借助自定义连接器,您可以集成 Gemini Enterprise 标准连接器库之外的外部数据源,从而让组织中的独特数据能够通过自然语言进行搜索和访问,并由 Gemini 和 Google 的高级搜索智能技术提供支持。自定义连接器直接与 Discovery Engine API 互动,从而实现强大的数据存储、索引编制和智能搜索功能。连接器会将源信息转换为基于 JSON 的标准化文档格式(用于构建内容、元数据和访问控制列表 [ACL]),并确保将这些数据整理到数据存储区中。这些存储区充当逻辑代码库,理想情况下代表一种文档格式,每个存储区都有自己的专用搜索索引和配置。
自定义连接器的工作原理
自定义连接器通过使用自动化数据流水线来执行三项关键操作:提取、转换和同步。此流程可确保外部数据得到正确准备并上传到 Gemini Enterprise。
提取:连接器使用外部系统的 API、数据库或文件格式从外部系统提取数据,包括文档、元数据和权限。
转换:连接器将原始数据转换为 Discovery Engine 的文档格式,构建内容和元数据,并为每个文档分配一个全局唯一 ID。对于访问权限控制,您可以直接使用 Google 识别的身份,也可以为外部用户或自定义群组使用身份映射。
同步:连接器会将文档上传到 Gemini Enterprise 数据存储区,并通过预定作业保持文档处于最新状态。数据同步是使用为实体创建的数据存储区执行的。如需详细了解如何创建数据存储区,请参阅数据存储区创建流程。根据您的需求选择同步模式:增量会添加和更新数据,而完全会替换整个数据集。
ACL 和身份映射
如需管理文档级访问权限,请根据数据使用的身份格式,选择纯 ACL 或身份映射这两种方法之一。
纯 ACL (AclInfo):当数据源使用 (Google Cloud) 识别的基于邮箱的身份时,使用此方法。此方法非常适合直接定义哪些人有权访问。
身份映射:当数据源使用用户名、旧版 ID 或其他外部身份系统时,使用此方法。它在外部身份群组(例如 EXT1)和内部身份提供方 (IDP) 用户或组(例如 IDPUser1@example.com)之间建立了清晰的一对一关联。这样,系统就可以了解并应用来自源系统的基于群组的访问控制,这在以下情况下非常有用:API 返回群组标签,但没有完整的用户成员身份信息;或者为了高效伸缩 ACL,无需在每个文档中列出数千名用户。此过程需要将所有嵌套或分层身份结构解析为直接映射的扁平列表,通常采用指定的 JSON 格式。使用外部身份的唯一外部身份群组 ID(例如,EXT1)来维护系统完整性。如需了解详情和查看示例,请参阅身份映射。
数据存储区创建流程
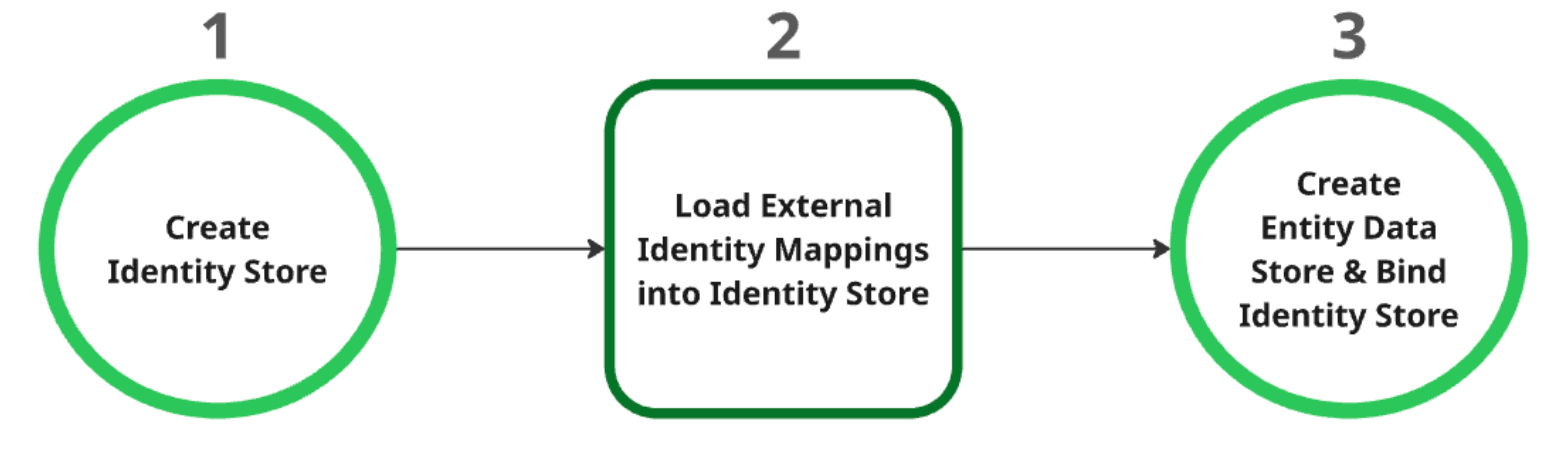
创建身份存储区:此存储区充当所有身份映射的父级资源。创建后,系统会自动提取项目级身份提供方 (IDP) 设置。如需了解详情,请参阅检索或创建身份存储区。
将外部身份映射加载到身份存储区:创建身份存储区后,将外部身份数据加载到其中。如需了解详情,请参阅将身份映射注入到身份存储区。
创建并绑定实体数据存储区:只有在成功创建身份存储区并加载身份映射后,才能创建实体数据存储区。您必须在创建身份存储区期间将其绑定到实体数据存储区。如需详细了解如何创建实体数据存储区,请参阅创建数据存储区。
数据同步
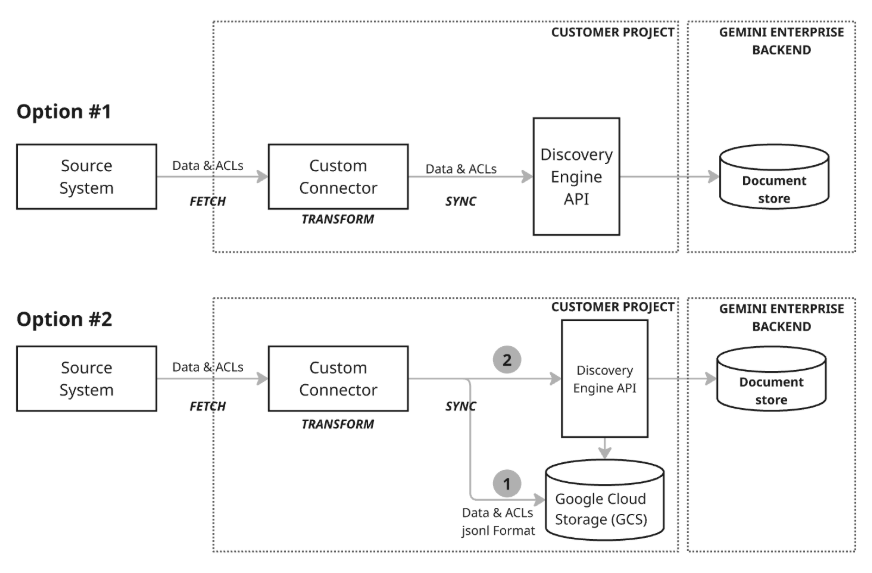
同步数据有两种不同的架构模型:
架构模型 1:增量 upsert:增量 upsert 方法最适合数据流式传输且需要实时更新的场景。连接器利用 Discovery Engine API,通过在发生小更改时调用相应函数来执行高效的增量更新插入(插入或更新数据)。这种注重最小更改规模和最小延迟的做法可确保文档存储区始终保持最新状态,即使数据变化很快也是如此。
架构模型 2:与 Google Cloud Storage 全面同步:此推荐方法提供了一整套数据管理功能,并且非常灵活。它支持完全同步(允许在整个数据集中插入、更新和删除数据)和增量同步(仅通过发送更改来处理插入和更新)。这使得该方法能够满足各种数据需求,尤其是在管理更大规模或更复杂的数据操作时。此模型采用暂存流程(图中的第 1 步),连接器先将数据写入 Google Cloud Storage (GCS),然后利用 Discovery Engine API 通过从暂存的 GCS 位置调用必要的导入函数来更新文档存储区。
自定义连接器非常灵活,足以支持混合架构,让您可以针对快速变化的数据实现增量更新插入,并针对预定的完整数据更新或删除实现全面同步。