
במסמך הזה מפורט מידע על כוונון אוטומטי של עומסי עבודה ברצף (batch) ב-Managed Service for Apache Spark. אופטימיזציה של עומס עבודה ב-Spark לשיפור הביצועים והחוסן יכולה להיות מאתגרת בגלל מספר האפשרויות להגדרת Spark והקושי בהערכת ההשפעה של האפשרויות האלה על עומס העבודה. התכונה 'התאמה אוטומטית של Managed Service for Apache Spark' מספקת חלופה להגדרה ידנית של עומס עבודה. היא עושה זאת על ידי החלה אוטומטית של הגדרות Spark על עומס עבודה חוזר של Spark, על סמך שיטות מומלצות לאופטימיזציה של Spark וניתוח של הרצות עומס עבודה (שנקראות 'קבוצות').
הרשמה ל-Managed Service for Apache Spark autotuning
כדי להירשם לגישה לגרסת הטרום-השקה של התכונה 'כוונון אוטומטי של Managed Service for Apache Spark' שמתוארת בדף הזה, צריך למלא את טופס ההרשמה בקשה לגישה לגרסת טרום-השקה של Managed Service for Apache Spark ולשלוח אותו. אחרי שהטופס יאושר, לפרויקטים שמפורטים בו תהיה גישה לתכונות בגרסת טרום-השקה.
יתרונות
היתרונות של כוונון אוטומטי ב-Managed Service for Apache Spark:
- אופטימיזציה אוטומטית: כוונון אוטומטי של הגדרות Spark ושל עיבודים ברצף (batch processing) לא יעילים ב-Managed Service for Apache Spark, שיכול להאיץ את זמני הריצה של העבודות.
- למידה היסטורית: לומדים מהרצות חוזרות כדי להחיל המלצות שמותאמות לעומס העבודה שלכם.
קבוצות בעלות מאפיינים משותפים (cohort) שעוברות אופטימיזציה אוטומטית
התאמה אוטומטית מופעלת על הרצות חוזרות (קבוצות) של עומס עבודה באצווה.
השם של הקוהורט שאתם מציינים כשאתם שולחים עומס עבודה באצווה מזהה אותו כאחד מהריצות העוקבות של עומס העבודה החוזר.
התאמה אוטומטית מופעלת על קבוצות של עומסי עבודה של אצווה באופן הבא:
הכוונון האוטומטי מחושב ומוחל על הקבוצה השנייה ואלה שאחריה של עומס עבודה. התאמה אוטומטית לא מוחלת על ההרצה הראשונה של עומס עבודה חוזר, כי התאמה אוטומטית של Managed Service for Apache Spark משתמשת בהיסטוריית עומסי העבודה לצורך אופטימיזציה.
התאמה אוטומטית לא חלה רטרואקטיבית על עומסי עבודה פעילים, אלא רק על עומסי עבודה חדשים שנשלחים.
הכוונון האוטומטי לומד ומשתפר לאורך זמן על ידי ניתוח הנתונים הסטטיסטיים של הקוהורט. כדי לאפשר למערכת לאסוף מספיק נתונים, מומלץ להשאיר את הכוונון האוטומטי מופעל לפחות חמש פעמים.
שמות קוהורטים: מומלץ להשתמש בשמות קוהורטים שעוזרים לזהות את סוג עומס העבודה החוזר. לדוגמה, אפשר להשתמש ב-daily_sales_aggregation כשם של קבוצת משתמשים לעומס עבודה מתוזמן שמריץ משימת צבירה של נתוני מכירות מדי יום.
תרחישים של כוונון אוטומטי
במקרים הרלוונטיים, הכוונון האוטומטי בוחר ומבצע באופן אוטומטי את הפעולות הבאות (scenarios או יעדים) כדי לבצע אופטימיזציה של עומס עבודה באצווה:
- התאמה לעומס: הגדרות של התאמה אוטומטית לעומס ב-Spark.
- אופטימיזציה של הצטרפות: הגדרות התצורה של Spark לאופטימיזציה של ביצועי הצטרפות של שידור SQL.
- ערבוב מחיצות: הגדרות תצורה של Spark לשיפור מחיצות ערבוב.
שימוש בכוונון אוטומטי של Managed Service for Apache Spark
אפשר להפעיל כוונון אוטומטי של Managed Service for Apache Spark בעומס עבודה של אצווה באמצעות Google Cloud המסוף, Google Cloud CLI, Dataproc API או ספריות הלקוח ב-Cloud.
המסוף
כדי להפעיל כוונון אוטומטי של Managed Service for Apache Spark בכל שליחה של עומס עבודה חוזר ברצף, מבצעים את השלבים הבאים:
נכנסים לדף Batches של Managed Service for Apache Spark במסוף Google Cloud .
כדי ליצור עומס עבודה של אצווה, לוחצים על Create.
בקטע Autotuning:
מעבירים את הלחצן הפעלה כדי להפעיל את הכוונון האוטומטי של עומס העבודה של Spark.
קבוצת משתמשים: ממלאים את שם קבוצת המשתמשים, שמזהה את האצווה כאחת מסדרה של עומסי עבודה חוזרים. התאמה אוטומטית מופעלת בעומסי העבודה השני והבאים שמוגשים עם שם הקוהורט הזה. לדוגמה, אפשר לציין את
daily_sales_aggregationכשם קבוצת המשתמשים עבור עומס עבודה מתוזמן של אצווה שמריץ משימת צבירה של נתוני מכירות מדי יום.
ממלאים את שאר הקטעים בדף יצירת קבוצה לפי הצורך, ואז לוחצים על שליחה. מידע נוסף על השדות האלה זמין במאמר בנושא שליחת עומס עבודה של אצווה.
gcloud
כדי להפעיל כוונון אוטומטי של Managed Service for Apache Spark בכל שליחה של עומס עבודה חוזר של אצווה, מריצים את הפקודה הבאה של ה-CLI של gcloud gcloud dataproc batches submit באופן מקומי בחלון טרמינל או ב-Cloud Shell.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=auto \ other arguments ...
מחליפים את מה שכתוב בשדות הבאים:
- COMMAND: סוג עומס העבודה של Spark, למשל
Spark, PySpark, Spark-SqlאוSpark-R. - REGION: האזור שבו יפעל עומס העבודה של Batch.
- COHORT: שם הקבוצה בעלת המאפיינים המשותפים, שמזהה את האצווה כאחת מתוך סדרה של עומסי עבודה חוזרים.
התאמה אוטומטית מופעלת בעומסי העבודה השני והבאים שמוגשים עם שם הקוהורט הזה. לדוגמה, אפשר לציין את
daily_sales_aggregationכשם של קבוצת משתמשים לעומס עבודה של אצווה מתוזמנת שמריצה משימת צבירה של נתוני מכירות מדי יום.
--autotuning-scenarios=auto: הפעלת כוונון אוטומטי.
API
כדי להפעיל כוונון אוטומטי של Managed Service for Apache Spark בכל שליחה של עומס עבודה חוזר ברצף, שולחים בקשת batches.create שכוללת את השדות הבאים:
-
RuntimeConfig.cohort: שם הקבוצה בעלת המאפיינים המשותפים, שמזהה את האצווה כאחת מתוך סדרה של עומסי עבודה חוזרים. התאמה אוטומטית מופעלת על עומסי העבודה השני והבאים שמוגשים עם שם הקוהורט הזה. לדוגמה, אפשר לציין אתdaily_sales_aggregationכשם הקוהורט לעומס עבודה של אצווה מתוזמנת שמריצה משימת צבירה של נתוני מכירות מדי יום.
AutotuningConfig.scenarios: מצייניםAUTOכדי להפעיל כוונון אוטומטי בעומס העבודה של Spark batch.
דוגמה:
...
runtimeConfig:
cohort: COHORT_NAME
autotuningConfig:
scenarios:
- AUTO
...
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaההוראות להגדרה במאמר התחלה מהירה של Managed Service for Apache Spark באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של Managed Service for Apache Spark Java API.
כדי לבצע אימות ל-Managed Service for Apache Spark, מגדירים את ה-Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
כדי להפעיל כוונון אוטומטי של Managed Service for Apache Spark בכל שליחה של עומס עבודה חוזר ברצף, צריך להפעיל את BatchControllerClient.createBatch עם CreateBatchRequest שכולל את השדות הבאים:
-
Batch.RuntimeConfig.cohort: שם הקבוצה בעלת המאפיינים המשותפים, שמזהה את האצווה כאחת מתוך סדרה של עומסי עבודה חוזרים. התאמה אוטומטית מופעלת על עומסי העבודה השני והבאים שמוגשים עם שם הקוהורט הזה. לדוגמה, אפשר לציין את השםdaily_sales_aggregationלקבוצת המשתמשים של עומס עבודה באצווה מתוזמנת שמריצה משימת צבירה של נתוני מכירות מדי יום.
Batch.RuntimeConfig.AutotuningConfig.scenarios: מצייניםAUTOכדי להפעיל כוונון אוטומטי בעומס העבודה של אצווה Spark.
דוגמה:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.AUTO))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
כדי להשתמש ב-API, צריך להשתמש בגרסה google-cloud-dataproc ואילך של ספריית הלקוח 4.43.0. אפשר להשתמש באחת מההגדרות הבאות כדי להוסיף את הספרייה לפרויקט.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonההוראות להגדרה במאמר התחלה מהירה של Managed Service for Apache Spark באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של Managed Service for Apache Spark Python API.
כדי לבצע אימות ל-Managed Service for Apache Spark, מגדירים את ה-Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
כדי להפעיל כוונון אוטומטי של Managed Service for Apache Spark בכל שליחה של עומס עבודה חוזר ברצף, צריך להפעיל את BatchControllerClient.create_batch עם Batch שכולל את השדות הבאים:
-
batch.runtime_config.cohort: שם הקבוצה בעלת המאפיינים המשותפים, שמזהה את האצווה כאחת מתוך סדרה של עומסי עבודה חוזרים. התאמה אוטומטית מופעלת על עומסי העבודה השני והבאים שמוגשים עם שם הקוהורט הזה. לדוגמה, אפשר לציין אתdaily_sales_aggregationכשם הקוהורט לעומס עבודה מתוזמן של אצווה שמריץ משימת צבירה של נתוני מכירות יומיים.
batch.runtime_config.autotuning_config.scenarios: מצייניםAUTOכדי להפעיל כוונון אוטומטי בעומס העבודה של אצווה Spark.
דוגמה:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.AUTO
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
כדי להשתמש ב-API, צריך להשתמש בגרסה google-cloud-dataproc ואילך של ספריית הלקוח 5.10.1. כדי להוסיף אותו לפרויקט, אפשר להשתמש בדרישה הבאה:
google-cloud-dataproc>=5.10.1
Airflow
במקום לשלוח ידנית כל קבוצת משנה של נתוני אצווה שעברו כוונון אוטומטי, אפשר להשתמש ב-Airflow כדי לתזמן את השליחה של כל עומס עבודה חוזר של אצווה. כדי לעשות זאת, קוראים ל-BatchControllerClient.create_batch עם Batch שכולל את השדות הבאים:
-
batch.runtime_config.cohort: שם הקבוצה בעלת המאפיינים המשותפים, שמזהה את האצווה כאחת מתוך סדרה של עומסי עבודה חוזרים. התאמה אוטומטית מופעלת על עומסי העבודה השני והבאים שמוגשים עם שם הקוהורט הזה. לדוגמה, אפשר לציין את השםdaily_sales_aggregationלקבוצת משתמשים עבור עומס עבודה של אצווה מתוזמנת שמריצה משימת צבירה של נתוני מכירות מדי יום.
batch.runtime_config.autotuning_config.scenarios: מצייניםAUTOכדי להפעיל כוונון אוטומטי בעומס העבודה של אצווה Spark.
דוגמה:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.AUTO,
]
}
},
},
batch_id="BATCH_ID",
)
כדי להשתמש ב-API, צריך להשתמש בגרסה google-cloud-dataproc ואילך של ספריית הלקוח 5.10.1. אפשר להשתמש בדרישה הבאה של סביבת Airflow:
google-cloud-dataproc>=5.10.1
כדי לעדכן את החבילה ב-Managed Service for Apache Airflow, אפשר לעיין במאמר בנושא התקנת יחסי תלות של Python ב-Managed Airflow .
צפייה בשינויים של כוונון אוטומטי
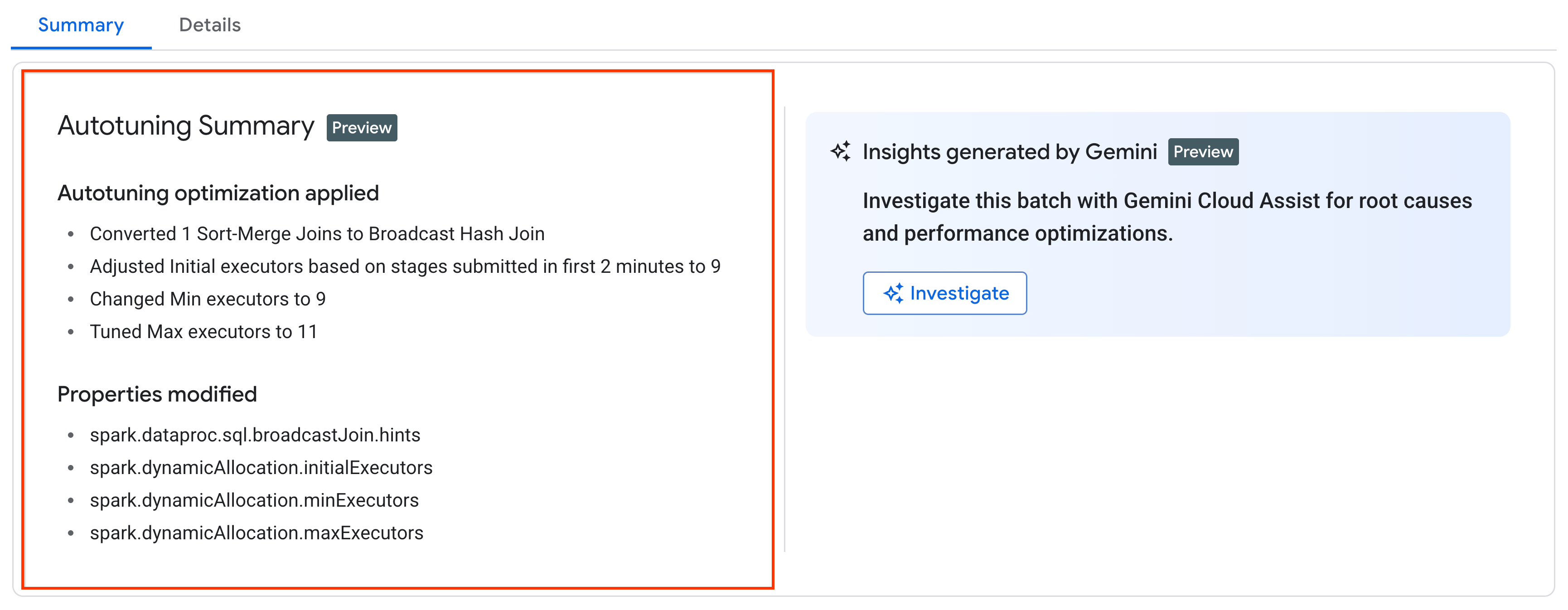
כדי לראות את השינויים שבוצעו בעומס עבודה של עיבוד ברצף (batch) על ידי התכונה 'התאמה אוטומטית' של Managed Service for Apache Spark, מריצים את הפקודה gcloud dataproc batches describe.
דוגמה: הפלט של gcloud dataproc batches describe דומה לזה:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties:
spark.dataproc.sql.broadcastJoin.hints:
annotation: Converted 1 Sort-Merge Joins to Broadcast Hash Join
value: v2;Inner,<hint>
spark.dynamicAllocation.initialExecutors:
annotation: Adjusted Initial executors based on stages submitted in first
2 minutes to 9
overriddenValue: '2'
value: '9'
spark.dynamicAllocation.maxExecutors:
annotation: Tuned Max executors to 11
overriddenValue: '5'
value: '11'
spark.dynamicAllocation.minExecutors:
annotation: Changed Min executors to 9
overriddenValue: '2'
value: '9'
...
אפשר לראות את השינויים האחרונים שבוצעו באמצעות כוונון אוטומטי בעומס עבודה פעיל, שהסתיים או שנכשל, בדף פרטי אצווה במסוף Google Cloud , בכרטיסייה סיכום.
תמחור
Managed Service for Apache Spark עם כוונון אוטומטי מוצע במהלך תצוגה מקדימה פרטית ללא תשלום נוסף. התמחור הרגיל של Managed Service for Apache Spark חל.