
כשמאחסנים את הנתונים במערכות אחסון שונות, ניהול האבטחה המפוצלת יכול להפוך לאתגר משמעותי.
אתם רוצים לוודא שמידע רגיש, כמו רשומות פיננסיות, יישאר מוגן, גם אם אתם מאחסנים אותו בפורמטים פתוחים כמו Apache Iceberg בGoogle Cloud אחסון. אתם צריכים את אמצעי ההגנה האלה כדי להחיל אותם על מנועי שאילתות שונים, כמו BigQuery SQL ו-Apache Spark.
במדריך הזה תלמדו איך לבנות lakehouse מאובטח כדי לפתור את האתגרים האלה. באמצעות סקריפטים, אתם מגדירים מדיניות אבטחה ורואים איך Knowledge Catalog (לשעבר Dataplex Universal Catalog) ו-Lakehouse for Apache Iceberg פועלים יחד כדי לאכוף את המדיניות במנועי שאילתות שונים.
סקירה כללית של הארכיטקטורה
כדי להגדיר בקרת גישה מפורטת בפורמט טבלה פתוח כמו Apache Iceberg, צריך ליצור ארכיטקטורת אבטחה קפדנית ומאוחדת.
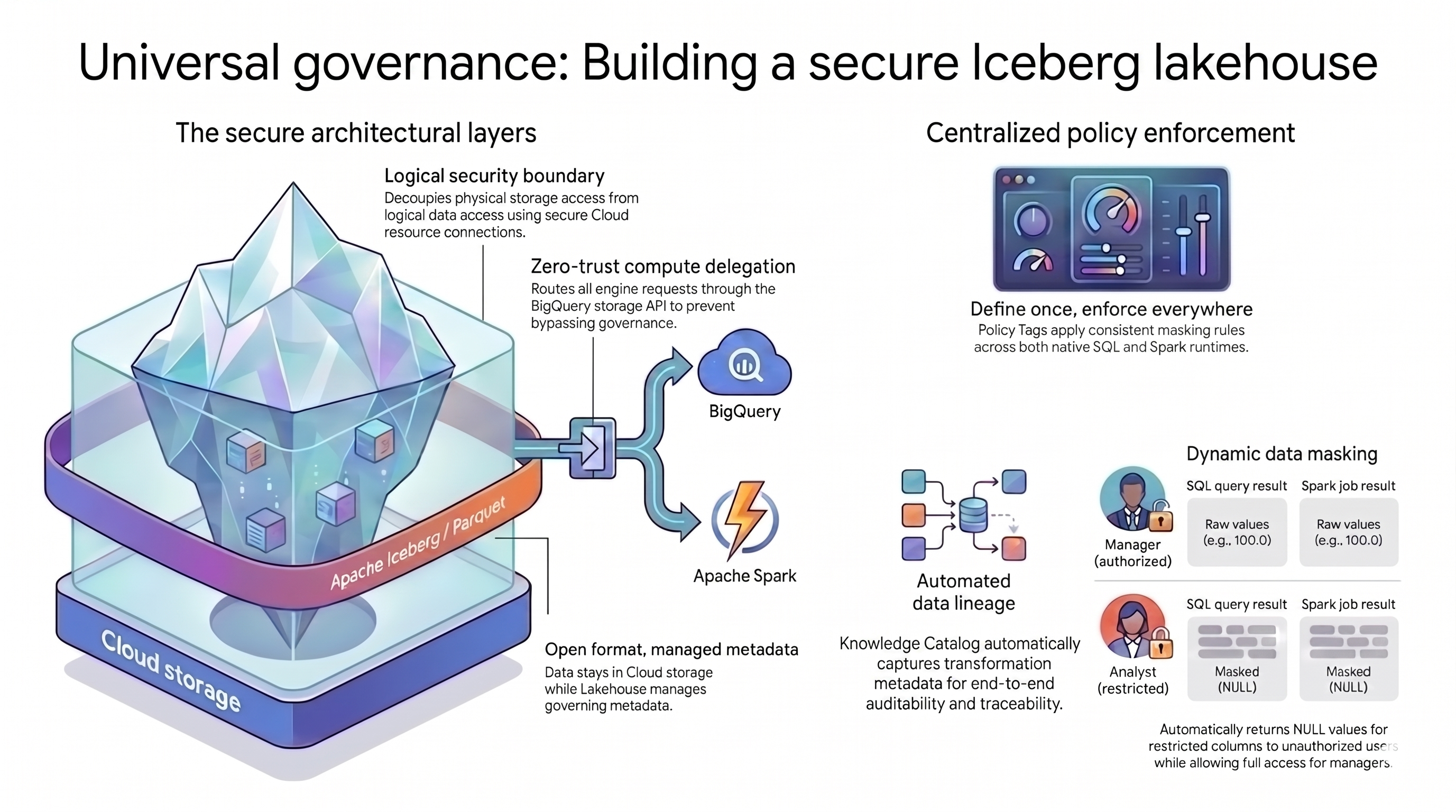
הדפוס של אגם הנתונים שבו משתמשים במדריך הזה מסתמך על שני מושגים עיקריים כדי לפתור את האתגר הזה:
- שכבות ארכיטקטוניות מאובטחות: במקום לאפשר למשתמשים או למנועי שאילתות לגשת ישירות לקטגוריות של Cloud Storage, אתם יכולים לבנות בסיס מאובטח ושכבתי שמבוסס על המאפיינים הבאים:
- פורמט פתוח עם מטא-נתונים מנוהלים: הנתונים נשארים בפורמט הפתוח שלהם Apache Iceberg (Parquet) בתוך Cloud Storage, בזמן ש-Lakehouse for Apache Iceberg מנהל את המטא-נתונים של הטבלה.
- גבול אבטחה לוגי: אתם מפרידים בין הרשאות אחסון לבין שאילתות נתונים באמצעות חיבור מאובטח למשאב Cloud. לעולם לא מעניקים למשתמשי קצה גישה ישירה לקבצים.
- העברת הרשאות לחישוב: כדי למנוע ממנועי שאילתות לעקוף את הכללים, אתם מנתבים את כל בקשות הנתונים דרך BigQuery Storage API.
- אכיפת מדיניות מרכזית: לאחר הקמת בסיס מאובטח, Knowledge Catalog משמש כמישור הבקרה היחיד של הארכיטקטורה, ומחיל כללים באופן אוניברסלי:
- הגדרה פעם אחת, אכיפה בכל מקום: מגדירים תגי מדיניות ב-Knowledge Catalog רק פעם אחת, והפלטפורמה מחילה כללי מיסוך עקביים בכל מנועי השאילתות הנתמכים.
- הסתרת נתונים דינמית: המערכת מעריכה את זהות המשתמש במהלך שאילתות. משתמשים מורשים רואים ערכים גולמיים, בעוד שמשתמשים עם הרשאה מוגבלת מקבלים פלט של
NULLבכל מנועי השאילתות. - מעקב אוטומטי אחר מקורות נתונים: ב-Knowledge Catalog מתבצע מעקב אוטומטי אחר טרנספורמציות של נתונים, ונוצרת שרשרת ביקורת בלי קוד מותאם אישית לרישום ביומן.
מטרות
- יצירת טבלאות Apache Iceberg שמנוהלות על ידי BigQuery. Lakehouse מנהל את המטא-נתונים של Iceberg.
- הגדרת כללי אבטחה מרכזיים באמצעות תגי מדיניות כדי להסתיר ולהגן על עמודות רגישות.
- הפרדה בין הרשאות אחסון פיזי לבין שאילתות לוגיות של נתונים באמצעות קישור למשאבים ב-Cloud.
- ניתוב מאובטח של שאילתות דרך Managed Service for Apache Spark כדי שמנועים חיצוניים לא יוכלו לעקוף את כללי האבטחה שלכם.
- אפשר לעיין במפה אינטראקטיבית של הנתונים באמצעות היסטוריית הנתונים.
לפני שמתחילים
לפני שמתחילים, צריך לבצע את הפעולות הבאות:
- בוחרים פרויקט Google Cloud למדריך הזה.
- מוודאים שהחיוב מופעל בפרויקט.
הכנת הסביבה
במדריך הזה משתמשים ב-Cloud Shell, סביבת שורת פקודה שפועלת בענן.
בGoogle Cloud Console, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה.
מגדירים את משתני הפרויקט:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"הגדרת משתנים לשתי פרסונות של משתמשים: אנליסט קמעונאי ומנהל קמעונאי:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)מפעילים את ממשקי ה-API הנדרשים Google Cloud .
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
הורדת קוד המקור של המדריך
מורידים את סקריפטים של Python למדריך הזה ממאגר Google Cloud DevRel:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
יצירה של קטגוריית אחסון
יוצרים קטגוריה חדשה לאחסון קבצים של טבלאות Iceberg:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
הכנת זהויות ואבטחה
בשלב הזה, מגדירים הקצאת משאבי מחשוב על ידי יצירת קישור למשאבים ב-Cloud. החיבור הזה פועל כזהות מאובטחת ומוקצית ש-BigQuery משתמש בה כדי לנהל את קובצי Iceberg ולקרוא אותם. כך אפשר לוודא שלמשתמשים פרטיים אף פעם לא תהיה גישה ישירה לקטגוריה שלכם ב-Cloud Storage.
מריצים את הפקודות הבאות כדי ליצור את החיבור, לאחזר את חשבון השירות שנוצר אוטומטית ולהעניק לחשבון הזה את ההרשאות שנדרשות לניהול נתוני Iceberg:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
יוצרים חשבונות שירות לשתי פרסונות: Analyst ו-Manager. הפקודות הבאות מגדירות את חשבונות השירות האלה, מאפשרות למשתמש הנוכחי להתחזות להם לצורך בדיקה ומעניקות להם תפקידים ספציפיים להרצת שאילתות ולצפייה בנתונים.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
יצירת טבלאות Apache Iceberg
אפשר להשתמש במנוע BigQuery SQL כדי ליצור טבלאות Apache Iceberg. למרות שמריצים את פקודות היצירה באמצעות BigQuery, Lakehouse פועל כשכבת הניהול שמאחסנת את המטא-נתונים של הטבלה ומאבטחת את קובצי ה-Parquet הבסיסיים ב-Cloud Storage.
אחרי שיוצרים את הטבלאות, מריצים טרנספורמציה מהירה כדי לראות איך Knowledge Catalog מטפל באבטחה ועוקב באופן אוטומטי אחרי המסלול של הנתונים.
יצירת מערך נתונים ב-BigQuery
קודם צריך ליצור מערך נתונים ב-BigQuery כדי לקבץ את הטבלאות:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
יצירת טבלאות Iceberg
מריצים את הפקודות הבאות כדי ליצור טבלאות של מלאי ועסקאות:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
הוספת נתונים לדוגמה
מכניסים נתונים לדוגמה לטבלאות:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
עכשיו יש לכם שתי טבלאות Iceberg עם נתונים גולמיים לדוגמה. Lakehouse מנהל את המטא-נתונים, אבל קובצי ה-Parquet בפועל נמצאים בקטגוריה שלכם ב-Cloud Storage.
טרנספורמציה של נתונים בשביל שושלת אוטומטית
לצבור את העסקאות הגולמיות שלכם לסיכום מכירות יומי. הטרנספורמציה הזו יוצרת טבלה חדשה ומפיקה את המטא-נתונים שמשמשים את Knowledge Catalog למיפוי אוטומטי של מסלול הנתונים.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
הגדרת כללי מדיניות באמצעות Python
בסביבת ייצור, כתיבת כללי האבטחה כקוד (תשתית כקוד) מאפשרת להפוך את המדיניות לניתנת לשחזור, לניהול גרסאות וקלה לתחזוקה. בקטע הזה נסביר איך להשתמש ב- Google Cloud Python SDK כדי להגדיר את כללי הממשל ולאכוף אותם באופן אוטומטי.
הכנת סביבה וירטואלית של Python
כדי לנהל את התלות ולוודא שסקריפטים של ניהול הרשאות יפעלו בצורה מהימנה, צריך להגדיר סביבה וירטואלית מבודדת של Python:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
הגדרת טקסונומיות ותגים של אבטחה
מתחילים בבניית הבסיס לכללי האבטחה. בשלב הזה יוצרים טקסונומיה שתשמש כמאגר ותג מדיניות שישמש כתווית אבטחה ספציפית לנתונים רגישים.
מריצים את הסקריפט כדי ליצור את המשאבים:
python 1_create_taxonomy.py
כדי לראות את הלוגיקה המרכזית, אפשר לעיין ב1_create_taxonomy.py:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
הגדרה מפורשת של סוג המדיניות FINE_GRAINED_ACCESS_CONTROL הופכת תג מטא-נתונים רגיל לגבול אבטחה מחמיר עם דחייה כברירת מחדל. כברירת מחדל, כל עמודה עם התג הזה חוסמת את הגישה לכל המשתמשים.
יצירת מדיניות דינמית להסתרת נתונים
עכשיו צריך להגדיר מה קורה כשמישהו בלי הרשאות שולח שאילתה לעמודה עם תג. יוצרים מדיניות להסתרת נתונים שמחליפה באופן אוטומטי ערכים רגישים ב-NULL עבור פרסונה של אנליסט.
מריצים את הסקריפט כדי להגדיר את כלל המיסוך:
python 2_create_masking.py
בתוך 2_create_masking.py, הסקריפט מחפש את המזהה של תג המדיניות שיצרתם ומחיל את מדיניות הנתונים על חשבון השירות Analyst:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
הענקת גישה עם הרשאות מיוחדות לנתונים
בגלל ההגדרה של דחייה כברירת מחדל, אף אחד לא יכול לקרוא את העמודה עם התג. צריך להעניק גישה באופן מפורש למשתמשים מורשים. נותנים את התפקיד Fine-Grained Reader (קריאה עם הרשאות גישה מפורטות) לדמות הניהול ולחשבון שלכם. כך המשתמשים הספציפיים האלה יכולים לעקוף את כללי ההסתרה ולקרוא את הנתונים שלא הוסתרו.
מריצים את הסקריפט כדי להעניק גישה:
python 3_grant_access.py
בתוך 3_grant_access.py, הסקריפט משנה את מדיניות ה-IAM של תג המדיניות:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
צירוף תגי אבטחה לסכימת הטבלה
לבסוף, תוכלו לקשר את הכללים הלוגיים לנתונים בפועל. מעדכנים את הסכימה של טבלת Iceberg כדי לצרף את תג המדיניות ישירות לעמודה amount. אחרי שתעשו את זה, Lakehouse יחיל באופן מיידי את ההגנות על קובצי הטבלה בפורמט Iceberg בדלי.
מריצים את הסקריפט כדי לצרף את תג המדיניות:
python 4_attach_tag.py
בדיקה של 4_attach_tag.py הסקריפט מאחזר את סכימת הטבלה ב-BigQuery, מבצע איטרציה בשדות ומצרף את התג באופן ספציפי לעמודה amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
אימות מדיניות האבטחה
מריצים כמה שאילתות לדוגמה כדי לוודא שההרשאות פועלות כמו שצריך. כדי להוכיח ש-Lakehouse אוכף את אותן מדיניות אבטחה כשעוברים בין מנועי שאילתות, מריצים את הבדיקות האלה באמצעות BigQuery ו-Apache Spark.
בדיקה באמצעות BigQuery SQL
כדאי להתחיל בבדיקת המדיניות ישירות ב-BigQuery. זו הדרך הכי מהירה לוודא שכללי המיסוך וההרשאות פעילים.
בדיקה כמנהל
לפרסונה Manager יש גישה מפורטת ומוגבלת לקוראים. הם צריכים לראות כל פרט בטבלה, כולל הערכים בעמודה amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
למנהל יש הרשאת קריאה עם גישה מדויקת, ולכן בשאילתה מוצגים ערכי הסכום הגולמיים:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
בדיקה כאנליסט
עוברים לפרסונה Analyst ומריצים את אותה שאילתה.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
גם אם מריצים את אותה שאילתה, ב-Knowledge Catalog הערכים הרגישים בעמודה amount מוסתרים:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
חזרה לחשבון
כדי לחזור למשתמש האדמין, צריך לנקות את מצב האימות של Cloud Shell.
gcloud config unset auth/impersonate_service_account
בדיקה באמצעות Apache Spark
האבטחה נפרצת לעיתים קרובות כשמשתמשים ניגשים ישירות לקובצי נתונים ב-Cloud Storage. אם מדען נתונים משתמש ב-Apache Spark כדי לקרוא את קובצי הטבלה של Iceberg ישירות, הוא בדרך כלל יעקוף את הכללים שלכם כי Cloud Storage מבין רק הרשאות ברמת הקטגוריה.
כדי למנוע את זה, משתמשים במתן הרשאות גישה לחישוב. באמצעות Spark-BigQuery Connector, אתם יוצרים גשר מאובטח שמנתב את כל הבקשות של Spark דרך BigQuery Storage API. כך אפשר לוודא ש-Knowledge Catalog בודק את ההרשאות ומחיל כללי אנונימיזציה לפני שנתונים מגיעים לאשכול Spark.
מעלים את סקריפט read_transactions.py לקטגוריה שלכם ב-Cloud Storage כדי ש-Managed Service for Apache Spark יוכל לגשת אליו:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
בודקים את הלוגיקה המרכזית בסקריפט שהעליתם:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
הסקריפט לא מפנה את Spark אל הנתיב gs:// של קובצי Iceberg. אם מציינים .format("bigquery"), BigQuery Storage API מיירט את בקשת הקריאה, בודק את הזהות של המשתמש שמריץ את משימת Spark, מחיל את כללי המיסוך של Knowledge Catalog ומחזיר רק את הנתונים המורשים ל-Spark DataFrame.
הפעלת Spark כמנהל
שליחת עבודת Spark בתור פרסונה של מנהל. אפשר להשתמש ב-Managed Service for Apache Spark, שירות מנוהל שמאפשר להריץ עומסי עבודה של Spark בלי הצורך לנהל אשכולות משלכם:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
בודקים את יומני הפלט של העבודה במסוף. מכיוון שלמנהל יש את התפקיד 'קורא עם הרשאות גישה מפורטות', Spark מאחזר בהצלחה את הסכומים הלא מוסווים:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
הפעלת Spark כאנליסט
לבסוף, מריצים את אותו קוד Spark כמו הדמות Analyst:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
בודקים שוב את היומנים. למרות שהאנליסט הפעיל את אותו קוד Spark, ממשק BigQuery Storage API יירוט את הבקשה ואכף את המדיניות של Knowledge Catalog. ב-DataFrame של Spark של האנליסט מוצג הערך null בסכומים.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
בחירת המנוע המתאים: BigQuery SQL לעומת Apache Spark
הרגע הוכחת שקטלוג הידע אוכף את המדיניות שלך בלי קשר למנוע השאילתות שבו את משתמשת. אבל כשעוברים לייצור, איך בוחרים את הכלי הנכון?
- BigQuery SQL: משתמשים ב-SQL הזה לניתוח מהיר ולבינה עסקית. זו האפשרות הטובה ביותר אם SQL היא השפה העיקרית שלכם, כי החישובים מתבצעים ישירות במקום שבו הנתונים נמצאים.
- Apache Spark: בוחרים ב-Spark למשימות מורכבות יותר שדורשות Python. השימוש ב-Spark הכי יעיל בצינורות של למידת מכונה או כשצריך להעביר קוד Hadoop מדור קודם אל lakehouse.
מעקב אחרי מסלול הנתונים באמצעות שושלת אוטומטית
שושלת נתונים עוזרת לכם להבין מאיפה הנתונים מגיעים ואיך הם משתנים. מענה על שאלות חיוניות כמו 'אילו טבלאות גולמיות שימשו ליצירת דוח המכירות הזה?' עוזר לכם לשמור על תאימות, לבצע ניפוי באגים בצינורות נתונים במהירות ולבנות בסיס נתונים אמין.
במקום לכתוב קוד מורכב לרישום ביומן באופן ידני, Lakehouse עוקב אחרי מחזור החיים הזה באופן אוטומטי. לדוגמה, כשיוצרים טבלת סיכום כמו בדוגמה שמופיעה בהמשך המדריך הזה, BigQuery מתעד את פרטי השינוי באופן מיידי ושולח אותם ל-Knowledge Catalog.
עיון בתרשים האינטראקטיבי של שרשרת היוחסין
בודקים את המפה האינטראקטיבית שנוצרה ב-Knowledge Catalog. התרשים מראה איך נתונים גולמיים זורמים מהטבלה transactions לטבלה transactions_summary. כך תוכלו לעקוב אחרי הנתונים מקצה לקצה, כפי שנדרש בביקורת נתונים.
- במסוף Google Cloud , עוברים אל Knowledge Catalog > Search.
- מקלידים
lakehouse_retail_demo.transactions_summaryבסרגל החיפוש ולוחצים על הטבלה. - לוחצים על הכרטיסייה Lineage (מקורות נתונים).
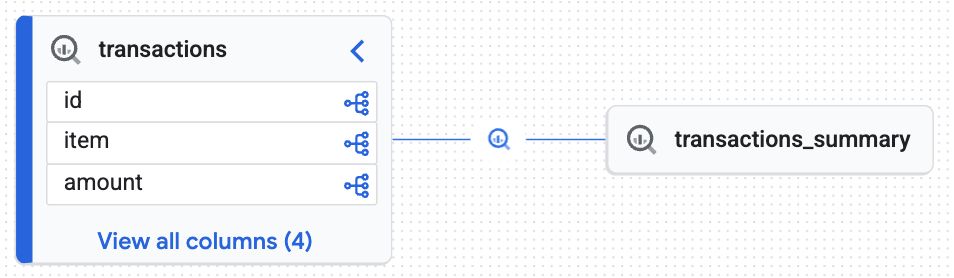
התרשים האינטראקטיבי מאשר שטבלת היעד (transactions_summary) נגזרת מטבלת Iceberg הגולמית המנוהלת (transactions). ההדמיה הזו מראה את היכולת לעקוב אחרי הנתונים מקצה לקצה.
הסרת המשאבים
כדי להימנע מחיובים שוטפים, צריך להסיר את המשאבים שיצרתם לצורך המדריך הזה.
מחיקת משאבי ניהול
כדי למחוק את מערך הנתונים ב-BigQuery או את הקטגוריה של Cloud Storage, צריך למחוק את כללי ניהול הנתונים.
מריצים את סקריפט הניקוי של Python:
python cleanup_governance.py
בודקים את סקריפט cleanup_governance.py ממאגר המידע כדי למצוא את לוגיקת הפירוק הבאה. סדר המחיקה הוא קריטי. קודם מוחקים את מדיניות האנונימיזציה של הנתונים. לאחר מכן, מוחקים את הטקסונומיה הראשית, וכך מסירים אוטומטית את כל תגי המדיניות הבסיסיים ומונעים שגיאות של תלות במשאבים.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
הסרת זהויות, אחסון ונכסי מחשוב
מוחקים את טבלאות BigQuery, את דלי Cloud Storage, את חשבונות השירות ואת הסביבה הווירטואלית המקומית של Python.
מעתיקים ומריצים את סקריפט הניקוי הבא ב-Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
מנקים את קובצי הפרויקט:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
סיכום
יצרתם בהצלחה lakehouse מאובטח! השתמשתם ב-Lakehouse for Apache Iceberg כדי לנהל טבלאות Iceberg, ושמרתם על אבטחת קובצי הטבלה הבסיסיים ב-Cloud Storage. הגדרתם תגי מדיניות במיקום מרכזי אחד והחלתם אותם באופן אוניברסלי על מנועי שאילתות שונים. לבסוף, תוכלו לעקוב אוטומטית אחרי כל התהליך שעוברים הנתונים באמצעות שושלת נתונים בזמן אמת.
המאמרים הבאים
- Managed Service for Apache Spark: במאמר Serverless Spark מוסבר איך להרחיב את צינורות הנתונים בלי להקצות אשכולות.
- עיון בבקרת גישה מתקדמת: כדי להטמיע תרחישי אבטחה מורכבים יותר, כדאי לעיין בתיעוד הרשמי בנושא התאמה אישית של Lakehouse עם תכונות נוספות.
- שליטה בנתונים לא מובְנים ב-AI גנרטיבי: מידע על טבלאות אובייקטים. אפשר להרחיב את דפוס הגשר המאובטח הזה לקבצים לא מובְנים (קובצי PDF, תמונות) ב-Cloud Storage, וכך ליצור בסיס נתונים מאובטח ומנוהל לצינורות של Vertex AI ו-RAG.
- לנסות תרחישי שימוש אחרים: אפשר לנסות תרחישי שימוש אחרים ב-Knowledge Catalog.