
Esta página descreve como ler várias tabelas de um banco de dados do Microsoft SQL Server usando a fonte Multi Table source. Use a fonte de várias tabelas quando quiser que o pipeline leia a partir de várias tabelas. Se você quiser que seu pipeline leia a partir de uma única tabela, consulte Como ler uma tabela do SQL Server.
A origem de várias tabelas gera dados com vários esquemas e inclui um campo de nome da tabela que indica a tabela de onde vieram os dados. Ao usar a fonte de várias tabelas, use um dos coletores de várias tabelas, BigQuery Multi Table ou GCS Multi File.
Antes de começar
- Faça login na sua Google Cloud conta do. Se você não conhece o Google Cloud, crie uma conta para avaliar a performance dos nossos produtos em cenários reais. Clientes novos também recebem US $300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Ative as APIs do Cloud Data Fusion, Cloud Storage, BigQuery e Dataproc.
Funções necessárias para ativar APIs
Para ativar as APIs, é necessário ter o papel do IAM de administrador de uso do serviço (
roles/serviceusage.serviceUsageAdmin), que contém a permissãoserviceusage.services.enable. Saiba como conceder papéis.- Crie uma instância do Cloud Data Fusion.
- Verifique se o banco de dados do SQL Server pode aceitar conexões do Cloud Data Fusion. Para fazer isso com segurança, recomendamos que você crie uma instância particular do Cloud Data Fusion.
Conferir a instância do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o Google Cloud console e a interface separada do Cloud Data Fusion. No Google Cloud consol, é possível criar um Google Cloud projeto e criar e excluir instâncias do Cloud Data Fusion. Na interface do Cloud Data Fusion, é possível usar as várias páginas, como o Studio ou o Administrador, para usar os recursos do Cloud Data Fusion.
No console Google Cloud , acesse a página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e em Ver instância.
Armazenar a senha do SQL Server como uma chave segura
Adicione a senha do SQL Server como uma chave segura para criptografar na instância do Cloud Data Fusion. Posteriormente neste guia, você garantirá que sua senha seja recuperada usando o Cloud KMS.
No canto superior direito de qualquer página do Cloud Data Fusion, clique em Administrador do sistema.
Clique na guia Configuration.
Clique em Fazer chamadas HTTP.

No menu suspenso, escolha PUT.
No campo do caminho, digite
namespaces/NAMESPACE_ID/securekeys/PASSWORD.No campo Corpo, digite
{"data":"SQL_SERVER_PASSWORD"}.Clique em Enviar.
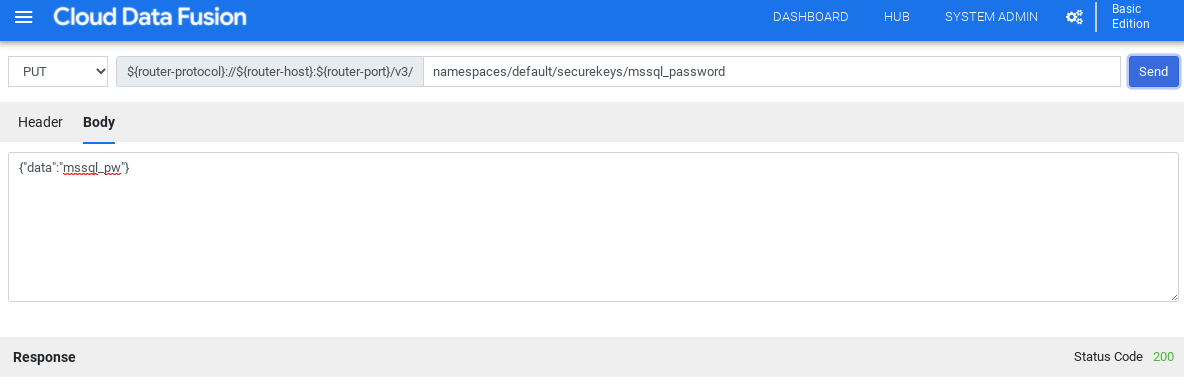
Verifique se a Resposta recebida é o código de status 200.
Acessar o driver JDBC para SQL Server
Usando o Hub
Na interface do Cloud Data Fusion, clique em Hub.
Na barra de pesquisa, digite
Microsoft SQL Server JDBC Driver.Clique em Driver JDBC do Microsoft SQL Server.
Clique em Fazer download. Siga as etapas de download mostradas.
Clique em Implantar. Faça o upload do arquivo JAR na etapa anterior.
Clique em Concluir.
Usando o Studio
Acesse Microsoft.com.
Escolha o download e clique em Fazer o download.
Na interface do Cloud Data Fusion, clique em Menu e navegue até a página Studio.
Clique em Adicionar.
Em Driver, clique em Fazer upload.
Faça o upload do arquivo JAR baixado na etapa 2.
Clique em Próxima.
Configure o driver inserindo um Nome.
No campo Nome da classe, digite
com.microsoft.sqlserver.jdbc.SQLServerDriver.Clique em Concluir.
Implantar os plug-ins de várias tabelas
Na UI da Web do Cloud Data Fusion, clique em Hub.
Na barra de pesquisa, digite
Multiple table plugins.Clique em Múltiplos plug-ins de tabela.
Clique em Implantar.
Clique em Concluir.
Clique em Criar um pipeline.
Conectar-se ao SQL Server
Na interface do Cloud Data Fusion, clique em Menu e navegue até a página Studio.
No Studio, expanda o menu Origem.
Clique em Várias tabelas de banco de dados.
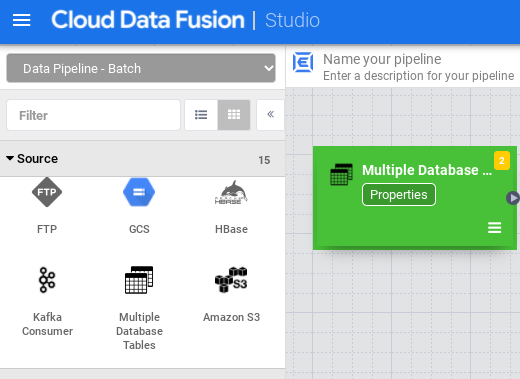
Coloque o ponteiro sobre o nó Várias tabelas de banco de dados e clique em Propriedades.
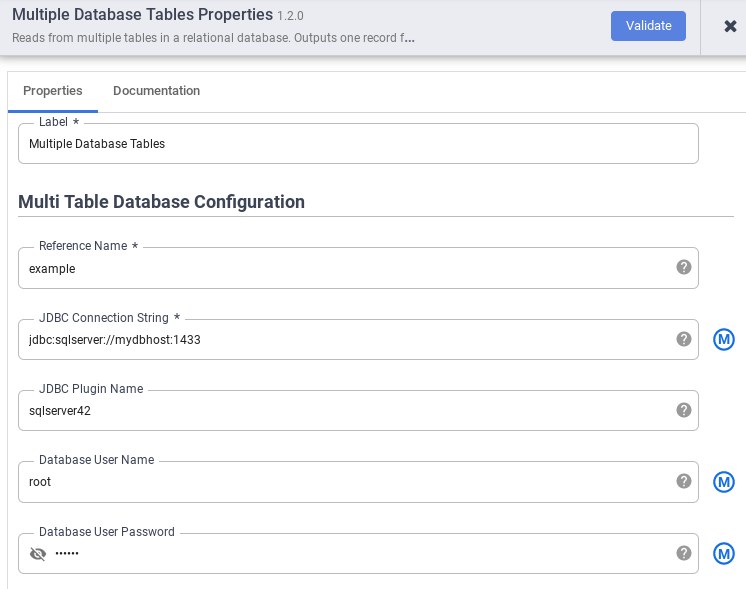
No campo Nome de referência, especifique um nome de referência que será usado para identificar sua origem do SQL Server.
No campo String de conexão JDBC, insira a string de conexão JDBC. Por exemplo,
jdbc:sqlserver://mydbhost:1433. Para mais informações, consulte Como criar o URL de conexão.Insira o Nome do plug-in JDBC, o Nome de usuário do banco de dados e a Senha do usuário do banco de dados.
Clique em Validar.
Clique em Fechar.
Conectar ao BigQuery ou ao Cloud Storage
Na interface do Cloud Data Fusion, clique em Menu e navegue até a página Studio.
Expanda Coletor.
Clique em BigQuery Multi Table ou GCS Multi File.
Conecte o nó Várias tabelas de banco de dados com BigQuery Multi Table ou GCS Multi File.
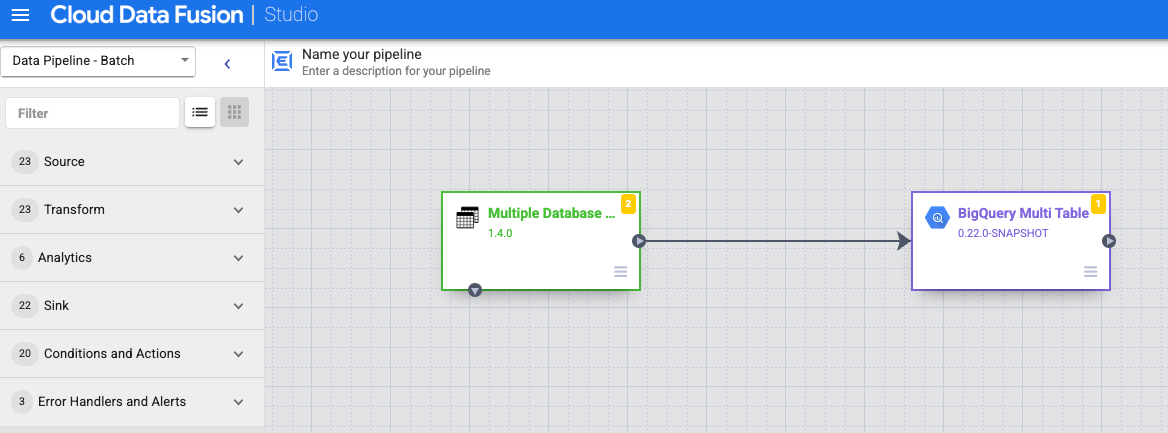
Mantenha o ponteiro sobre o BigQuery Multi Table ou GCS Multi File nó, clique em Properties e configure o coletor.
Para mais informações, consulte Coletor de várias tabelas do Google BigQuery e Coletor de vários arquivos do Google Cloud Storage.
Clique em Validar.
Clique em Fechar.
Executar a visualização do pipeline
Na interface do Cloud Data Fusion, clique em Menu e navegue até a página Studio.
Clique em Visualização.
Clique em Executar. Aguarde a conclusão da visualização.
Implantar o pipeline
Na interface do Cloud Data Fusion, clique em Menu e navegue até a página Studio.
Clique em Implantar.
Executar o pipeline
Na interface do Cloud Data Fusion, clique em Menu.
Clique em Lista.
Clique no pipeline.
Na página de detalhes do pipeline, clique em Executar.
A seguir
- Saiba mais sobre o Cloud Data Fusion.
- Siga um dos tutoriais.