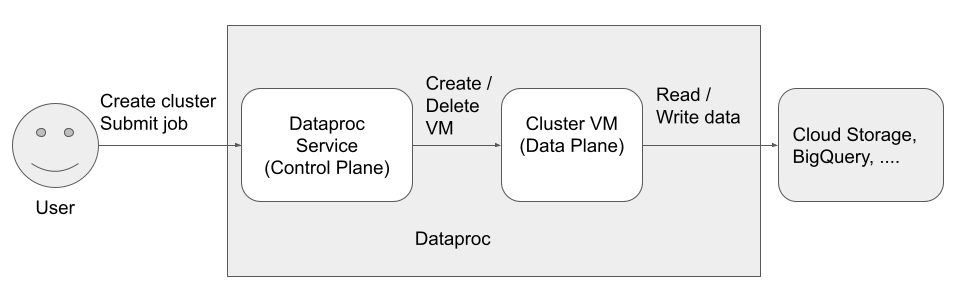
Dataproc API 使用者 (使用者身分)
範例:username@example.com
這是呼叫 Managed Service for Apache Spark 的使用者,可建立叢集、提交工作,以及向服務發出其他要求。使用者通常為個人,但如果是透過 API 用戶端或從 Compute Engine、Cloud Run 函式或 Managed Service for Apache Airflow 等其他Google Cloud 服務叫用 Managed Service for Apache Spark,使用者亦可能為服務帳戶。
相關角色
附註
- 透過 Dataproc API 提交的工作會在 Linux 上以
root權限執行。 除非在建立叢集時設定
--metadata=block-project-ssh-keys=true明確封鎖,Managed Service for Apache Spark 叢集會繼承專案範圍的 Compute Engine SSH 中繼資料 (請參閱「叢集中繼資料」)。系統會為每個專案層級的 SSH 使用者建立 HDFS 使用者目錄。這些 HDFS 目錄是在部署叢集時建立,而現有叢集不會為新的 (部署後) SSH 使用者提供 HDFS 目錄。
Managed Service for Apache Spark 服務代理 (控制層身分)
範例:service-project-number@dataproc-accounts。iam.gserviceaccount.com
Managed Service for Apache Spark 服務代理服務帳戶可用於對 Managed Service for Apache Spark 叢集所在專案中的資源執行多種系統作業,包括:
- 建立 Compute Engine 資源,包括 VM 執行個體、執行個體群組和執行個體範本
get和list作業,以確認映像檔、防火牆、Managed Service for Apache Spark 初始化動作和 Cloud Storage bucket 等資源的設定- 自動建立 Managed Service for Apache Spark 暫存和臨時 bucket (如果使用者未指定暫存或臨時 bucket)
- 將叢集設定中繼資料寫入暫存 bucket
- 存取主專案中的虛擬私有雲網路
相關角色
Managed Service for Apache Spark VM 服務帳戶 (資料層身分)
範例:project-number-compute@developer.gserviceaccount.com
您的應用程式程式碼會在 Managed Service for Apache Spark VM 上以 VM 服務帳戶身分執行。已授予此服務帳戶上的使用者工作角色 (以及相關權限)。
VM 服務帳戶會執行下列動作:
- 與 Managed Service for Apache Spark 控制層通訊。
- 從 Managed Service for Apache Spark 暫存和臨時 bucket 讀取及寫入資料。
- 視 Managed Service for Apache Spark 工作需求,從 Cloud Storage、BigQuery、Cloud Logging 和其他 Google Cloud 資源讀取及寫入資料。
相關角色
後續步驟
- 進一步瞭解 Managed Service for Apache Spark 角色和權限。
- 進一步瞭解 Managed Service for Apache Spark 服務帳戶。
- 請參閱「BigQuery 存取控管」。
- 請參閱「Cloud Storage 存取控管選項」。