
BigQuery は、Google が提供するペタバイト規模の低料金フルマネージド アナリティクス データ ウェアハウスです。データポータルの BigQuery コネクタを使用すると、データポータルで BigQuery テーブルのデータにアクセスできます。
始める前に
データポータルで BigQuery データにアクセスするには、Google Cloud 請求先アカウントを指定する必要があります。BigQuery は有料サービスであり、データポータルを使用して BigQuery にアクセスすると、BigQuery の利用料金が発生する場合があります。詳しくは、BigQuery の料金をご覧ください。
BigQuery に接続する方法
データポータルは、Google BigQuery のテーブル、ビュー、カスタムクエリに接続できます。
接続の手順
[作成] をクリックし、[レポート] を選択します。
レポート エディタが表示され、[データのレポートへの追加] パネルが開きます。
新しい埋め込みデータソースを作成するには、BigQuery コネクタを選択します。
- 再利用可能な既存のデータソースを選択するには、[マイ データソース] タブをクリックし、以前に作成した任意のデータソースまたは共有されているデータソースを選択します。
データソースと BigQuery データの間の接続を構成します。BigQuery のテーブルまたはビューに接続することも、カスタム SQL クエリを使用して接続することもできます。
[追加] をクリックします。
しばらくすると、データソースに接続されたテーブルがレポートのキャンバスに表示されます。
埋め込みデータソースと再利用可能なデータソースの比較
データソースは、埋め込みまたは再利用可能のいずれかになります。レポートには、埋め込みデータソースと再利用可能なデータソースの両方を使用できます。
レポートの編集中に作成したデータソースは、レポート内に埋め込まれます。埋め込みデータソースを編集するには、そのレポート内で編集する必要があります。埋め込みデータソースを使用すると、レポートとデータソースの共同編集がよりスムーズに行えるようになります。レポートを編集できるユーザーであれば、データソースの編集と接続の変更も可能です。レポートを共有またはコピーした場合、埋め込みデータソースも共有またはコピーされます。
ホームページから作成するデータソースは再利用できます。これらのデータソースはさまざまなレポートで再利用でき、再利用可能なデータソースを使用すれば、組織全体で一貫したデータモデルを作成して共有できます。再利用可能なデータソースを編集できるのは、そのデータソースを共有されたユーザーのみです。接続を変更できるのはデータソースの認証情報のオーナーのみです。
詳しくは、データソースについてをご覧ください。
データポータルを初めてご利用の場合
プロパティ パネルを使用して、テーブルのデータとスタイルを変更します。ツールバーを使用して、レポートにグラフやコントロールなどのコンポーネントを追加することも可能です。
BigQuery のテーブルまたはビューに接続する
BigQuery テーブルには、行に整理された個々のレコードが含まれています。各レコードは列(フィールドとも呼ばれる)で構成されています。BigQuery ビューは、SQL クエリ(BigQuery コンソールで実行)によって定義される仮想テーブルです。
テーブルまたはビューに接続するには、次の情報を指定する必要があります。
- BigQuery プロジェクト
- データセット
- テーブルまたはビュー
プロジェクト
プロジェクトでは BigQuery リソースが整理され、レポートが BigQuery の無料割り当てを超過した場合、課金に必要な情報が提供されます。課金とデータ管理の両方に同じプロジェクトを使用したり、1 つのプロジェクトをデータ用に使用し、別のプロジェクトで課金を行ったりすることもできます。詳しくは、Google Cloud プロジェクトをご覧ください。
次のいずれかのオプションを選択して、プロジェクトを選択します。
- 最近のプロジェクト
- マイ プロジェクト
- 共有プロジェクト
最近のプロジェクト
[最近のプロジェクト] オプションを使用すると、 Google Cloud コンソールで最近アクセスしたプロジェクトが表示されます。プロジェクト ID を手動で入力することもできます。選択したプロジェクトは、課金とデータアクセスの両方に使用されます。プロジェクトを選択したら、データセットを選択します。
マイ プロジェクト
[マイ プロジェクト] オプションを使用すると、アクセス権があるプロジェクトを選択できます。プロジェクト ID を手動で入力することもできます。選択したプロジェクトは、課金とデータアクセスの両方に使用されます。プロジェクトを選択したら、データセットを選択します。
多くのプロジェクトへのアクセス権を持っている場合は、一部のプロジェクトが一覧に表示されない可能性があります。一覧のアイテム数が上限を超えてしまっている場合、一覧に表示されていないプロジェクトを入力フィールドに直接入力することができます。
共有プロジェクト
[共有プロジェクト] オプションを使用すると、共有されているプロジェクトにアクセスできます。データと課金に異なるプロジェクトを選択できます。
データセット
データセットは、データの整理とデータアクセスの制御に使用されます。リストからデータセットを選択するか、データセットを名前で検索します。
公開データセット
BigQuery の一般公開データセットは公開サンプルです。データセットは共有されますが、プロジェクトは共有されません。このデータに対してクエリを実行するには、独自の課金プロジェクトを指定する必要があります。ここで選択したプロジェクトが、共有データにおける処理費用の請求に使用されます。
テーブル
データポータルのデータソースは、単一のテーブルまたはビューに接続できます。
日付パーティション分割テーブルに接続する
データポータルでは、BigQuery の日付パーティション分割テーブルを利用できます。DATE、DATETIME、または TIMESTAMP フィールドでパーティション分割されたテーブルに接続すると、このデータソースに基づくグラフの期間ディメンションとしてそのフィールドを使用できます。
詳しくは、データポータルを BigQuery の日付パーティション分割テーブルに接続するをご覧ください。
カスタム SQL クエリを使用して BigQuery に接続する
[カスタムクエリ] オプションを使用すると、SQL を記述してデータに接続できます。カスタムクエリの構文は、標準 SQL 言語に準拠している必要があります。レガシーの BigQuery SQL 言語を使用する場合は、[レガシー SQL を使用する] オプションを選択します。
BigQuery ユーザー インターフェースを使用してクエリを作成し、テストしてから、そのクエリをコピーしてデータポータルのカスタムクエリ ボックスに貼り付けます。
課金プロジェクト
[課金プロジェクト] オプションを使用すると、プロジェクト ID を検索するか手動で入力することで、カスタムクエリの課金プロジェクトを指定できます。組織に多くの BigQuery プロジェクトがある場合は、手動入力でプロジェクトを探す必要があります。
あるプロジェクトを請求に使用し、別のプロジェクトをデータに使用するには、ユーザー インターフェースで課金プロジェクトを選択または入力して、カスタムクエリの SELECT...FROM 句でデータ プロジェクトを指定します。
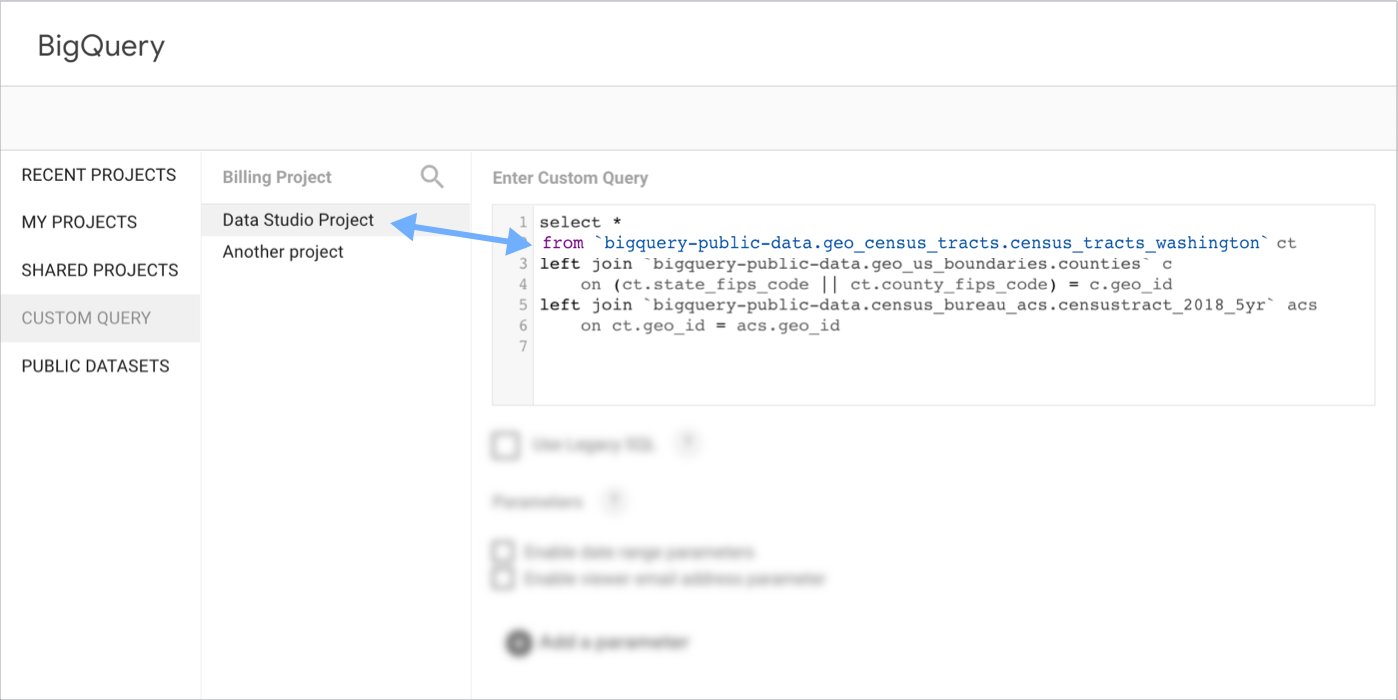
クエリ パラメータ
パラメータを使用すると、よりレスポンシブでカスタマイズ可能なレポートを作成できます。BigQuery データソースのパラメータは、基になるクエリに戻すことができます。カスタムクエリでパラメータを使用するには、BigQuery でのパラメータ化されたクエリの実行に関する構文ガイドラインをご覧ください。
詳しくは、カスタムクエリでパラメータを使用するをご覧ください。
カスタムクエリの制限事項
データポータルでは、データベースに対するクエリが生成されるたびに、カスタム SQL が内部 SELECT ステートメントとして使用されます。つまり、カスタムクエリで新しい仮想テーブルが生成され、データポータルは独自に生成した「外部」SQL を使用してそのテーブルをクエリします。そのため、データポータルのカスタムクエリには次の制限が適用されます。
カスタム SQL クエリに含めることができるステートメントは 1 つのみ
たとえば、以下は、複数の SQL ステートメントが含まれるため機能しません。
DECLARE cost_per_tb_in_dollar FLOAT64 DEFAULT 4.2;
SELECT total_bytes_billed / (1024 * 1024)* cost_per_tb_in_dollar)/(1024*1024))) FROM billing-table;
結合では明確なフィールド名を使用する
カスタム結合クエリは、重複する列名を処理できません。重複するフィールドを含むカスタムクエリに基づくデータソースを使用しているグラフには、次のようなユーザー設定エラーが表示されます。
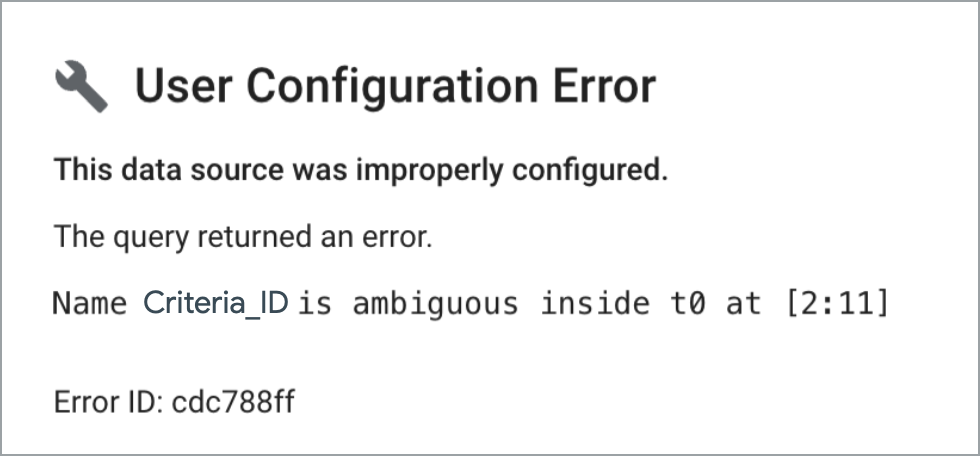
この問題を回避するため、カスタムクエリでは明確なフィールド名を使用するようにしてください。
たとえば、同じスキーマを持つ 2 つのテーブルを、両方のテーブルに存在する Criteria_ID フィールドで結合するとします。
SELECT * FROM (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_1'
) As table_1
LEFT JOIN (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_2'
) As table_2
ON
table_1.Criteria_ID = table_2.Criteria_ID
このクエリには、次の重複する列名が含まれています。
Criteria_IDParent_IDName
Field is ambiguous エラーを回避するには、AS キーワードを使用して重複するフィールドの名前を明示的に変更します。
SELECT *
FROM (
SELECT
Criteria_ID AS Criteria_ID_1,
Parent_ID AS Parent_ID_1,
Name AS NAME_1
FROM
'table_1' ) AS table_1
LEFT JOIN (
SELECT
Criteria_ID AS Criteria_ID_2,
Parent_ID AS Parent_ID_2,
Name AS NAME_2
FROM
'table_2' ) AS table_2
ON
table_1.Criteria_ID_1 = table_2.Criteria_ID_2;
名前を変更する必要があるフィールドが数個だけの場合は、名前を変更するフィールドを除くすべてのフィールドを選択することもできます。次に例を示します。
SELECT * EXCEPT (city), city AS city_1 FROM 'table_1'
クエリのタイムアウト
データポータルのカスタムクエリは 3 ~ 5 分後にタイムアウトする場合があります。カスタムクエリがタイムアウトした場合は、次の方法で問題を解決してみてください。
- 実行速度を上げるために、クエリを簡素化します。
- データベースでクエリを実行し、結果を別のテーブルに保存してからデータソース内のそのテーブルに接続します。
HTTP 504 Gateway timeoutエラーでクエリが引き続き失敗する場合は、カスタムクエリを BigQuery ビューまたはマテリアライズド ビューに移行し、そのビューに接続するようにデータポータルのデータソースを更新します。
複数日のテーブル
BigQuery は、複数のテーブルにまたがるクエリ実行をサポートしており、各テーブルは 1 日のデータを保持しています。テーブルの形式は YYYYMMDD です。テーブルの形式は YYYYMMDD です。データポータルが YYYYMMDD 形式のテーブルを見つけると、複数日のテーブルとしてマークされ、「prefix_YYYYMMDD」という名前のみがそのテーブルに表示されます。
グラフを作成してこのテーブルを可視化すると、データポータルによってデフォルトの期間である過去 28 日間のデータが自動的に生成され、過去 28 日間のテーブルに対するクエリが適切に実行されます。この設定を行うには、レポートを編集モードに切り替えてグラフを選択し、[データ] タブで [期間] プロパティを調整します。
BigQuery に発行された SQL を表示する
データポータルによって生成されたすべての BigQuery SQL は、BigQuery のクエリ履歴画面で確認できます。
レコード数指標
BigQuery データソースでは、[レコード数] 指標が自動的に表示されます。この指標を使用することで、ディメンションを分割し、レコード数をグラフごとに集計して表示することができます。
VPC Service Controls のサポート
データポータルは、閲覧者の IP ベースのアクセス権を使用して、VPC Service Controls(VPC-SC)境界で保護された BigQuery プロジェクトに接続できます。BigQuery コネクタはレポート閲覧者の IP アドレスを BigQuery に渡します。これにより、セットアップされている IP ベースのアクセスレベルを適用できます。
VPC Service Controls の障害のトラブルシューティング
予期しない VPC Service Controls の障害とそのトラブルシューティング方法について説明します。
- 問題の説明: プライマリ データセットが VPC-SC 境界外にある場合でも、VPN を使用せずにレポートを表示すると
Service Control Failureエラーが発生することがあります。 - 根本原因: このエラーは、VPC-SC 境界で保護されている課金プロジェクトを使用するレポート内の以前の BigQuery カスタムクエリ データソースまたは「ゴースト」BigQuery カスタムクエリ データソースが原因で発生することがよくあります。
回避策: これらの非表示のデータソースを特定して修正するには、次の手順を行います。
- 影響を受けるレポートのコピーを作成します。
- 新しいコピーで、[リソース] > [追加済みのデータソースの管理] に移動します。
- 「BigQuery カスタム SQL」ソースを見つけて、境界のない課金プロジェクトを使用するように更新するか、不要になった場合は削除します。
BigQuery の GEOGRAPHY ポリゴンを可視化する
レポートで Google マップの可視化を使用して、GEOGRAPHY ポリゴンを表示できます。チュートリアルについては、データポータルを使用して BigQuery GEOGRAPHY ポリゴンを可視化するをご覧ください。
ジョブラベルでデータポータルのクエリを分析する
データポータルから BigQuery に送信されるクエリには、すべて BigQuery のジョブラベル requestor:looker_studio が付いています。このジョブラベルを使用すると、データポータルに関連する BigQuery のクエリを特定できます。BigQuery のラベルの詳細については、BigQuery のドキュメント ページのラベルの表示をご覧ください。
BigQuery データソースのオーナーは、「BigQuery を活用」アイコンをクリックしてジョブの詳細を確認することもできます。
データポータルのグラフとレポートのパフォーマンスと費用を追跡する方法については、BigQuery のドキュメント ページの データポータルでデータを分析するをご覧ください。
BigQuery ダイアログ
BigQuery データソースのオーナー認証情報がある場合、データポータルでは、BigQuery を使用するグラフの右上隅に BigQuery アイコンが表示されます。グラフにカーソルを合わせ、BigQuery アイコンをクリックして [BigQuery] ダイアログを開きます。このダイアログには、BigQuery ジョブの詳細ページへのリンクが表示されます。BigQuery ジョブの詳細ページには、次の情報が表示されます。
- グラフの SQL クエリ
- SQL クエリが返したデータ
- クエリステップのステージごとの内訳
- 合計実行時間や使用されたスロットなどのクエリ統計情報
BigQuery Storage Read API でパフォーマンスを改善する
ページネーションされた結果を使用するクエリでは、BigQuery Storage Read API を有効にすると、クエリ時間を短縮できます。データポータルは、クエリの実行時間が短縮される場合に、Storage Read API を自動的に使用します。
BigQuery Storage Read API を有効にするには、データポータルに接続されている BigQuery ユーザーに次の権限を付与します。
bigquery.readsessions.createbigquery.readsessions.getData
割り当てと一般的な上限
一般に、BigQuery データソースには、BigQuery 自体と同じレート制限と割り当て制限が適用されます。
最大行数
BigQuery コネクタを使用して返すことができる最大行数は 200 万行です。データポータルでは、200 万行を超えるデータがある場合は表示されますが、行数は明示されません。
テーブルの最大数
BigQuery 接続の場合、データポータル コネクタを使用する際のデータセットあたりのテーブル数は 5,000 個に制限されています。この上限を超えると、データポータルがデータセットのテーブルリストを読み込むときに UI が応答しなくなることがあります。
この上限に達した場合は、次のいずれかの回避策を使用できます。
- カスタム クエリを使用する: テーブルに接続する代わりに、カスタム SQL クエリを使用して BigQuery に接続します。例:
SELECT * FROM project.dataset.table。 - BigQuery から接続する: BigQuery コンソールで、[エクスポート] または [データを探索] オプションを使用し、[Looker Studio で開く] を選択します。
- データセットを管理する: テーブルを 5,000 個未満のテーブルを含む小さなデータセットに再編成するか、必要なテーブルまたはビューのみを含む専用のレポート データセットを作成します。
MEDIAN 関数と PERCENTILE 関数
BigQuery データソースの場合、MEDIAN と PERCENTILE は BigQuery の APPROX_QUANTILES 関数を使用して実装されます。BigQuery からのデータに MEDIAN または PERCENTILE を適用すると、同じデータでも他の種類のデータソースからのデータに MEDIAN または PERCENTILE を適用した場合とは若干異なる結果が返されることがあります。
顧客管理の暗号鍵(CMEK)
BigQuery コネクタは、顧客管理の暗号鍵(CMEK)をサポートしていません。 Google Cloud プロジェクトが CMEK を必要とする組織のポリシーの対象である場合、データポータルはデータをクエリできず、CONDITION_NOT_MET エラーを返します。
TIME データ型
データポータルは、BigQuery の TIME データ型をサポートしていません。データセット内の TIME フィールドは、データポータルの TEXT フィールドに変換されます。レポートで時間データを可視化するには、次のいずれかの回避策を使用して TIME データを DATETIME データ型に変換します。
回避策 1: カスタムクエリを使用する
データポータルで BigQuery カスタムクエリをデータソースとして使用します。TIME フィールドを「ダミー」の日付と組み合わせて、データポータルでサポートされている DATETIME 値を作成します。
カスタム SQL クエリ
SELECT
*,
-- Combine a dummy date (1970-01-01) with your TIME field
DATETIME(DATE "1970-01-01", your_time_field) AS time_as_datetime
FROM
`your_project.your_dataset.your_table`
- 結果: データポータルは
time_as_datetimeを [日付と時刻] のデータ型として扱います。 - カスタマイズ: ダミーの日付を非表示にして、時刻部分のみを表示するには: レポートで time_as_datetime フィールドの [表示形式] を編集し、[時間] や [分] などの形式を選択するか、h:mm:ss などのカスタム形式を指定します。フィールドの表示形式の詳細
回避策 2: 計算フィールドを使用する
SQL クエリを変更したくない場合は、計算フィールドを使用してデータポータル内で直接変換を処理できます。この例では、BigQuery の TIME フィールドに「時:分:秒」形式(23:59:59 など)のデータが含まれていることを前提としています。
計算フィールドの数式
PARSE_DATETIME("%H:%M:%S", CAST(your_time_field AS TEXT))
- 結果:
PARSE_DATETIME関数は、文字列を [日付と時刻] オブジェクトに変換します。CAST関数は、your_time_fieldがTEXTとして扱われるようにします。文字列に日付が指定されていないため、データポータルでは日付部分が自動的に 1970 年 1 月 1 日に設定されます。PARSEDATE 関数の詳細をご覧ください。 - カスタマイズ: カスタムクエリの回避策と同様に、グラフの [設定] タブでフィールドの [表示形式] を変更して、グラフに関連する時間情報のみが表示されるようにします。