
אתם יכולים להשתמש ב-Enterprise Document OCR כחלק מ-Document AI כדי לזהות ולחלץ טקסט ומידע על פריסה ממסמכים שונים. בעזרת תכונות שניתנות להגדרה, אפשר להתאים את המערכת לדרישות ספציפיות של עיבוד מסמכים.
סקירה כללית
אתם יכולים להשתמש ב-Enterprise Document OCR למשימות כמו הזנת נתונים שמבוססת על אלגוריתמים או על למידת מכונה, ולשיפור ולאימות של דיוק הנתונים. אתם יכולים להשתמש ב-Enterprise Document OCR גם כדי לבצע משימות כמו:
- דיגיטציה של טקסט: חילוץ טקסט ונתוני פריסה ממסמכים לחיפוש, לצינורות לעיבוד מסמכים שמבוססים על כללים או ליצירת מודלים בהתאמה אישית.
- שימוש באפליקציות של מודלי שפה גדולים (LLM): אפשר להשתמש בהבנה ההקשרית של מודלי שפה גדולים (LLM) וביכולות החילוץ של טקסט ופריסה של OCR כדי להפוך שאלות ותשובות לאוטומטיות. לקבל תובנות מהנתונים ולייעל את תהליכי העבודה.
- ארכיון: המרת מסמכים מנייר לטקסט שניתן לקריאה על ידי מכונה כדי לשפר את הנגישות למסמכים.
בחירת ה-OCR המתאים ביותר לתרחיש השימוש
| הפתרון | Product | תיאור | תרחיש לדוגמה |
|---|---|---|---|
| Document AI | Enterprise Document OCR | מודל ייעודי לתרחישי שימוש במסמכים. התכונות המתקדמות כוללות ציון איכות התמונה, רמזים לגבי השפה ותיקון סיבוב. | מומלץ כשמחפשים טקסט במסמכים. תרחישי שימוש לדוגמה כוללים קובצי PDF, מסמכים סרוקים כתמונות או קובצי Microsoft DocX. |
| Document AI | תוספים ל-OCR | תכונות פרימיום לצרכים ספציפיים. התכונה הזו תואמת רק לגרסה 2.0 ואילך של Enterprise Document OCR. | צריך לזהות נוסחאות מתמטיות, לקבל מידע על סגנון הגופן או להפעיל חילוץ של תיבות סימון. |
| Cloud Vision API | זיהוי טקסט | API בארכיטקטורת REST שזמין בכל העולם ומבוסס על Google Cloud מודל OCR רגיל. מכסת ברירת המחדל היא 1,800 בקשות לדקה. | תרחישים כלליים של חילוץ טקסט שדורשים חביון נמוך וקיבולת גבוהה. |
| Cloud Vision | OCR Google Distributed Cloud (הוצא משימוש) | אפליקציה של Google Cloud Marketplace שאפשר לפרוס כקונטיינר לכל אשכול GKE באמצעות GKE Enterprise. | כדי לעמוד בדרישות של מיקום הנתונים או בדרישות התאימות. |
זיהוי וחילוץ
Enterprise Document OCR יכול לזהות בלוקים, פסקאות, שורות, מילים וסמלים בקובצי PDF ובתמונות, וגם ליישר מסמכים כדי לשפר את הדיוק.
מאפיינים נתמכים לזיהוי פריסה ולחילוץ נתונים:
| טקסט מודפס | כתב יד | פסקה | חסימה | Line | Word | ברמת הסמל | מספר הדף |
|---|---|---|---|---|---|---|---|
| ברירת מחדל | ברירת מחדל | ברירת מחדל | ברירת מחדל | ברירת מחדל | ברירת מחדל | ניתן להגדרה | ברירת מחדל |
התכונות של Enterprise Document OCR שאפשר להגדיר כוללות:
חילוץ טקסט מוטמע או מקורי מקובצי PDF דיגיטליים: התכונה הזו מחלצת טקסט וסמלים בדיוק כמו שהם מופיעים במסמכי המקור, גם אם מדובר בטקסט מסובב, בגדלים או בסגנונות קיצוניים של גופנים ובטקסט מוסתר חלקי.
תיקון סיבוב: אפשר להשתמש ב-Enterprise Document OCR כדי לבצע עיבוד מקדים של תמונות מסמכים ולתקן בעיות סיבוב שעלולות להשפיע על איכות החילוץ או העיבוד.
ציון איכות התמונה: מקבלים מדדי איכות שיכולים לעזור בניתוח מסמכים. ציון איכות התמונה מספק מדדי איכות ברמת הדף בשמונה מימדים, כולל טשטוש, נוכחות של גופנים קטנים מהרגיל ובוהק.
ציון טווח דפים: מציינים את טווח הדפים במסמך קלט ל-OCR. כך תוכלו לחסוך בהוצאות ובזמן העיבוד של דפים לא נחוצים.
זיהוי שפה: זיהוי השפות שבהן כתוב הטקסט שחולץ.
רמזים לגבי שפה וכתב יד: כדי לשפר את הדיוק, אפשר לספק למודל ה-OCR רמז לגבי שפה או כתב יד על סמך המאפיינים הידועים של מערך הנתונים.
כדי ללמוד איך להפעיל הגדרות OCR, אפשר לעיין במאמר הפעלת הגדרות OCR.
תוספים ל-OCR
Enterprise Document OCR מציע יכולות ניתוח אופציונליות שאפשר להפעיל לפי הצורך בבקשות עיבוד ספציפיות.
היכולות הבאות של התוסף זמינות בגרסאות היציבות pretrained-ocr-v2.0-2023-06-02 ו-pretrained-ocr-v2.1-2024-08-07, ובגרסת Release Candidate pretrained-ocr-v2.1.1-2025-01-31.
- OCR מתמטי: זיהוי וחילוץ של נוסחאות ממסמכים בפורמט LaTeX.
- חילוץ תיבות סימון: זיהוי תיבות סימון וחילוץ הסטטוס שלהן (מסומנות או לא מסומנות) בתגובה של Enterprise Document OCR.
- זיהוי סגנון גופן: זיהוי מאפייני גופן ברמת המילה, כולל סוג הגופן, סגנון הגופן, כתב יד, עובי וצבע.
במאמר הפעלה של תוספי OCR מוסבר איך להפעיל את התוספים שמופיעים ברשימה.
פורמטים נתמכים של קבצים
Enterprise Document OCR תומך בפורמטים של קבצים: PDF, GIF, TIFF, JPEG, PNG, BMP ו-WebP. מידע נוסף זמין במאמר בנושא קבצים נתמכים.
Enterprise Document OCR תומך גם בקובצי DocX של עד 15 עמודים בסנכרון ו-30 עמודים באסינכרון. כדי לבקש הגדלה של המכסה (QIR), פועלים לפי השלבים לבקשת התאמה של מכסה. התמיכה ב-DocX נמצאת בתצוגה מקדימה פרטית. כדי לבקש גישה, צריך לפנות לצוות התמיכה בחשבונות Google.
ניהול גרסאות מתקדם
התכונה 'ניהול גרסאות מתקדם' נמצאת בתצוגה מקדימה. שדרוגים של מודלים בסיסיים של AI/ML OCR עשויים להוביל לשינויים בהתנהגות של OCR. אם נדרשת עקביות מלאה, אפשר להשתמש בגרסה קפואה של המודל כדי להצמיד את ההתנהגות למודל OCR מדור קודם למשך עד 18 חודשים. כך תוכלו לוודא שתוצאת הפונקציה OCR תתבסס על אותה תמונה. ראו את הטבלה בנושא גרסאות המעבד.
גרסאות המעבד
התכונה הזו תואמת לגרסאות המעבד הבאות. מידע נוסף מופיע במאמר בנושא ניהול גרסאות של מעבדים.
| מזהה גרסה | ערוץ הפצה | תיאור |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
יציב | גרסה קפואה של מודל v1.0: קבצים, הגדרות וקובצי הפעלה של מודל, שנלקחו מתמונת מצב של גרסה והוקפאו בקובץ אימג' של קונטיינר למשך עד 18 חודשים. |
pretrained-ocr-v2.0-2023-06-02 |
יציב | מודל מוכן לייצור שמתמחה בתרחישי שימוש במסמכים. כולל גישה לכל תוספי ה-OCR. |
pretrained-ocr-v2.1-2024-08-07 |
יציב | השיפורים העיקריים בגרסה 2.1 הם: זיהוי טוב יותר של טקסט מודפס, זיהוי מדויק יותר של תיבות סימון וסדר קריאה מדויק יותר. |
pretrained-ocr-v2.1.1-2025-01-31 |
גרסה מועמדת להפצה | גרסה v2.1.1 דומה לגרסה V2.1, והיא זמינה בכל האזורים חוץ מאלה: US, EU ו-asia-southeast1. |
שימוש ב-Enterprise Document OCR לעיבוד מסמכים
במדריך למתחילים הזה נסביר על Enterprise Document OCR. במאמר הזה מוסבר איך לשפר את תוצאות ה-OCR של המסמכים בתהליך העבודה שלכם, על ידי הפעלה או השבתה של אחת מהגדרות ה-OCR הזמינות.
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
יצירת מעבד Enterprise Document OCR
קודם יוצרים מעבד Enterprise Document OCR. מידע נוסף זמין במאמר בנושא יצירה וניהול של מעבדים.
הגדרות OCR
כדי להפעיל את כל הגדרות ה-OCR, צריך להגדיר את השדות המתאימים ב-ProcessOptions.ocrConfig ב-ProcessDocumentRequest או ב-BatchProcessDocumentsRequest.
מידע נוסף זמין במאמר בנושא שליחת בקשת עיבוד.
ניתוח איכות התמונה
ניתוח חכם של איכות המסמך מתבצע באמצעות למידת מכונה כדי להעריך את איכות המסמך על סמך קלות הקריאה של התוכן שלו.
הערכת האיכות הזו מוחזרת כציון איכות [0, 1], כאשר 1 מייצג איכות מושלמת.
אם ציון האיכות שזוהה נמוך מ-0.5, מוחזרת גם רשימה של סיבות שליליות לאיכות (ממוינות לפי הסבירות).
סבירות גבוהה מ-0.5 נחשבת לזיהוי חיובי.
אם המסמך נחשב לפגום, ה-API מחזיר את שמונת סוגי הפגמים הבאים במסמך:
quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare
יש כמה מגבלות בניתוח הנוכחי של איכות המסמך:
- הוא יכול להחזיר תוצאות חיוביות כוזבות לגבי מסמכים דיגיטליים ללא פגמים. התכונה הזו מתאימה במיוחד למסמכים שנסרקו או צולמו.
פגמים של בוהק הם מקומיים. הנוכחות שלהם לא בהכרח תפגע בקריאות הכוללת של המסמך.
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.enableImageQualityScores ל-true בבקשת העיבוד.
התכונה הנוספת הזו מוסיפה לשיחה זמן אחזור שדומה לזמן האחזור של עיבוד OCR.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
תשובה
תוצאות זיהוי הפגמים מופיעות בDocument.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
דוגמאות מלאות של פלט זמינות במאמר פלט לדוגמה של מעבד.
רמזים לגבי שפה
מעבד ה-OCR תומך ברמזים לשפה שאתם מגדירים כדי לשפר את הביצועים של מנוע ה-OCR. הוספת רמז לשפה מאפשרת ל-OCR לבצע אופטימיזציה לשפה שנבחרה במקום לשפה שהמערכת הסיקה.
קלט
כדי להפעיל את ההגדרה, צריך להגדיר את ProcessOptions.ocrConfig.hints[].languageHints[] עם רשימה של קודי שפה בפורמט BCP-47.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
דוגמאות מלאות של פלט זמינות במאמר פלט לדוגמה של מעבד.
זיהוי סמלים
מילוי נתונים ברמת הסמל (או האות הבודדת) בתגובה למסמך.
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.enableSymbol ל-true בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
תשובה
אם התכונה הזו מופעלת, השדה Document.pages[].symbols[] יאוכלס.
דוגמאות מלאות של פלט זמינות במאמר פלט לדוגמה של מעבד.
ניתוח מובנה של קובצי PDF
חילוץ טקסט מוטמע מקובצי PDF דיגיטליים. כשההגדרה הזו מופעלת, אם יש טקסט דיגיטלי, המערכת משתמשת אוטומטית במודל ה-PDF הדיגיטלי המובנה. אם יש טקסט לא דיגיטלי, המערכת משתמשת אוטומטית במודל ה-OCR האופטי. המשתמש מקבל את שתי התוצאות של הטקסטים אחרי מיזוג.
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.enableNativePdfParsing ל-true בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
זיהוי דמויות בתוך תיבה
כברירת מחדל, ב-Enterprise Document OCR מופעל גלאי שמטרתו לשפר את איכות חילוץ הטקסט של תווים שנמצאים בתוך תיבה. לדוגמה:

אם נתקלתם בבעיות באיכות ה-OCR של תווים בתוך תיבות, אתם יכולים להשבית את התכונה.
קלט
כדי להשבית את ההגדרה, מגדירים את ProcessOptions.ocrConfig.disableCharacterBoxesDetection לערך true בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
פריסה מדור קודם
אם אתם צריכים אלגוריתם היוריסטי לזיהוי פריסות, אתם יכולים להפעיל פריסה מדור קודם, שמשמשת כחלופה לאלגוריתם הנוכחי לזיהוי פריסות שמבוסס על למידת מכונה. זו לא ההגדרה המומלצת. הלקוחות יכולים לבחור את האלגוריתם המתאים ביותר לפריסת המסמך, בהתאם לתהליך העבודה שלהם.
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.advancedOcrOptions ל-["legacy_layout"] בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
ציון טווח דפים
כברירת מחדל, ה-OCR מחלץ טקסט ומידע על הפריסה מכל הדפים במסמכים. אתם יכולים לבחור מספרי דפים ספציפיים או טווחים של דפים ולחלץ טקסט רק מהדפים האלה.
יש שלוש דרכים להגדיר את זה ב-ProcessOptions:
- כדי לעבד רק את הדף השני והחמישי:
{
"individualPageSelector": {"pages": [2, 5]}
}
- כדי לעבד רק את שלושת הדפים הראשונים:
{
"fromStart": 3
}
- כדי לעבד רק את ארבעת הדפים האחרונים:
{
"fromEnd": 4
}
בתגובה, כל Document.pages[].pageNumber תואם לאותם דפים שצוינו בבקשה.
שימושים בתוספים ל-OCR
אפשר להפעיל את יכולות הניתוח האופציונליות האלה של Enterprise Document OCR לפי הצורך, בבקשות עיבוד ספציפיות.
OCR למתמטיקה
זיהוי תווים אופטי (OCR) של מתמטיקה מזהה, מפענח ומחלץ נוסחאות, כמו משוואות מתמטיות שמיוצגות כ-LaTeX, יחד עם קואורדינטות של תיבות תוחמות.
דוגמה לייצוג ב-LaTeX:
זוהתה תמונה
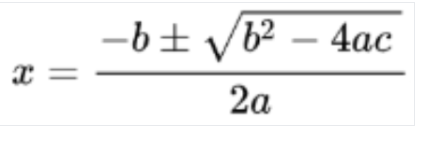
המרת LaTeX
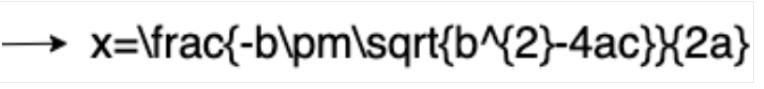
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr ל-true בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
תשובה
הפלט של זיהוי התווים האופטי (OCR) של המתמטיקה מופיע ב-Document.pages[].visualElements[] עם "type": "math_formula".
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
חילוץ סימני בחירה
אם האפשרות הזו מופעלת, המודל מנסה לחלץ את כל תיבות הסימון ולחצני הבחירה במסמך, יחד עם קואורדינטות של תיבות תוחמות.
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection ל-true בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
תשובה
הפלט של תיבת הסימון מופיע ב-Document.pages[].visualElements[] עם "type": "unfilled_checkbox" או "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
זיהוי סגנון גופן
אם מפעילים את זיהוי סגנון הגופן, Enterprise Document OCR מחלץ מאפייני גופן שאפשר להשתמש בהם לעיבוד מתקדם טוב יותר.
ברמת הטוקן (המילה), המאפיינים הבאים מזוהים:
- זיהוי כתב יד
- סגנון הגופן
- גודל גופן
- סוג הגופן
- צבע גופן
- משקל הגופן
- הריווח בין האותיות
- הטקסט המודגש
- נטוי
- קו תחתון
- צבע הטקסט (RGBa)
צבע הרקע (RGBa)
קלט
כדי להפעיל את ההרשאות, צריך להגדיר את ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo ל-true בבקשת העיבוד.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
תשובה
הפלט של font-style מופיע ב-Document.pages[].tokens[].styleInfo עם הסוג StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
המרת אובייקטים של מסמכים לפורמט Vision AI API
Document AI Toolbox כולל כלי שממיר את הפורמט של Document AI API Document לפורמט של Vision AI AnnotateFileResponse, וכך מאפשר למשתמשים להשוות בין התשובות של מעבד ה-OCR של המסמך לבין Vision AI API. הנה קוד לדוגמה.
סתירות ידועות בין התגובה של Vision AI API לבין התגובה של Document AI API והכלי להמרה:
- התשובה של Vision AI API מאכלסת רק את
verticesלבקשות תמונה, ומאכלסת רק אתnormalized_verticesלבקשות PDF. התשובה של Document AI והממיר מאכלסים אתverticesוגם אתnormalized_vertices. - התגובה של Vision AI API מאכלסת את
detected_breakבסמל האחרון של המילה. התגובה של Document AI API והממיר מאכלסים אתdetected_breakבמילה ובסמל האחרון של המילה. - התשובה של Vision AI API תמיד מאכלסת את שדות הסמלים. כברירת מחדל, התגובה של Document AI לא מאכלסת שדות של סמלים. כדי לוודא שהתשובה של Document AI והממיר ימלאו את השדות של הסמלים, צריך להגדיר את התכונה
enable_symbolכ'מפורטת'.
דוגמאות קוד
בדוגמאות הקוד הבאות אפשר לראות איך לשלוח בקשת עיבוד שמאפשרת הגדרות של OCR ותוספים, ואז לקרוא את השדות ולהדפיס אותם במסוף:
REST
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- LOCATION: המיקום של המעבד, לדוגמה:
us– ארצות הבריתeu- האיחוד האירופי
- PROJECT_ID: מזהה הפרויקט ב- Google Cloud .
- PROCESSOR_ID: המזהה של המעבד בהתאמה אישית.
- PROCESSOR_VERSION: מזהה גרסת המעבד. מידע נוסף זמין במאמר בנושא בחירת גרסת מעבד. לדוגמה:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: ערך בוליאני להשבתת הבדיקה האנושית (נתמך רק על ידי מעבדי 'האדם שבתהליך').
-
true– דילוג על בדיקה אנושית -
false– הפעלת בדיקה אנושית (ברירת מחדל)
-
- MIME_TYPE†: אחת מהאפשרויות התקפות של סוג MIME.
- IMAGE_CONTENT†: אחד מהערכים התקינים
של תוכן מסמך מוטבע, שמיוצג כזרם של בייטים. בייצוגי JSON, קידוד base64 (מחרוזת ASCII) של נתוני התמונה הבינאריים. המחרוזת הזו צריכה להיראות כמו המחרוזת הבאה:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: מציין אילו שדות לכלול בפלט
Document. זוהי רשימה מופרדת בפסיקים של שמות מלאים של שדות בפורמטFieldMask.- לדוגמה:
text,entities,pages.pageNumber
- לדוגמה:
- הגדרות OCR
- ENABLE_NATIVE_PDF_PARSING: (בוליאני) חילוץ טקסט מוטמע מקובצי PDF, אם יש כזה.
- ENABLE_IMAGE_QUALITY_SCORES: (בוליאני) מפעיל ציוני איכות חכמים של מסמכים.
- ENABLE_SYMBOL: (בוליאני) כולל מידע על זיהוי תווים אופטי (OCR) של סמל (אות).
- DISABLE_CHARACTER_BOXES_DETECTION: (בוליאני) השבתת זיהוי תיבות תווים במנוע ה-OCR.
- LANGUAGE_HINTS: רשימה של קודי שפה בפורמט BCP-47 לשימוש ב-OCR.
- ADVANCED_OCR_OPTIONS: רשימה של אפשרויות מתקדמות ל-OCR כדי לכוונן עוד יותר את התנהגות ה-OCR. הערכים התקפים הנוכחיים הם:
-
legacy_layout: אלגוריתם היוריסטי לזיהוי פריסות, שמשמש כחלופה לאלגוריתם הנוכחי לזיהוי פריסות שמבוסס על למידת מכונה.
-
- תוספי פרימיום ל-OCR
- ENABLE_SELECTION_MARK_DETECTION: (בוליאני) הפעלת זיהוי סימני בחירה במנוע ה-OCR.
- COMPUTE_STYLE_INFO (בוליאני) הפעלת מודל לזיהוי גופנים והחזרת מידע על סגנון הגופן.
- ENABLE_MATH_OCR: (בוליאני) הפעלת המודל שיכול לחלץ נוסחאות מתמטיות ב-LaTeX.
- INDIVIDUAL_PAGES: רשימה של דפים בודדים לעיבוד.
† אפשר גם לציין את התוכן הזה באמצעות תוכן בקידוד base64 באובייקט inlineDocument.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
גוף בקשת JSON:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
כדי לשלוח את הבקשה עליכם לבחור אחת מהאפשרויות הבאות:
curl
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
אם הבקשה תתבצע בהצלחה, השרת יחזיר קוד סטטוס 200 OK של HTTP ואת התשובה בפורמט JSON. גוף התשובה מכיל מופע של Document.
Python
למידע נוסף, קראו את מאמרי העזרה של Document AI Python API.
כדי לבצע אימות ב-Document AI, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
המאמרים הבאים
- רשימת המעבדים
- אפשר להפריד מסמכים לחלקים קריאים באמצעות Layout Parser.
- יוצרים מסווג תוכן מותאם אישית.