
Document AI יוצר מדדי הערכה, כמו דיוק וזיכרון, כדי לעזור לכם לקבוע את ביצועי החיזוי של המעבדים.
מדדי ההערכה האלה נוצרים על ידי השוואה בין הישויות שמוחזרות על ידי המעבד (התחזיות) לבין ההערות במסמכי הבדיקה. אם למעבד שלכם אין קבוצת נתונים לבדיקה, אתם צריכים קודם ליצור קבוצת נתונים ולהוסיף תוויות למסמכי הבדיקה.
הרצת הערכה
הערכה מופעלת באופן אוטומטי בכל פעם שמבצעים אימון או המשך אימון של גרסת מעבד.
אפשר גם להפעיל הערכה באופן ידני. הפעולה הזו נדרשת כדי ליצור מדדים מעודכנים אחרי ששיניתם את קבוצת הנתונים לבדיקה, או אם אתם מעריכים גרסה של מעבד שאומן מראש.
ממשק משתמש באינטרנט
נכנסים לדף Processors במסוף Google Cloud ובוחרים את המעבד.
בכרטיסייה Evaluate & Test (הערכה ובדיקה), בוחרים את הגרסה של המעבד שרוצים להעריך ולוחצים על Run new evaluation (הפעלת הערכה חדשה).
אחרי שהתהליך יסתיים, בדף יוצגו מדדי הערכה לכל התוויות ולכל תווית בנפרד.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
קבלת תוצאות של הערכה
ממשק משתמש באינטרנט
נכנסים לדף Processors במסוף Google Cloud ובוחרים את המעבד.
בכרטיסייה הערכה ובדיקה, בוחרים את הגרסה של המעבד כדי לראות את ההערכה.
אחרי שהתהליך יסתיים, בדף יוצגו מדדי הערכה לכל התוויות ולכל תווית בנפרד.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
הצגת רשימה של כל ההערכות של גרסת מעבד
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
מדדי הערכה לכל התוויות
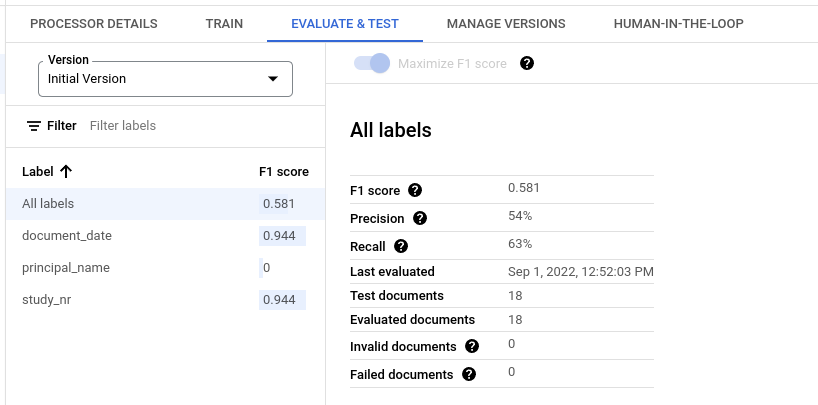
המדדים של כל התוויות מחושבים על סמך מספר התוצאות החיוביות האמיתיות, התוצאות החיוביות השגויות והתוצאות השליליות השגויות במערך הנתונים בכל התוויות. לכן, הם משוקללים לפי מספר הפעמים שכל תוויות מופיעה במערך הנתונים. הגדרות של המונחים האלה מופיעות במאמר מדדי הערכה של תוויות ספציפיות.
דיוק: שיעור החיזויים שתואמים להערות בקבוצת נתונים לבדיקה. מוגדר כ-
True Positives / (True Positives + False Positives)Recall: the proportion of annotations in the test set that are correctly predicted. מוגדר כ-
True Positives / (True Positives + False Negatives)ציון F1: הממוצע ההרמוני של הדיוק וההחזרה, שמשלב בין הדיוק וההחזרה למדד יחיד, ונותן משקל שווה לשניהם. מוגדר כ-
2 * (Precision * Recall) / (Precision + Recall)
מדדי הערכה של תוויות ספציפיות
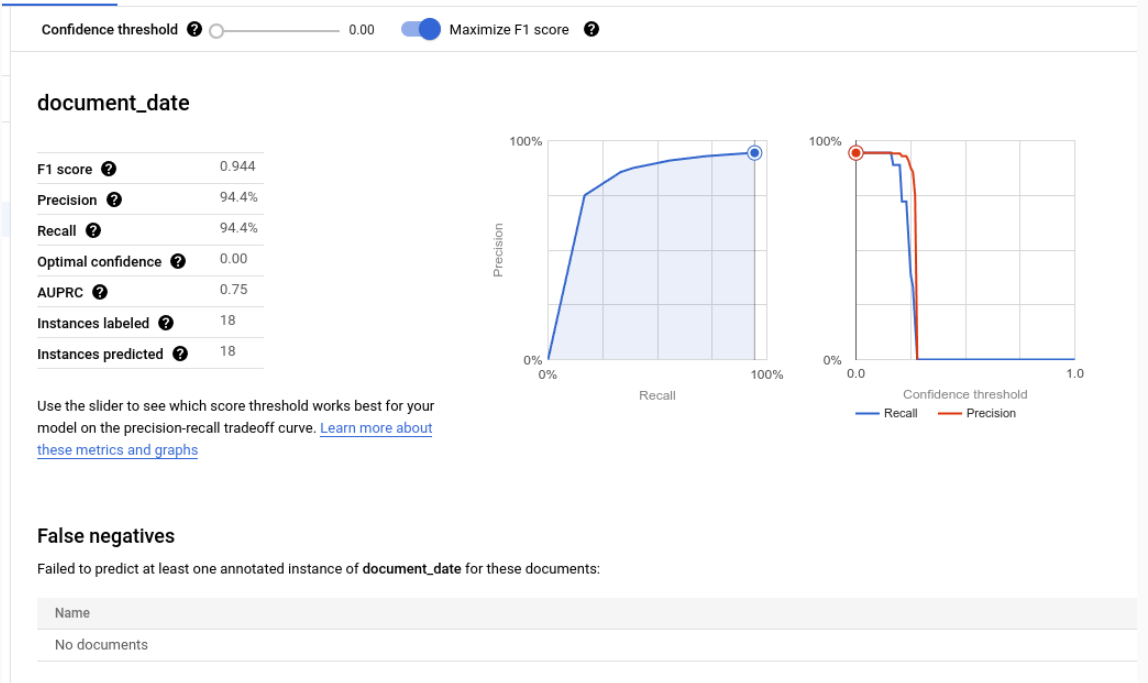
חיוביים אמיתיים: הישויות החזויות שתואמות להערה במסמך הבדיקה. מידע נוסף זמין במאמר בנושא התנהגות ההתאמה.
חיוביים כוזבים: ישויות שחזיתם שלא תואמות לאף הערה במסמך הבדיקה.
שלילי כוזב: ההערות במסמך הבדיקה שלא תואמות לאף אחת מהישויות שחזיתם.
- False Negatives (Below Threshold): the annotations in the test document that would have matched a predicted entity, but the predicted entity's confidence value is below the specified confidence threshold.
סף ביטחון
לוגיקת ההערכה מתעלמת מכל החיזויים עם רמת סמך מתחת לסף המהימנות שצוין, גם אם החיזוי נכון. Document AI מספק רשימה של False Negatives (Below Threshold), שהן ההערות שהיו מתאימות אם סף הסמך היה מוגדר נמוך יותר.
Document AI מחשב באופן אוטומטי את הסף האופטימלי שממקסם את ציון F1, וכברירת מחדל, מגדיר את סף הוודאות לערך האופטימלי הזה.
אתם יכולים לבחור את סף רמת הסמך הרצוי על ידי הזזת פס ההזזה. באופן כללי, סף מהימנות גבוה יותר מוביל ל:
- דיוק גבוה יותר, כי יש סיכוי גבוה יותר שהתחזיות יהיו נכונות.
- שיעור היזכרות נמוך יותר, כי יש פחות תחזיות.
ישויות טבלאיות
המדדים של תווית אב לא מחושבים על ידי ממוצע ישיר של מדדי הצאצא, אלא על ידי החלת סף מהימנות האב על כל תוויות הצאצא שלו וצבירת התוצאות.
הסף האופטימלי לרכיב ההורה הוא ערך הסף של רמת הוודאות, שאם הוא מוחל על כל רכיבי הצאצא, מתקבל ציון F1 מקסימלי לרכיב ההורה.
התנהגות ההתאמה
ישות חזויה תואמת להערה אם:
- סוג הישות החזוי (
entity.type) תואם לשם התווית של ההערה - הערך של הישות החזויה (
entity.mention_textאוentity.normalized_value.text) תואם לערך הטקסט של ההערה, בכפוף להתאמה משוערת אם היא מופעלת.
שימו לב: המערכת משתמשת רק בסוג ובערך הטקסט כדי למצוא התאמה. לא נעשה שימוש במידע אחר, כמו עוגני טקסט ותיבות תוחמות (למעט ישויות טבלאיות שמתוארות בהמשך).
תוויות עם מופע יחיד לעומת תוויות עם מופעים מרובים
לתוויות שמופיעות פעם אחת יש ערך אחד לכל מסמך (לדוגמה, מזהה חשבונית), גם אם הערך הזה מופיע כמה פעמים באותו מסמך (לדוגמה, מזהה החשבונית מופיע בכל דף באותו מסמך). גם אם הטקסט של כמה הערות שונה, הן נחשבות שוות. במילים אחרות, אם יש התאמה בין ישות חזויה לבין אחת מההערות, היא נחשבת להתאמה. ההערות הנוספות נחשבות להזכרות כפולות ולא נכללות בספירה של אף אחת מהקטגוריות: חיובי אמיתי, חיובי שגוי או שלילי שגוי.
תוויות עם כמה מופעים יכולות לקבל כמה ערכים שונים. לכן, כל ישות ותיוג חזויים נלקחים בחשבון ומוצמדים בנפרד. אם מסמך מכיל N הערות לתווית עם כמה מופעים, יכולות להיות N התאמות עם הישויות החזויות. כל ישות ותיוג חזויים נספרים בנפרד כחיובי אמיתי, חיובי שגוי או שלילי שגוי.
התאמה חלקית
המתג התאמה משוערת מאפשר להחמיר או להקל על חלק מכללי ההתאמה כדי להקטין או להגדיל את מספר ההתאמות.
לדוגמה, בלי התאמה משוערת, המחרוזת ABC לא תואמת למחרוזת abc בגלל השימוש באותיות רישיות. אבל עם התאמה חלקית, הם מתאימים.
כשמפעילים התאמה משוערת, אלה השינויים בכללים:
נרמול רווחים לבנים: מסיר רווחים לבנים בתחילת הטקסט או בסופו, ומכווץ רווחים לבנים רצופים באמצע הטקסט (כולל מעברי שורה) לרווחים בודדים.
הסרת סימני פיסוק בתחילת הטקסט או בסופו: מסירה את התווים הבאים של סימני פיסוק בתחילת הטקסט או בסופו
!,.:;-"?|.התאמה לא תלוית אותיות רישיות: ממירה את כל התווים לאותיות קטנות.
נרמול של נתוני כסף: בתוויות עם סוג הנתונים
money, צריך להסיר את סימני המטבע שמופיעים בתחילת הערך ובסופו.
ישויות טבלאיות
לישויות ולביאורים ברמת ההורה אין ערכי טקסט, וההתאמה מתבססת על תיבות התוחמות המשולבות של הישויות והביאורים ברמת הילד. אם יש רק הורה חזוי אחד והורה עם הערה אחת, הם יותאמו באופן אוטומטי, ללא קשר לתיבות התוחמות.
אחרי שמתבצעת התאמה בין ההורים, מתבצעת התאמה בין הילדים כאילו הם לא היו ישויות טבלאיות. אם לא נמצאה התאמה להורים, Document AI לא ינסה למצוא התאמה לילדים שלהם. המשמעות היא שיכול להיות שייחשבו לישויות צאצא שגויות, גם אם תוכן הטקסט שלהן זהה, אם לא נמצאה התאמה לישויות ההורה שלהן.
יחסי הורה / צאצא הם תכונה בגרסת טרום-השקה (Preview), והם נתמכים רק בטבלאות עם רמה אחת של קינון.
ייצוא מדדי הערכה
נכנסים לדף Processors במסוף Google Cloud ובוחרים את המעבד.
בכרטיסייה הערכה ובדיקה, לוחצים על הורדת מדדים כדי להוריד את מדדי ההערכה כקובץ JSON.
לוח הבקרה למעקב
לוח הבקרה של המעקב במסוף Google Cloud מאפשר ליצור בקלות תצוגות חזותיות של מעקב אחרי מדדים ומשאבים שונים שנעשה בהם שימוש במעבדי Document AI.
רשימת המדדים והשדות שלהם: מספר הדפים שעברו עיבוד בהצלחה והמספר הכולל של המסמכים שנשלחו לעיבוד. לשני המדדים האלה יש את השדות הבאים: location, processor type, processor_id, processor_version_id, status ו-processing_type.
המדדים זמן אחזור של סנכרון, זמן אחזור של עיבוד ברצף לכל מסמך ומספר פעולות עיבוד ברצף כוללים את השדות הבאים: location, processor_type, processor_id, processor_version_id ו-status.
יצירת תצוגת מעקב
אתם יכולים לעקוב אחרי המעבדים בנפרד או ביחד, באמצעות תצוגה לכל מעבד ותצוגה לכל פרויקט. השלבים זהים בשני המקרים.
במסוף Google Cloud , בקטע Document AI, עוברים לדף Processors.
אופציונלי: אם רוצים לעקוב אחרי מעבד ספציפי, בוחרים אותו מהרשימה.
בחלונית הניווט, בוחרים באפשרות Monitoring monitoring.
מגדירים את טווח הזמן.
מסמנים את תיבות הסימון של התוויות שנבחרו למדד ולמשאב ולוחצים על אישור.
אופציונלי: אפשר לראות אפשרויות נוספות לכל תרשים באמצעות האפשרות תפריט .