
האפשרות 'אימון ומיצוי של AI גנרטיבי' מאפשרת לכם:
- שימוש בטכנולוגיית zero-shot ו-few-shot כדי לקבל מודל עם ביצועים גבוהים עם מעט נתוני אימון או ללא נתוני אימון, באמצעות המודל הבסיסי.
- ככל שתספקו יותר נתוני אימון, תוכלו להשתמש בכוונון עדין כדי לשפר עוד יותר את הדיוק.
שיטות לאימון AI גנרטיבי
שיטת האימון שתבחרו תלויה במספר המסמכים שזמינים לכם ובמידת המאמץ שאתם מוכנים להשקיע באימון המודל. יש שלוש דרכים לאמן מודל של AI גנרטיבי:
| שיטת האימון | Zero-shot | כמה דוגמאות | כוונון עדין |
|---|---|---|---|
| דיוק | בינוני | בינוני עד גבוה | גבוהה |
| מאמץ | נמוכה | נמוכה | בינוני |
| מספר מסמכי ההדרכה המומלץ | 0 | 5 עד 10 | 10 עד 50+ |
גרסאות של מודלים של חילוץ מותאם אישית
המודלים הבאים זמינים לכלי לחילוץ בהתאמה אישית. כדי לשנות את גרסאות המודלים, אפשר לעיין במאמר בנושא ניהול גרסאות המעבד.
גרסאות 1.4, 1.5 ו-1.5 Pro תומכות בציוני מהימנות.
| גרסת המודל | תיאור | ערוץ הפצה | עיבוד באמצעות ML בארה"ב או באיחוד האירופי | כוונון עדין בארה"ב ובאיחוד האירופי | תאריך הפצה |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.5-2025-05-05 |
מועמד מוכן לייצור שמבוסס על מודל שפה גדול (LLM) של Gemini 2.5 Flash. מומלץ למי שרוצה להתנסות במודלים חדשים יותר. | יציב | כן | ארה"ב, האיחוד האירופי | 5 במאי 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
מודל מוכן לייצור שמבוסס על Gemini 2.5 Pro LLM. תומך במכסה של עד 30 דפים בדקה לבקשות של תהליכים אונליין. האיכות של המודל הזה גבוהה יותר בהשוואה לגרסה 1.5, ויכול להיות שזמן האחזור שלו ארוך יותר. | יציב | כן | לא | 20 ביוני 2025 |
pretrained-foundation-model-v1.5.1-2025-08-07 |
מודל בגרסת טרום-השקה (Preview) לציבור הרחב שמבוסס על מודל שפה גדול (LLM) של Gemini 2.5 Flash. למודל הזה יש את אותן תכונות כמו לגרסה 1.5, והוא כולל שיפורים בלמידה דינמית עם מעט דוגמאות. | גרסה מועמדת להפצה | כן | לא | 8 באוגוסט 2025 |
pretrained-foundation-model-v1.6-pro-2025-12-01 |
מודל בגרסת טרום-השקה שמבוסס על מודל שפה גדול (LLM) של Gemini 3 Pro. | גרסה מועמדת להפצה | כן | לא | 1 בדצמבר 2025 |
pretrained-foundation-model-v1.6-2026-01-13 |
מודל בגרסת טרום-השקה שמבוסס על Gemini 3 Flash LLM. | גרסה מועמדת להפצה | כן | לא | 13 בינואר 2026 |
כדי לשנות את גרסת המעבד בפרויקט, אפשר לעיין במאמר בנושא ניהול גרסאות של מעבדים.
כדי לשלוח בקשה להגדלת המכסה (QIR) של מכסת ברירת המחדל של המעבד, פועלים לפי השלבים לבקשת שינוי מכסות.
הגדרה ראשונית
אם עדיין לא עשיתם זאת, מפעילים את החיוב ואת ממשקי ה-API של Document AI.
יצירה והערכה של מודל AI גנרטיבי
יוצרים מעבד ומגדירים שדות שרוצים לחלץ לפי השיטות המומלצות. זה חשוב כי זה משפיע על איכות החילוץ.
- עוברים אל מרכז הבקרה > כלי חילוץ בהתאמה אישית > יצירת מעבד > הקצאת שם.
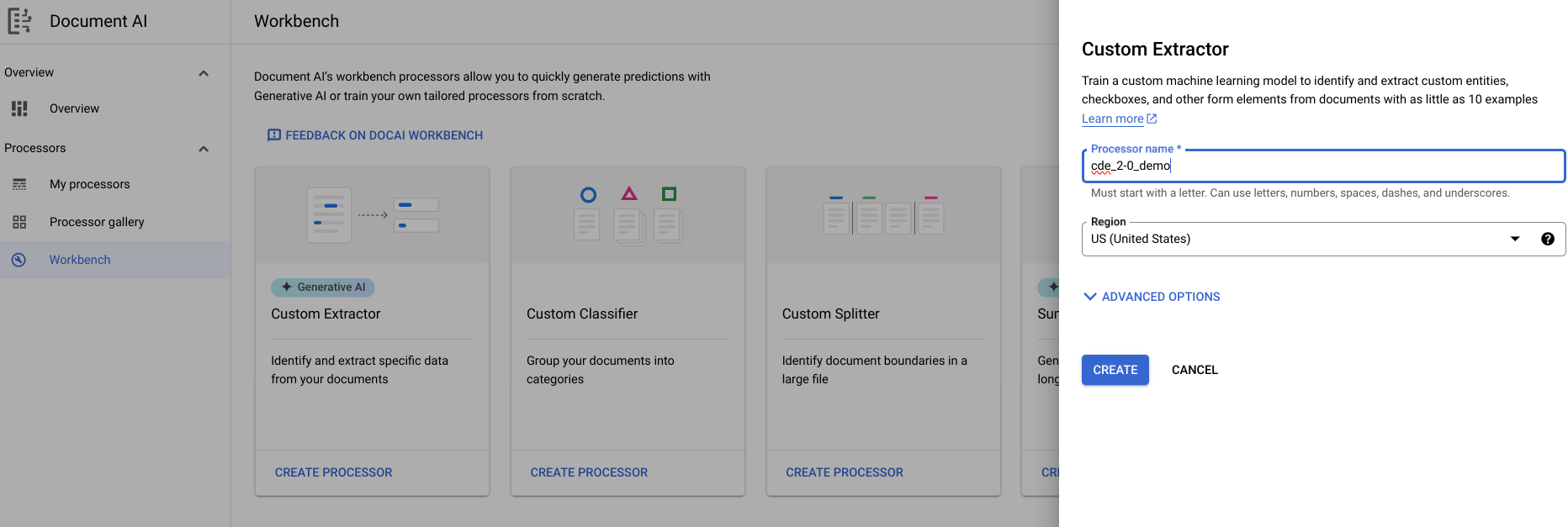
- עוברים אל שנתחיל? > יצירת שדה חדש.
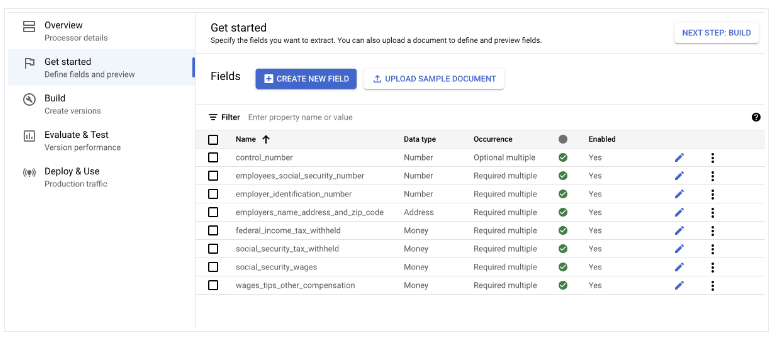
ייבוא מסמכים
- ייבוא מסמכים עם תיוג אוטומטי והקצאת מסמכים לקבוצת האימון ולקבוצת נתונים לבדיקה.
- במקרה של zero-shot, נדרשת רק הסכימה. כדי להעריך את רמת הדיוק של המודל, צריך רק קבוצת בדיקה.
- ללמידה עם מעט דוגמאות, מומלץ להשתמש בחמישה מסמכי אימון.
- מספר מסמכי הבדיקה הנדרשים תלוי בתרחיש לדוגמה. בדרך כלל, ככל שיש יותר מסמכי בדיקה, כך התוצאות טובות יותר.
- בודקים שהתוויות במסמך רשומות באופן הרצוי או עורכים אותן.
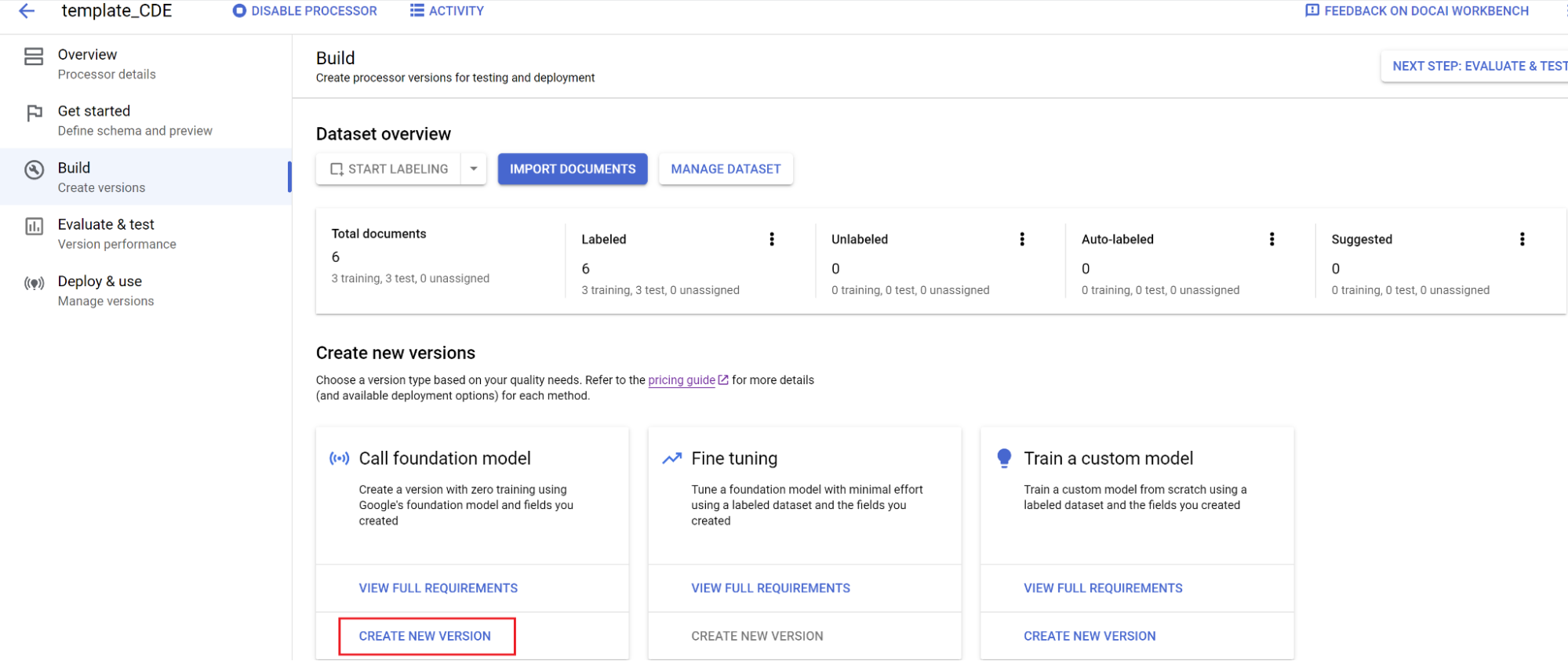
אימון מודל:
- בוחרים באפשרות Build (בנייה) ואז באפשרות Create new version (יצירת גרסה חדשה).
- מזינים שם ולוחצים על יצירה.
הערכה:
- עוברים אל הערכה ובדיקה, בוחרים את הגרסה שאומנה זה עתה ולוחצים על הצגת ההערכה המלאה.
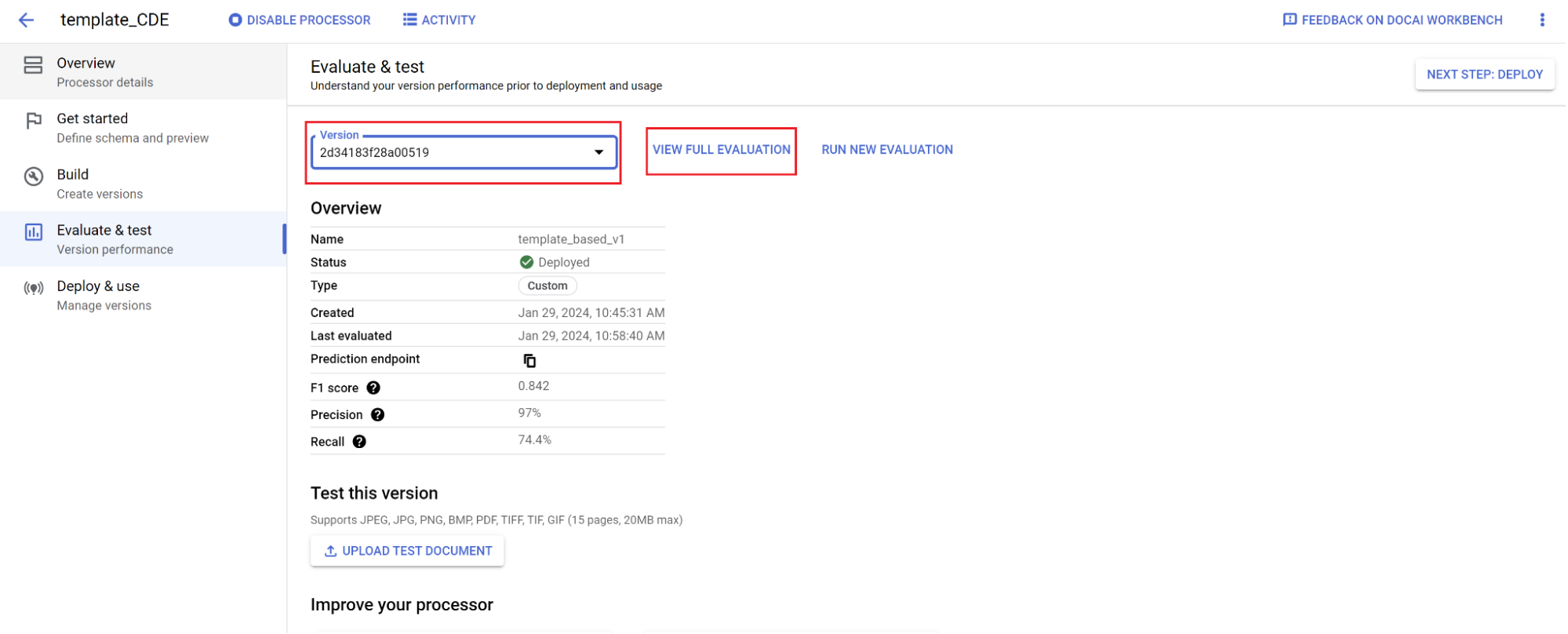
- עכשיו מוצגים מדדים כמו f1, דיוק וזיכרון לכל המסמך ולכל שדה.
- מחליטים אם הביצועים עומדים ביעדי הייצור. אם לא, מעריכים מחדש את קבוצות האימון והבדיקה.
כדי להגדיר גרסה חדשה כברירת מחדל:
- עוברים אל ניהול גרסאות.
- לוחצים על החץ כדי להרחיב את האפשרויות ובוחרים באפשרות הגדרה כברירת מחדל.
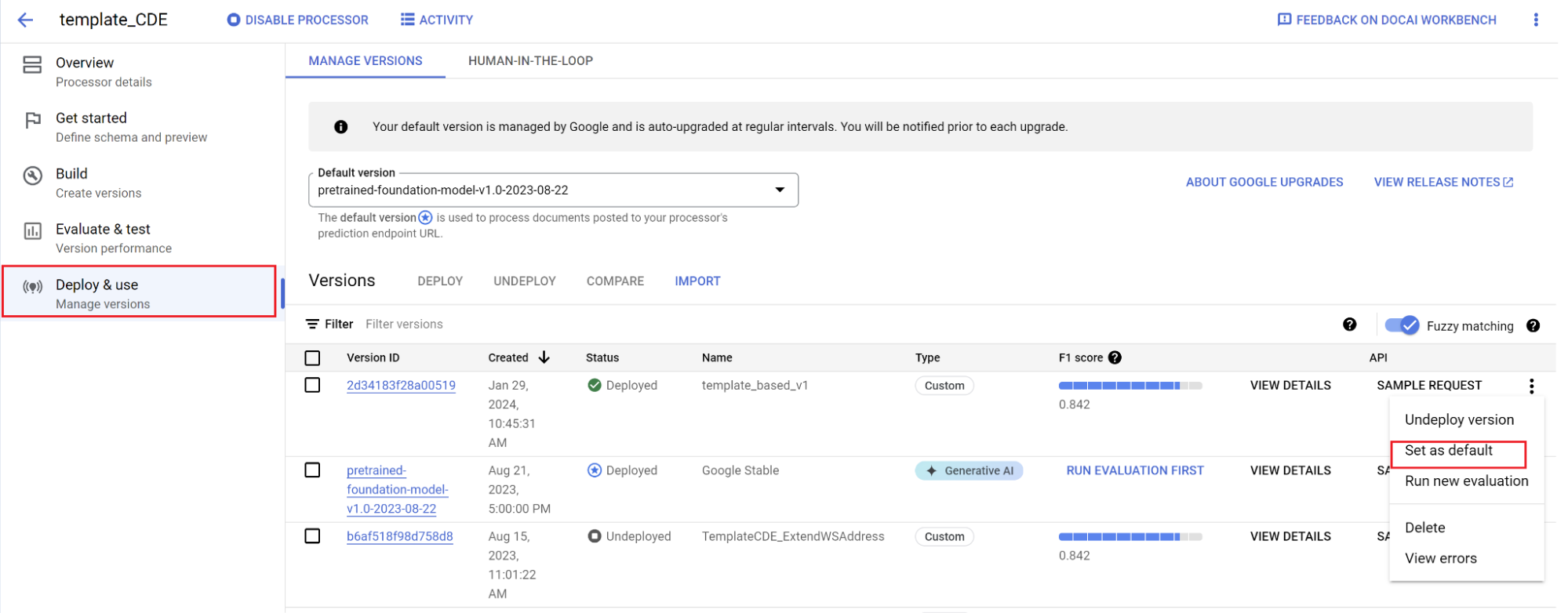
המודל שלך פרוס עכשיו. מסמכים שנשלחים למעבד הזה משתמשים בגרסה המותאמת אישית שלכם. אתם יכולים להעריך את ביצועי המודל כדי לבדוק אם הוא צריך אימון נוסף.
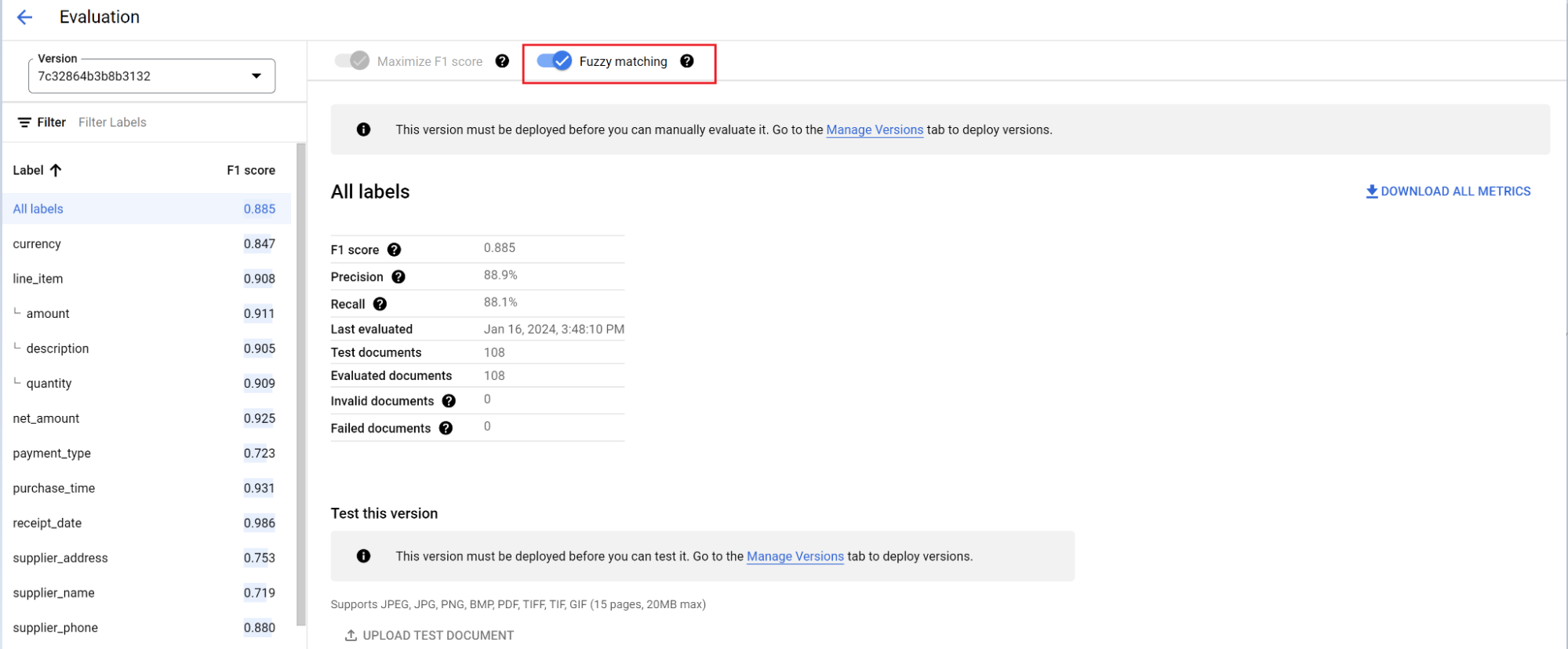
הפניה להערכה
מנוע ההערכה יכול לבצע התאמה מדויקת או התאמה משוערת. כדי שתהיה התאמה מדויקת, הערך שחולץ חייב להיות זהה לערך האמת הבסיסי, אחרת הוא ייחשב כפספוס.
חילוצים של התאמה משוערת עם הבדלים קלים כמו הבדלים באותיות רישיות עדיין נחשבים להתאמה. אפשר לשנות את זה במסך הערכה.
כוונון עדין
בשיטת הכוונון העדין, משתמשים במאות או באלפי מסמכים לאימון.
יוצרים מעבד ומגדירים את השדות שרוצים לחלץ בהתאם לשיטות המומלצות. זה חשוב כי זה משפיע על איכות החילוץ.
ייבוא מסמכים עם תיוג אוטומטי, והקצאת מסמכים למערך האימון ולקבוצת נתונים לבדיקה.
בודקים שהתוויות במסמך רשומות באופן הרצוי או עורכים אותן.
אימון המודל.
- לוחצים על הכרטיסייה Build (יצירה) ואז על Create New Version (יצירת גרסה חדשה) בתיבה Fine-tuning (כוונון עדין).
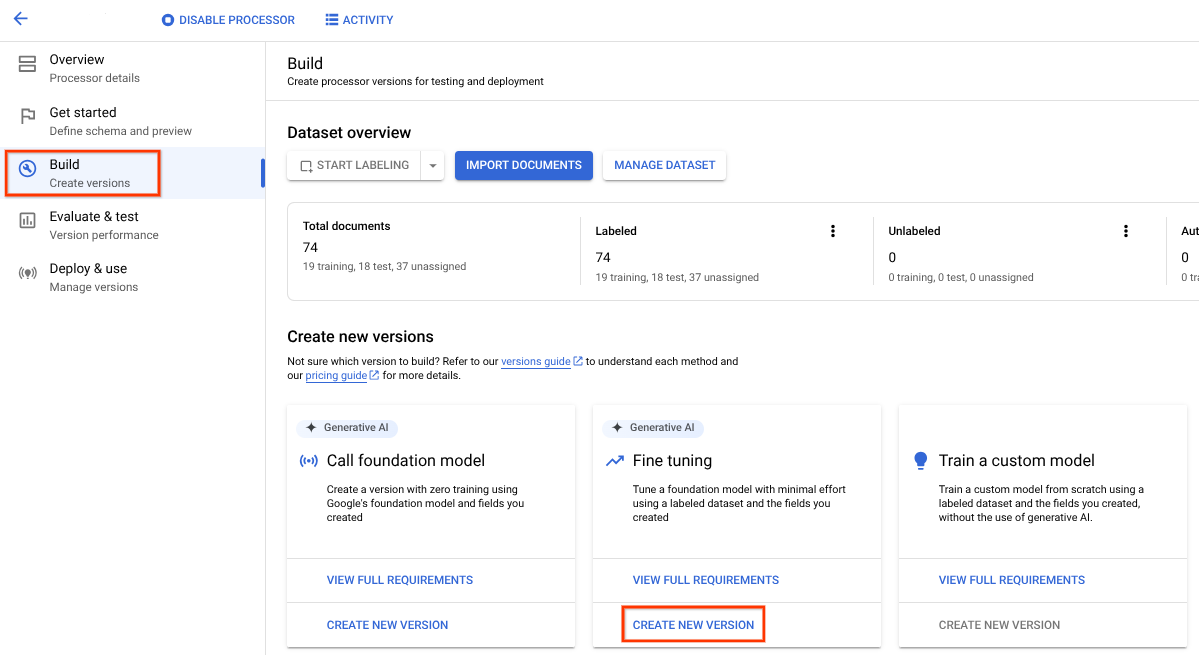
אפשר לנסות את פרמטרי ההדרכה או הערכים שמופיעים כברירת מחדל. אם התוצאות לא מספקות, אפשר לנסות את האפשרויות המתקדמות הבאות:
שלבי ההכשרה (בין 100 ל-400): קובעים את התדירות שבה המשקלים עוברים אופטימיזציה באצווה של נתונים במהלך ההתאמה.
- ערך נמוך מדי מצביע על סיכון שהאימון יסתיים לפני ההתכנסות (התאמה חסרה).
- ערך גבוה מדי מצביע על כך שהמודל עשוי לראות את אותה קבוצת נתונים כמה פעמים במהלך האימון, מה שעלול להוביל להתאמת יתר.
- פחות שלבים מובילים לזמן אימון מהיר יותר. מספרים גבוהים יותר יכולים לעזור במסמכים עם מעט וריאציות בתבנית (ומספרים נמוכים יותר במסמכים עם יותר וריאציות).
מכפיל קצב הלמידה (בין 0.1 ל-10): קובע את מהירות האופטימיזציה של פרמטרים של המודל בנתוני האימון. הוא תואם בערך לגודל של כל שלב אימון.
- שיעורים נמוכים מצביעים על שינויים קטנים במשקלים של המודל בכל שלב אימון. אם הערך נמוך מדי, יכול להיות שהמודל לא יתכנס לפתרון יציב.
- שיעורים גבוהים מצביעים על שינויים גדולים, ושיעורים גבוהים מדי יכולים להצביע על כך שהמודל מדלג על הפתרון האופטימלי ומתכנס במקום זאת לפתרון לא אופטימלי.
- בחירת קצב הלמידה לא משפיעה על זמן האימון.
נותנים שם, בוחרים את הגרסה הנדרשת של מעבד הבסיס ולוחצים על יצירה.
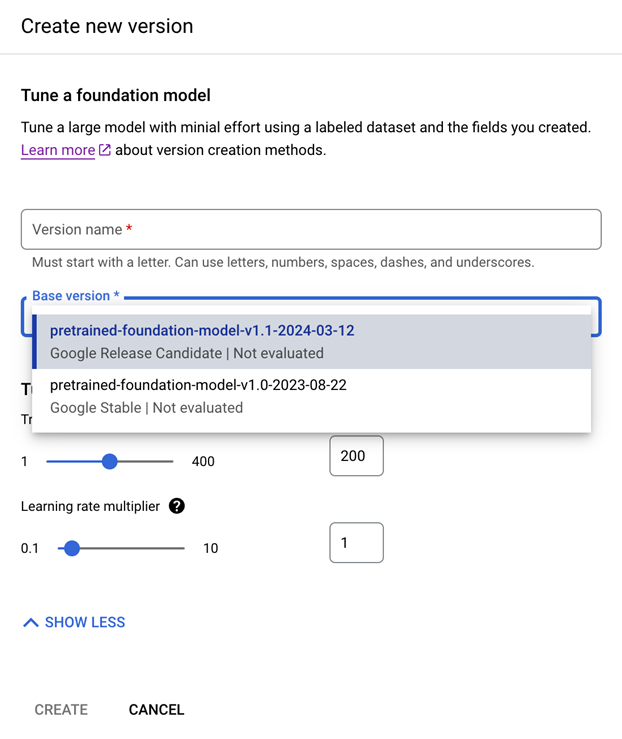
הערכה: עוברים אל הערכה ובדיקה, בוחרים את הגרסה שאומנה זה עתה ולוחצים על הצגת ההערכה המלאה.
- עכשיו מוצגים מדדים כמו f1, דיוק וזיכרון לגבי המסמך כולו וכל שדה.
- בודקים אם הביצועים עומדים ביעדי הייצור. אם לא, יכול להיות שיהיה צורך במסמכי הדרכה נוספים.
כדי להגדיר גרסה חדשה כברירת מחדל:
- עוברים אל ניהול גרסאות.
- לוחצים על האפשרות כדי להרחיב אותה, ואז לוחצים על הגדרה כברירת מחדל.
המודל שלכם נפרס עכשיו, ומסמכים שנשלחים למעבד הזה משתמשים עכשיו בגרסה המותאמת אישית שלכם. אתם רוצים להעריך את ביצועי המודל כדי לבדוק אם הוא צריך אימון נוסף.
סימון אוטומטי בתוויות באמצעות מודל בסיס
מודל הבסיס יכול לחלץ שדות בצורה מדויקת ממגוון סוגי מסמכים, אבל אפשר גם לספק נתוני אימון נוספים כדי לשפר את הדיוק של המודל עבור מבני מסמכים ספציפיים.
Document AI משתמש בשמות התוויות שאתם מגדירים ובאנוטציות קודמות כדי לתייג מסמכים בקלות ובמהירות באמצעות תיוג אוטומטי.
- אחרי שיוצרים מעבד בהתאמה אישית, עוברים לכרטיסייה Get Started (תחילת העבודה).
- בוחרים באפשרות יצירת שדה חדש.
נותנים לתווית שם תיאורי וייחודי. בוחרים באפשרות שליפה כדי לשלוף ערכים ישירות מהמסמך, או באפשרות הסקה כדי שהמערכת תסיק את הערכים. כך משפרים את הדיוק והביצועים של מודל הבסיס.
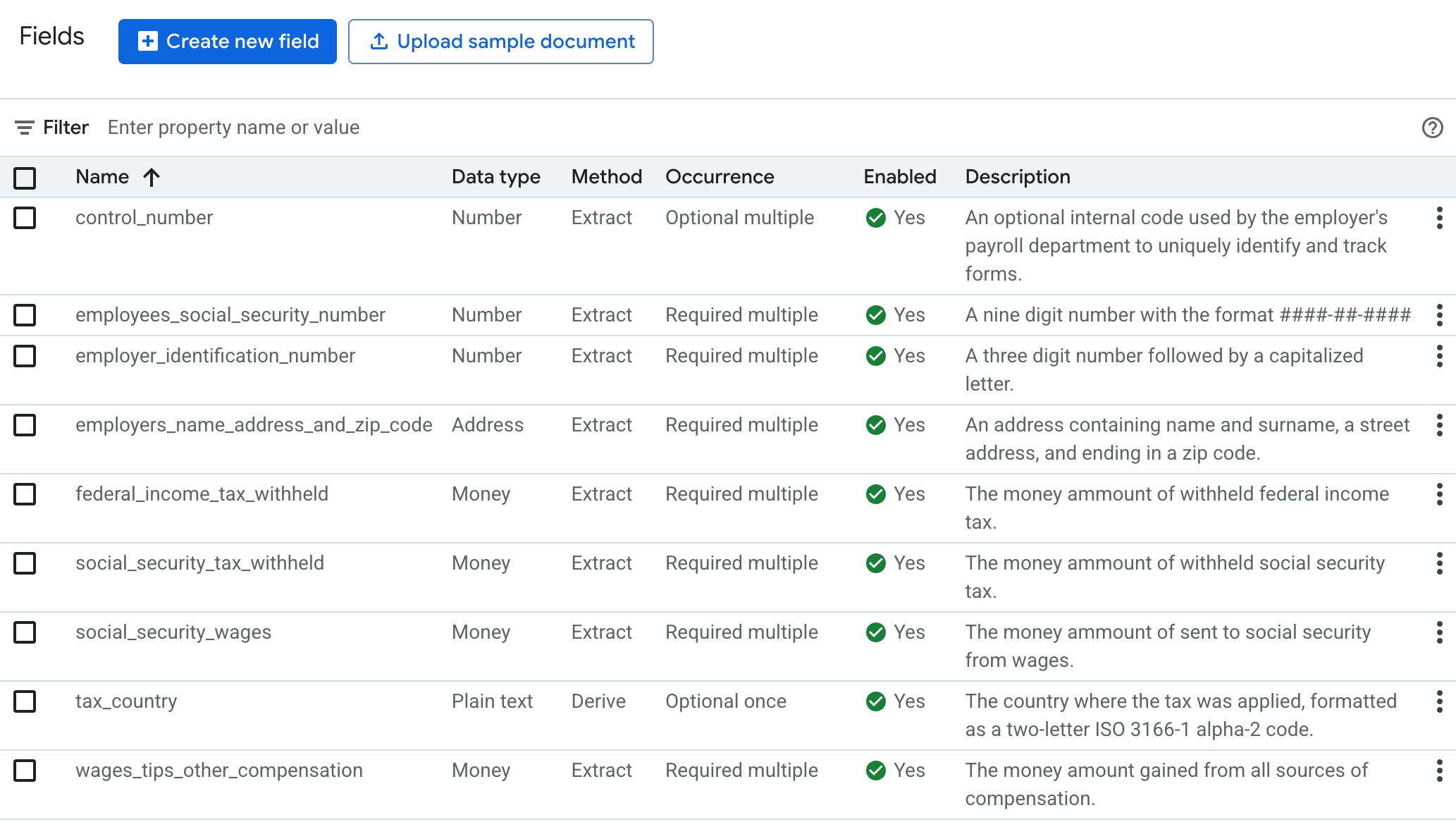
כדי לשפר את הדיוק והביצועים של החילוץ, מוסיפים תיאור (למשל הקשר, תובנות וידע קודם לגבי כל ישות) לסוגי הישויות שהמודל צריך לזהות.
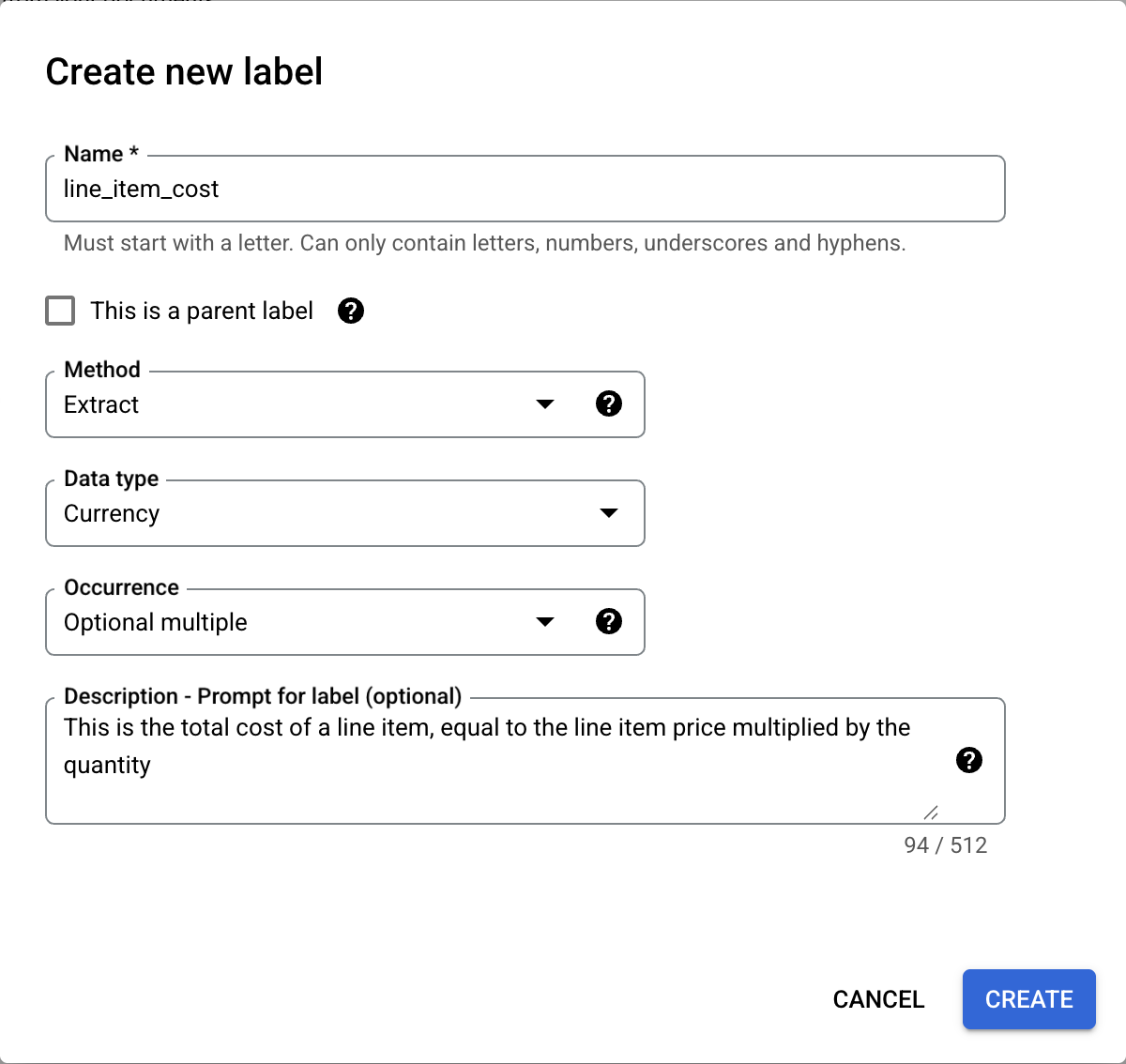
עוברים לכרטיסייה Build (בנייה) ובוחרים באפשרות Import Documents (ייבוא מסמכים).
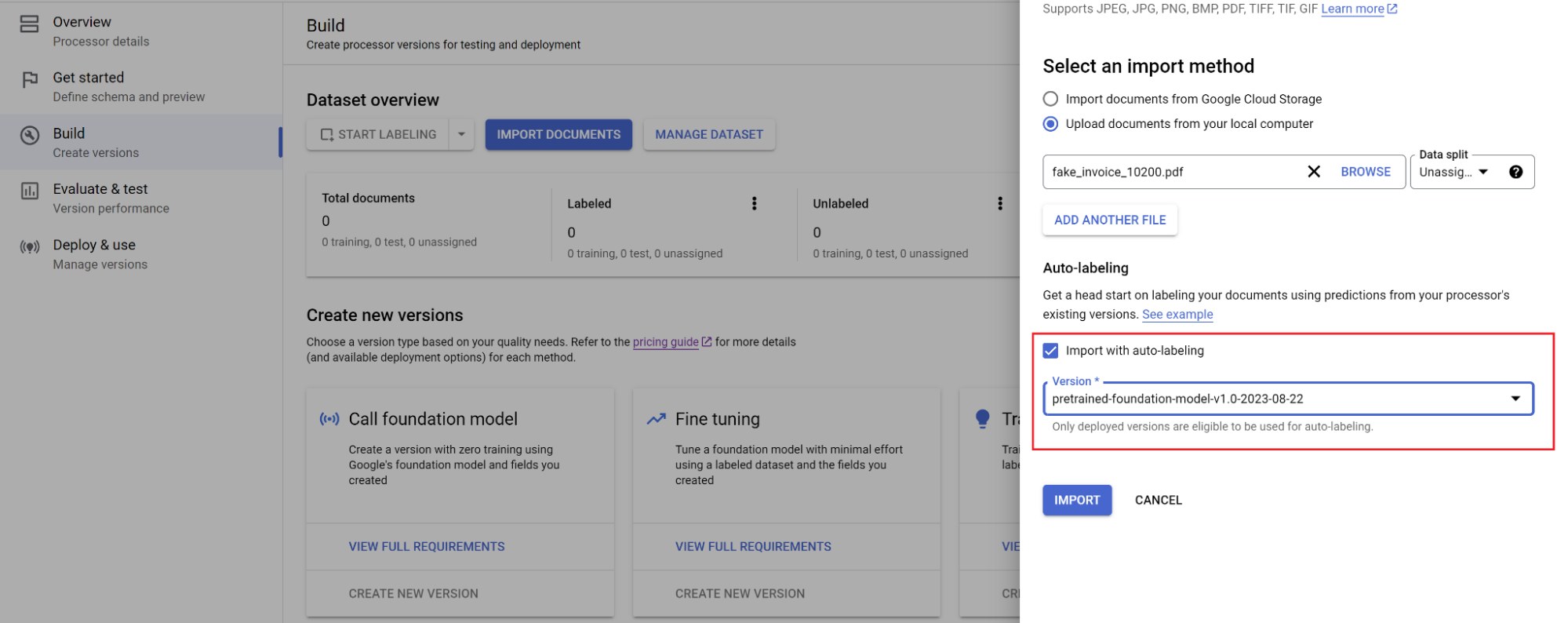
בוחרים את הנתיב של המסמכים ואת הקבוצה שאליה רוצים לייבא את המסמכים. מסמנים את האפשרות של תיוג אוטומטי ובוחרים את מודל הבסיס.
בכרטיסייה יצירה, בוחרים באפשרות ניהול קבוצת נתונים.
כשרואים את המסמכים המיובאים, בוחרים אחד מהם.
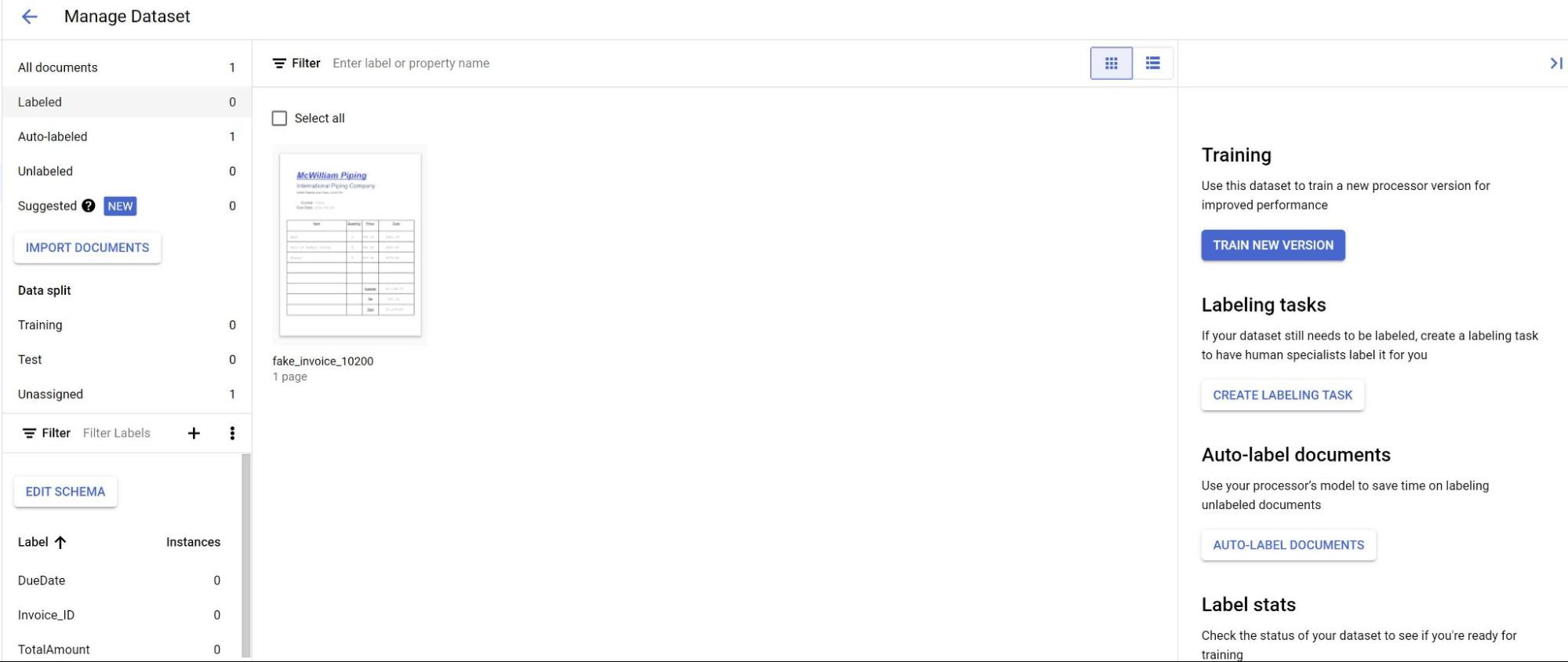
החיזויים מהמודל מוצגים עכשיו בהדגשה סגולה.
- בודקים כל תווית שהמודל חוזה ומוודאים שהיא נכונה.
אם יש שדות חסרים, מוסיפים גם אותם.
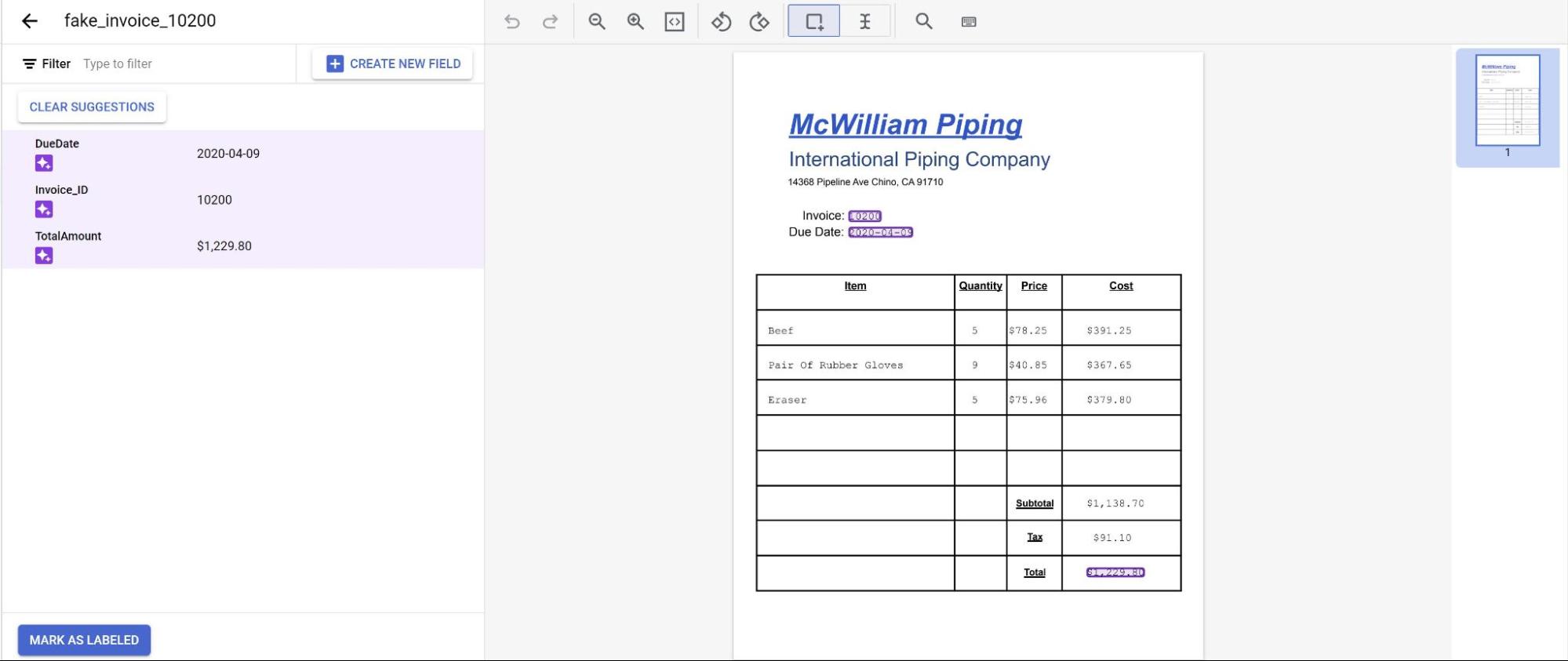
אחרי שבודקים את המסמך, לוחצים על סימון כפריט שסומן בתווית. המסמך מוכן עכשיו לשימוש על ידי המודל.
מוודאים שהמסמך נמצא בקבוצת הבדיקה או בקבוצת נתונים לאימון.
שלוש רמות של סידור פנימי
הכלי 'חילוץ מותאם אישית' תומך עכשיו בשלוש רמות של סידור פנימי. התכונה הזו מאפשרת חילוץ טוב יותר של טבלאות מורכבות.
אפשר לקבוע את סוג המודל באמצעות קריאות ה-API הבאות:
התשובה של הפעולות האלה היא ProcessorVersion, שמכילה את השדה modelType בגרסת v1beta3 לתצוגה מקדימה.
התהליך ודוגמה
אנחנו משתמשים בדוגמה הזו:
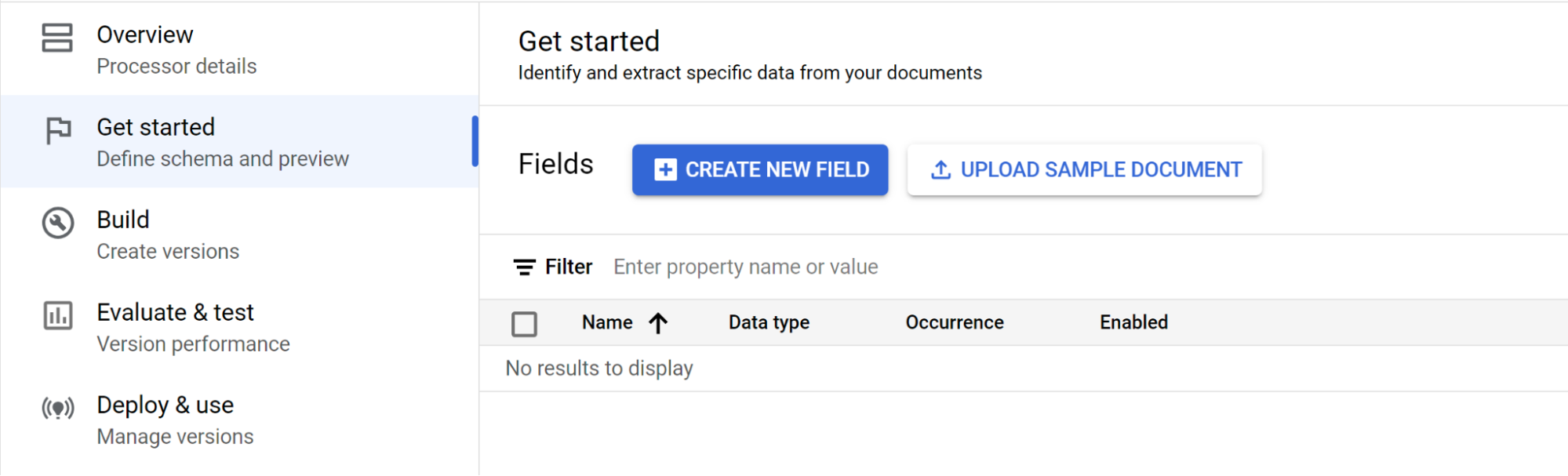
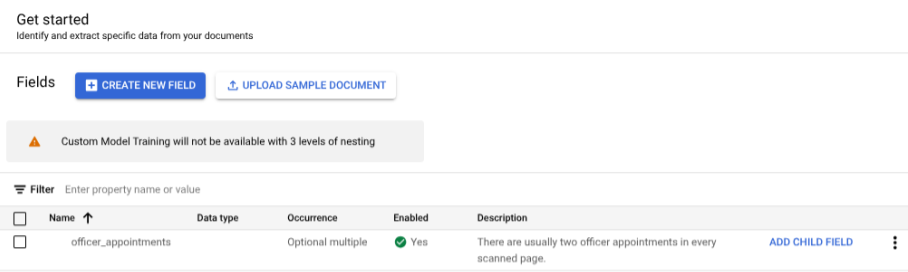
לוחצים על Get Started (תחילת העבודה) ויוצרים שדה:
- יוצרים את הרמה העליונה.
- בדוגמה הזו נעשה שימוש ב-
officer_appointments. - בוחרים באפשרות זוהי תווית הורה.
- בוחרים באפשרות מופע:
Optional multiple.
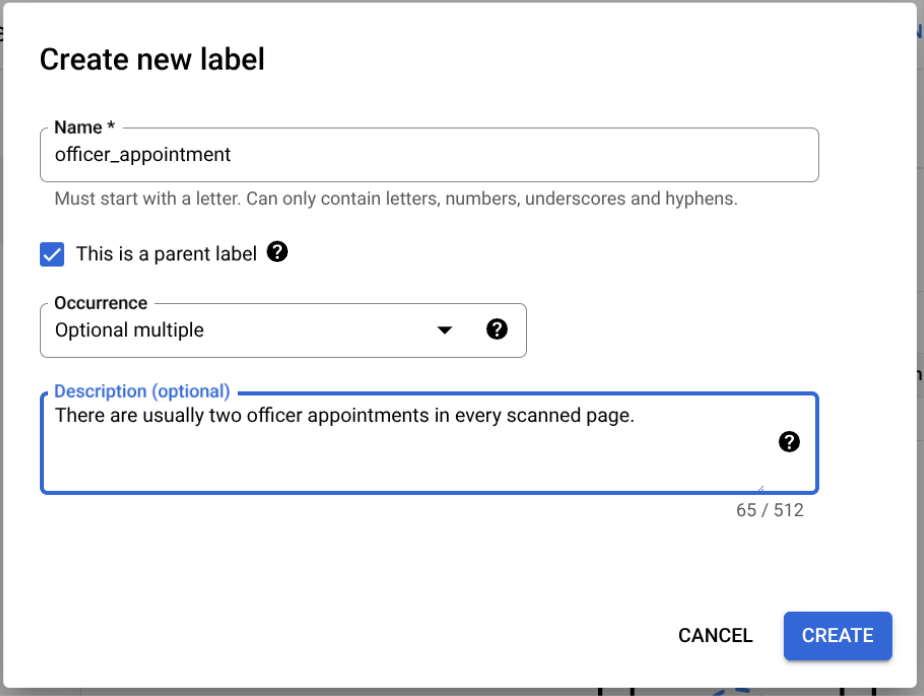
לוחצים על הוספת שדה צאצא. עכשיו אפשר ליצור את התווית ברמה השנייה:
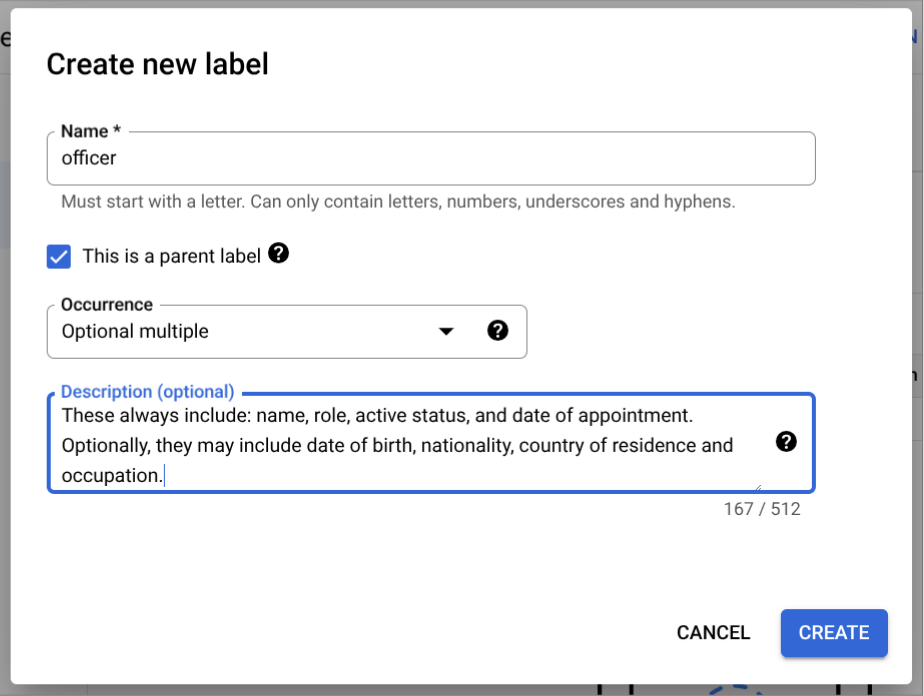
- יוצרים
officerלתווית הרמה הזו. - בוחרים באפשרות זוהי תווית הורה.
- בוחרים באפשרות מופע:
Optional multiple.
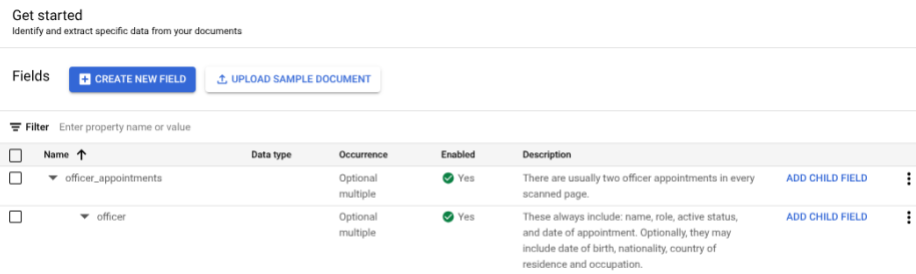
- יוצרים
בוחרים באפשרות הוספת שדה צאצא מהרמה השנייה
officer. יוצרים תוויות צאצא לרמה השלישית של הקינון.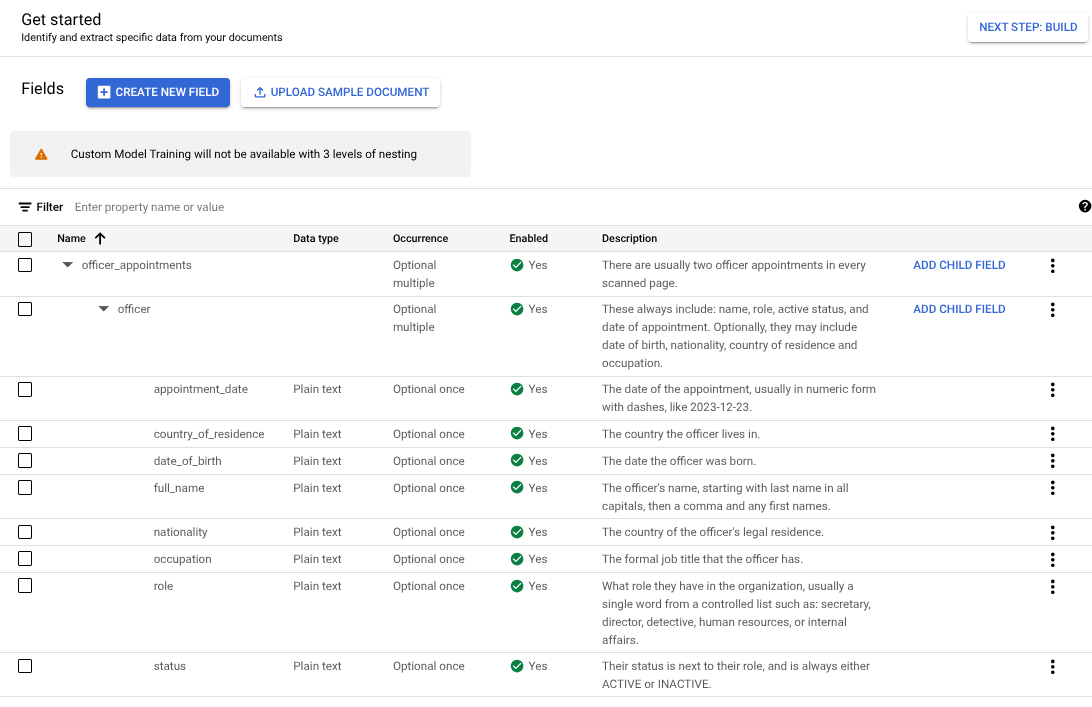
אחרי שמגדירים את הסכימה, אפשר לקבל חיזויים ממסמכים עם שלוש רמות של קינון באמצעות תיוג אוטומטי.
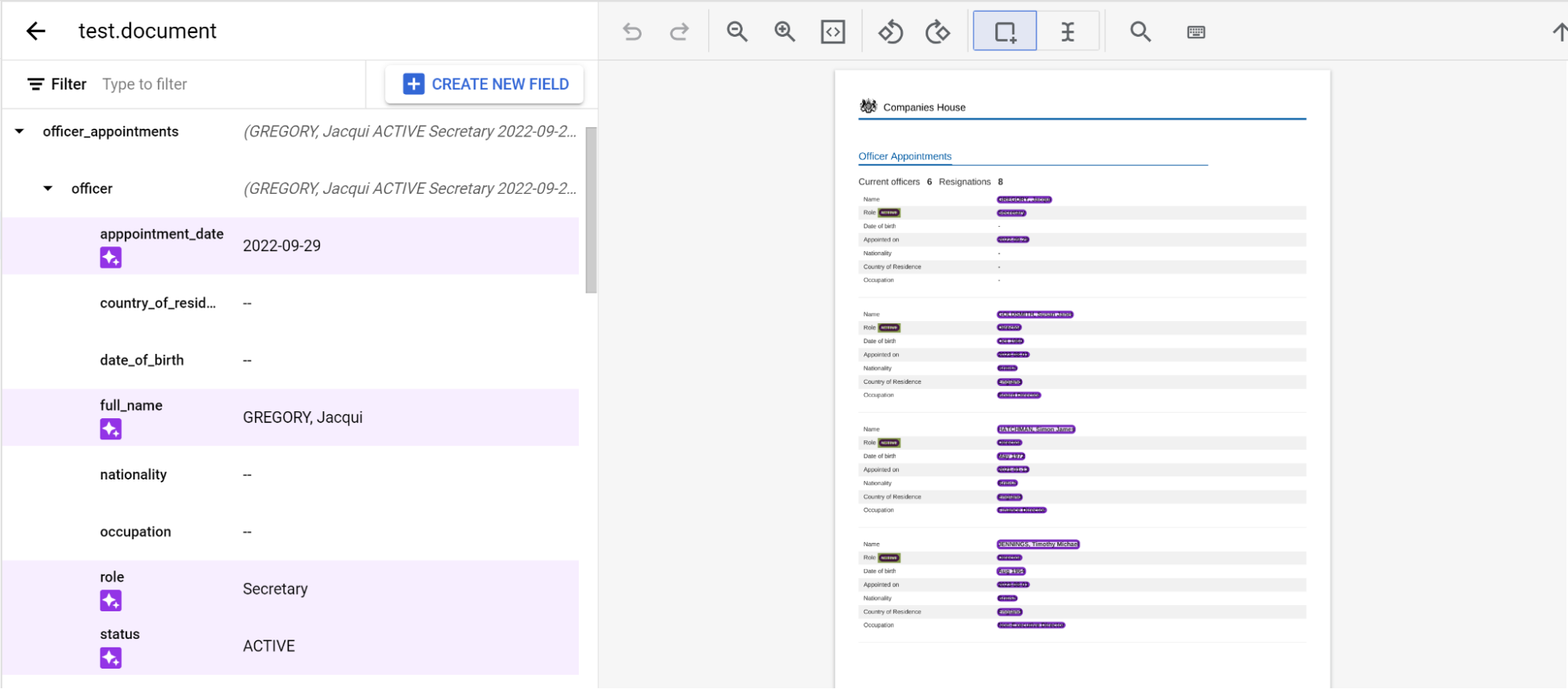
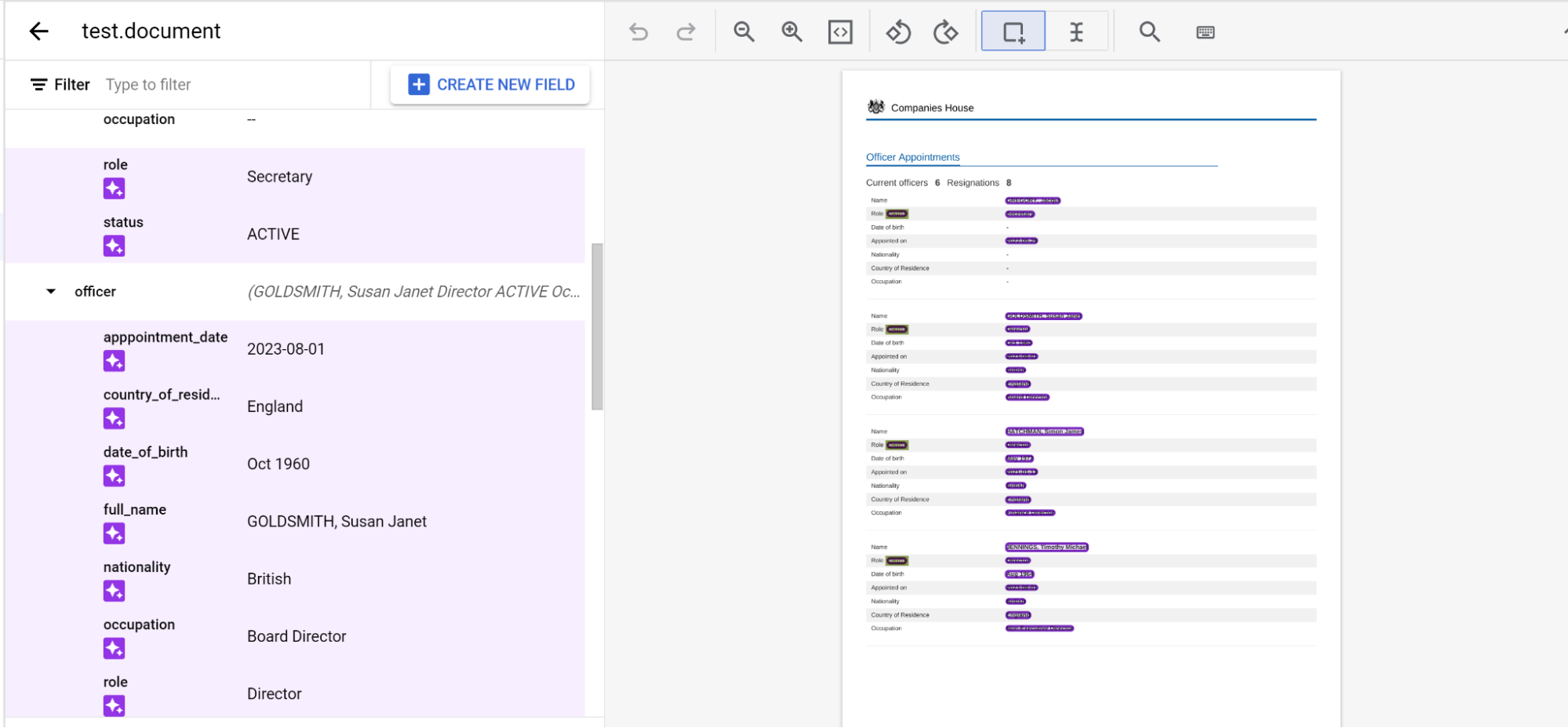
תיוג ישויות מוטמעות בכמה דפים
מעבד pretrained-foundation-model-v1.5-2025-05-05 תומך בסידור פנימי של שלוש רמות בדפים.
מתייגים ישות כרגיל בדף. הערה: הישות עם התווית תהיה גלויה רק בדף שבו היא קיבלה את התווית, וסרגל הניווט ישתנה מדף לדף. אם מצמידים את ישות האם, סרגל הניווט הזה נשאר.
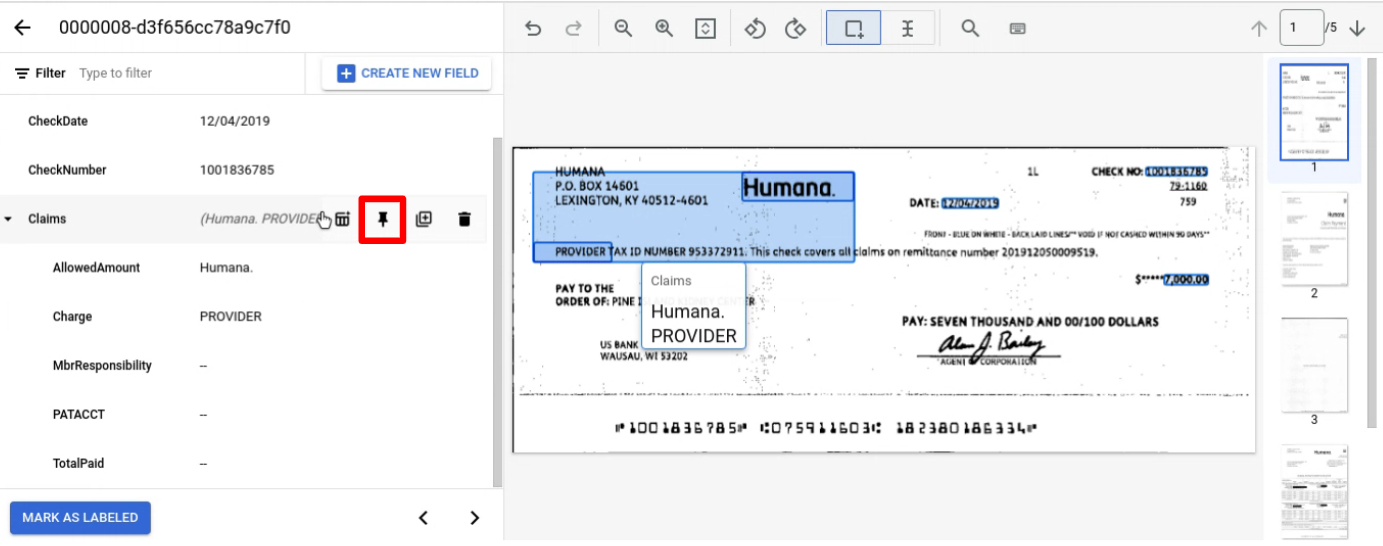
כדי להוסיף תווית לכל הדפים, מצמידים את ישות האם עם ישויות הצאצא שרוצים להוסיף להן תווית.
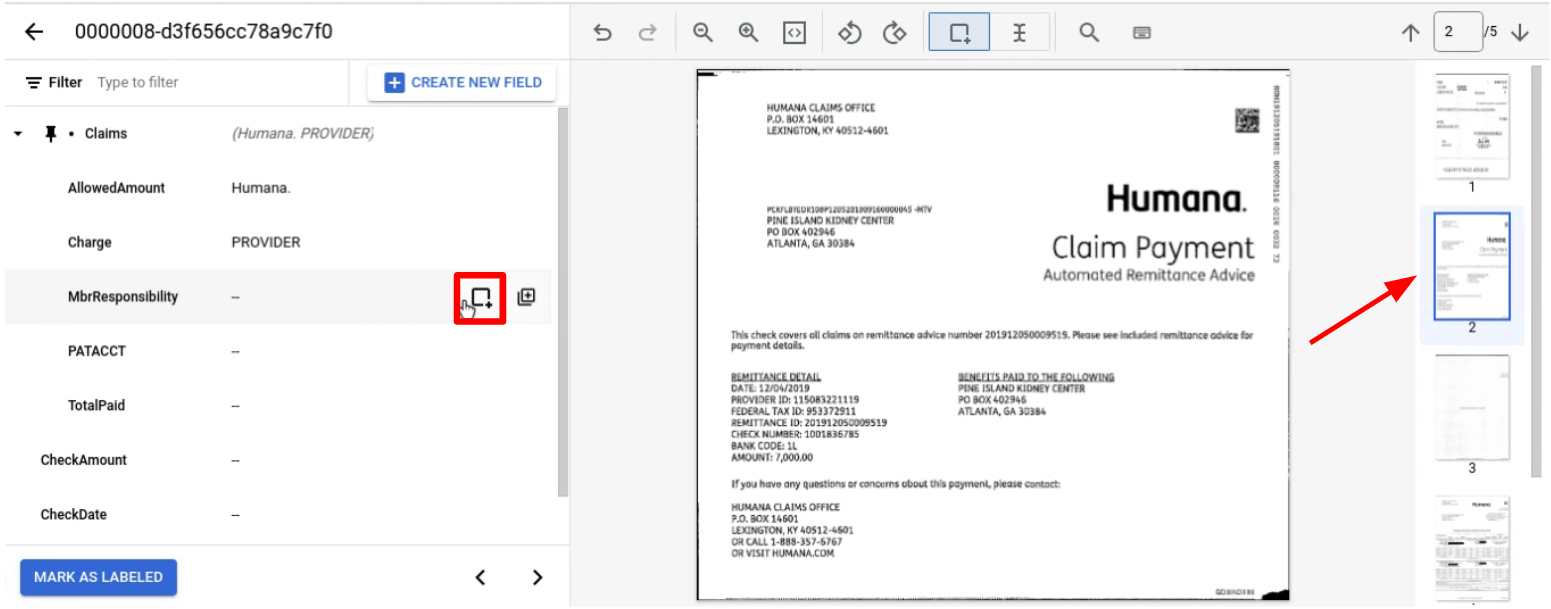
עוברים לדף עם הישות או הישויות המשניות שרוצים להוסיף להן תווית.
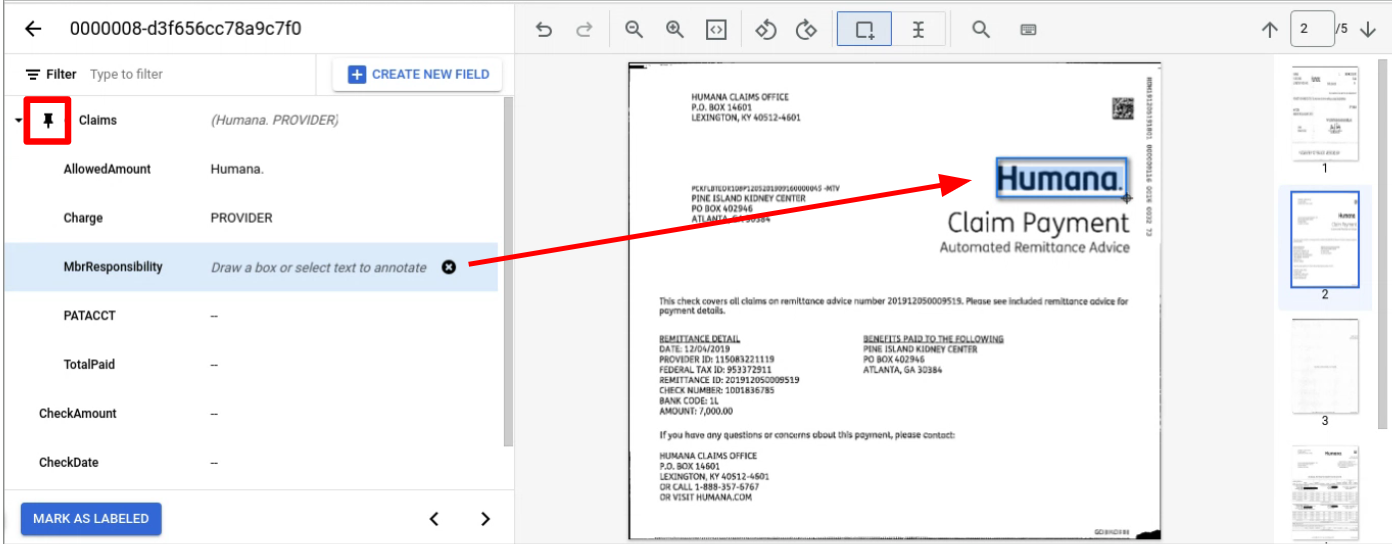
הגדרת מערך נתונים
כדי לאמן גרסה של מעבד, לאמן אותה מחדש או להעריך אותה, צריך מערך נתונים של מסמכים. מעבדים של Document AI לומדים מדוגמאות, בדיוק כמו בני אדם. מערך הנתונים תורם ליציבות המעבד מבחינת הביצועים.קבוצת נתונים לאימון
כדי לשפר את המודל ואת רמת הדיוק שלו, מאמנים מערך נתונים על המסמכים שלכם. המודל מורכב ממסמכים עם נתוני אמת.- כדי לבצע התאמה עדינה של מודל חדש בגרסה
pretrained-foundation-model-v1.5-2025-05-05, צריך לפחות 50 מסמכי אימון ו-50 מסמכי בדיקה. - ללמידה עם מעט דוגמאות, מומלץ להשתמש בחמישה מסמכים.
- במקרה של סיווג ללא דוגמאות, נדרשת רק סכימה.
מערך נתונים לבדיקה
קבוצת הנתונים של הבדיקה היא מה שהמודל משתמש בו כדי ליצור ציון F1 (דיוק). הוא מורכב ממסמכים עם נתוני אמת. כדי לראות כמה פעמים המודל צדק, נעשה שימוש בנתוני האמת כדי להשוות בין התחזיות של המודל (שדות שחולצו מהמודל) לבין התשובות הנכונות. מערך נתוני הבדיקה צריך לכלול לפחות 50 מסמכים עבורpretrained-foundation-model-v1.5-2025-05-05.
חילוץ מותאם אישית עם תיאורי מאפיינים
בעזרת תיאורי נכסים, אפשר לאמן מודל על ידי תיאור של השדות המסומנים. אתם יכולים לספק הקשר ותובנות נוספים לגבי כל ישות. כך המודל יכול להתאמן על ידי התאמת שדות שמתאימים לתיאור שסיפקתם, ולשפר את הדיוק של החילוץ. אפשר לציין תיאורי מאפיינים גם לישויות ראשיות וגם לישויות משניות.
דוגמאות טובות לתיאורי מאפיינים כוללות מידע על מיקום ודפוסי טקסט של ערכי המאפיינים, שעוזרים להבחין בין מקורות פוטנציאליים לבלבול במסמך. תיאורים ברורים ומדויקים של המאפיינים מנחים את המודל באמצעות כללים שמקדמים חילוצים מהימנים ועקביים יותר, ללא קשר למבנה המסמך הספציפי או לשינויים בתוכן.
עדכון סכימת המסמך למעבד
הוראות להגדרת תיאורי המאפיינים מופיעות במאמר עדכון סכימת המסמך.
שליחת בקשת עיבוד עם תיאורי נכסים
אם כבר הוגדרו תיאורים בסכימת המסמך, אפשר לשלוח בקשת עיבוד עם ההוראות שמפורטות במאמר שליחת בקשת עיבוד.
שיפור המעבד באמצעות תיאורי נכסים
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- LOCATION: המיקום של המעבד, לדוגמה:
us– ארצות הבריתeu- האיחוד האירופי
- PROJECT_ID: מזהה הפרויקט ב- Google Cloud .
- PROCESSOR_ID: המזהה של המעבד בהתאמה אישית.
- DISPLAY_NAME: השם המוצג של המעבד.
- PRETRAINED_PROCESSOR_VERSION: מזהה גרסת המעבד. מידע נוסף זמין במאמר בנושא בחירת גרסת מעבד. לדוגמה:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: שלבי אימון לשיפור המודל.
- LEARN_RATE_MULTIPLIER: מכפיל קצב הלמידה לצורך כוונון עדין של המודל.
- DOCUMENT_SCHEMA: סכימה של המעבד. מידע נוסף מופיע במאמר בנושא ייצוג של DocumentSchema.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
גוף בקשת JSON:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
כדי לשלוח את הבקשה עליכם לבחור אחת מהאפשרויות הבאות:
curl
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
חילוץ מותאם אישית עם זיהוי חתימות
(גרסת Preview ציבורית) חילוץ מותאם אישית תומך בזיהוי חתימות. התכונה הזו מאפשרת לכם לזהות את קיומם של חתימות במסמכים. אפשר לזהות חתימות רק באמצעות סוג ה-method derived. אפשר לציין סכימה עם סוג הישות signature
עבור ישויות כאלה. הישויות של החתימה נגזרות באמצעות רמזים ויזואליים מהמסמך.
לדוגמאות ולהוראות הגדרה, לוחצים על Custom extractor with derived field and signature detection (כלי חילוץ מותאם אישית עם שדה נגזר וזיהוי חתימה).
חילוץ מותאם אישית עם שדות נגזרים
הכלי לחילוץ מותאם אישית תומך בשדות נגזרים. הוא מאפשר לכם להגדיר שדה שיאוכלס באמצעות הסקה או יצירה חכמה על סמך ההקשר של המסמך, במקום חילוץ טקסט ישיר. אפשר להשתמש בזה בתרחישי שימוש כמו הסקת המדינה מכתובת, סיכום מסמך, ספירת פריטים בטבלה או זיהוי אם מזהה הוא אותנטי, בלי שהערך יופיע במפורש בטקסט.
לדוגמאות ולהוראות הגדרה, לוחצים על Custom extractor with derived field and signature detection (כלי חילוץ מותאם אישית עם שדה נגזר וזיהוי חתימה).
המאמרים הבאים
מידע נוסף על כלי חילוץ מותאם אישית עם שדה נגזר וזיהוי חתימה