
Quando archivi i dati in diversi sistemi di archiviazione, la gestione della sicurezza frammentata può diventare una sfida importante.
Devi assicurarti che le informazioni sensibili, come i registri finanziari, rimangano protette, anche se le archivi in formati aperti come Apache Iceberg nello Google Cloud spazio di archiviazione. Queste protezioni devono essere applicate a diversi motori di query, come BigQuery SQL e Apache Spark.
In questo tutorial, creerai una data lakehouse sicura per risolvere queste sfide. Utilizzando gli script, definirai le policy di sicurezza e vedrai come Knowledge Catalog (in precedenza Dataplex Universal Catalog) e Lakehouse for Apache Iceberg collaborano per applicare le policy a diversi motori di query.
Panoramica dell'architettura
Per configurare un controllo dell'accesso granulare su un formato di tabella aperto come Apache Iceberg, devi creare un'architettura di sicurezza rigorosa e unificata.
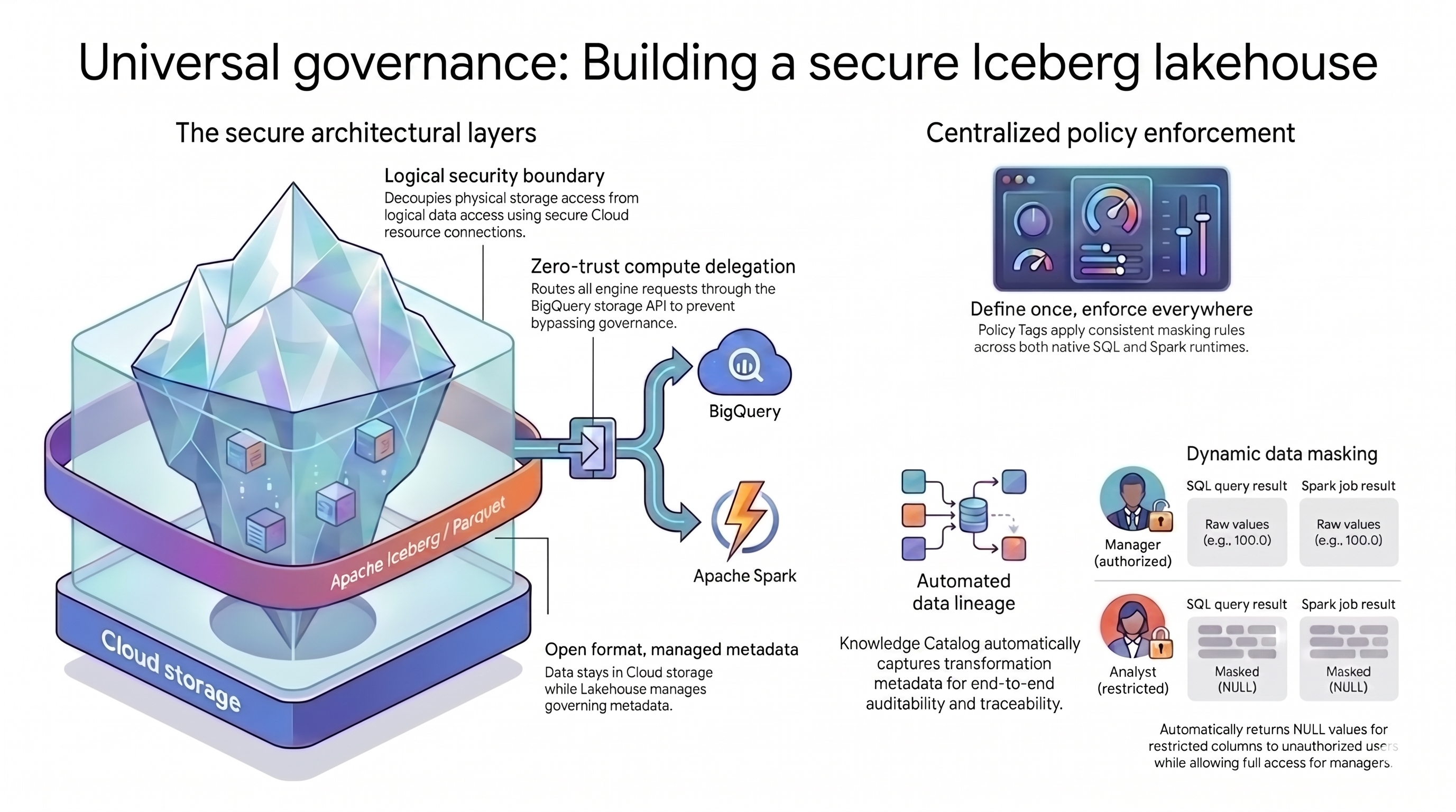
Il pattern lakehouse utilizzato in questo tutorial si basa su due concetti principali per risolvere questa sfida:
- Livelli di architettura sicuri: anziché consentire agli utenti o ai motori di query di accedere direttamente ai bucket Cloud Storage, crei una base sicura a livelli basata sui seguenti attributi:
- Formato aperto con metadati gestiti: i dati rimangono nel formato Apache Iceberg (Parquet) aperto all'interno di Cloud Storage, mentre Lakehouse for Apache Iceberg gestisce i metadati della tabella.
- Limite di sicurezza logico: disaccoppi le autorizzazioni di archiviazione dalle query sui dati utilizzando una connessione alle risorse Cloud sicura. Non concedi mai agli utenti finali l'accesso diretto ai file.
- Delega di calcolo: per impedire ai motori di query di ignorare le regole, indirizzi tutte le richieste di dati tramite l'API BigQuery Storage.
- Applicazione centralizzata delle policy: con una base sicura, Knowledge Catalog funge da control plane unico per l'architettura, applicando le regole in modo universale:
- Definisci una volta, applica ovunque: definisci i tag di policy in Knowledge Catalog una sola volta e la piattaforma applica regole di mascheramento coerenti a tutti i motori di query supportati.
- Mascheramento dinamico dei dati: il sistema valuta l'identità dell'utente durante le query. Gli utenti autorizzati vedono i valori non elaborati, mentre gli utenti con limitazioni ricevono output
NULLin tutti i motori di query. - Derivazione automatica dei dati: Knowledge Catalog monitora automaticamente le trasformazioni dei dati, creando un audit trail senza codice di logging personalizzato.
Obiettivi
- Crea tabelle Apache Iceberg gestite da BigQuery. Lakehouse gestisce i metadati Iceberg.
- Configura regole di sicurezza centrali utilizzando i tag di policy per mascherare e proteggere le colonne sensibili.
- Separa le autorizzazioni di archiviazione fisica dalle query sui dati logici utilizzando una connessione alla risorsa Cloud.
- Instrada le query in modo sicuro tramite Managed Service for Apache Spark in modo che i motori esterni non possano ignorare le regole di sicurezza.
- Esplora una mappa interattiva dei tuoi dati utilizzando la derivazione dei dati.
Prima di iniziare
Prima di iniziare, segui questi passaggi:
- Seleziona un Google Cloud progetto per questo tutorial.
- Verifica che la fatturazione sia attivata per il tuo progetto.
Prepara l'ambiente
Questo tutorial utilizza Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella Google Cloud console, fai clic sull'icona Cloud Shell nella barra degli strumenti in alto a destra.
Imposta le variabili del progetto:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"Definisci le variabili per due utenti tipo, un analista di vendita al dettaglio e un responsabile di vendita al dettaglio:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)Abilita leAPI richieste Google Cloud .
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
Scarica il codice sorgente del tutorial
Scarica gli script Python per questo tutorial dal Google Cloud repository DevRel:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Crea un bucket di archiviazione
Crea un nuovo bucket per contenere i file delle tabelle Iceberg:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Prepara identità e sicurezza
In questo passaggio, configurerai la delega di calcolo creando una connessione alla risorsa Cloud. Questa connessione funge da identità delegata sicura che BigQuery utilizza per gestire e leggere i file Iceberg. In questo modo, gli utenti singoli non hanno mai accesso diretto al bucket Cloud Storage.
Esegui i seguenti comandi per creare la connessione, recuperare il account di servizio generato automaticamente e concedere a questo account le autorizzazioni necessarie per gestire i dati Iceberg:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Crea service account per due utenti tipo: Analista e Responsabile. I seguenti comandi configurano questi service account, consentono all'utente corrente di simulare l'identità per i test e concedono loro ruoli specifici per eseguire query e visualizzare i dati.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Crea tabelle Apache Iceberg
Utilizza il motore BigQuery SQL per creare tabelle Apache Iceberg. Sebbene tu esegua i comandi di creazione con BigQuery, Lakehouse funge da livello di gestione che archivia i metadati della tabella e protegge i file Parquet sottostanti in Cloud Storage.
Dopo aver creato le tabelle, esegui una trasformazione rapida per vedere come Knowledge Catalog gestisce la sicurezza e monitora automaticamente il percorso dei dati.
Crea un set di dati BigQuery
Innanzitutto, crea un set di dati BigQuery per raggruppare le tabelle:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Crea le tabelle Iceberg
Esegui i seguenti comandi per creare le tabelle di inventario e transazioni:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Inserisci dati di esempio
Inserisci dati di esempio nelle tabelle:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Ora hai due tabelle Iceberg con dati di esempio non elaborati. Lakehouse gestisce i metadati, ma i file Parquet effettivi si trovano nel bucket Cloud Storage.
Trasforma i dati per la derivazione automatica
Aggrega le transazioni non elaborate in un riepilogo delle vendite giornaliere. Questa trasformazione crea una nuova tabella e genera i metadati che Knowledge Catalog utilizza per mappare automaticamente il percorso dei dati.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Definisci le policy utilizzando Python
In un ambiente di produzione, la scrittura delle regole di sicurezza come codice (infrastruttura come codice) rende le policy ripetibili, con controllo delle versioni e più facili da gestire. In questa sezione, utilizzerai l'SDK Google Cloud Python per definire e applicare automaticamente le regole di governance.
Prepara l'ambiente virtuale Python
Configura un ambiente virtuale Python isolato per gestire le dipendenze e assicurarti che gli script di governance vengano eseguiti in modo affidabile:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Definisci tassonomie e tag di sicurezza
Inizia creando la base per le regole di sicurezza. In questo passaggio, creerai una tassonomia che fungerà da contenitore e un tag di policy che fungerà da etichetta di sicurezza specifica per i dati sensibili.
Esegui lo script per creare le risorse:
python 1_create_taxonomy.py
Esamina 1_create_taxonomy.py per visualizzare la logica principale:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Impostando esplicitamente il tipo di policy FINE_GRAINED_ACCESS_CONTROL, trasformi un tag di metadati standard in un limite di sicurezza rigoroso con negazione predefinita. Per impostazione predefinita, qualsiasi colonna con questo tag nega l'accesso a tutti gli utenti.
Crea una policy di mascheramento dinamico dei dati
Ora, definisci cosa succede quando qualcuno senza privilegi esegue una query su una colonna con tag. Crea una policy di mascheramento dei dati che sostituisce automaticamente i valori sensibili con NULL per l'utente tipo Analista.
Esegui lo script per configurare la regola di mascheramento:
python 2_create_masking.py
All'interno di 2_create_masking.py, lo script cerca l'ID del tag di criteri creato e applica la policy dei dati al account di servizio Analista:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Concedi l'accesso con privilegi ai dati
A causa della configurazione con negazione predefinita, nessuno può leggere la colonna con tag. Devi concedere esplicitamente l'accesso agli utenti autorizzati. Concedi all'utente tipo Responsabile e al tuo account il ruolo Lettore granulare. In questo modo, questi utenti specifici possono ignorare le regole di mascheramento e leggere i dati non mascherati.
Esegui lo script per concedere l'accesso:
python 3_grant_access.py
All'interno di 3_grant_access.py, lo script modifica la policy IAM del tag di policy:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Collega i tag di sicurezza allo schema della tabella
Infine, puoi collegare le regole logiche ai dati effettivi. Aggiorna lo schema della tabella Iceberg per collegare il tag di criteri direttamente alla colonna amount. Dopo aver eseguito questa operazione, Lakehouse applica immediatamente le protezioni ai file della tabella Iceberg nel bucket.
Esegui lo script per collegare il tag di criteri:
python 4_attach_tag.py
Esamina 4_attach_tag.py. Lo script recupera lo schema della tabella BigQuery, scorre i campi e collega il tag in modo specifico alla colonna amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Verifica le policy di sicurezza
Esegui alcune query di test per assicurarti che le autorizzazioni funzionino come previsto. Per dimostrare che Lakehouse applica le stesse policy di sicurezza quando cambi motore di query, esegui questi test utilizzando sia BigQuery sia Apache Spark.
Esegui il test con BigQuery SQL
Inizia controllando le policy direttamente in BigQuery. È il modo più veloce per verificare che le regole di mascheramento e le autorizzazioni siano attive.
Esegui il controllo come Responsabile
L'utente tipo Responsabile ha accesso in lettura granulare con privilegi. Dovrebbe vedere ogni dettaglio della tabella, inclusi i valori nella colonna amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Poiché il responsabile ha il ruolo Lettore granulare, la query mostra i valori dell'importo non elaborati:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Esegui il controllo come Analista
Passa all'utente tipo Analista ed esegui la stessa query.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Anche se esegui la stessa query, Knowledge Catalog maschera i valori sensibili nella colonna amount:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Torna al tuo account
Pulisci lo stato di autenticazione di Cloud Shell per tornare all'utente amministratore.
gcloud config unset auth/impersonate_service_account
Esegui il test con Apache Spark
La sicurezza spesso si interrompe quando gli utenti accedono direttamente ai file di dati in Cloud Storage. Se un data scientist utilizza Apache Spark per leggere direttamente i file della tabella Iceberg, in genere ignora le regole perché Cloud Storage comprende solo le autorizzazioni a livello di bucket.
Per evitare questo problema, utilizza la delega di calcolo. Utilizzando il connettore Spark-BigQuery, crei un bridge sicuro che instrada tutte le richieste Spark tramite l'API BigQuery Storage. In questo modo, Knowledge Catalog controlla le autorizzazioni e applica le regole di mascheramento prima che i dati raggiungano il cluster Spark.
Carica lo script read_transactions.py nel bucket Cloud Storage in modo che Managed Service for Apache Spark possa accedervi:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Esamina la logica principale nello script che hai caricato:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Lo script non indirizza Spark al percorso gs:// dei file Iceberg. Specificando .format("bigquery"), l'API BigQuery Storage intercetta la richiesta di lettura, controlla l'identità dell'utente che esegue il job Spark, applica le regole di mascheramento di Knowledge Catalog e restituisce solo i dati autorizzati a Spark DataFrame.
Esegui Spark come Responsabile
Invia un job Spark come utente tipo Responsabile. Utilizza Managed Service for Apache Spark, un servizio gestito che ti consente di eseguire carichi di lavoro Spark senza la difficoltà di gestire i tuoi cluster:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Esamina i log di output del job nel terminale. Poiché il responsabile ha il ruolo Lettore granulare, Spark recupera correttamente gli importi non mascherati:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Esegui Spark come Analista
Infine, esegui lo stesso codice Spark come utente tipo Analista:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Esamina di nuovo i log. Anche se l'analista ha eseguito lo stesso codice Spark, l'API BigQuery Storage ha intercettato la richiesta e applicato la policy di Knowledge Catalog. Spark DataFrame dell'analista mostra null per gli importi.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Scegli il motore giusto: BigQuery SQL o Apache Spark
Hai appena dimostrato che Knowledge Catalog applica la policy indipendentemente dal motore di query utilizzato. Ma quando passi alla produzione, come scegli lo strumento giusto?
- BigQuery SQL: utilizzalo per analisi rapide e business intelligence. È la scelta migliore quando SQL è la lingua principale perché esegue i calcoli direttamente dove si trovano i dati.
- Apache Spark: scegli Spark per attività più complesse che richiedono Python. Spark funziona meglio per le pipeline di machine learning o quando devi importare codice Hadoop legacy nella tua lakehouse.
Visualizza il percorso dei dati con la derivazione automatica
La derivazione dei dati ti aiuta a capire da dove provengono i dati e come vengono trasformati. Rispondere a domande essenziali come "Quali tabelle non elaborate sono state utilizzate per generare questo report sulle vendite?" ti aiuta a mantenere la conformità, eseguire rapidamente il debug delle pipeline di dati e creare una base di dati affidabile.
Anziché scrivere manualmente codice di logging complesso, Lakehouse monitora automaticamente questo ciclo di vita. Ad esempio, quando hai creato la tabella di riepilogo in precedenza in questo tutorial, BigQuery ha acquisito immediatamente i dettagli della trasformazione e li ha inviati a Knowledge Catalog.
Esplora il grafico di derivazione interattivo
Dai un'occhiata alla mappa interattiva generata da Knowledge Catalog. Mostra come i dati non elaborati vengono trasferiti dalla tabella transactions alla tabella transactions_summary. In questo modo, ottieni la tracciabilità end-to-end necessaria per un audit dei dati.
- Nella Google Cloud console, vai a Knowledge Catalog > Ricerca.
- Digita
lakehouse_retail_demo.transactions_summarynella barra di ricerca e fai clic sulla tabella. - Fai clic sulla scheda Derivazione.
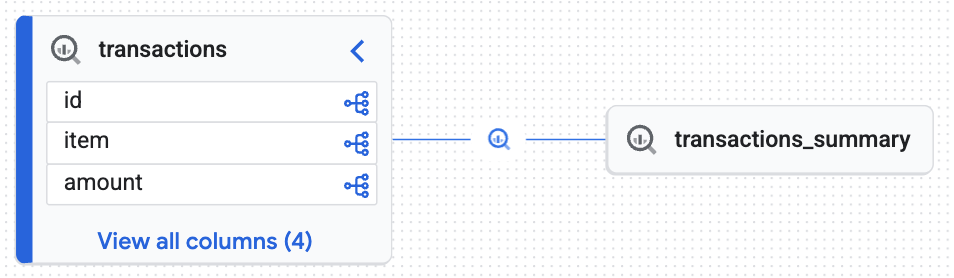
Il grafico interattivo conferma che la tabella di destinazione (transactions_summary) deriva dalla tabella Iceberg non elaborata con governance (transactions). Questa visualizzazione mostra la tracciabilità end-to-end dei dati.
Libera spazio
Per evitare addebiti continui, rimuovi le risorse che hai creato per questo tutorial.
Elimina le risorse di governance
Prima di poter eliminare il set di dati BigQuery o il bucket Cloud Storage, devi eliminare le regole di governance.
Esegui lo script di pulizia Python:
python cleanup_governance.py
Esamina lo script cleanup_governance.py dal repository per trovare la seguente logica di eliminazione. L'ordine di eliminazione è fondamentale. Innanzitutto, elimini la policy di mascheramento dei dati. Poi, elimini la tassonomia principale, che rimuove automaticamente tutti i tag di policy sottostanti ed evita errori di dipendenza delle risorse.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Rimuovi identità, spazio di archiviazione e asset di calcolo
Elimina le tabelle BigQuery, i bucket Cloud Storage, i service account e l'ambiente virtuale Python locale.
Copia ed esegui il seguente script di pulizia in Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
Libera spazio nei file del progetto:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
Conclusione
Hai creato correttamente una data lakehouse sicura. Utilizzando Lakehouse for Apache Iceberg per gestire le tabelle Iceberg, hai mantenuto i file delle tabelle sottostanti al sicuro in Cloud Storage. Hai definito i tag di policy in un'unica posizione centrale e li hai applicati in modo universale a diversi motori di query. Infine, hai monitorato automaticamente l'intero percorso dei dati con la derivazione dei dati in tempo reale.
Passaggi successivi
- Managed Service for Apache Spark: scopri come scalare le pipeline di dati senza eseguire il provisioning dei cluster nella pagina della documentazione di Spark serverless.
- Esplora il controllo dell'accesso avanzato: per implementare scenari di sicurezza più complessi, consulta la documentazione ufficiale sulla personalizzazione di Lakehouse con funzionalità aggiuntive.
- Governa i dati non strutturati per l'AI generativa: scopri le tabelle di oggetti. Estendi questo pattern di bridge sicuro ai file non strutturati (PDF, immagini) in Cloud Storage, creando una base di dati sicura e con governance per Vertex AI e le pipeline RAG.
- Prova altri casi d'uso: prova altri casi d'uso di Knowledge Catalog .