
Cas d'utilisation de Knowledge Catalog
Exécutez des requêtes complexes en langage naturel sur des ressources de données d'entreprise à l'aide d'un agent de découverte qui effectue des appels à l'API Knowledge Catalog (Python).
Générez des résumés optimisés par l'IA pour vos composants de données à grande échelle, à l'aide d'un agent d'enrichissement qui effectue des appels à l'API Knowledge Catalog (Python).
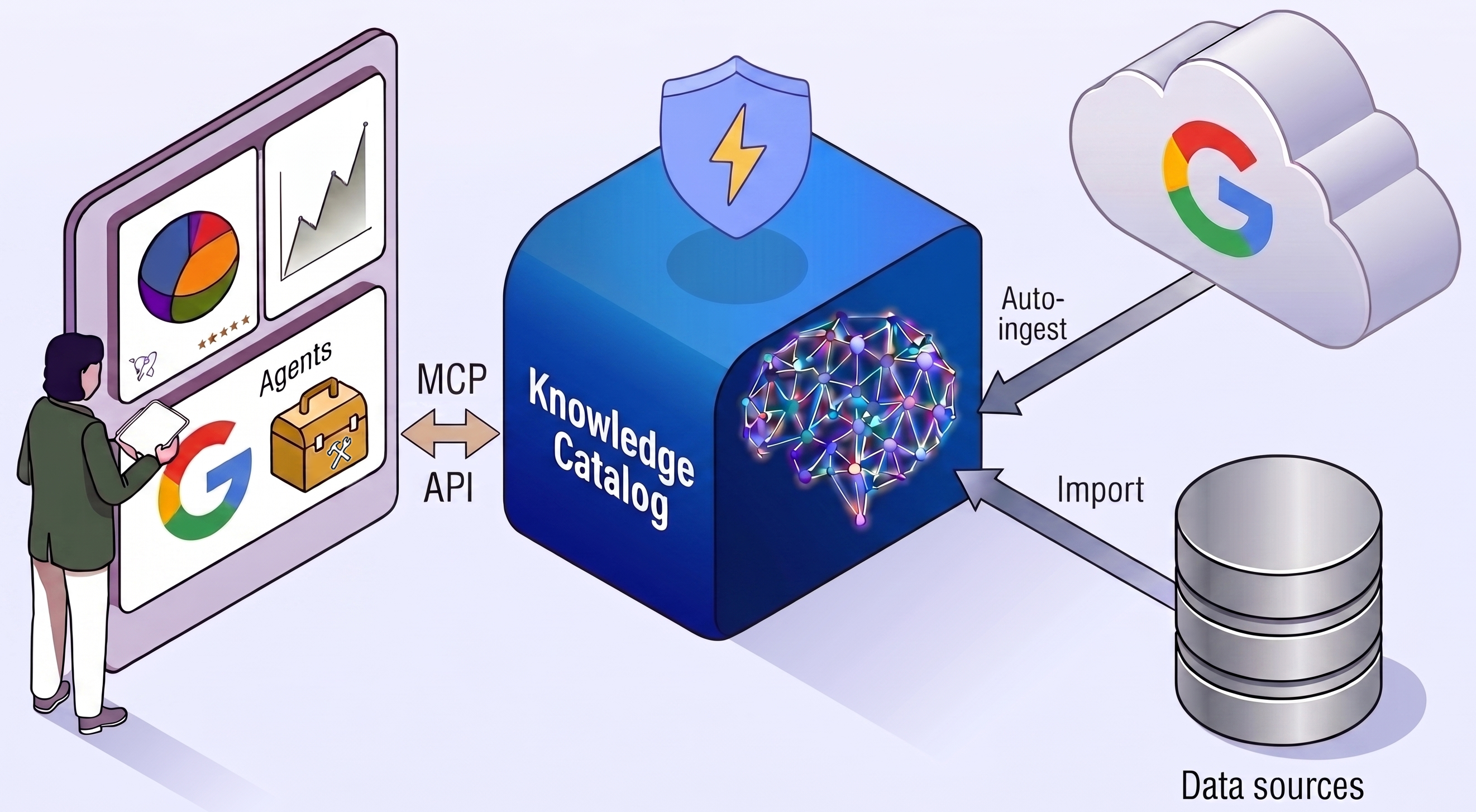
Concevez des workflows d'analyse multicloud dans des datastores distribués à l'aide d'agents d'IA et de Knowledge Catalog comme graphique contextuel.
Associez des métadonnées structurées et basées sur un schéma (aspects) et des définitions métier (glossaires) à vos composants de données (entrées) à l'aide de la console Google Cloud.
Créez des tables Apache Iceberg, appliquez des règles de données centralisées pour la sécurité au niveau des colonnes, définissez des règles de sécurité et visualisez la traçabilité des données automatisée.
Ingérez automatiquement les métadonnées des services Google tels que BigQuery.
Indexez les métadonnées de sources de données personnalisées à l'aide d'API ouvertes.
Grâce à Gemini CLI, utilisez des requêtes en langage naturel pour profiler des données et générer des règles de qualité des données, puis déployez ces règles sous forme d'analyses automatisées.
Vérifiez que Knowledge Catalog peut faire la distinction entre les données sources et les dérivés temporaires, en utilisant des requêtes en langage naturel pour Gemini CLI.
Identifier l'impact des transformations de données sur les ressources en aval, l'intégrité des données et les workflows
Retracez le flux de données sensibles jusqu'au processus qui les déplace d'un emplacement approuvé vers un emplacement non approuvé.
Réduisez les coûts de stockage en identifiant les composants qui ne sont pas utilisés activement comme sources pour d'autres processus.
Récupérez le contexte préformaté et prêt pour le LLM pour les composants de données à l'aide d'une seule requête API.