
לכלול רק את ארצות הברית, קנדה או מקסיקו
נניח שאתם רוצים להגביל את המידע בתרשים רק לנתונים שמגיעים מארצות הברית, ממקסיקו או מקנדה. בוחרים את התרשים ומוסיפים את המסנן הבא:
- כלול/לא כלול: כלול
- מאפיין: מדינה
- סוג ההתאמה: IN
- ערך:
United States, Canada, Mexico
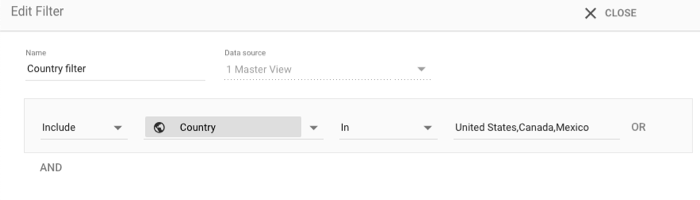
אפשר גם להשתמש ב-3 פסוקיות OR. אבל קל יותר להשתמש באופרטור IN עם רשימה.
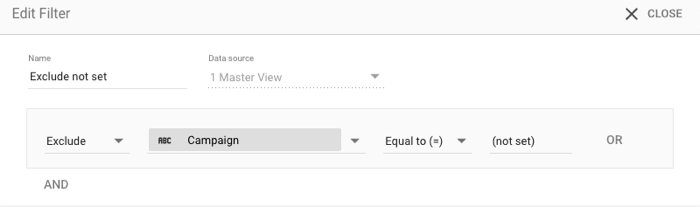
החרגה של '(not set)'
כדי להחריג ערכים מסוג '(not set)' מהתרשימים, משתמשים במסנן החרגה. לדוגמה:
- הכללה/החרגה: החרגה
- מאפיין: קמפיין
- סוג התאמה: שווה ל-
- ערך:
(not set)
חיפוש נתונים בסוף ערך
האופרטורים RegExp Match ו-RegExp Contains מאפשרים לבצע התאמות מורכבות יותר. לדוגמה, כדי לסנן נתונים שמכילים ערך בסוף הנתונים, אפשר להשתמש בסמן סוף השורה $:
- כלול/לא כלול: כלול
- מאפיין: אמצעי
- סוג ההתאמה:: התאמה לביטוי רגולרי
- ערך:.
*c$
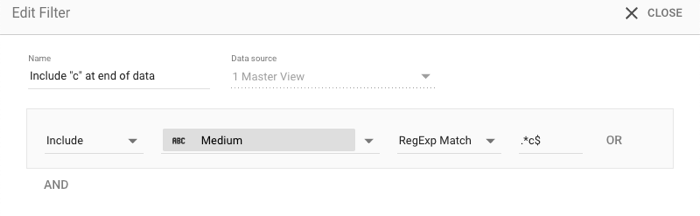
כשמחילים את התנאי על המאפיין אמצעי הגעה ב-Analytics, צריך לכלול ערכים כמו organic ו-cpc.
הסבר על הביטוי הרגולרי: .*c$
.*פירושו "התאמה לכל דבר" (כולל כלום),ואז האות 'c'
$הוא התו 'סוף השורה'. (כדי להתאים לתחילת המחרוזת, משתמשים ב-^).
דוגמה נוספת:
^c.*k.*$ תואם לטקסט שמתחיל באות c, ואחריה כל דבר, ואחרי זה האות k, ואחרי זה כל דבר עד סוף המחרוזת. התנאי הזה יתאים לערכים כמו cook, cookie ו-cake.
החרגה של נתונים שלא מתחילים בתו אלפביתי
מחלקות תווים של ביטויים רגולריים הן קיצור דרך יעיל להתאמת סוגי תווים. לדוגמה:
- הכללה/החרגה: החרגה
- סוג ההתאמה:: התאמה לביטוי רגולרי
- ערך:
^[[:^alpha:]].*
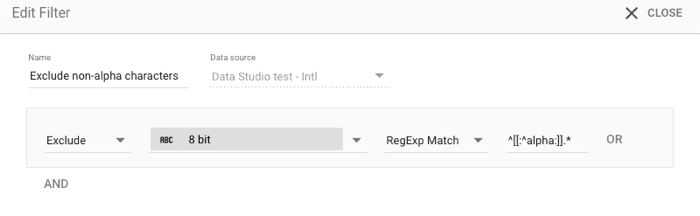
הסינון הזה יסיר תווים לא אלפביתיים, כמו קאנג'י יפני או האנגול קוריאני.
הסבר על הביטוי הרגולרי: ^[[:^alpha:]].*
^פירושו 'תחילת המחרוזת'
[[:alpha:]]היא מחלקת התווים האלפביתית [A-Za-z]. [[:^alpha:]] שולל את המחלקה ("לא אלפביתית")
.*פירושו 'התאמה לכל דבר'
מקורות מידע שקשורים לנושא
התחביר של ביטויים רגולריים ב-Google RE2.