
Lorsque vous stockez vos données dans différents systèmes de stockage, la gestion de la sécurité fragmentée peut devenir un défi majeur.
Vous souhaitez vous assurer que les informations sensibles, telles que les registres financiers, restent protégées, même si vous les stockez dans des formats ouverts tels qu'Apache Iceberg sur Google Cloud Storage. Vous devez appliquer ces protections à différents moteurs de requête, comme BigQuery SQL et Apache Spark.
Dans ce tutoriel, vous allez créer un data lakehouse sécurisé pour résoudre ces problèmes. À l'aide de scripts, vous définissez des règles de sécurité et voyez comment Knowledge Catalog (anciennement Dataplex Universal Catalog) et Lakehouse pour Apache Iceberg fonctionnent ensemble pour appliquer les règles sur différents moteurs de requête.
Présentation de l'architecture
Pour configurer un contrôle précis des accès sur un format de table ouvert comme Apache Iceberg, vous devez créer une architecture de sécurité stricte et unifiée.
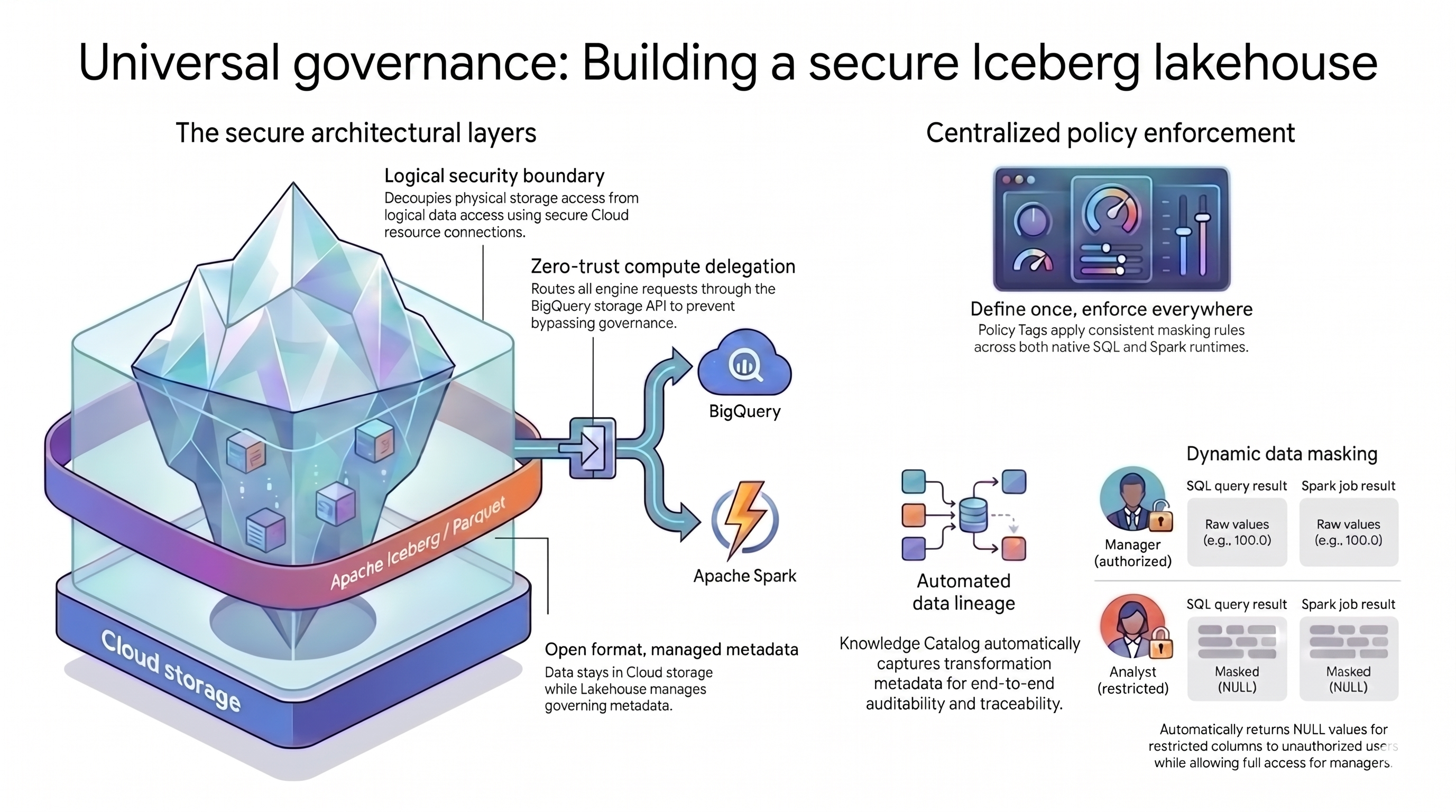
Le modèle lakehouse que vous utilisez dans ce tutoriel repose sur deux concepts principaux pour relever ce défi :
- Couches architecturales sécurisées : au lieu de laisser les utilisateurs ou les moteurs de requête accéder directement à vos buckets Cloud Storage, vous créez une base sécurisée et multicouche en fonction des attributs suivants :
- Format ouvert avec métadonnées gérées : vos données restent dans leur format Apache Iceberg (Parquet) ouvert dans Cloud Storage, tandis que Lakehouse pour Apache Iceberg gère les métadonnées de la table.
- Limite de sécurité logique : vous dissociez les autorisations de stockage des requêtes de données à l'aide d'une connexion sécurisée à une ressource Cloud. Vous n'accordez jamais aux utilisateurs finaux un accès direct aux fichiers.
- Délégation de calcul : pour empêcher les moteurs de requête de contourner vos règles, vous devez acheminer toutes les demandes de données via l'API BigQuery Storage.
- Application centralisée des règles : avec une base sécurisée en place, Knowledge Catalog sert de plan de contrôle unique pour l'architecture, en appliquant les règles de manière universelle :
- Définissez les tags avec stratégie une seule fois et appliquez-les partout : vous définissez les tags avec stratégie dans Knowledge Catalog une seule fois, et la plate-forme applique des règles de masquage cohérentes sur tous vos moteurs de requête compatibles.
- Masquage dynamique des données : le système évalue l'identité de l'utilisateur lors des requêtes. Les utilisateurs autorisés voient les valeurs brutes, tandis que les utilisateurs restreints reçoivent des résultats
NULLdans tous les moteurs de requête. - Traçabilité des données automatisée : Knowledge Catalog suit automatiquement les transformations de données, ce qui crée un journal d'audit sans code de journalisation personnalisé.
Objectifs
- Créez des tables Apache Iceberg gérées par BigQuery. Le lakehouse gère les métadonnées Iceberg.
- Configurez des règles de sécurité centrales à l'aide de tags avec stratégie pour masquer et protéger les colonnes sensibles.
- Séparez les autorisations de stockage physique des requêtes de données logiques à l'aide d'une connexion de ressource Cloud.
- Acheminez les requêtes de manière sécurisée via Managed Service pour Apache Spark afin que les moteurs externes ne puissent pas contourner vos règles de sécurité.
- Explorez une carte interactive de vos données à l'aide de la traçabilité des données.
Avant de commencer
Avant de commencer, procédez comme suit :
- Sélectionnez un projet Google Cloud pour ce tutoriel.
- Vérifiez que la facturation est activée pour votre projet.
Préparer votre environnement
Ce tutoriel utilise Cloud Shell, un environnement de ligne de commande qui s'exécute dans le cloud.
Dans la consoleGoogle Cloud , cliquez sur l'icône Cloud Shell dans la barre d'outils en haut à droite.
Définissez les variables de votre projet :
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"Définissez des variables pour deux personas d'utilisateur, un analyste et un responsable du secteur de la vente au détail :
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)Activez les Google Cloud API requises.
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
Télécharger le code source du tutoriel
Téléchargez les scripts Python pour ce tutoriel à partir du dépôt Google Cloud DevRel :
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Créer un bucket de stockage
Créez un bucket pour stocker les fichiers de table Iceberg :
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Préparer les identités et la sécurité
Au cours de cette étape, vous allez configurer la délégation de calcul en créant une connexion aux ressources Cloud. Cette connexion sert d'identité sécurisée et déléguée que BigQuery utilise pour gérer et lire vos fichiers Iceberg. Cela permet de s'assurer que les utilisateurs individuels n'ont jamais accès directement à votre bucket Cloud Storage.
Exécutez les commandes suivantes pour créer la connexion, récupérer son compte de service généré automatiquement et accorder à ce compte les autorisations nécessaires pour gérer vos données Iceberg :
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Créez des comptes de service pour deux personas : Analyst et Manager. Les commandes suivantes configurent ces comptes de service, permettent à votre utilisateur actuel de les emprunter pour les tests et leur attribuent des rôles spécifiques pour exécuter des requêtes et afficher des données.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Créer des tables Apache Iceberg
Utilisez le moteur SQL BigQuery pour créer des tables Apache Iceberg. Bien que vous exécutiez les commandes de création avec BigQuery, Lakehouse sert de couche de gestion qui stocke les métadonnées des tables et sécurise les fichiers Parquet sous-jacents dans Cloud Storage.
Une fois les tables créées, vous exécutez une transformation rapide pour voir comment Knowledge Catalog gère la sécurité et suit automatiquement le parcours de vos données.
Créer un ensemble de données BigQuery
Commencez par créer un ensemble de données BigQuery pour regrouper vos tables :
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Créer les tables Iceberg
Exécutez les commandes suivantes pour créer des tables d'inventaire et de transactions :
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Insérer des exemples de données
Insérez des exemples de données dans les tables :
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Vous disposez maintenant de deux tables Iceberg contenant des exemples de données brutes. Le lakehouse gère les métadonnées, mais les fichiers Parquet sont stockés dans votre bucket Cloud Storage.
Transformer les données pour la traçabilité automatisée
Regroupez vos transactions brutes dans un récapitulatif des ventes quotidiennes. Cette transformation crée une table et génère les métadonnées que Knowledge Catalog utilise pour mapper automatiquement le parcours de vos données.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Définir des règles à l'aide de Python
Dans un environnement de production, écrire vos règles de sécurité sous forme de code (infrastructure as code) rend vos règles reproductibles, contrôlées par version et plus faciles à gérer. Dans cette section, vous allez utiliser le SDK Python Google Cloud pour définir et appliquer automatiquement vos règles de gouvernance.
Préparer l'environnement virtuel Python
Configurez un environnement virtuel Python isolé pour gérer vos dépendances et vous assurer que vos scripts de gouvernance s'exécutent de manière fiable :
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Définir des taxonomies et des tags de sécurité
Commencez par créer la base de vos règles de sécurité. Dans cette étape, vous allez créer une taxonomie qui servira de conteneur et un tag avec stratégie qui servira de libellé de sécurité spécifique pour les données sensibles.
Exécutez le script pour créer les ressources :
python 1_create_taxonomy.py
Examinez 1_create_taxonomy.py pour voir la logique principale :
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
En définissant explicitement le type de règle FINE_GRAINED_ACCESS_CONTROL, vous transformez un tag de métadonnées standard en limite de sécurité stricte avec refus par défaut. Par défaut, l'accès à toute colonne comportant ce tag est refusé à tous les utilisateurs.
Créer une règle de masquage dynamique des données
Définissez maintenant ce qui se passe lorsqu'une personne sans privilèges interroge une colonne taguée. Créez une règle de masquage des données qui remplace automatiquement les valeurs sensibles par NULL pour le persona Analyst.
Exécutez le script pour configurer la règle de masquage :
python 2_create_masking.py
Dans 2_create_masking.py, le script recherche l'ID du tag avec stratégie que vous avez créé et applique la règle de données au compte de service Analyst :
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Accorder un accès privilégié à vos données
En raison de votre configuration de refus par défaut, personne ne peut lire la colonne taguée. Vous devez accorder explicitement l'accès aux utilisateurs autorisés. Attribuez le rôle "Lecteur détaillé" à la persona Manager et à votre propre compte. Ces utilisateurs spécifiques peuvent ainsi contourner les règles de masquage et lire les données non masquées.
Exécutez le script pour accorder l'accès :
python 3_grant_access.py
Dans 3_grant_access.py, le script modifie la stratégie IAM du tag de stratégie :
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Associer des tags de sécurité au schéma de table
Enfin, vous pouvez associer vos règles logiques aux données réelles. Mettez à jour le schéma de votre table Iceberg pour associer votre tag avec stratégie directement à la colonne amount. Une fois cette opération effectuée, Lakehouse applique instantanément vos protections aux fichiers de table Iceberg de votre bucket.
Exécutez le script pour associer le tag de règle :
python 4_attach_tag.py
Examinez 4_attach_tag.py. Le script récupère le schéma de la table BigQuery, parcourt les champs et associe le tag spécifiquement à la colonne amount :
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Vérifier vos règles de sécurité
Exécutez quelques requêtes de test pour vous assurer que vos autorisations fonctionnent comme prévu. Pour prouver que Lakehouse applique les mêmes règles de sécurité lorsque vous changez de moteur de requête, vous exécutez ces tests à l'aide de BigQuery et d'Apache Spark.
Tester avec BigQuery SQL
Commencez par vérifier vos règles directement dans BigQuery. C'est le moyen le plus rapide de vérifier que vos règles de masquage et vos autorisations sont actives.
Vérifier en tant qu'administrateur
Le rôle Responsable dispose d'un accès en lecture privilégié et précis. Ils doivent pouvoir voir tous les détails du tableau, y compris les valeurs de la colonne amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Comme le responsable dispose du rôle Lecteur détaillé, la requête affiche les valeurs brutes des montants :
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Vérifier en tant qu'analyste
Passez au persona Analyst et exécutez la même requête.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Même si vous exécutez la même requête, Knowledge Catalog masque les valeurs sensibles de la colonne amount :
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Revenir à votre compte
Nettoyez l'état d'authentification Cloud Shell pour revenir à votre utilisateur administrateur.
gcloud config unset auth/impersonate_service_account
Tester avec Apache Spark
La sécurité est souvent compromise lorsque les utilisateurs accèdent directement aux fichiers de données dans Cloud Storage. Si un data scientist utilise Apache Spark pour lire directement les fichiers de table Iceberg, il contourne normalement vos règles, car Cloud Storage ne comprend que les autorisations au niveau du bucket.
Pour éviter cela, utilisez la délégation de calcul. En utilisant le connecteur Spark-BigQuery, vous créez un pont sécurisé qui achemine toutes les requêtes Spark via l'API BigQuery Storage. Cela permet à Knowledge Catalog de vérifier les autorisations et d'appliquer les règles de masquage avant que les données n'atteignent le cluster Spark.
Importez le script read_transactions.py dans votre bucket Cloud Storage pour que Managed Service pour Apache Spark puisse y accéder :
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Examinez la logique de base du script que vous avez importé :
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Le script ne pointe pas Spark vers le chemin d'accès gs:// des fichiers Iceberg. En spécifiant .format("bigquery"), l'API BigQuery Storage intercepte la requête de lecture, vérifie l'identité de l'utilisateur exécutant le job Spark, applique les règles de masquage du Knowledge Catalog et ne renvoie que les données autorisées au DataFrame Spark.
Exécuter Spark en tant que responsable
Envoyez un job Spark en tant que responsable. Utilisez Managed Service pour Apache Spark, un service géré qui vous permet d'exécuter des charges de travail Spark sans avoir à gérer vos propres clusters :
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Examinez les journaux de sortie du job dans le terminal. Étant donné que le responsable dispose du rôle Lecteur détaillé, Spark récupère les montants non masqués :
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Exécuter Spark en tant qu'analyste
Enfin, exécutez le même code Spark que la persona Analyst :
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Examinez à nouveau les journaux. Même si l'analyste a exécuté le même code Spark, l'API BigQuery Storage a intercepté la requête et appliqué le règlement Knowledge Catalog. Le DataFrame Spark de l'analyste affiche null pour les montants.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Choisir le bon moteur : BigQuery SQL ou Apache Spark
Vous venez de prouver que Knowledge Catalog applique votre règle, quel que soit le moteur de requête que vous utilisez. Mais comment choisir le bon outil lorsque vous passez à la production ?
- BigQuery SQL : utilisez-le pour l'analyse rapide et l'informatique décisionnelle. C'est le meilleur choix si SQL est votre langage principal, car il exécute les calculs directement là où se trouvent les données.
- Apache Spark : choisissez Spark pour les tâches plus complexes qui nécessitent Python. Spark est idéal pour les pipelines de machine learning ou lorsque vous devez importer un ancien code Hadoop dans votre lakehouse.
Visualiser le parcours de vos données grâce à la traçabilité automatisée
La traçabilité des données vous aide à comprendre d'où viennent vos données et comment elles sont transformées. Répondre à des questions essentielles telles que "Quelles tables brutes ont été utilisées pour générer ce rapport sur les ventes ?" vous aide à assurer la conformité, à déboguer rapidement les pipelines de données et à créer une base de données fiable.
Au lieu d'écrire manuellement un code de journalisation complexe, Lakehouse suit automatiquement ce cycle de vie. Par exemple, lorsque vous avez créé votre tableau récapitulatif plus tôt dans ce tutoriel, BigQuery a capturé instantanément les détails de la transformation et les a envoyés à Knowledge Catalog.
Explorer le graphique de traçabilité interactif
Consultez la carte interactive générée par le Knowledge Catalog. Il montre comment les données brutes sont transférées de la table transactions vers la table transactions_summary. Cela vous offre la traçabilité de bout en bout dont vous avez besoin pour un audit des données.
- Dans la console Google Cloud , accédez à Knowledge Catalog > Search (Catalogue de connaissances > Recherche).
- Saisissez
lakehouse_retail_demo.transactions_summarydans la barre de recherche, puis cliquez sur le tableau. - Cliquez sur l'onglet Traçabilité.
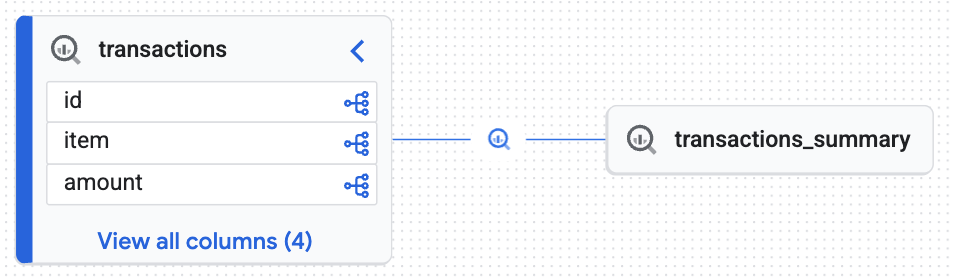
Le graphique interactif confirme que la table cible (transactions_summary) est dérivée de la table Iceberg brute régie (transactions). Cette visualisation illustre la traçabilité de bout en bout de vos données.
Effectuer un nettoyage
Pour éviter que des frais ne vous soient facturés en permanence, supprimez les ressources que vous avez créées pour ce tutoriel.
Supprimer les ressources de gouvernance
Avant de pouvoir supprimer l'ensemble de données BigQuery ou le bucket Cloud Storage, vous devez supprimer les règles de gouvernance.
Exécutez le script de nettoyage Python :
python cleanup_governance.py
Consultez le script cleanup_governance.py du dépôt pour trouver la logique de suppression suivante. L'ordre de suppression est essentiel. Commencez par supprimer la stratégie d'omission des données. Vous supprimez ensuite la taxonomie parente, ce qui supprime automatiquement tous les tags avec stratégie sous-jacents et évite les erreurs de dépendance des ressources.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Supprimer des identités, des ressources de stockage et de calcul
Supprimez les tables BigQuery, les buckets Cloud Storage, les comptes de service et l'environnement virtuel Python local.
Copiez et exécutez le script de nettoyage suivant dans Cloud Shell :
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
Nettoyez les fichiers du projet :
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
Conclusion
Vous avez réussi à créer un data lakehouse sécurisé. En utilisant Lakehouse pour Apache Iceberg afin de gérer les tables Iceberg, vous avez sécurisé les fichiers de table sous-jacents dans Cloud Storage. Vous avez défini des tags avec stratégie dans un emplacement centralisé et les avez appliqués de manière universelle à différents moteurs de requête. Enfin, vous avez suivi automatiquement l'ensemble du parcours de vos données grâce à la traçabilité des données en temps réel.
Étapes suivantes
- Managed Service pour Apache Spark : découvrez comment faire évoluer vos pipelines de données sans provisionner de clusters sur la page de documentation Spark sans serveur.
- Découvrez le contrôle d'accès avancé : pour implémenter des scénarios de sécurité plus complexes, consultez la documentation officielle sur la personnalisation du lakehouse avec des fonctionnalités supplémentaires.
- Gouverner les données non structurées pour l'IA générative : découvrez les tables d'objets. Étendez ce modèle de pont sécurisé aux fichiers non structurés (PDF, images) dans Cloud Storage, en établissant une base de données sécurisée et régie pour Vertex AI et les pipelines RAG.
- Essayer d'autres cas d'utilisation : essayez d'autres cas d'utilisation de Knowledge Catalog.