
Knowledge Catalog adalah katalog data yang didukung Gemini yang menyediakan konteks dan tata kelola bisnis universal untuk seluruh properti data Anda. Dengan mengekstrak semantik secara otomatis dari data terstruktur dan tidak terstruktur, alat ini membangun grafik konteks dinamis yang mendasari agen AI dalam enterprise truth dan mengurangi halusinasi. Tim data dan developer AI menggunakan Knowledge Catalog untuk menemukan data, menerapkan kebijakan, dan mengambil konteks yang kaya untuk analisis dan aplikasi otonom. Untuk mengetahui panduan mendetail tentang Knowledge Catalog, lihat video yang disematkan.
Dataplex Universal Catalog kini disebut Knowledge Catalog
Untuk mencerminkan visi penyatuan tata kelola data dengan kemampuan AI generatif secara lebih baik, Dataplex Universal Catalog kini menjadi Knowledge Catalog. Evolusi nama produk ini merepresentasikan peralihan dari registry metadata pasif konvensional ke grafik konteks aktif yang didukung AI.
Alasan Dataplex menjadi Knowledge Catalog
Seiring dengan percepatan adopsi AI generatif oleh organisasi, agen AI memerlukan konteks bisnis yang mendalam untuk memberikan respons yang akurat dan berdasarkan fakta. Knowledge Catalog menjembatani kesenjangan antara tata kelola data perusahaan dan alur kerja agen AI.
Apa perbedaan antara Dataplex dan Knowledge Catalog
Pembaruan Knowledge Catalog mencerminkan kemampuan baru yang berfokus pada AI. Tidak seperti katalog pasif konvensional, Knowledge Catalog secara otomatis mengelola metadata, logika bisnis, dan hubungan data ke dalam grafik konteks terpadu. Grafik ini memberikan enterprise truth yang andal yang dibutuhkan agen AI untuk menjalankan tugas kompleks secara akurat. Fitur ini memanfaatkan fitur seperti penataan konteks otomatis, contoh kueri terverifikasi, dan integrasi Model Context Protocol (MCP) lokal dan jarak jauh.
Yang tidak berubah
Deployment, API, dan konfigurasi Dataplex yang ada akan tetap beroperasi. Fitur inti seperti penemuan data, silsilah, kualitas data, dan glosarium bisnis tidak berubah dan didukung. Metadata, aspek, dan konfigurasi yang ada akan bertransisi ke pengalaman Knowledge Catalog baru tanpa migrasi manual, perpindahan data, atau waktu non-operasional.
API dan library klien
Perubahan merek menjadi Knowledge Catalog tidak mengubah endpoint API, perintah gcloud dataplex, atau library klien yang ada. Anda dapat
terus menggunakan API dan library klien Knowledge Catalog untuk
berinteraksi dengan Knowledge Catalog:
REST API. Lihat dokumentasi Knowledge Catalog REST API.
RPC API. Lihat dokumentasi Knowledge Catalog RPC API.
Library klien. Mulai menggunakan Knowledge Catalog dalam bahasa pilihan Anda menggunakan library klien Knowledge Catalog.
Perintah gcloud. Mengelola resource Knowledge Catalog menggunakan grup perintah
gcloud dataplex. Lihat referensi perintah gcloud Dataplex.
Cara kerja Knowledge Catalog
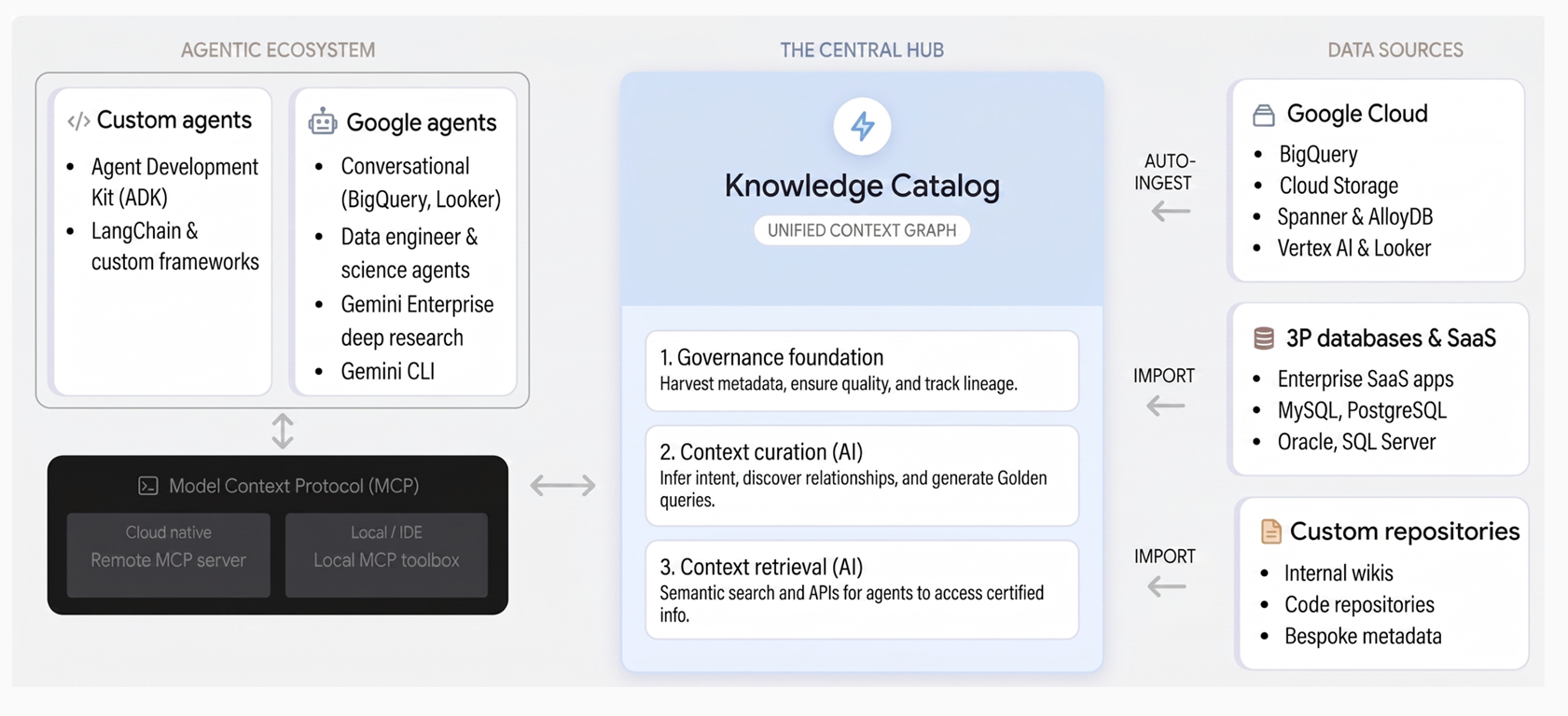
Knowledge Catalog menyatukan tata kelola dan konteks melalui tiga pilar inti:
Dasar tata kelola. Knowledge Catalog secara otomatis mengumpulkan metadata teknis dari layanan seperti BigQuery, AlloyDB untuk PostgreSQL, dan Spanner, serta sistem pihak ketiga. Google Cloud Hal ini membangun fondasi data tepercaya melalui glosarium bisnis terpusat, pemeriksaan kualitas data, deteksi anomali, dan tata kelola berbasis kebijakan.
Seleksi konteks. Dengan menggunakan Gemini, layanan ini menyimpulkan niat bisnis dengan menganalisis skema, log kueri, dan model semantik di seluruh data Anda. Fitur ini menghasilkan deskripsi bahasa alami, menemukan hubungan, dan menyarankan pola SQL terverifikasi dalam bentuk contoh kueri yang mencakup logika bisnis yang kompleks.
Pengambilan konteks. Agen dan aplikasi AI dapat langsung menemukan aset dan mengambil konteks yang diperkaya melalui penelusuran semantik dan alat yang mendukung Model Context Protocol (MCP). Dengan demikian, agen dapat mengakses kebenaran organisasi untuk pengambilan keputusan yang andal.
Diagram berikut mengilustrasikan arsitektur Knowledge Catalog dan cara menyatukan tata kelola data dengan alur kerja AI generatif:
Kasus penggunaan umum
Knowledge Catalog membantu engineer data, data scientist, dan developer AI memecahkan tantangan dalam pengelolaan data dan pengembangan AI:
Memperkaya data untuk AI. Gunakan insight data untuk data tidak terstruktur guna mengekstrak metadata dan entity secara otomatis dari file tidak terstruktur seperti PDF di Cloud Storage. Hal ini membuat data gelap dan pengetahuan organisasi dapat diakses oleh model AI.
Mengurangi halusinasi AI. Berikan agen AI contoh kueri yang telah diverifikasi sebelumnya dan batas aman semantik, sehingga mereka dapat menjalankan pengambilan data yang kompleks dengan akurasi yang lebih deterministik.
Mempercepat penemuan data. Gunakan penelusuran semantik dan grafik konteks terpusat untuk menemukan aset data yang relevan di berbagai sumber untuk alur kerja analisis dan ilmu data.
Mengotomatiskan pembuatan produk data. Inferensi hubungan di seluruh estate data Anda untuk mengemas aset ke dalam produk data mandiri dengan perjanjian tingkat layanan (SLA) dan batasan tata kelola bawaan.
Contoh alur kerja di Knowledge Catalog
Untuk melihat cara membangun grafik konteks dan mengelola aset data, pertimbangkan cara perusahaan retail online menggunakan fitur Knowledge Catalog berikut:
Temukan dan katalogkan data. Retailer secara otomatis menyerap data transaksi dan mengumpulkan metadata dari Google Cloud layanan seperti BigQuery, Pub/Sub, dan Cloud Storage. Layanan ini juga mengimpor metadata dari database inventaris kustom untuk membuat tampilan terpadu dari seluruh aset data retail. Untuk mengetahui informasi selengkapnya, lihat Menemukan data.
Menelusuri aset data. Data scientist menemukan aset data pelanggan yang tepat yang mereka butuhkan menggunakan mesin telusur Knowledge Catalog dengan pemfilteran berfaset, penelusuran semantik bahasa alami, dan operator logis. Untuk mengetahui informasi selengkapnya, lihat Menelusuri aset data.
Perkaya data dengan konteks bisnis. Tim tata kelola data menentukan terminologi retail (seperti "Nilai Seumur Hidup" atau "SKU") menggunakan glosarium bisnis, dan menggunakan insight data yang didukung AI untuk membuat deskripsi tabel produk baru secara otomatis. Mereka juga menerapkan metadata dan tag (aspek) kustom terstruktur secara manual dan seragam di seluruh aset mereka. Untuk mengetahui informasi selengkapnya, lihat Mengelola aspek dan memperkaya metadata serta Mengelola glosarium bisnis.
Memahami hubungan data dengan silsilah. Tim engineering secara otomatis melacak silsilah data untuk melihat cara data pesanan berpindah, diubah, dan digunakan di seluruh sistem mereka. Mereka menggunakan grafik silsilah untuk memecahkan masalah pipeline pelaporan, melakukan analisis akar masalah pada error checkout, dan memastikan kepatuhan. Untuk mengetahui informasi selengkapnya, lihat Ringkasan silsilah data.
Membuat profil data dan mengukur kualitas. Retailer menggunakan pembuatan profil data otomatis untuk mengidentifikasi pola dan anomali dalam tabel harga BigQuery mereka. Mereka menentukan dan menjalankan pemeriksaan kualitas data untuk memastikan alamat pengiriman pelanggan akurat, lengkap, dan andal untuk workload AI dan pemenuhan pesanan di hilir. Untuk mengetahui informasi selengkapnya, lihat Ringkasan pembuatan profil data dan Ringkasan kualitas data otomatis.
Menyeleksi dan membagikan produk data. Tim platform data mengemas aset penjualan regional dan metadata, skor kualitas, serta silsilah terkait ke dalam produk data "Customer 360" pilihan yang ditemukan dan digunakan oleh tim pemasaran dan inventaris. Untuk mengetahui informasi selengkapnya, lihat Ringkasan produk data.
Knowledge Catalog di Google Cloud ekosistem
Saat membangun fondasi data, penting untuk memahami cara Knowledge Catalog terintegrasi dengan layananGoogle Cloud terkait:
| Layanan | Peran utama | Kapan digunakan |
|---|---|---|
| Knowledge Catalog | Konteks agentik dan tata kelola data | Gunakan untuk membuat katalog metadata, mengelola kualitas data, dan menyediakan perujukan semantik untuk agen AI. |
| BigQuery | Data warehouse perusahaan | Gunakan untuk menyimpan, membuat kueri, dan menganalisis set data yang sangat besar. Knowledge Catalog memperkaya data BigQuery dengan konteks bisnis. |
| Vertex AI | Platform AI dan machine learning | Digunakan untuk membangun dan men-deploy model ML dan agen AI. Agen menggunakan Knowledge Catalog API untuk mengambil konteks perusahaan yang akurat. |
| Cloud Storage | Penyimpanan data tidak terstruktur | Digunakan untuk menyimpan file mentah. Knowledge Catalog memindai bucket Cloud Storage untuk mengekstrak metadata dan entity yang dapat ditelusuri. |
Konsep inti
Untuk menggunakan Knowledge Catalog secara efektif, pahami konsep utama berikut:
Grafik konteks. Peta dinamis dan terpadu tentang hubungan data dengan bisnis Anda. Hal ini menghubungkan skema teknis dengan entitas bisnis dan pengetahuan tidak terstruktur.
Contoh kueri. Pola SQL terverifikasi yang telah dibuat sebelumnya dan mencakup logika bisnis yang kompleks. Kueri ini memungkinkan agen AI dan manusia mengueri data secara akurat tanpa perlu membuat ulang gabungan tabel yang rumit.
Model Context Protocol (MCP). Standar terbuka yang memungkinkan agen AI menemukan dan menggunakan alat yang tersedia secara adaptif. Knowledge Catalog menggunakan alat MCP untuk menyajikan kebenaran organisasi yang tersertifikasi langsung ke agen, dengan menawarkan server MCP jarak jauh dan lokal untuk mengakomodasi persyaratan aksesibilitas dan keamanan.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
Penyerapan
Knowledge Catalog secara otomatis menyerap metadata dari sumberGoogle Cloud berikut. Untuk beberapa layanan, seperti AlloyDB untuk PostgreSQL dan Cloud SQL, Anda harus mengaktifkan integrasi Knowledge Catalog terlebih dahulu sebelum metadata dapat di-ingest:
Analytics dan lakehouse
- Set data, tabel, tampilan, model, rutin, koneksi, dan set data tertaut BigQuery
- Pertukaran dan listingan BigQuery sharing (sebelumnya Analytics Hub)
- Repositori Dataform dan aset kode
- Layanan, database, dan tabel Dataproc Metastore
Tabel Katalog REST Iceberg (termasuk Google Cloud IRC runtime Lakehouse, IRC Unity Databricks, IRC Katalog Data AWS Glue, dan IRC Horizon Snowflake)
AI dan Machine Learning
- Model, set data, grup fitur, tampilan fitur, dan instance toko online Vertex AI
Business intelligence
- Instance, dasbor, elemen dasbor, Look, project LookML, model, Eksplorasi, dan tampilan Looker (Google Cloud core) (Pratinjau)
Database
- Instance, cluster, dan tabel Bigtable (termasuk detail grup kolom)
- Instance, database, tabel, dan tampilan Spanner
Streaming dan pesan
- Topik Pub/Sub
Data tidak terstruktur
Database operasional
- Cluster, instance, database, skema, tabel, dan tampilan AlloyDB untuk PostgreSQL (Pratinjau). Knowledge Catalog hanya mengambil metadata dari instance utama AlloyDB untuk PostgreSQL, bukan dari replika baca. Untuk informasi selengkapnya, lihat Mengelola resource AlloyDB untuk PostgreSQL menggunakan Knowledge Catalog.
- Instance, database, skema, tabel, tampilan Cloud SQL. Knowledge Catalog hanya mengambil metadata dari instance utama Cloud SQL, bukan dari replika baca. Untuk mengetahui informasi selengkapnya, lihat Mengelola resource Cloud SQL menggunakan Knowledge Catalog.
Untuk mengimpor metadata dari sumber pihak ketiga ke Knowledge Catalog, Anda dapat menggunakan konektor Knowledge Catalog atau pipeline konektivitas terkelola. Untuk mengetahui informasi selengkapnya, lihat Tentang Konektor Knowledge Catalog dan Ringkasan konektivitas terkelola.
Batasan
Saat merencanakan deployment, pertimbangkan batasan berikut:
Integrasi yang didukung. Meskipun Knowledge Catalog mendukung sistem pihak ketiga utama, ekstraksi semantik otomatis tertentu mungkin terbatas pada layanan bawaan Google Cloud .
Batas kuota. Kuota API Google Cloud standar berlaku untuk operasi pengambilan konteks dan ekstraksi metadata.
Langkah berikutnya
Pelajari cara menelusuri aset data.
Pelajari silsilah data.
Pelajari pembuatan profil data.
Pelajari kualitas data otomatis.