
總覽
Looker 會運用匯總感知邏輯,在資料庫中找出最小、最有效率的資料表來執行查詢,同時維持結果的準確性。
對於資料庫中的超大型資料表,Looker 開發人員可以建立較小的匯總資料表,將資料依不同屬性組合分組。匯總資料表就像「匯總」或「彙整」資料的表格,Looker 可在查詢時盡可能使用這類資料表,而非原始的大型資料表。如果在妥善規劃下導入這項功能,可讓平均查詢速度提升好幾倍。
舉例來說,您可能有一個 PB 級的資料表,其中包含網站上每筆訂單的資料列。您可以從這個資料庫建立匯總資料表,其中包含每日銷售總額。如果您的網站每天收到 1,000 筆訂單,則每日匯總資料表中的資料列會比原始資料表少 999 列。您可以建立另一個包含每月銷售總額的匯總表格,這樣效率會更高。因此,如果使用者查詢每日或每週銷售額,Looker 會使用每日銷售總額資料表。如果使用者查詢年度銷售量,但您沒有年度匯總資料表,Looker 會使用次佳的資料表,也就是本例中的月銷售匯總資料表。
Looker 會盡可能使用最小的匯總資料表回答使用者的問題。例如:
- 如要查詢每月銷售總額,Looker 會使用以每月銷售額為準的匯總資料表 (
sales_monthly_aggregate_table)。 - 如果查詢的是每天的銷售總額,由於沒有這種精細程度的匯總資料表,Looker 會從原始資料庫表格 (
orders_database) 取得查詢結果。不過,如果使用者經常執行這類查詢,您可以為此建立匯總資料表。 - 如果查詢每週銷售量,由於沒有每週匯總資料表,Looker 會使用次佳的每日銷售匯總資料表 (
sales_daily_aggregate_table)。
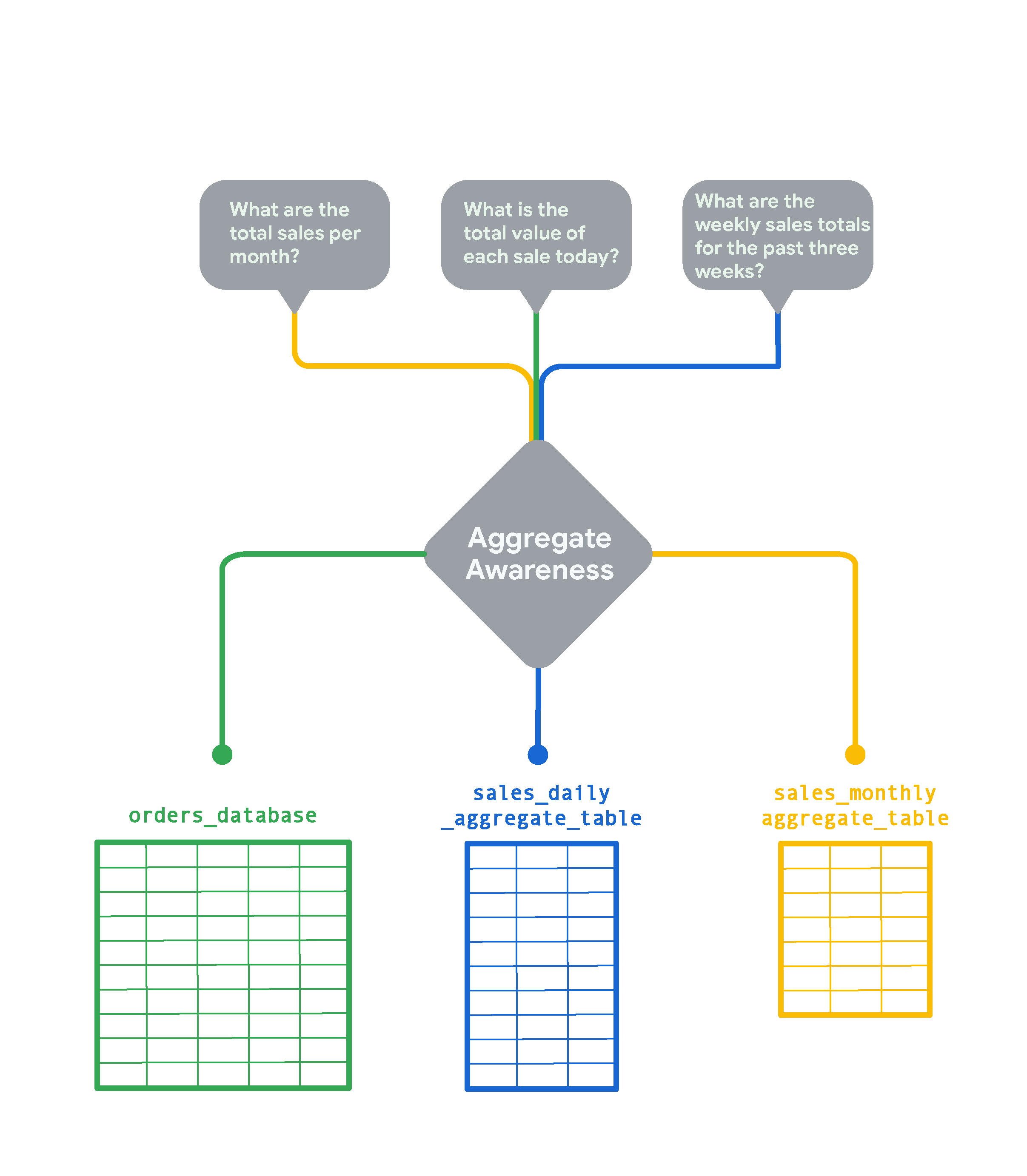
Looker 會運用匯總感知邏輯,查詢最小的匯總資料表,以回答使用者的問題。只有在查詢需要比匯總資料表更精細的資料時,才會使用原始資料表。
您不需要在個別的探索中加入或新增匯總資料表。Looker 會動態調整探索查詢的 FROM 子句,以存取最適合查詢的匯總資料表。也就是說,系統會保留下鑽,並整合探索。有了匯總感知功能,Explore 就能自動運用匯總資料表,但仍可視需要深入瞭解細微資料。
您也可以利用匯總資料表大幅提升資訊主頁的效能,尤其是查詢巨量資料集的圖塊。詳情請參閱 aggregate_table 參數說明頁面的「從資訊主頁取得匯總資料表 LookML」一節。
在專案中新增匯總資料表
Looker 開發人員可以建立符合策略需求的匯總資料表,盡量減少須對資料庫中大型資料表執行查詢的次數。匯總資料表必須保留在資料庫中,才能供匯總感知功能使用。因此,匯總資料表也是一種永久衍生資料表 (PDT)。
匯總資料表是透過 LookML 專案中 explore 參數下的 aggregate_table 參數定義。
以下是 LookML 中含有匯總資料表的 explore 範例:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
如要建立匯總資料表,您可以從頭編寫 LookML,也可以從「探索」或從資訊主頁取得匯總資料表 LookML。如要瞭解 aggregate_table 參數及其子參數的詳細資料,請參閱 aggregate_table 參數說明文件頁面。
設計匯總資料表
如要讓「探索」查詢使用匯總資料表,匯總資料表必須能為「探索」查詢提供準確資料。如果符合下列所有條件,Looker 就能將匯總資料表用於「探索」查詢:
- 探索查詢的欄位是匯總資料表欄位的子集 (請參閱本頁面的「欄位因素」一節)。如果是時間範圍,則可從匯總表格中的時間範圍衍生探索查詢的時間範圍 (請參閱本頁的「時間範圍因素」一節)。
- 「探索」查詢包含匯總感知功能支援的指標類型 (請參閱本頁的「指標類型因素」一節),或「探索」查詢具有完全相符的匯總資料表 (請參閱本頁的「建立與『探索』查詢完全相符的匯總資料表」一節)。
- 探索查詢的時區與匯總資料表使用的時區相符 (請參閱本頁的「時區因素」一節)。
- 探索查詢的篩選器參照匯總資料表中可用的欄位做為維度,或探索查詢的每個篩選器都與匯總資料表中的篩選器相符 (請參閱本頁的「篩選器因素」一節)。
如要確保匯總資料表能為「探索」查詢提供準確資料,方法之一是建立與「探索」查詢完全相符的匯總資料表。詳情請參閱本頁的「建立與探索查詢完全相符的匯總資料表」一節。
現場因素
如要用於「探索」查詢,匯總資料表必須包含該「探索」查詢所需的所有維度和指標,包括用於「探索」查詢中篩選器的欄位。如果「探索」查詢包含匯總資料表中沒有的維度或指標,Looker 就無法使用匯總資料表,而會改用基礎資料表。
舉例來說,如果查詢依維度 A 和 B 分組、依指標 C 匯總,並依維度 D 篩選,則匯總資料表至少須包含維度 A、B 和 D,以及指標 C。
匯總資料表也可以包含其他欄位,但必須至少包含「探索」查詢欄位,才能進行最佳化。時間範圍維度是唯一例外,因為較粗略的時間範圍可從較精細的時間範圍衍生而來。
由於這些欄位考量,匯總資料表專用於定義該資料表的探索。在一個探索下定義的匯總資料表,不會用於其他探索的查詢。
時間範圍因素
Looker 的匯總意識邏輯可從一個時間範圍衍生出另一個時間範圍。只要匯總表格的時間範圍精細程度與探索查詢相同 (或更精細),即可用於查詢。舉例來說,如果探索查詢需要其他時間範圍的資料,例如每日、每月和每年資料,甚至是當月第幾天、當年第幾天和當年第幾週的資料,系統就能使用以每日資料為基礎的匯總資料表。但如果「探索」查詢需要每小時的資料,就無法使用年度匯總資料表,因為匯總資料表的資料不夠精細,無法滿足「探索」查詢的需求。
這項原則也適用於時間範圍子集。舉例來說,如果您有篩選過去三個月的匯總資料表,而使用者查詢資料時篩選過去兩個月,Looker 就能使用該匯總資料表進行查詢。
此外,如果查詢含有時間範圍篩選器,只要匯總資料表的時間範圍與 Explore 查詢中使用的時間範圍篩選器具有相同或更精細的粒度,即可使用匯總資料表。舉例來說,如果匯總資料表含有每日時間範圍維度,即可用於篩選日期、週或月份的探索查詢。
評估類型因素
如要讓「探索」查詢使用匯總資料表,匯總資料表中的指標必須能為「探索」查詢提供準確資料。
因此,系統僅支援特定類型的指標,詳情請參閱以下各節:
如果探索查詢使用任何其他類型的指標,Looker 會使用原始資料表 (而非匯總資料表) 傳回結果。唯一例外狀況是「探索」查詢與匯總資料表查詢完全相符,如「建立與『探索』查詢完全相符的匯總資料表」一節所述。
否則 Looker 會使用原始資料表 (而非匯總資料表) 傳回結果。
支援的指標類型
匯總知名度可用於使用下列指標類型的指標的「探索」查詢:
如要將匯總資料表用於「探索」查詢,Looker 必須能夠對匯總資料表的測量值執行運算,才能在「探索」查詢中提供準確資料。舉例來說,含有 type: sum 的指標可用於匯總認知度,因為您可以加總多個總和:將每週總和的匯總資料表加總,即可取得準確的每月總和。同樣地,您可以使用 type: max 的指標,因為每日最大值的匯總資料表可用於找出準確的每週最大值。
如果是含有 type: average 的測量指標,系統會支援匯總感知功能,因為 Looker 會使用總和和計數資料,從匯總表格準確衍生平均值。
以 SQL 運算式定義的指標
您也可以搭配使用匯總認知度和以 sql 參數中的運算式定義的指標。以 SQL 運算式定義時,系統也支援下列指標類型:
如果指標定義為其他指標的組合,則支援匯總意識,例如:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
如果計算是在 sql 參數中定義,系統也會支援匯總認知度,例如以下指標:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
如果測量指標的 sql 參數中定義了 MIN、MAX 和 COUNT 作業,系統就會支援匯總認知,例如這個測量指標:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
參照 LookML 欄位的測量指標
在指標中使用 sql 運算式時,匯總認知度支援下列類型的欄位參照:
- 使用
${view_name.field_name}格式的參照,表示其他檢視區塊中的欄位 - 使用
${field_name}格式的參照,表示同一檢視區塊中的欄位
如果測量結果是使用 ${TABLE}.column_name 格式定義 (表示資料表中的資料欄),則不支援匯總意識。(如要瞭解如何在 LookML 中使用參照,請參閱「併入 SQL 並參照 LookML 物件」說明文件頁面)。
舉例來說,以這個 sql 參數定義的指標無法在匯總資料表中使用,因為該指標採用 ${TABLE}.column_name 格式:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
如要在匯總表格中加入這項指標,可以改為建立以 ${TABLE}.column_name 格式定義的維度,然後建立參照該維度的指標,如下所示:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
現在您可以在匯總資料表中,使用 wholesale_value 評估指標。
可估算不重複計數的指標
一般來說,匯總認知度不支援不重複計數,因為如果您嘗試匯總不重複計數,就無法取得準確的資料。舉例來說,如果您要計算網站上的不重複使用者,某位使用者可能在間隔三週後造訪網站兩次。如果您嘗試套用每週匯總表格,取得網站上每月不重複使用者人數,該使用者會在每月不重複計數查詢中計入兩次,因此資料會不正確。
如要解決這個問題,請建立與「探索」查詢完全相符的匯總資料表,如本頁「建立與『探索』查詢完全相符的匯總資料表」一節所述。如果探索查詢和匯總資料表查詢相同,不重複計數指標就會提供準確的資料,因此可用於匯總認知度。
您也可以使用不重複計數的近似值。如果方言支援 HyperLogLog 草圖,Looker 就能運用 HyperLogLog 演算法,估算匯總資料表的相異計數。
HyperLogLog 演算法的已知錯誤率約為 2%。Looker 開發人員必須確認可使用指標的近似資料,才能使用 allow_approximate_optimization: yes 參數,這樣系統才能從匯總資料表概略計算指標。
如要瞭解詳情,並查看支援使用 HyperLogLog 計算不重複計數的方言清單,請參閱 allow_approximate_optimization 參數說明文件頁面。
時區因素
在許多情況下,資料庫管理員會使用世界標準時間做為資料庫的時區。不過,許多使用者可能不在世界標準時間時區。Looker 提供多種時區轉換選項,讓使用者能以自己的時區取得查詢結果:
- 查詢時區:這項設定會套用至資料庫連線的所有查詢。如果所有使用者都位於同一時區,您可以設定單一查詢時區,將所有查詢從資料庫時區轉換為查詢時區。
- 使用者專屬時區:可為使用者個別指派及選取時區。在這種情況下,查詢會從資料庫時區轉換為個別使用者的時區。
如要進一步瞭解這些選項,請參閱「使用時區設定」說明文件頁面。
瞭解這些概念有助於掌握匯總感知功能,因為如果查詢包含日期維度或日期篩選條件,匯總資料表必須與原始查詢使用的時區設定相符,才能用於查詢。
如果未指定 timezone 值,匯總資料表會使用資料庫時區。如果符合下列任一情況,資料庫連線也會使用資料庫時區:
如果符合上述任一情況,您可以省略匯總資料表的 timezone 參數。
否則,應定義匯總資料表的時區,以符合可能的查詢,這樣匯總資料表就更有可能派上用場:
- 如果資料庫連線使用單一查詢時區,請將匯總資料表的
timezone值與查詢時區值相符。 - 如果資料庫連線使用特定使用者的時區,您應建立相同的匯總資料表,每個資料表都有不同的
timezone值,以配合使用者的可能時區。
篩選因子
在匯總表格中加入篩選器時,請務必小心。對匯總資料表套用篩選器時,可能會將結果縮小到匯總資料表無法使用的程度。舉例來說,假設您建立每日訂單數的匯總資料表,且該資料表只篩選來自澳洲的太陽眼鏡訂單。如果使用者執行「探索」查詢,想瞭解全球太陽眼鏡的每日訂單數量,Looker 就無法使用匯總資料表,因為匯總資料表只包含澳洲的資料。匯總資料表篩選的資料範圍過於狹窄,無法用於「探索」查詢。
此外,請留意 Looker 開發人員可能已在「探索」中內建的篩選器,例如:
access_filters:套用使用者專屬的資料限制。always_filter:要求使用者在探索查詢中加入特定一組篩選條件。使用者可在查詢時變更預設篩選條件值,但無法移除篩選條件。conditionally_filter:定義一組預設篩選條件,而使用者只要從探索中定義的第二個清單套用至少一個篩選條件,就能覆寫這些預設篩選條件。
這些篩選器類型是以特定欄位為依據。如果探索包含這些篩選器,您必須在 aggregate_table 的 dimensions 參數中加入這些篩選器的欄位。
舉例來說,以下是根據 orders.region 欄位套用存取權篩選條件的探索:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
如要建立用於這項探索的匯總資料表,該資料表必須包含存取篩選器所依據的欄位。在下一個範例中,存取權篩選器是以 orders.region 欄位為依據,而這個欄位也包含在匯總資料表做為維度:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
由於匯總資料表查詢包含 orders.region 維度,因此 Looker 可以動態篩選匯總資料表中的資料,以符合「探索」查詢中的篩選條件。因此,即使探索有存取權篩選器,Looker 仍可將匯總資料表用於探索的查詢。
如果探索查詢使用以 bind_filters 設定的原生衍生資料表,也會受到影響。bind_filters 參數會將探索查詢中的指定篩選器傳遞至原生衍生資料表子查詢。如果是匯總感知,如果「探索」查詢需要使用 bind_filters 的原生衍生資料表,則只有在「探索」查詢中,原生衍生資料表 bind_filters 參數使用的所有欄位,與匯總資料表中的篩選值完全相同時,「探索」查詢才能使用匯總資料表。
建立與「探索」查詢完全相符的匯總資料表
如要確保匯總資料表可用於探索查詢,其中一種方法是建立與探索查詢完全相符的匯總資料表。如果「探索」查詢和匯總資料表都使用相同的指標、維度、篩選條件、時區和其他參數,匯總資料表的結果就會套用至「探索」查詢。如果匯總資料表與「探索」查詢完全相符,Looker 就能使用包含任何類型指標的匯總資料表。
您可以使用「探索」齒輪選單中的「取得 LookML」選項,從「探索」建立匯總資料表。您也可以使用資訊主頁齒輪選單中的「取得 LookML」選項,為資訊主頁中的所有圖塊建立完全相符項目。
判斷查詢使用哪個匯總資料表
具備 see_sql 權限的使用者可以在「探索」的「SQL」分頁中查看註解,瞭解查詢會使用哪個匯總資料表。「SQL」分頁標籤註解也會顯示在開發模式中,因此開發人員可以測試新的匯總資料表,看看 Looker 如何使用這些資料表,再將新資料表推送至正式環境。
舉例來說,根據先前顯示的每月匯總資料表範例,您可以前往「探索」並執行年度銷售總額的查詢。然後點按「SQL」分頁,即可查看 Looker 建立的查詢詳細資料。如果您處於開發模式,Looker 會顯示註解,指出查詢使用的匯總資料表。
從「SQL」分頁的下列註解中,我們可以瞭解 Looker 是使用 sales_monthly 匯總資料表進行這項查詢,以及其他匯總資料表未用於查詢的原因:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
如要瞭解 SQL 分頁中可能顯示的註解,以及如何解決問題,請參閱本頁的「疑難排解」一節。
匯總感知功能的運算節省預估值
如果資料庫連線支援費用估算,且查詢可使用匯總資料表,則「探索」視窗會顯示使用匯總資料表而非直接查詢資料庫,可節省的運算費用。在執行查詢前,系統會在「探索」中的「執行」按鈕旁,顯示匯總的認知度節省金額。
執行查詢前,如要查看查詢會使用哪個匯總資料表,可以點選「SQL」分頁標籤,如本文件頁面的「判斷查詢使用哪個匯總資料表」一節所述。
查詢執行完畢後,「探索」視窗的「執行」按鈕旁會顯示用來回答查詢的匯總資料表。
如果資料庫連線已啟用費用估算功能,系統會顯示匯總的節省金額。詳情請參閱「在 Looker 中探索資料 」說明文件頁面。
Looker 會將新資料併入匯總資料表
對於設有時間篩選器的匯總資料表,Looker 可以將新資料聯集到匯總資料表中。您可能有一個匯總資料表,其中包含過去三天的資料,但該匯總資料表可能是昨天建立的。匯總資料表會缺少今天的資訊,因此您不會預期使用該資料表,對最近的每日資訊執行「探索」查詢。
不過,Looker 仍可使用該匯總資料表中的資料進行查詢,因為 Looker 會對最新資料執行查詢,然後將這些結果併入匯總資料表中的結果。
在下列情況下,Looker 可以將新資料與匯總資料表的資料聯集:
- 匯總資料表設有時間篩選器。
- 匯總表格包含的維度,與時間篩選器所依據的時間欄位相同。
舉例來說,下列匯總資料表含有以 orders.created_date 欄位為準的維度,以及以相同欄位為準的時間篩選器 ("3 days"):
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
如果這個匯總資料表是昨天建立的,Looker 會擷取匯總資料表尚未納入的最新資料,然後將最新結果與匯總資料表的結果合併。也就是說,使用者可以取得最新資料,同時運用匯總認知度來提升成效。
如果您處於開發模式,可以按一下「探索」的「SQL」分頁標籤,查看 Looker 用於查詢的匯總資料表,以及 Looker 用於匯入匯總資料表未納入的新資料的 UNION 陳述式。
匯總資料表必須保留
匯總資料表必須保留在資料庫中,才能供匯總感知功能使用。持久性策略是在匯總資料表的 materialization 參數中指定。由於匯總資料表是永久衍生資料表 (PDT),因此匯總資料表與 PDT 的需求條件相同。詳情請參閱「Looker 中的衍生資料表」說明文件頁面。
如果方言支援永久累加型衍生資料表,您可以在專案中建立這類資料表。Looker 會將最新資料附加至資料表,藉此建構永久累加型衍生資料表,而非重新建構整個資料表。由於匯總資料表本身就是一種 PDT,因此您也可以建立累加型匯總資料表。如要進一步瞭解永久累加型衍生資料表,請參閱永久累加型衍生資料表說明文件頁面。如需漸進式匯總資料表的範例,請參閱 increment_key 參數說明文件頁面。
如果使用者具備 develop 權限,即可覆寫持續性設定,並重建查詢的所有匯總資料表,以取得最新資料。如要重建查詢的資料表,請從「探索動作」齒輪選單中選取「重建衍生資料表並執行」選項。
您必須等待「探索」查詢載入完成,才能使用這個選項。
「重建衍生資料表並執行」選項會重建查詢中參照的所有衍生資料表,以及查詢中資料表所依附的任何衍生資料表。包括匯總資料表,這類資料表本身就是永久衍生資料表。
如果使用者啟動「重建衍生資料表並執行」選項,查詢會等待資料表重建完成,再載入結果。其他使用者的查詢仍會使用現有資料表。重建永久資料表後,所有使用者都會使用重建的資料表。
如要進一步瞭解「重建衍生資料表並執行」選項,請參閱「Looker 中的衍生資料表」說明文件頁面。
疑難排解
如「判斷查詢使用哪個匯總資料表」一節所述,如果您處於開發模式,可以在「探索」中執行查詢,然後按一下「SQL」分頁標籤,查看查詢使用的匯總資料表 (如有) 相關註解。
如果查詢未使用匯總資料表,「SQL」分頁也會顯示相關註解。如果未使用的匯總資料表,註解開頭會是:
Did not use [explore name]::[aggregate table name];
舉例來說,以下是關於查詢未採用「探索」中定義的 sales_daily 匯總資料表的註解:order_items
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
在本例中,查詢中的篩選器導致系統無法使用匯總資料表。
下表列出無法使用匯總資料表的其他可能原因,以及提高匯總資料表可用性的步驟。
| 未使用匯總資料表的原因 | 說明和可能步驟 |
|---|---|
| 探索中沒有這類欄位。 | 發生 LookML 驗證類型錯誤。這很可能是因為匯總資料表定義有誤,或是匯總資料表的 LookML 中有錯字。可能是欄位名稱有誤等問題。如要解決這個問題,請確認匯總表格中的維度和指標與「探索」中的欄位名稱相符。如要進一步瞭解如何定義匯總資料表,請參閱 aggregate_table 參數說明文件頁面。 |
| 匯總資料表不會在查詢中納入下列欄位。 | 如要用於「探索」查詢,匯總資料表必須包含該「探索」查詢所需的所有維度和指標,包括用於「探索」查詢中篩選器的欄位。如果「探索」查詢包含匯總資料表中沒有的維度或指標,Looker 就無法使用匯總資料表,而會改用基礎資料表。詳情請參閱本頁的「欄位因素」一節。時間範圍維度是唯一例外,因為較粗略的時間範圍可從較精細的時間範圍衍生而來。如要解決這個問題,請確認探索查詢的欄位已納入匯總資料表定義。 |
| 查詢包含下列篩選器,但這些篩選器既未納入欄位,也未與匯總資料表中的篩選器完全相符。 | 探索查詢中的篩選器會阻止 Looker 使用匯總資料表。 如要解決這個問題,請採取下列任一做法:
|
| 查詢包含下列無法匯總的指標。 | 查詢包含一或多個不支援匯總意識度的測量指標類型,例如不重複計數、中位數或百分位數。如要解決這個問題,請檢查查詢中的各項指標類型,確認是否為支援的指標類型。此外,如果 Explore 具有聯結,請確認您的指標不會透過扇出聯結轉換為相異指標 (對稱匯總)。如需說明,請參閱本頁的「使用彙整的對稱探索」一節。 |
| 其他匯總資料表更適合用於最佳化。 | 查詢有多個可用的匯總資料表,而 Looker 找到更適合的匯總資料表。在此情況下,您無須採取任何行動。 |
Looker 未進行任何分組 (因為有 primary_key 或 cancel_grouping_fields 參數),因此無法彙整查詢。 |
查詢參照的維度會導致查詢無法使用 GROUP BY 子句,因此 Looker 無法使用任何匯總資料表。
如要解決這個問題,請確認檢視區塊的 primary_key 參數和「探索」的 cancel_grouping_fields 參數設定正確無誤。 |
| 匯總表格包含查詢中沒有的篩選器。 | 匯總資料表含有查詢中沒有的非時間篩選器。如要解決這個問題,請從匯總資料表中移除篩選器。詳情請參閱本頁的「篩選條件」一節。 |
欄位在「探索」查詢中定義為僅限篩選器欄位,但列於匯總資料表的 dimensions 參數中。 |
匯總資料表的 dimensions 參數會列出僅在「探索」查詢中定義為 filter 欄位的欄位。如要解決這個問題,請從匯總表格的 dimensions 清單中移除該欄位。如果匯總資料表需要這個欄位,請將其新增至匯總資料表查詢中的 filters 清單。 |
| 最佳化工具無法判斷為何未使用匯總資料表。 | 這個註解適用於特殊情況。如果經常使用的探索查詢出現這種情況,您可以建立與探索查詢完全相符的匯總資料表。如 aggregate_table 參數頁面所述,您可以從「探索」取得匯總資料表 LookML。 |
注意事項
含彙整的探索對稱式彙整
請注意,在聯結多個資料庫表格的探索中,Looker 可以將 SUM、COUNT 和 AVERAGE 類型的測量值分別算繪為 SUM DISTINCT、COUNT DISTINCT 和 AVERAGE DISTINCT。Looker 這麼做是為了避免扇出誤算。舉例來說,count 測量指標會以 count_distinct 測量指標類型呈現。這是為了避免聯結的扇出誤算,也是 Looker 對稱匯總功能的一部分。如要瞭解 Looker 的這項功能,請參閱對稱匯總的最佳做法頁面。
對稱匯總功能可避免誤算,但有時也會導致匯總資料表無法使用,因此請務必瞭解這項功能。
如果是匯總感知支援的指標類型,則適用於 sum、count 和 average。如果符合下列條件,Looker 會將這些類型的指標算繪為 DISTINCT:
如要瞭解這些類型的聯結,請參閱 relationship 參數說明文件頁面。
如果發現匯總資料表未因此原因而使用,您可以建立匯總資料表,完全比對「探索」查詢,以便在「探索」中使用這些指標類型 (含彙整)。詳情請參閱本頁的「建立與 Explore 查詢完全相符的匯總資料表」一節。
此外,如果您的 SQL 方言支援 HyperLogLog 草圖,可以將 allow_approximate_optimization: yes 參數新增至指標。以 allow_approximate_optimization: yes 定義計數測量指標時,即使系統將其算為不重複計數,Looker 仍可將該指標用於匯總認知度。
詳情請參閱 allow_approximate_optimization 參數說明文件頁面,以及支援 HyperLogLog 草圖的 SQL 方言清單。
匯總感知功能支援的方言
使用匯總感知功能的權限取決於 Looker 連線使用的資料庫方言。在最新版 Looker 中,下列方言支援匯總認知:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
支援方言,可逐步建構匯總資料表
如要讓 Looker 支援 Looker 專案中的漸進式匯總資料表,資料庫方言也必須支援這類資料表。下表列出最新版 Looker 中支援遞增建構 PDT 的方言:
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |