Los conectores personalizados te permiten integrar fuentes de datos externas que no forman parte de la biblioteca de conectores estándar de Gemini Enterprise, lo que hace que los datos únicos de tu organización se puedan buscar y acceder a ellos mediante lenguaje natural, con la tecnología de Gemini y la inteligencia de búsqueda avanzada de Google. El conector personalizado interactúa directamente con la API Discovery Engine, lo que permite disfrutar de sólidas funciones de almacenamiento de datos, indexación y búsqueda inteligente. El conector convierte la información de origen en el formato de documento estandarizado basado en JSON (estructurando el contenido, los metadatos y las listas de control de acceso) y se asegura de que estos datos se organicen en almacenes de datos. Estas tiendas actúan como repositorios lógicos y, lo ideal, es que representen un único formato de documento. Cada una tiene su propio índice de búsqueda y sus propias configuraciones.
Cómo funcionan los conectores personalizados
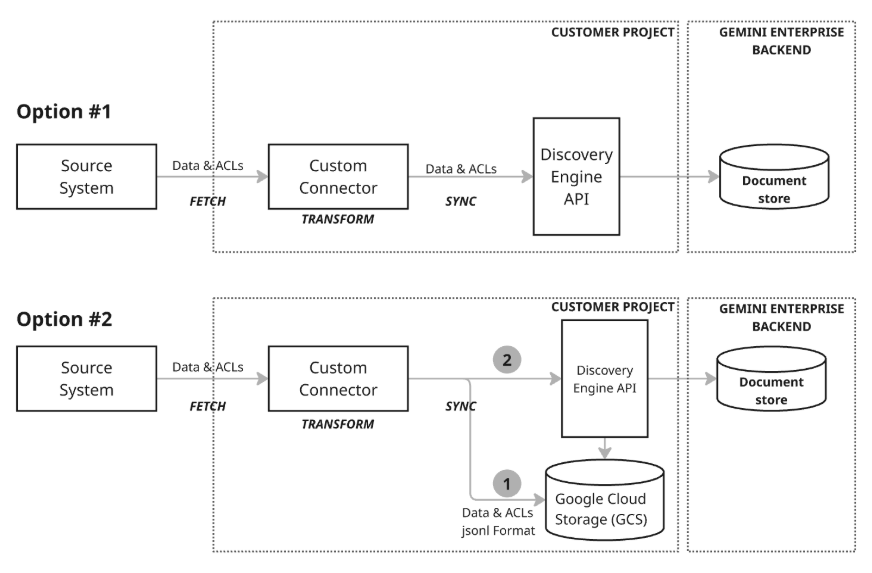
Los conectores personalizados funcionan mediante una canalización de datos automatizada que realiza tres acciones clave: obtener, transformar y sincronizar. Este proceso asegura que los datos externos se preparen y se suban correctamente a Gemini Enterprise.
Obtención: el conector extrae datos, incluidos documentos, metadatos y permisos, del sistema externo mediante sus APIs, bases de datos o formatos de archivo.
Transformación: el conector convierte los datos sin procesar al formato de documento de Discovery Engine, estructura el contenido y los metadatos, y asigna un ID único global a cada documento. Para los controles de acceso, puedes usar directamente las identidades reconocidas por Google o la asignación de identidades para usuarios externos o grupos personalizados.
Sincronización: el conector sube los documentos a los almacenes de datos de Gemini Enterprise y los mantiene actualizados mediante tareas programadas. La sincronización de datos se realiza mediante un almacén de datos creado para una entidad. Para obtener más información sobre cómo crear un almacén de datos, consulta Proceso de creación de almacenes de datos. Elige un modo de sincronización en función de tus necesidades: Incremental añade y actualiza datos, mientras que Completo sustituye todo el conjunto de datos.
LCAs y mapeado de identidades
Para gestionar el acceso a nivel de documento, puedes elegir entre dos métodos: listas de control de acceso puras o asignación de identidades, en función del formato de identidad que utilicen los datos.
LCAs puras (AclInfo): este método se usa cuando la fuente de datos utiliza identidades basadas en correo electrónico reconocidas por (Google Cloud). Este enfoque es ideal para definir directamente quién tiene acceso.
Mapeado de identidades: este método se usa cuando la fuente de datos utiliza nombres de usuario, IDs antiguos u otros sistemas de identidad externos. Establece una asociación clara e individual entre grupos de identidades externas (por ejemplo, EXT1) y usuarios o grupos de proveedores de identidades (IDPs) internos (por ejemplo, IDPUser1@example.com). Permite que el sistema comprenda y aplique controles de acceso basados en grupos del sistema de origen, lo que resulta útil cuando una API devuelve etiquetas de grupo sin membresías de usuario completas o para escalar las listas de control de acceso de forma eficiente sin tener que enumerar miles de usuarios por documento. El proceso requiere resolver todas las estructuras de identidad anidadas o jerárquicas en una lista plana de asignaciones directas, normalmente en un formato JSON especificado. Usa IDs de grupo de identidad externa únicos (por ejemplo, EXT1) para que las identidades externas mantengan la integridad del sistema. Para obtener más información y ejemplos, consulta Asignación de identidades.
Proceso de creación de almacenes de datos
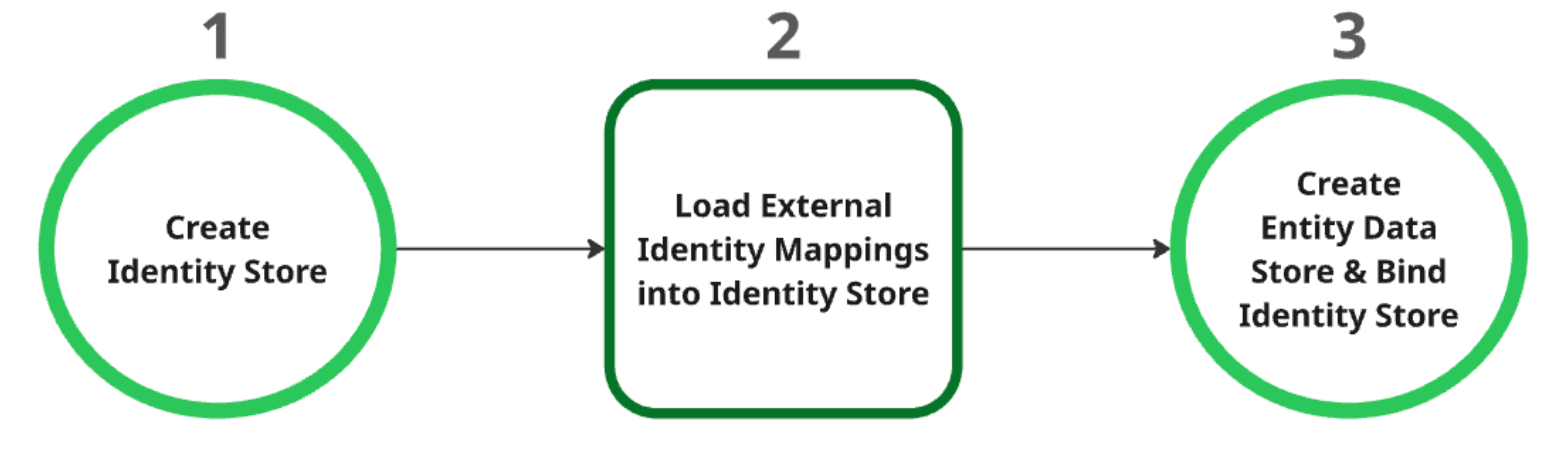
Crea el almacén de identidades: este almacén actúa como recurso superior de todas las asignaciones de identidades. Una vez creado, se obtienen automáticamente los ajustes del proveedor de identidades (IDP) a nivel de proyecto. Para obtener más información, consulta Recuperar o crear un almacén de identidades.
Cargar mapeados de identidades externas en el almacén de identidades: después de crear el almacén de identidades, carga los datos de identidades externas en él. Para obtener más información, consulte Ingerir la asignación de identidades en el almacén de identidades.
Crea y vincula el almacén de datos de entidades: el almacén de datos de entidades solo se puede crear después de que se haya creado correctamente el almacén de identidades y se hayan cargado las asignaciones de identidades. Debes vincular el almacén de identidades al almacén de datos de la entidad durante su creación. Para obtener más información sobre cómo crear un almacén de datos de entidades, consulta Crear un almacén de datos.
Sincronizar datos
Hay dos modelos de arquitectura diferentes para sincronizar datos:
Modelo de arquitectura 1: upsert incremental. El enfoque de upsert incremental es el más adecuado para situaciones en las que los datos se transmiten y requieren actualizaciones en tiempo real. El conector aprovecha la API Discovery Engine para realizar inserciones y actualizaciones incrementales eficientes (insertar o actualizar datos) llamando a las funciones adecuadas con pequeños cambios a medida que se producen. Este enfoque en los tamaños de cambio mínimos y el retraso mínimo mantiene la tienda de documentos muy actualizada, incluso con datos que cambian rápidamente.
Modelo de arquitectura 2: sincronización completa con Google Cloud Storage: este enfoque recomendado ofrece un conjunto completo de funciones de gestión de datos y una gran flexibilidad. Admite sincronizaciones completas, que permiten insertar, actualizar y eliminar datos en todo el conjunto de datos, y sincronizaciones incrementales, que solo gestionan las inserciones y las actualizaciones enviando los cambios. Esto hace que el enfoque sea sólido para una amplia gama de necesidades de datos, sobre todo para gestionar operaciones de datos más grandes o complejas. Este modelo utiliza un proceso de staging (paso 1 del diagrama) en el que el conector primero escribe los datos en Google Cloud Storage (GCS) y, a continuación, aprovecha la API Discovery Engine para actualizar el almacén de documentos llamando a las funciones de importación necesarias desde la ubicación de GCS.
Los conectores personalizados son lo suficientemente flexibles como para admitir una arquitectura híbrida, lo que te permite implementar la inserción y actualización incremental de datos que cambian rápidamente y la sincronización completa de actualizaciones o eliminaciones de datos programadas.