
Document AI מאפשר לכם לאמן גרסאות חדשות של מעבדים באמצעות נתוני אימון משלכם, ולהעריך את האיכות של גרסת המעבד בהשוואה לנתוני בדיקה משלכם.
האפשרות הזו שימושית כשרוצים להשתמש במעבד בהתאמה אישית. יש מעבד Document AI לסוג המסמך שלך, אבל אפשר לאמן מחדש גרסה מותאמת אישית שלו כדי שתתאים לצרכים שלך.
בדרך כלל, האימון וההערכה מתבצעים במקביל כדי להגיע לגרסה של מעבד באיכות גבוהה שאפשר להשתמש בה.
Document AI
Document AI מאפשר לכם ליצור כלי חילוץ בהתאמה אישית, שמחלץ ישויות ממסמכים מסוג מסוים, למשל, הפריטים בתפריט או השם והפרטים ליצירת קשר מקורות חיים.
בניגוד למעבדים אחרים, מעבדים בהתאמה אישית לא מגיעים עם גרסאות מעובדות מראש, ולכן הם לא יכולים לעבד מסמכים עד שתאמנו גרסה מאפס.
כדי להתחיל להשתמש ב-Document AI, אפשר לעיין במאמר בנושא יצירת מעבד מותאם אישית משלכם.
עדכון של מעבד
אתם יכולים להמשיך לאמן גרסאות חדשות של מעבדים כדי לשפר את הדיוק של הנתונים, לחלץ שדות מותאמים אישית נוספים מהמסמכים ולהוסיף תמיכה בשפות חדשות.
אימון מתקדם מתבצע באמצעות למידת העברה בגרסאות של מעבדים שאומנו מראש על ידי Google, ובדרך כלל נדרשים פחות נתונים מאשר באימון מאפס.
כדי להתחיל, אפשר לעיין במאמר בנושא המשך אימון של מעבד שאומן מראש.
מעבדים נתמכים
לא כל המעבדים המיוחדים תומכים בהדרכה. אלה המעבדים שתומכים באימון.
שיקולים והמלצות לגבי נתונים
האיכות והכמות של הנתונים קובעות את האיכות של האימון, האימון הנוסף וההערכה.
החלק של קבלת קבוצה של מסמכים מייצגים מהעולם האמיתי ומתן מספיק תוויות באיכות גבוהה הוא בדרך כלל החלק שלוקח הכי הרבה זמן ומשאבים בתהליך.
מספר המסמכים
אם לכל המסמכים יש פורמט דומה (לדוגמה, טופס קבוע עם שונות נמוכה מאוד), נדרשים פחות מסמכים כדי להשיג דיוק. ככל שהשונות גבוהה יותר, כך נדרשים יותר מסמכים.
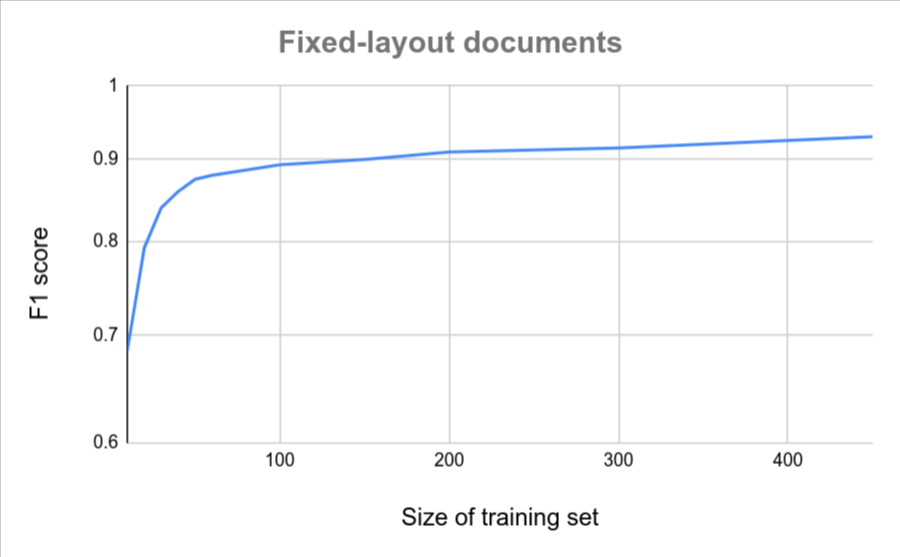
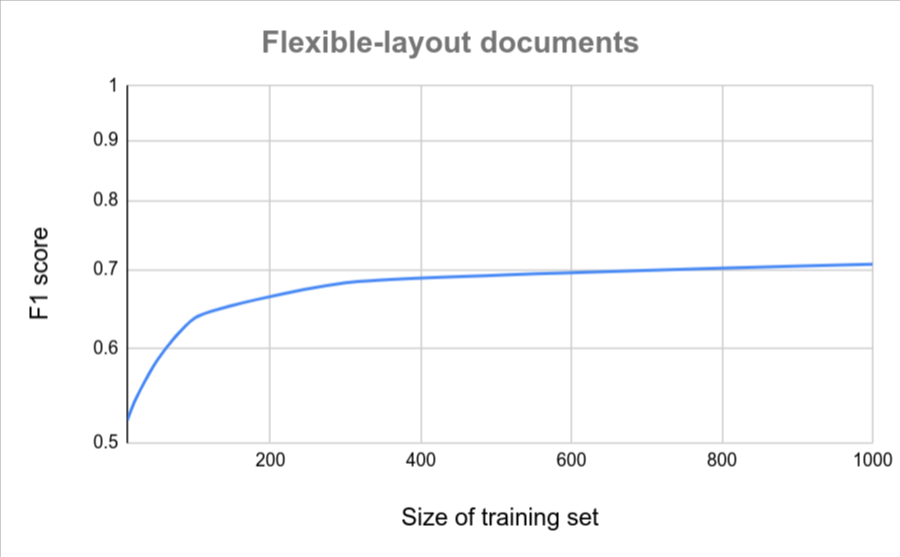
בתרשימים הבאים מוצגת הערכה גסה של מספר המסמכים שנדרשים כדי שמחלץ מסמכים בהתאמה אישית ישיג ציון איכות מסוים.
| מגוון קטן | שונות גבוהה |
|---|---|
 |
 |
יצירת תוויות לנתונים
כדאי לעיין באפשרויות לתווית מסמכים ולוודא שיש לכם מספיק משאבים להוספת הערות למסמכים במערך הנתונים.
אימון מודלים
מעבדי חילוץ מותאמים אישית יכולים להשתמש בסוגים שונים של מודלים, בהתאם לתרחיש השימוש הספציפי ולנתוני האימון הזמינים.
- מודל בהתאמה אישית: מודל שמשתמש בנתוני אימון מתויגים.
- מבוססות על תבנית: מסמכים עם פריסה קבועה.
- מבוסס-מודל: מסמכים עם וריאציות מסוימות בפריסה.
- מודל AI גנרטיבי: מבוסס על מודלים בסיסיים שעברו אימון מראש ודורשים אימון נוסף מינימלי.
בטבלה הבאה מוצגים תרחישי שימוש שמתאימים לכל סוג מודל.
| מודל בהתאמה אישית | AI גנרטיבי | ||
|---|---|---|---|
| מבוסס על תבנית | מבוסס על מודל | ||
| גרסת פריסה | ללא | נמוכה עד בינונית | גבוהה |
| כמות הטקסט החופשי (לדוגמה, פסקאות בחוזה) | נמוכה | נמוכה | גבוהה |
| כמות נתוני האימון הנדרשת | נמוכה | גבוהה | נמוכה |
| רמת הדיוק עם נתוני אימון מוגבלים | גבוה יותר | נמוך יותר | גבוה יותר |
איך משפרים את הביצועים של מעבד באמצעות תיאורי נכסים
מתי כדאי להשתמש במעבד אחר
הנה כמה דוגמאות למקרים שבהם כדאי לשקול אפשרויות אחרות מלבד Document AI Workbench, או להתאים את תהליך העבודה:
- פורמטים מסוימים של קלט מבוסס-טקסט (.txt, .html, .docx, .md וכו') לא נתמכים ב-Document AI Workbench. כדאי לשקול שימוש במוצרים אחרים לעיבוד שפה מובנים מראש או בהתאמה אישית ב- Google Cloud, כמו Cloud Natural Language API.
- הסכימה של הכלי המותאם אישית לחילוץ מסמכים תומכת בעד 150 תוויות של ישויות. אם הלוגיקה העסקית שלכם דורשת יותר מ-150 ישויות בהגדרת הסכימה, כדאי לאמן כמה מעבדים, שכל אחד מהם יתמקד בקבוצת משנה של ישויות.
איך מאמנים מעבד
בהנחה שכבר יצרתם מעבד שתומך באימון או באימון מחדש והוספתם תוויות למערך הנתונים, אתם יכולים לאמן גרסה חדשה של מעבד מאפס. אפשר גם להמשיך לאמן גרסה חדשה של מעבד על סמך גרסה קיימת.
גרסת מעבד האימון
ממשק משתמש באינטרנט
במסוף Google Cloud , עוברים לכרטיסייה Train של המעבד.
לוחצים על עריכת סכימה כדי לפתוח את הדף ניהול תוויות. בודקים את התוויות של המעבד.
התוויות שמופעלות בזמן האימון קובעות את הישויות שגרסת המעבד החדשה מחלצת. אם תווית לא פעילה בסכימה, מעבד הגרסה לא מחלץ את התווית הזו, גם אם המסמכים מסומנים בתווית.
בכרטיסייה Train (אימון), לוחצים על View Label Stats (הצגת נתוני התוויות) ומאמתים את קבוצת הבדיקה וקבוצת הנתונים לאימון. מסמכים שתויגו אוטומטית, לא תויגו או לא הוקצו לא נכללים באימון ובהערכה.
לוחצים על אימון גרסה חדשה.
השדה Version Name מגדיר את השדה
nameשלprocessorVersion.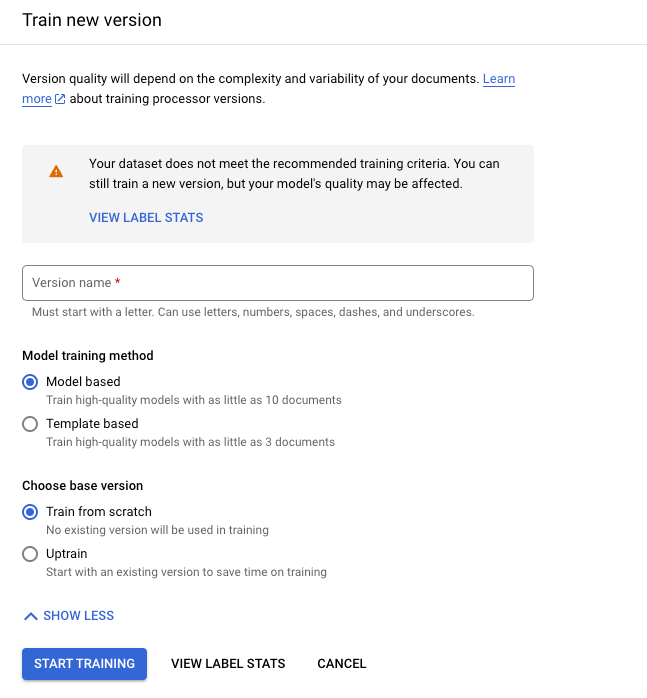
לוחצים על Start training (התחלת האימון) ומחכים עד שהגרסה החדשה של המעבד תאומן ותיבדק.
אפשר לעקוב אחרי התקדמות האימון בכרטיסייה ניהול גרסאות:
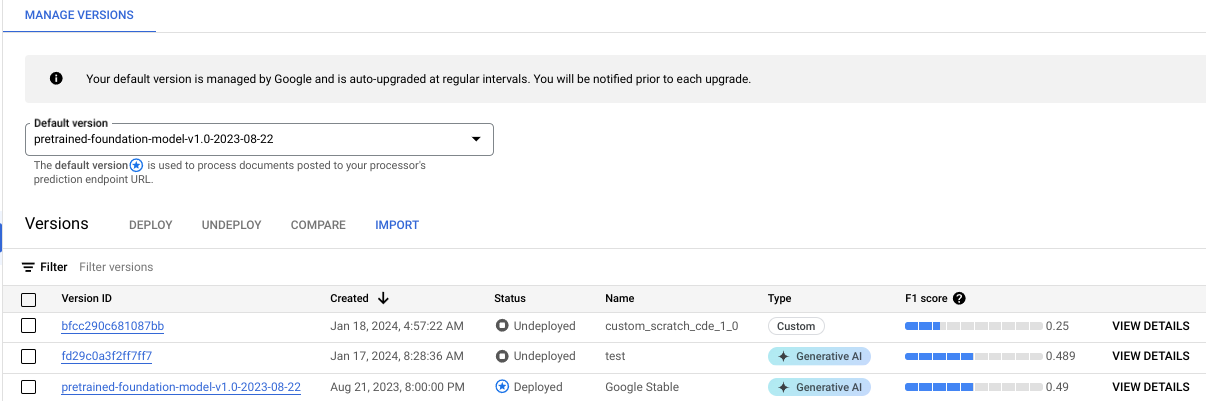
לוחצים על הכרטיסייה Evaluate & Test (הערכה ובדיקה) כדי לראות את הביצועים של גרסת המעבד החדשה בקבוצת נתונים לבדיקה. מידע נוסף זמין במאמר בנושא הערכת גרסת המעבד.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
פריסה ושימוש בגרסת המעבד
אתם יכולים לפרוס ולנהל את גרסאות המעבד בדיוק כמו כל גרסה אחרת של מעבד. מידע נוסף זמין במאמר בנושא ניהול גרסאות של מעבדים.
אחרי הפריסה, אפשר לשלוח בקשת עיבוד למעבד המותאם אישית.
השבתה או מחיקה של מעבד
אם אתם לא רוצים יותר להשתמש במעבד, אתם יכולים להשבית או למחוק אותו. אם משביתים מעבד, אפשר להפעיל אותו מחדש. אם מוחקים מעבד, אי אפשר לשחזר אותו.
בחלונית Document AI שמימין, לוחצים על My processors.
לוחצים על סמל שלוש הנקודות האנכיות משמאל לשם המעבד. לוחצים על השבתת המעבד או על מחיקת המעבד.
מידע נוסף זמין במאמר בנושא ניהול גרסאות של מעבדים.
שדרוג גרסה של מעבד שעבר כוונון עדין
אפשר לשדרג גרסאות של מעבדים של כלי חילוץ מותאם אישית שעברו כוונון עדין לגרסת בסיס חדשה יותר. ההגדרות של גרסת הבסיס החדשה יותר יתבססו על הגרסה הישנה יותר. הוא ישתמש בנתוני האימון של המעבד שנמצאים בגרסאות המקוריות.
במסוף של Google Google Cloud , עוברים לכרטיסייה Deploy & use (פריסה ושימוש) של המעבד ומסמנים את תיבת הסימון של גרסת מעבד נתמכת לשדרוג. ההגדרה הזו תשמש כבסיס להגדרת הגרסה החדשה של המעבד.
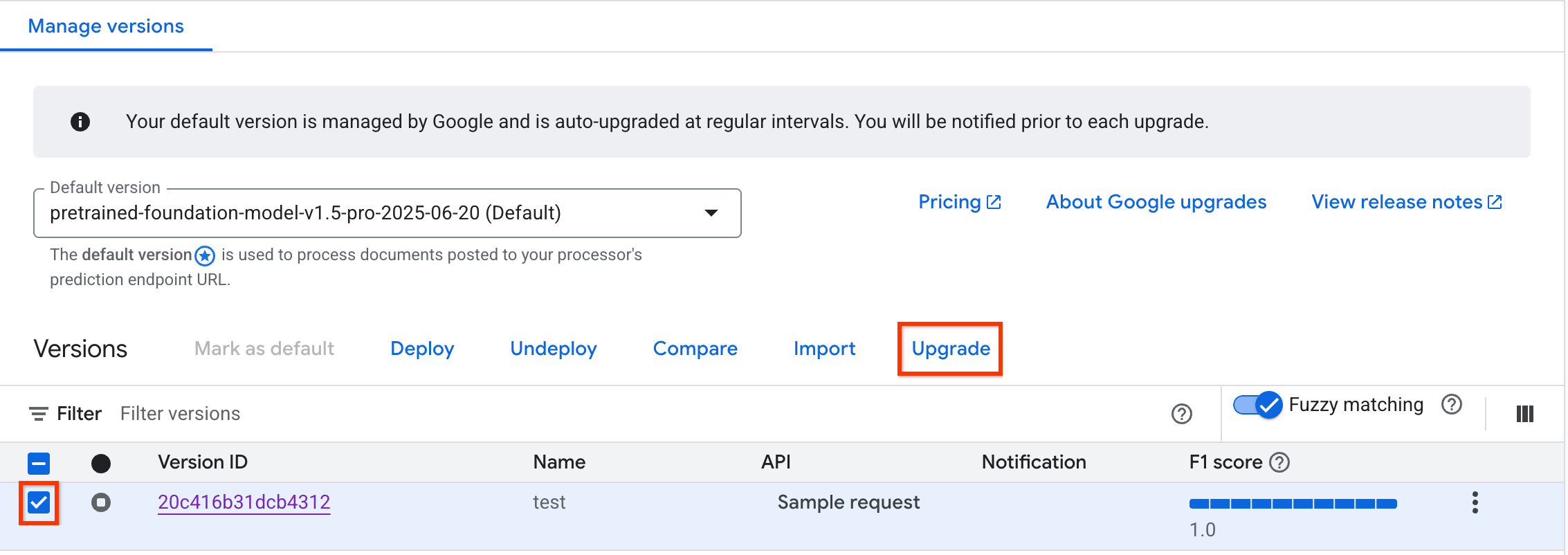
בוחרים באפשרות שדרוג המופעלת. מזינים את השם ואת גרסת הבסיס של גרסת המעבד החדשה.
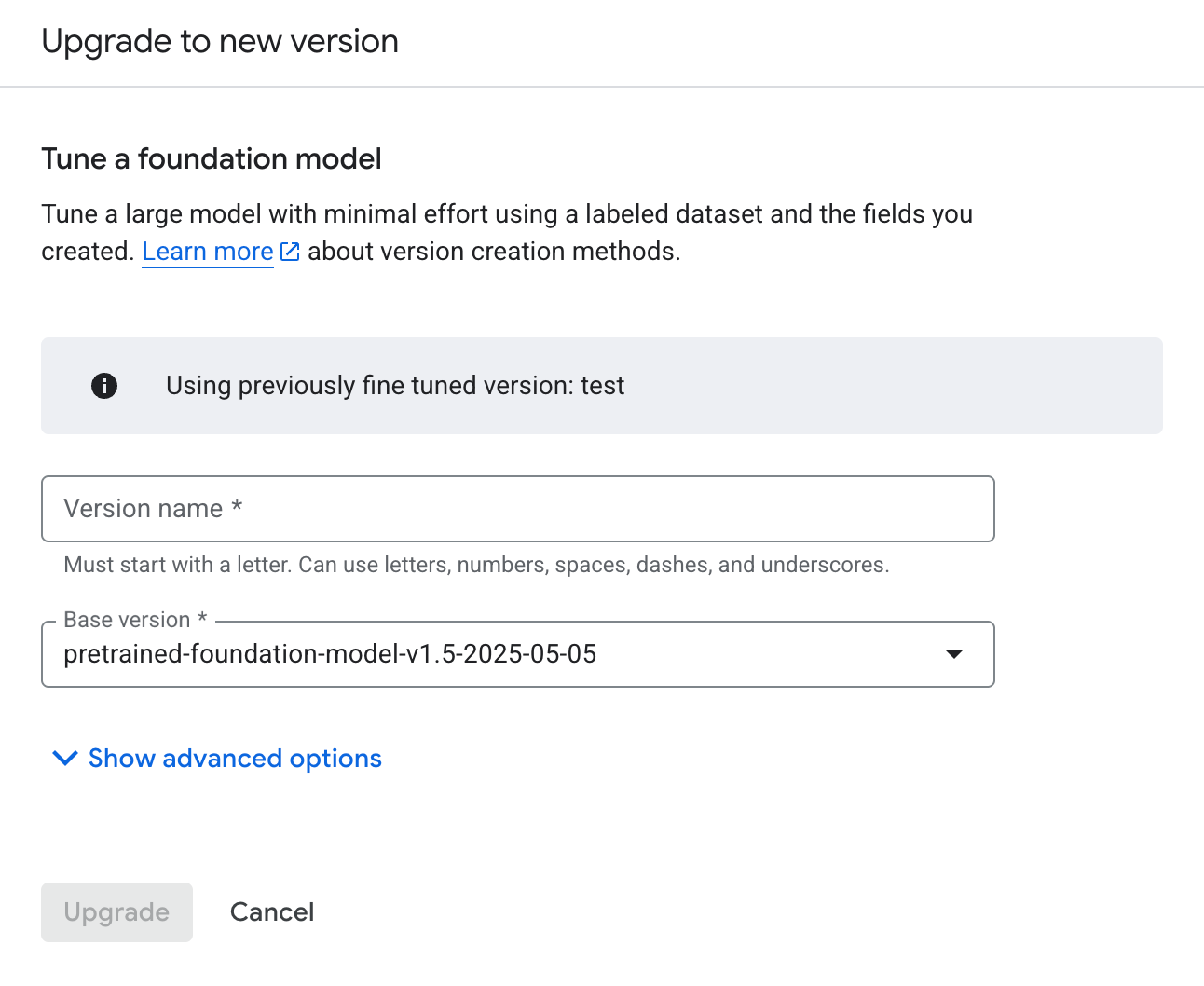
לוחצים על שדרוג וממתינים עד שהגרסה החדשה של המעבד תלמד.
שימוש ב-API לשדרוג
אפשר גם להשתמש בקריאות API כדי לשדרג גרסאות של מעבדי חילוץ מותאם אישית שעברו כוונון עדין לגרסת בסיס חדשה יותר.
curl
בדוגמה הזו מוסבר איך להעביר מודל processor קיים שעבר כוונון באמצעות השדה FoundationModelTuningOptions ב-TrainingMethod.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים במידע שמופיע בכרטיסייה סקירה כללית של המעבד במסוףGoogle Cloud של Document AI.
- LOCATION: המיקום של המעבד.
- PROJECT_ID: מזהה הפרויקט.
- PROCESSOR_ID: מזהה המעבד.
- DISPLAY_NAME: השם המוצג החדש של המעבד.
- BASE_PROCESSOR_VERSION: השם של גרסת המעבד של המודל הנוכחי
PROCESSOR_VERSION: המזהה של המעבד הנוכחי שרוצים לשדרג
curl -X POST -v -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://LOCATION-documentai.googleapis.com/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions:train" \ -d '{ "processor_version": { "display_name": "DISPLAY_NAME" }, "base_processor_version": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/BASE_PROCESSOR_VERSION", "foundation_model_tuning_options": { "train_steps": 10, "learning_rate_multiplier": 1, "previous_fine_tuned_processor_version_name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION", } }'
הצפנה של נתוני אימון
נתוני האימון של Document AI נשמרים ב-Cloud Storage וניתן להצפין אותם באמצעות מפתחות הצפנה בניהול הלקוח אם נדרש.
מחיקת נתוני אימון
אחרי שמשימת אימון של Document AI מסתיימת, כל נתוני האימון שנשמרו ב-Cloud Storage מאבדים תוקף אחרי תקופת שמירה של יומיים. פעולות מחיקה של נתונים שמתבצעות לאחר מכן יתבצעו בהתאם לתהליך שמתואר במאמר מחיקת נתונים ב- Google Cloud.
תמחור
אין עלות לאימון או לאימון מתקדם. אתם משלמים על אירוח ועל חיזוי. מידע נוסף זמין במאמר בנושא תמחור של Document AI.