
L'agente di rilevamento di Knowledge Catalog è un assistente basato sull'AI che migliora la pertinenza della ricerca per query complesse in linguaggio naturale in base alle funzionalità di ricerca di Knowledge Catalog. Ottimizzando la comprensione e la formulazione delle query, fornisce risultati più accurati rispetto all'API di ricerca di Knowledge Catalog standard. Questa funzionalità è fondamentale soprattutto per le query complesse o lunghe.
Casi d'uso
L'agente di rilevamento offre un'esperienza conversazionale completa per scenari come i seguenti:
- Intenti e vincoli complessi o combinati: gestione delle richieste di ricerca con più criteri, ad esempio la ricerca di set di dati in
us-central1, ma l'esclusione delle risorse in BigQuery. - Ricerca orientata al business: individuazione degli asset di dati in base all'intento e al contesto aziendale anziché alla corrispondenza esatta dei termini tecnici.
- Esplorazione multi-turn: perfezionamento della ricerca tramite un dialogo conversazionale per restringere i risultati.
L'agente di rilevamento è basato su ricerca semantica di Knowledge Catalog che offre una ricerca ibrida predefinita. Puoi continuare a utilizzare direttamente la ricerca semantica di Knowledge Catalog quando devi elaborare ricerche con intenzione di acquisto elevata (quando conosci la risorsa o la colonna specifica), requisiti di bassa latenza o ricerca ibrida senza configurazione.
Come funziona
L'agente di rilevamento esegue i seguenti passaggi per rispondere a una query di ricerca:
- Analizza l'input per l'intento di comprendere la query, genera più varianti di ricerca e mappa i termini ai filtri dei metadati.
- Cerca le risorse utilizzando la ricerca semantica di Knowledge Catalog.
- Classifica i risultati uniti in base alla pertinenza.
Il seguente diagramma fornisce i dettagli della procedura:
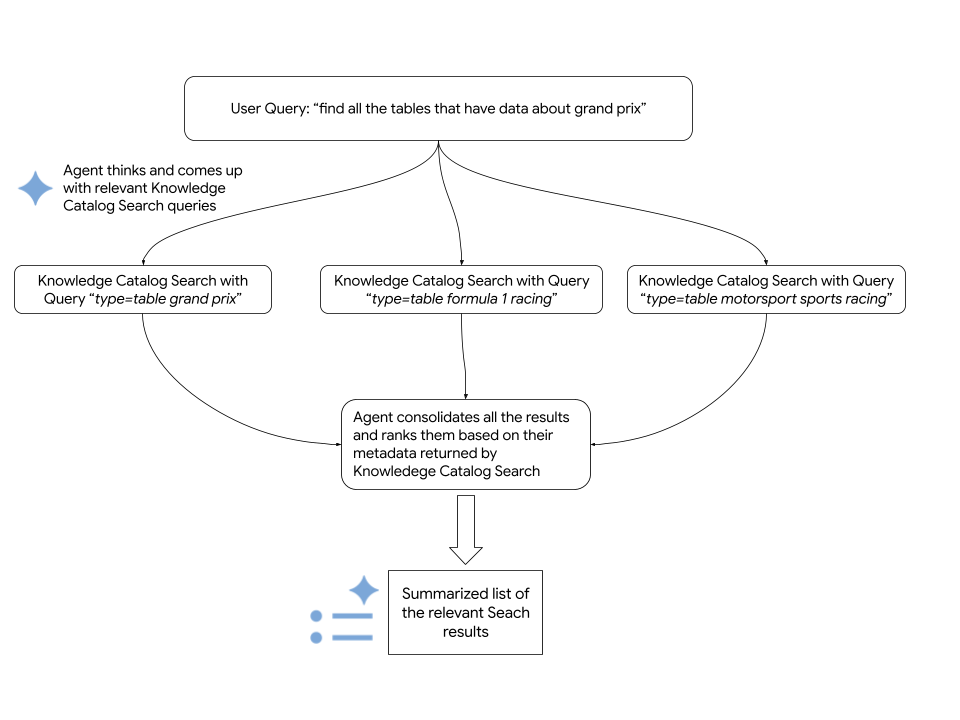
L'agente si basa sull'API di ricerca di Knowledge Catalog per recuperare le risorse pertinenti Google Cloud . Il seguente snippet di codice mostra come l'agente chiama la ricerca semantica di Knowledge Catalog:
# Configure the request parameters for the
# call to Knowledge Catalog Semantic Search API.
endpoint = "dataplex.googleapis.com"
client = dataplex_v1.CatalogServiceClient(
client_options={"api_endpoint": endpoint}
)
location = "global"
consumer_project_id = "my-gcp-project"
parent_name = f"projects/{consumer_project_id}/locations/{location}"
# Call Knowledge Catalog Semantic Search API.
response = client.search_entries(
request={
"name": parent_name,
"query": query,
"page_size": 50,
"semantic_search": True,
}
)
# Call Knowledge Catalog LookupContext for each search result
# to retrieve rich, LLM-ready metadata.
entries = []
for result in response.results:
entry_name = result.dataplex_entry.name
# Prepare the LookupContext request for the specific resource
lookup_request = {
"name": parent_name,
"resources": [entry_name]
}
# Call the LookupContext API
lookup_response = client.lookup_context(request=lookup_request)
# Extract the rich context YAML to share with the agent
entries.append({
"entry_name": entry_name,
"context": lookup_response.context
})
return {"results": entries}
Prima di iniziare
Per eseguire l'agente di rilevamento di Knowledge Catalog, assicurati di soddisfare i seguenti requisiti:
Ruoli obbligatori
Per ottenere le autorizzazioni necessarie per utilizzare l'agente di rilevamento, chiedi all'amministratore di concederti i seguenti ruoli IAM nel tuo Google Cloud progetto iam.gserviceaccount.com:
- Visualizzatore Dataplex (
roles/dataplex.viewer) - Utente Vertex AI (
roles/aiplatform.user) - Service Usage Consumer (
roles/serviceusage.serviceUsageConsumer)
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questi ruoli predefiniti includono le autorizzazioni necessarie per utilizzare l'agente di rilevamento. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per utilizzare l'agente di rilevamento sono necessarie le seguenti autorizzazioni:
-
dataplex.projects.search -
aiplatform.endpoints.predict -
serviceusage.services.use
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Abilita API
Per utilizzare l'agente di rilevamento di Knowledge Catalog, abilita le seguenti API nel tuo progetto: API Knowledge Catalog, API Vertex AI e API Service Usage.
Ruoli richiesti per abilitare le API
Per abilitare le API, devi disporre dell'autorizzazione serviceusage.services.enable. Se hai
creato il progetto, probabilmente hai già questa autorizzazione tramite il
ruolo Proprietario (roles/owner). In caso contrario, puoi ottenere questa autorizzazione tramite il
ruolo Amministratore Service Usage (roles/serviceusage.serviceUsageAdmin).
Scopri come concedere i ruoli.
Configura l'ambiente
Per configurare l'ambiente di sviluppo per l'agente di rilevamento:
Clona il repository
dataplex-labs.git clone https://github.com/GoogleCloudPlatform/dataplex-labs.gitPassa alla directory dell'agente:
cd dataplex-labs/knowledge_catalog_discovery_agentCrea e attiva un ambiente virtuale Python, quindi installa le dipendenze elencate nel
requirements.txtfile:google-adk(Agent Development Kit)google-cloud-dataplex(client Python di Knowledge Catalog)google-api-core
python3 -m venv /tmp/kcsearch source /tmp/kcsearch/bin/activate pip3 install -r requirements.txtImposta le variabili di ambiente con il seguente comando:
export GOOGLE_CLOUD_PROJECT=PROJECT_ID export GOOGLE_GENAI_USE_VERTEXAI=TrueSostituisci quanto segue:
PROJECT_IDcon l'ID del tuo progetto
Esegui l'agente di rilevamento come agente root
Per eseguire l'agente di rilevamento direttamente come agente root:
- Nel file
agent.pyche si trova nella cartellaknowledge_catalog_discovery_agent, rinomina la variabilediscovery_agentinroot_agent. Esegui l'agente utilizzando il
adk runcomando:adk run path/to/agent/parent/folderSostituisci quanto segue:
path/to/agent/parent/foldercon la directory principale che contiene la cartella con l'agente. Ad esempio, se l'agente si trova inknowledge_catalog_discovery_agent/, eseguiadk rundalla directoryagents/.
Esegui l'agente di rilevamento come strumento dell'agente
Per integrare l'agente di rilevamento in un agente personalizzato più grande, ad esempio my_custom_agent:
Configura la struttura del progetto in modo che contenga il modulo dell'agente di rilevamento:
my_custom_agent/ ├── agent.py └── knowledge_catalog_discovery_agent/ ├── SKILL.md ├── agent.py ├── tools.py └── utils.pyNel file
agent.pydell'agente personalizzato, importa l'agente di rilevamento e utilizzalo come strumento dell'agente. Vedi l'esempio:root_agent = llm_agent.Agent( model=google_llm.Gemini(model=GEMINI_MODEL), name="my_custom_agent", instruction=( "You are a Custom Agent. Your goal is to help users understand" " their data landscape, evaluate data assets, and derive insights" " from available resources. **IMPORTANT**: You should use the" " `knowledge_catalog_discovery_agent` to search for and discover" " data assets. For best results, pass in the Natural Language user'" " query as is to the `knowledge_catalog_discovery_agent`. Once assets" " are found, you should analyze their metadata, compare them, and" " provide recommendations or summaries to the user to help them make" " decisions. Focus on general metadata summary and comparison." ), tools=[ agent_tool.AgentTool(discovery_agent), ], )Esegui l'agente utilizzando il comando
adk run:adk run path/to/agent/parent/folderSostituisci quanto segue:
path/to/agent/parent/foldercon la directory principale che contiene la cartellamy_custom_agent/. Ad esempio, se l'agente si trova inagents/my_custom_agent/, eseguiadk rundalla directoryagents/.
Passaggi successivi
- Comprendi la sintassi di ricerca per Knowledge Catalog.
- Scopri di più su Agent Development Kit.
- Prova altri casi d'uso di Knowledge Catalog.