
Saat Anda menyimpan data di berbagai sistem penyimpanan, mengelola keamanan yang terfragmentasi dapat menjadi tantangan besar.
Anda ingin memastikan informasi sensitif, seperti catatan keuangan, tetap terlindungi, meskipun Anda menyimpannya dalam format terbuka seperti Apache Iceberg di Google Cloud penyimpanan. Anda memerlukan perlindungan ini untuk diterapkan di berbagai mesin kueri, seperti BigQuery SQL dan Apache Spark.
Dalam tutorial ini, Anda akan membangun lakehouse data yang aman untuk mengatasi tantangan ini. Dengan menggunakan skrip, Anda akan menentukan kebijakan keamanan dan melihat Knowledge Catalog (sebelumnya Dataplex Universal Catalog) dan Lakehouse untuk Apache Iceberg bekerja sama untuk menerapkan kebijakan di berbagai mesin kueri.
Ringkasan arsitektur
Untuk menyiapkan kontrol akses terperinci pada format tabel terbuka seperti Apache Iceberg, Anda harus membuat arsitektur keamanan terpadu yang ketat.
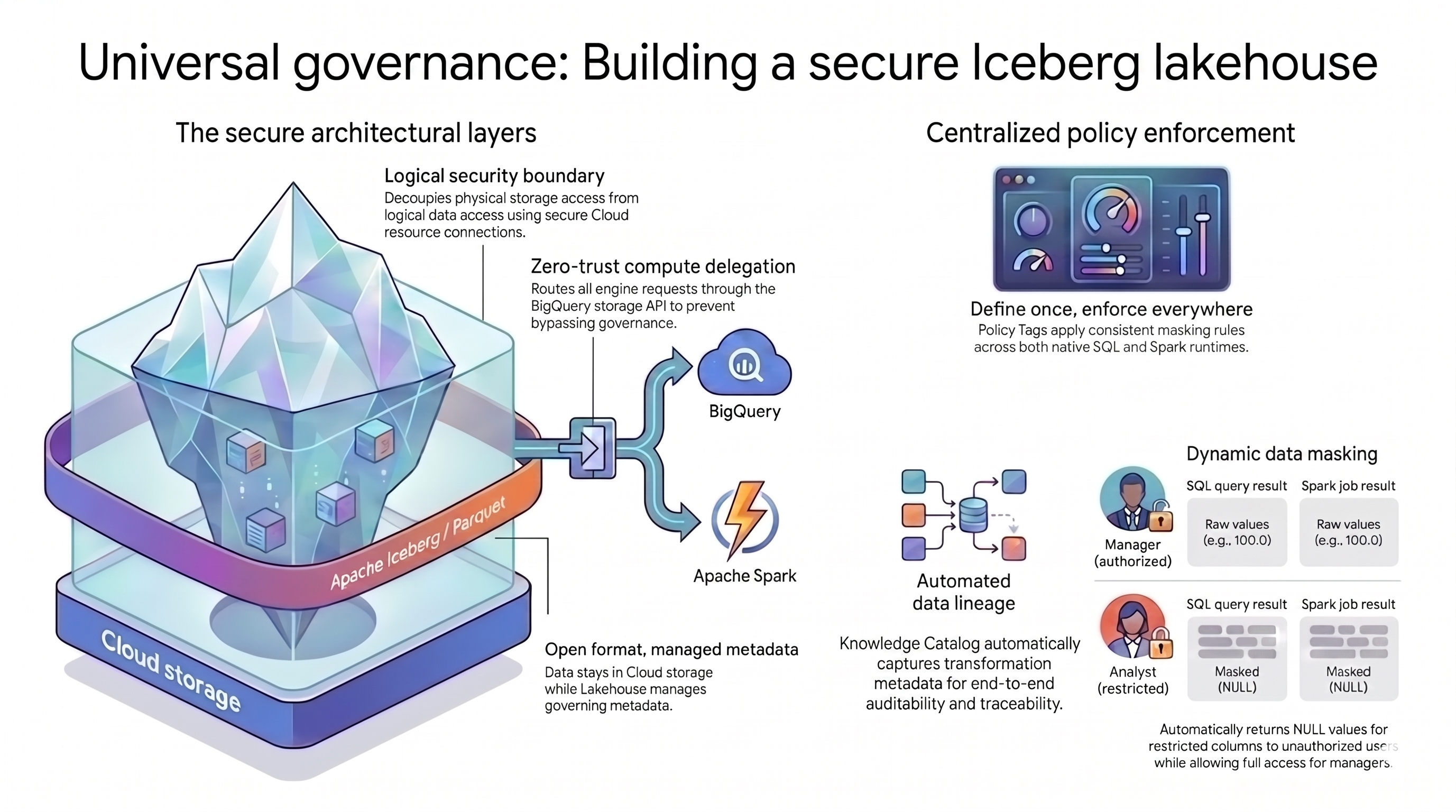
Pola lakehouse yang Anda gunakan dalam tutorial ini mengandalkan dua konsep utama untuk mengatasi tantangan ini:
- Lapisan arsitektur yang aman: Daripada mengizinkan pengguna atau mesin kueri mengakses bucket Cloud Storage Anda secara langsung, Anda akan membangun fondasi berlapis yang aman berdasarkan atribut berikut:
- Format terbuka dengan metadata terkelola: Data Anda tetap dalam format Apache Iceberg (Parquet) terbuka di dalam Cloud Storage, sementara Lakehouse untuk Apache Iceberg mengelola metadata tabel.
- Batas keamanan logis: Anda memisahkan izin penyimpanan dari kueri data menggunakan koneksi resource Cloud yang aman. Anda tidak pernah memberikan akses langsung ke file kepada pengguna akhir.
- Delegasi komputasi: Untuk mencegah mesin kueri melewati aturan Anda, Anda akan merutekan semua permintaan data melalui BigQuery Storage API.
- Penerapan kebijakan terpusat: Dengan fondasi yang aman, Knowledge Catalog bertindak sebagai satu-satunya bidang kontrol untuk arsitektur, yang menerapkan aturan secara universal:
- Tentukan sekali, terapkan di mana saja: Anda menentukan tag kebijakan di Knowledge Catalog hanya sekali, dan platform akan menerapkan aturan penyamaran yang konsisten di semua mesin kueri yang didukung.
- Penyamaran data dinamis: Sistem mengevaluasi identitas pengguna selama kueri. Pengguna yang diotorisasi akan melihat nilai mentah, sementara pengguna yang dibatasi akan menerima output
NULLdi semua mesin kueri. - Silsilah data otomatis: Knowledge Catalog melacak transformasi data secara otomatis, sehingga membuat jejak audit tanpa kode logging kustom.
Tujuan
- Membuat tabel Apache Iceberg yang dikelola oleh BigQuery. Lakehouse mengelola metadata Iceberg.
- Menyiapkan aturan keamanan pusat menggunakan tag kebijakan untuk menyamarkan dan melindungi kolom sensitif.
- Memisahkan izin penyimpanan fisik dari kueri data logis menggunakan koneksi resource Cloud.
- Merutekan kueri dengan aman melalui Managed Service untuk Apache Spark sehingga mesin eksternal tidak dapat melewati aturan keamanan Anda.
- Mempelajari peta interaktif data Anda menggunakan silsilah data.
Sebelum memulai
Sebelum memulai, lakukan hal berikut:
- Pilih Google Cloud project untuk tutorial ini.
- Konfirmasi bahwa penagihan diaktifkan untuk project Anda.
Menyiapkan lingkungan Anda
Tutorial ini menggunakan Cloud Shell, lingkungan command line yang berjalan di cloud.
Dari Google Cloud Konsol, klik ikon Cloud Shell di toolbar kanan atas.
Tetapkan variabel project Anda:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"Tentukan variabel untuk dua persona pengguna, analis retail dan pengelola retail:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)AktifkanAPI yang diperlukan Google Cloud .
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
Mendownload kode sumber tutorial
Download skrip Python untuk tutorial ini dari repositori Google Cloud DevRel:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Membuat bucket penyimpanan
Buat bucket baru untuk menyimpan file tabel Iceberg:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Menyiapkan identitas dan keamanan
Pada langkah ini, Anda akan menyiapkan delegasi komputasi dengan membuat koneksi resource Cloud. Koneksi ini bertindak sebagai identitas yang didelegasikan dan aman yang digunakan BigQuery untuk mengelola dan membaca file Iceberg Anda. Hal ini membantu memastikan bahwa setiap pengguna tidak pernah memiliki akses langsung ke bucket Cloud Storage Anda.
Jalankan perintah berikut untuk membuat koneksi, mengambil akun layanan yang dibuat secara otomatis, dan memberikan izin yang diperlukan akun tersebut untuk mengelola data Iceberg Anda:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Buat akun layanan untuk dua persona: Analis dan Pengelola. Perintah berikut menyiapkan akun layanan ini, mengizinkan pengguna saat ini untuk meniru akun tersebut untuk pengujian, dan memberikan peran tertentu kepada akun tersebut untuk menjalankan kueri dan melihat data.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Membuat tabel Apache Iceberg
Gunakan mesin BigQuery SQL untuk membuat tabel Apache Iceberg. Meskipun Anda menjalankan perintah pembuatan dengan BigQuery, Lakehouse bertindak sebagai lapisan pengelolaan yang menyimpan metadata tabel dan mengamankan file Parquet yang mendasarinya di Cloud Storage.
Setelah membuat tabel, Anda akan menjalankan transformasi cepat untuk melihat cara Knowledge Catalog menangani keamanan dan melacak perjalanan data Anda secara otomatis.
Membuat set data BigQuery
Pertama, buat set data BigQuery untuk mengelompokkan tabel Anda:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Membuat tabel Iceberg
Jalankan perintah berikut untuk membuat tabel inventaris dan transaksi:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Menyisipkan data sampel
Sisipkan data sampel ke dalam tabel:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Sekarang Anda memiliki dua tabel Iceberg dengan data sampel mentah. Lakehouse mengelola metadata, tetapi file Parquet sebenarnya ada di bucket Cloud Storage Anda.
Mengubah data untuk silsilah otomatis
Agregasi transaksi mentah Anda ke dalam ringkasan penjualan harian. Transformasi ini membuat tabel baru dan menghasilkan metadata yang digunakan Knowledge Catalog untuk memetakan perjalanan data Anda secara otomatis.
Google Cloudecho "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Menentukan kebijakan menggunakan Python
Di lingkungan produksi, menulis aturan keamanan sebagai kode (infrastruktur sebagai kode) membuat kebijakan Anda dapat diulang, dikontrol versinya, dan lebih mudah dikelola. Di bagian ini, Anda akan menggunakan Google Cloud Python SDK untuk menentukan dan menerapkan aturan tata kelola secara otomatis.
Menyiapkan lingkungan virtual Python
Siapkan lingkungan virtual Python yang terisolasi untuk mengelola dependensi dan memastikan skrip tata kelola Anda berjalan dengan andal:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Menentukan taksonomi dan tag keamanan
Mulailah dengan membangun fondasi untuk aturan keamanan Anda. Pada langkah ini, Anda akan membuat taksonomi untuk bertindak sebagai penampung dan tag kebijakan untuk berfungsi sebagai label keamanan tertentu untuk data sensitif.
Jalankan skrip untuk membuat resource:
python 1_create_taxonomy.py
Tinjau 1_create_taxonomy.py untuk melihat logika inti:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Dengan menetapkan jenis kebijakan FINE_GRAINED_ACCESS_CONTROL secara eksplisit, Anda akan mengubah tag metadata standar menjadi batas keamanan tolak-berdasarkan-default yang ketat. Secara default, kolom apa pun dengan tag ini akan menolak akses ke semua pengguna.
Membuat kebijakan penyamaran data dinamis
Sekarang, tentukan apa yang terjadi saat seseorang tanpa hak istimewa melakukan kueri kolom yang diberi tag. Buat kebijakan penyamaran data yang secara otomatis mengganti nilai sensitif dengan NULL untuk persona Analis.
Jalankan skrip untuk mengonfigurasi aturan penyamaran:
python 2_create_masking.py
Di dalam 2_create_masking.py, skrip akan mencari ID untuk tag kebijakan yang Anda buat dan menerapkan kebijakan data ke akun layanan Analis:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Memberikan akses istimewa ke data Anda
Karena penyiapan tolak-berdasarkan-default, tidak ada yang dapat membaca kolom yang diberi tag. Anda harus memberikan akses secara eksplisit kepada pengguna yang diotorisasi. Berikan peran Fine-Grained Reader kepada persona Pengelola dan akun Anda sendiri. Hal ini memungkinkan pengguna tertentu ini melewati aturan penyamaran dan membaca data yang tidak disamarkan.
Jalankan skrip untuk memberikan akses:
python 3_grant_access.py
Di dalam 3_grant_access.py, skrip akan mengubah kebijakan IAM tag kebijakan:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Melampirkan tag keamanan ke skema tabel
Terakhir, Anda dapat menghubungkan aturan logis ke data sebenarnya. Perbarui skema tabel Iceberg untuk melampirkan tag kebijakan langsung ke kolom amount. Setelah melakukannya, Lakehouse akan langsung menerapkan perlindungan Anda di seluruh file tabel Iceberg di bucket Anda.
Jalankan skrip untuk melampirkan tag kebijakan:
python 4_attach_tag.py
Tinjau 4_attach_tag.py. Skrip mengambil skema tabel BigQuery, melakukan iterasi melalui kolom, dan melampirkan tag secara khusus ke kolom amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Memverifikasi kebijakan keamanan
Jalankan beberapa kueri pengujian untuk memastikan izin Anda berfungsi seperti yang diharapkan. Untuk membuktikan bahwa Lakehouse menerapkan kebijakan keamanan yang sama saat Anda beralih mesin kueri, Anda akan menjalankan pengujian ini menggunakan BigQuery dan Apache Spark.
Menguji dengan BigQuery SQL
Mulailah dengan memeriksa kebijakan Anda langsung di BigQuery. Ini adalah cara tercepat untuk mengonfirmasi bahwa aturan dan izin penyamaran Anda aktif.
Memeriksa sebagai Pengelola
Persona Pengelola memiliki akses pembaca terperinci dan istimewa. Mereka akan melihat setiap detail dalam tabel, termasuk nilai di kolom amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Karena pengelola memiliki peran Fine-Grained Reader, kueri akan menampilkan nilai jumlah mentah:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Memeriksa sebagai Analis
Beralihlah ke persona Analis dan jalankan kueri yang sama.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Meskipun Anda menjalankan kueri yang sama, Knowledge Catalog akan menyamarkan nilai sensitif di kolom amount:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Kembali ke akun Anda
Kosongkan status autentikasi Cloud Shell Anda untuk kembali ke pengguna administrator.
gcloud config unset auth/impersonate_service_account
Menguji dengan Apache Spark
Keamanan sering kali terganggu saat pengguna langsung membuka file data di Cloud Storage. Jika ilmuwan data menggunakan Apache Spark untuk membaca file tabel Iceberg secara langsung, mereka biasanya akan melewati aturan Anda karena Cloud Storage hanya memahami izin tingkat bucket.
Untuk mencegah hal ini, gunakan delegasi komputasi. Dengan menggunakan Konektor Spark-BigQuery, Anda akan membuat jembatan aman yang merutekan semua permintaan Spark melalui BigQuery Storage API. Hal ini memastikan Knowledge Catalog memeriksa izin dan menerapkan aturan penyamaran sebelum data mencapai cluster Spark.
Upload skrip read_transactions.py ke bucket Cloud Storage Anda sehingga Managed Service untuk Apache Spark dapat mengaksesnya:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Tinjau logika inti dalam skrip yang Anda upload:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Skrip tidak mengarahkan Spark ke jalur gs:// file Iceberg. Dengan menentukan .format("bigquery"), BigQuery Storage API akan mencegat permintaan baca, memeriksa identitas pengguna yang menjalankan tugas Spark, menerapkan aturan penyamaran Knowledge Catalog, dan hanya menampilkan data yang diotorisasi ke Spark DataFrame.
Menjalankan Spark sebagai Pengelola
Kirim tugas Spark sebagai persona Pengelola. Gunakan Managed Service untuk Apache Spark, layanan terkelola yang memungkinkan Anda menjalankan workload Spark tanpa perlu mengelola cluster sendiri:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Tinjau log output tugas di terminal. Karena pengelola memiliki peran Fine-Grained Reader, Spark berhasil mengambil jumlah yang tidak disamarkan:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Menjalankan Spark sebagai Analis
Terakhir, jalankan kode Spark yang sama sebagai persona Analis:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Tinjau log lagi. Meskipun Analis menjalankan kode Spark yang sama, BigQuery Storage API mencegat permintaan dan menerapkan kebijakan Knowledge Catalog. Spark DataFrame Analis menampilkan null untuk jumlah.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Memilih mesin yang tepat: BigQuery SQL versus Apache Spark
Anda baru saja membuktikan bahwa Knowledge Catalog menerapkan kebijakan Anda, terlepas dari mesin kueri yang Anda gunakan. Namun, saat Anda beralih ke produksi, bagaimana cara memilih alat yang tepat?
- BigQuery SQL: Gunakan ini untuk analisis dan business intelligence yang cepat. Ini adalah pilihan terbaik jika SQL adalah bahasa utama Anda karena menjalankan komputasi langsung di tempat data berada.
- Apache Spark: Pilih Spark untuk tugas yang lebih kompleks yang memerlukan Python. Spark berfungsi paling baik untuk pipeline machine learning atau saat Anda perlu memasukkan kode Hadoop lama ke lakehouse Anda.
Melihat perjalanan data Anda dengan silsilah otomatis
Silsilah data membantu Anda memahami asal data dan cara data diubah. Menjawab pertanyaan penting seperti, "Tabel mentah mana yang digunakan untuk membuat laporan penjualan ini?" membantu Anda mempertahankan kepatuhan, men-debug pipeline data dengan cepat, dan membangun fondasi data yang andal.
Daripada menulis kode logging yang kompleks secara manual, Lakehouse akan melacak siklus proses ini secara otomatis. Misalnya, saat Anda membuat tabel ringkasan sebelumnya dalam tutorial ini, BigQuery akan langsung mengambil detail transformasi dan mengirimkannya ke Knowledge Catalog.
Mempelajari grafik silsilah interaktif
Lihat peta interaktif yang dihasilkan Knowledge Catalog. Peta ini menunjukkan cara data mentah mengalir dari tabel transactions ke tabel transactions_summary. Hal ini memberikan keterlacakan menyeluruh yang Anda butuhkan untuk audit data.
- Di Google Cloud Konsol, buka Knowledge Catalog > Search.
- Ketik
lakehouse_retail_demo.transactions_summarydi kotak penelusuran, lalu klik tabel. - Klik tab Lineage.
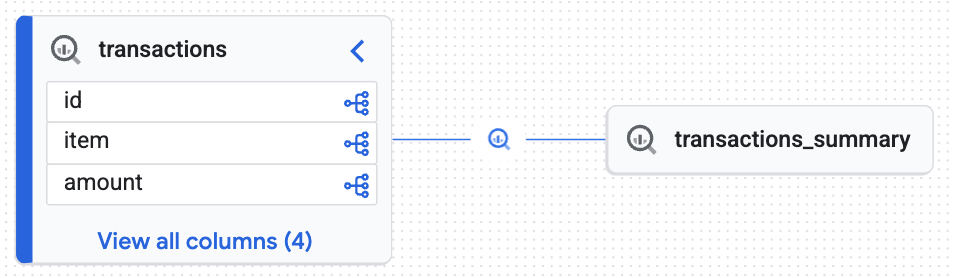
Grafik interaktif mengonfirmasi bahwa tabel target (transactions_summary) berasal dari tabel Iceberg yang dikelola mentah (transactions). Visualisasi ini menunjukkan keterlacakan menyeluruh data Anda.
Pembersihan
Untuk mencegah biaya berkelanjutan, hapus resource yang Anda buat untuk tutorial ini.
Menghapus resource tata kelola
Sebelum dapat menghapus set data BigQuery atau bucket Cloud Storage, Anda harus menghapus aturan tata kelola.
Jalankan skrip pembersihan Python:
python cleanup_governance.py
Tinjau skrip cleanup_governance.py dari repositori untuk menemukan logika penghapusan berikut. Urutan penghapusan sangat penting. Pertama, Anda menghapus kebijakan penyamaran data. Kemudian, Anda menghapus taksonomi induk, yang secara otomatis menghapus semua tag kebijakan yang mendasarinya dan menghindari error dependensi resource.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Menghapus aset identitas, penyimpanan, dan komputasi
Hapus tabel BigQuery, bucket Cloud Storage, akun layanan, dan lingkungan virtual Python lokal.
Salin dan jalankan skrip pembersihan berikut di Cloud Shell Anda:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
Bersihkan file project:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
Kesimpulan
Anda telah berhasil membangun lakehouse data yang aman. Dengan menggunakan Lakehouse untuk Apache Iceberg guna mengelola tabel Iceberg, Anda menjaga keamanan file tabel yang mendasarinya di Cloud Storage. Anda menentukan tag kebijakan di satu lokasi pusat dan menerapkannya secara universal di berbagai mesin kueri. Terakhir, Anda melacak seluruh perjalanan data secara otomatis dengan silsilah data real-time.
Langkah berikutnya
- Managed Service untuk Apache Spark: Temukan cara menskalakan pipeline data Anda tanpa menyediakan cluster di halaman dokumentasi Spark Serverless.
- Pelajari kontrol akses lanjutan: Untuk menerapkan skenario keamanan yang lebih kompleks, tinjau dokumentasi resmi tentang cara menyesuaikan Lakehouse dengan fitur tambahan.
- Mengatur data tidak terstruktur untuk GenAI: Temukan Tabel Objek. Perluas pola jembatan aman ini ke file tidak terstruktur (PDF, gambar) di Cloud Storage, sehingga membangun fondasi data yang aman dan dikelola untuk pipeline Vertex AI dan RAG.
- Coba kasus penggunaan lainnya: Coba kasus penggunaan Knowledge Catalog lainnya.