
本教學課程將逐步引導您使用 Distributed Replicated Block Device (DRBD) 和 Compute Engine,將 MySQL 5.6 資料庫部署至Google Cloud 。DRBD 是 Linux 平台的分散式複製儲存系統。
如果您是系統管理員、開發人員、工程師、資料庫管理員或 DevOps 工程師,本教學課程將會非常實用。您可能會想要管理自訂的 MySQL 執行個體,而非使用代管服務,原因如下:
- 您正在使用 MySQL 的跨地區執行個體。
- 您需要設定在 MySQL 代管版本中無法使用的參數。
- 您所希望的最佳化效能在代管版本中無法設定。
DRBD 提供封鎖裝置等級的複製功能。這表示您不需要在 MySQL 本身中設定複製功能,就可立即享有 DRBD 的優點,例如支援負載平衡的讀取和安全連線。
本教學課程使用下列項目:
雖然本說明文件有參考 MySQL 叢集、DRBD 配置和 Linux 資源管理等進階功能,但是使用這些資源並不需要進階知識。
架構
Pacemaker 是叢集資源管理員。Corosync 是 Pacemaker 所使用的叢集通訊與參與套件。在本教學課程中,您會使用 DRBD 將 MySQL 磁碟從主要執行個體複製到待命執行個體。為了讓用戶端連線至 MySQL 叢集,您也需要部署內部負載平衡器。
您部署由三個運算執行個體所組成的 Pacemaker 代管叢集。您會在其中兩個執行個體上安裝 MySQL,這兩個執行個體的功能分別為主要與待命執行個體。第三個執行個體的作用則是仲裁裝置。
在叢集中,每個節點都會投票選擇作為有效節點的節點 (負責執行 MySQL)。在雙節點叢集中,只需投票一次即可決定有效節點。在這種情況下,叢集行為可能會導致核心分裂問題或停機。當兩個節點都可主導即會發生核心分裂問題,原因在於雙節點的情況中只需要投票一次。如果關閉的是連線中斷時一律設為主要執行個體的節點,就會發生停機狀況。如果兩個節點之間的連線中斷,可能會有不只一個叢集節點假設本身才是有效節點。
加入仲裁裝置可避免這種情況發生。仲裁裝置的功能為仲裁者,其唯一的工作就是投票。如此一來,在 database1 和 database2 執行個體無法通訊的情況下,此仲裁裝置節點可以與兩個執行個體之一通訊,並仍可達成多數決的結果。
下圖顯示此處所說明的系統架構。

目標
- 建立叢集執行個體。
- 在其中的兩個執行個體上安裝 MySQL 和 DRBD。
- 設定 DRBD 複製功能。
- 在執行個體上安裝 Pacemaker。
- 在執行個體上設定 Pacemaker 叢集。
- 建立執行個體並將其設為仲裁裝置。
- 測試容錯移轉。
費用
使用 Pricing Calculator 可根據您的預測使用量來產生預估費用。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
在本教學課程中,除非另有說明,否則請使用 Cloud Shell 輸入指令。
完成本文所述工作後,您可以刪除建立的資源,避免繼續計費,詳情請參閱「清除所用資源」一節。
開始設定
在本節中,您將設定服務帳戶、建立環境變數並保留 IP 位址。
為叢集執行個體設定服務帳戶
開啟 Cloud Shell:
建立服務帳戶:
gcloud iam service-accounts create mysql-instance \ --display-name "mysql-instance"將本教學課程所需的角色附加至服務帳戶:
gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.instanceAdmin.v1 gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/compute.viewer gcloud projects add-iam-policy-binding ${DEVSHELL_PROJECT_ID} \ --member=serviceAccount:mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/iam.serviceAccountUser
建立 Cloud Shell 環境變數
建立具有本教學課程所需環境變數的檔案:
cat <<EOF > ~/.mysqldrbdrc # Cluster instance names DATABASE1_INSTANCE_NAME=database1 DATABASE2_INSTANCE_NAME=database2 QUORUM_INSTANCE_NAME=qdevice CLIENT_INSTANCE_NAME=mysql-client # Cluster IP addresses DATABASE1_INSTANCE_IP="10.140.0.2" DATABASE2_INSTANCE_IP="10.140.0.3" QUORUM_INSTANCE_IP="10.140.0.4" ILB_IP="10.140.0.6" # Cluster zones and region DATABASE1_INSTANCE_ZONE="asia-east1-a" DATABASE2_INSTANCE_ZONE="asia-east1-b" QUORUM_INSTANCE_ZONE="asia-east1-c" CLIENT_INSTANCE_ZONE="asia-east1-c" CLUSTER_REGION="asia-east1" EOF在目前工作階段中載入環境變數,然後設定 Cloud Shell 在使用者未來登入時自動載入變數:
source ~/.mysqldrbdrc grep -q -F "source ~/.mysqldrbdrc" ~/.bashrc || echo "source ~/.mysqldrbdrc" >> ~/.bashrc
保留 IP 位址
在 Cloud Shell 中,為三個叢集節點分別保留內部 IP 位址:
gcloud compute addresses create ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} ${QUORUM_INSTANCE_NAME} \ --region=${CLUSTER_REGION} \ --addresses "${DATABASE1_INSTANCE_IP},${DATABASE2_INSTANCE_IP},${QUORUM_INSTANCE_IP}" \ --subnet=default
建立 Compute Engine 執行個體
在以下步驟中,叢集執行個體使用 Debian 9,而用戶端執行個體則使用 Ubuntu 16。
在 Cloud Shell 中,在
asia-east1-a區域中建立名為database1的 MySQL 執行個體:gcloud compute instances create ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE1_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-1 \ --private-network-ip=${DATABASE1_INSTANCE_NAME} \ --tags=mysql --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"在
asia-east1-b區域中建立名為database2的 MySQL 執行個體:gcloud compute instances create ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --machine-type=n1-standard-2 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=50GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${DATABASE2_INSTANCE_NAME} \ --create-disk=mode=rw,size=300,type=pd-standard,name=disk-2 \ --private-network-ip=${DATABASE2_INSTANCE_NAME} \ --tags=mysql \ --service-account=mysql-instance@${DEVSHELL_PROJECT_ID}.iam.gserviceaccount.com \ --scopes="https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly" \ --metadata="DATABASE1_INSTANCE_IP=${DATABASE1_INSTANCE_IP},DATABASE2_INSTANCE_IP=${DATABASE2_INSTANCE_IP},DATABASE1_INSTANCE_NAME=${DATABASE1_INSTANCE_NAME},DATABASE2_INSTANCE_NAME=${DATABASE2_INSTANCE_NAME},QUORUM_INSTANCE_NAME=${QUORUM_INSTANCE_NAME},DATABASE1_INSTANCE_ZONE=${DATABASE1_INSTANCE_ZONE},DATABASE2_INSTANCE_ZONE=${DATABASE2_INSTANCE_ZONE}"建立供 Pacemaker 在
asia-east1-c區域使用的仲裁節點:gcloud compute instances create ${QUORUM_INSTANCE_NAME} \ --zone=${QUORUM_INSTANCE_ZONE} \ --machine-type=n1-standard-1 \ --network-tier=PREMIUM \ --maintenance-policy=MIGRATE \ --image-family=debian-9 \ --image-project=debian-cloud \ --boot-disk-size=10GB \ --boot-disk-type=pd-standard \ --boot-disk-device-name=${QUORUM_INSTANCE_NAME} \ --private-network-ip=${QUORUM_INSTANCE_NAME}建立 MySQL 用戶端執行個體:
gcloud compute instances create ${CLIENT_INSTANCE_NAME} \ --image-family=ubuntu-1604-lts \ --image-project=ubuntu-os-cloud \ --tags=mysql-client \ --zone=${CLIENT_INSTANCE_ZONE} \ --boot-disk-size=10GB \ --metadata="ILB_IP=${ILB_IP}"
安裝和設定 DRBD
在本節中,您會在 database1 和 database2 執行個體上安裝並設定 DRBD 套件,然後啟動從 database1 至 database2 的 DRBD 複製。
在 database1 上設定 DRBD
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面:
在
database1執行個體的資料列中,按一下「SSH」SSH以連線至執行個體。建立檔案以擷取並儲存環境變數中的執行個體中繼資料:
sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOF從檔案載入中繼資料變數:
source ~/.varsrc格式化資料磁碟:
sudo bash -c "mkfs.ext4 -m 0 -F -E \ lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"如需
mkfs.ext4選項的詳細說明,請參閱 mkfs.ext4 manpage。安裝 DRBD:
sudo apt -y install drbd8-utils建立 DRBD 設定檔:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'建立 DRBD 資源檔案:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on database1 { disk /dev/sdb; address 10.140.0.2:7789; } on database2 { disk /dev/sdb; address 10.140.0.3:7789; } } EOF"載入 DRBD 核心模組:
sudo modprobe drbd清除
/dev/sdb磁碟中的內容:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024建立 DRBD 資源
r0:sudo drbdadm create-md r0啟用 DRBD:
sudo drbdadm up r0在系統啟動時停用 DRBD,使叢集資源管理軟體依序啟用所有必要的服務:
sudo update-rc.d drbd disable
在 database2 上設定 DRBD
現在請在 database2 執行個體上安裝和設定 DRBD 套件。
- 透過 SSH 連線至
database2執行個體。 建立
.varsrc檔案,以擷取並儲存環境變數中的執行個體中繼資料:sudo bash -c cat <<EOF > ~/.varsrc DATABASE1_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_IP" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_NAME" -H "Metadata-Flavor: Google") DATABASE2_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE2_INSTANCE_ZONE" -H "Metadata-Flavor: Google") DATABASE1_INSTANCE_ZONE=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/DATABASE1_INSTANCE_ZONE" -H "Metadata-Flavor: Google") QUORUM_INSTANCE_NAME=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/QUORUM_INSTANCE_NAME" -H "Metadata-Flavor: Google") EOF從這個檔案載入中繼資料變數:
source ~/.varsrc格式化資料磁碟:
sudo bash -c "mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb"安裝 DRBD 套件:
sudo apt -y install drbd8-utils建立 DRBD 設定檔:
sudo bash -c 'cat <<EOF > /etc/drbd.d/global_common.conf global { usage-count no; } common { protocol C; } EOF'建立 DRBD 資源檔案:
sudo bash -c "cat <<EOF > /etc/drbd.d/r0.res resource r0 { meta-disk internal; device /dev/drbd0; net { allow-two-primaries no; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; rr-conflict disconnect; } on ${DATABASE1_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE1_INSTANCE_IP}:7789; } on ${DATABASE2_INSTANCE_NAME} { disk /dev/sdb; address ${DATABASE2_INSTANCE_IP}:7789; } } EOF"載入 DRBD 核心模組:
sudo modprobe drbd清除
/dev/sdb磁碟:sudo dd if=/dev/zero of=/dev/sdb bs=1k count=1024建立 DRBD 資源
r0:sudo drbdadm create-md r0啟用 DRBD:
sudo drbdadm up r0在系統啟動時停用 DRBD,使叢集資源管理軟體依序啟用所有必要的服務:
sudo update-rc.d drbd disable
啟動從 database1 到 database2 的 DRBD 複製功能
- 透過 SSH 連線至
database1執行個體。 覆寫主要節點上的所有
r0資源:sudo drbdadm -- --overwrite-data-of-peer primary r0 sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/drbd0驗證 DRBD 的狀態:
sudo cat /proc/drbd | grep ============輸出如下所示:
[===================>] sync'ed:100.0% (208/307188)M
將
/dev/drbd掛接到/srv:sudo mount -o discard,defaults /dev/drbd0 /srv
安裝 MySQL 和 Pacemaker
在本節中,您將在每個執行個體上安裝 MySQ L和 Pacemaker。
在 database1 上安裝 MySQL
- 透過 SSH 連線至
database1執行個體。 使用 MySQL 5.6 套件定義更新 APT 存放區:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'將 GPG 金鑰新增至 APT
repository.srv檔案:wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysql更新套件清單:
sudo apt update安裝 MySQL 伺服器:
sudo apt -y install mysql-server系統提示輸入密碼時,請輸入
DRBDha2。停止 MySQL 伺服器:
sudo /etc/init.d/mysql stop建立 MySQL 設定檔:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'為 MySQL 伺服器建立臨時目錄 (在
mysql.conf中設定):sudo mkdir /srv/tmp sudo chmod 1777 /srv/tmp將所有 MySQL 資料移至 DRBD 目錄
/srv/mysql:sudo mv /var/lib/mysql /srv/mysql在 DRBD 複製的儲存空間磁碟區下將
/var/lib/mysql連結至/srv/mysql:sudo ln -s /srv/mysql /var/lib/mysql將
/srv/mysql擁有者變更為mysql程序:sudo chown -R mysql:mysql /srv/mysql移除
InnoDB初始資料,確保磁碟盡可能乾淨:sudo bash -c "cd /srv/mysql && rm ibdata1 && rm ib_logfile*"InnoDB 是 MySQL 資料庫管理系統的儲存引擎。
啟動 MySQL:
sudo /etc/init.d/mysql start授予超級使用者遠端連線的存取權,以便在稍後測試部署:
mysql -uroot -pDRBDha2 -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'DRBDha2' WITH GRANT OPTION;"停用 MySQL 自動啟動功能,由叢集資源管理來啟動:
sudo update-rc.d -f mysql disable
在 database1 上安裝 Pacemaker
從先前建立的
.varsrc檔案載入中繼資料變數:source ~/.varsrc停止 MySQL 伺服器:
sudo /etc/init.d/mysql stop安裝 Pacemaker:
sudo apt -y install pcs在主要執行個體上的系統啟動時啟用
pcsd、corosync和pacemaker:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enable設定
corosync在pacemaker之前啟動:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10將叢集使用者密碼設為
haCLUSTER3以進行驗證:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"執行
corosync-keygen指令碼以產生 128 位元的叢集授權金鑰,並將其寫入/etc/corosync/authkey:sudo corosync-keygen -l將
authkey複製到database2執行個體。在系統提示您輸入通關密語時按下Enter鍵:sudo chmod 444 /etc/corosync/authkey gcloud beta compute scp /etc/corosync/authkey ${DATABASE2_INSTANCE_NAME}:~/authkey --zone=${DATABASE2_INSTANCE_ZONE} --internal-ip sudo chmod 400 /etc/corosync/authkey建立 Corosync 叢集設定檔:
sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"在
totem區段中所設定的 Totem 協議可提供可靠的通訊。Corosync 使用此通訊來控制叢集的成員資格,並指定叢集成員互相通訊的方式。其中的重要設定如下:
transport:指定單點傳播模式 (udpu)。Bindnetaddr:指定 Corosync 所繫結的網路位址。nodelist:定義叢集中的節點,以及如何與其連線 (在本例中指的是database1和database2節點)。quorum/two_node:根據預設,在雙節點叢集中不會有節點取得仲裁。您可以在quorum區段中為two_node指定值「1」來覆寫此預設值。
這設定可讓您設定叢集,並做好之後新增第三個仲裁裝置節點時的準備。
建立
corosync的服務目錄:sudo mkdir -p /etc/corosync/service.d設定
corosync使其注意到 Pacemaker:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'預設啟用
corosync服務:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'重新啟動
corosync和pacemaker服務:sudo service corosync restart sudo service pacemaker restart安裝 Corosync 仲裁裝置套件:
sudo apt -y install corosync-qdevice安裝殼層指令碼來處理 DRBD 的失敗事件:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.log
在 database2 上安裝 MySQL
- 透過 SSH 連線至
database2執行個體。 使用 MySQL 5.6 套件更新 APT 存放區:
sudo bash -c 'cat <<EOF > /etc/apt/sources.list.d/mysql.list deb http://repo.mysql.com/apt/debian/ stretch mysql-5.6\ndeb-src http://repo.mysql.com/apt/debian/ stretch mysql-5.6 EOF'將 GPG 金鑰新增到 APT 存放區:
wget -O /tmp/RPM-GPG-KEY-mysql https://repo.mysql.com/RPM-GPG-KEY-mysql sudo apt-key add /tmp/RPM-GPG-KEY-mysql更新套件清單:
sudo apt update安裝 MySQL 伺服器:
sudo apt -y install mysql-server系統提示輸入密碼時,請輸入
DRBDha2。停止 MySQL 伺服器:
sudo /etc/init.d/mysql stop建立 MySQL 設定檔:
sudo bash -c 'cat <<EOF > /etc/mysql/mysql.conf.d/my.cnf [mysqld] bind-address = 0.0.0.0 # You may want to listen at localhost at the beginning datadir = /var/lib/mysql tmpdir = /srv/tmp user = mysql EOF'移除
/var/lib/mysql下的資料,並為複製 DRBD 磁碟區的掛接目標新增符號連結。只有在發生容錯移轉時,DRBD 磁碟區 (/dev/drbd0) 才會掛接在/srv。sudo rm -rf /var/lib/mysql sudo ln -s /srv/mysql /var/lib/mysql停用 MySQL 自動啟動功能,由叢集資源管理來啟動:
sudo update-rc.d -f mysql disable
在 database2 上安裝 Pacemaker
從
.varsrc檔案載入中繼資料變數:source ~/.varsrc安裝 Pacemaker:
sudo apt -y install pcs將之前複製的 Corosync
authkey檔案移動至/etc/corosync/:sudo mv ~/authkey /etc/corosync/ sudo chown root: /etc/corosync/authkey sudo chmod 400 /etc/corosync/authkey在待命執行個體的系統啟動時啟用
pcsd、corosync和pacemaker:sudo update-rc.d -f pcsd enable sudo update-rc.d -f corosync enable sudo update-rc.d -f pacemaker enable設定
corosync在pacemaker之前啟動:sudo update-rc.d corosync defaults 20 20 sudo update-rc.d pacemaker defaults 30 10設定叢集使用者密碼以進行驗證。密碼與您在
database1執行個體所使用的密碼相同 (haCLUSTER3)。sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"建立
corosync設定檔:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum two_node: 1 } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"建立 Corosync 服務目錄:
sudo mkdir /etc/corosync/service.d設定
corosync使其注意到 Pacemaker:sudo bash -c 'cat <<EOF > /etc/corosync/service.d/pcmk service { name: pacemaker ver: 1 } EOF'預設啟用
corosync服務:sudo bash -c 'cat <<EOF > /etc/default/corosync # Path to corosync.conf COROSYNC_MAIN_CONFIG_FILE=/etc/corosync/corosync.conf # Path to authfile COROSYNC_TOTEM_AUTHKEY_FILE=/etc/corosync/authkey # Enable service by default START=yes EOF'重新啟動
corosync和pacemaker服務:sudo service corosync restart sudo service pacemaker restart安裝 Corosync 仲裁裝置套件:
sudo apt -y install corosync-qdevice安裝殼層指令碼來處理 DRBD 的失敗事件:
sudo bash -c 'cat << 'EOF' > /var/lib/pacemaker/drbd_cleanup.sh #!/bin/sh if [ -z \$CRM_alert_version ]; then echo "\$0 must be run by Pacemaker version 1.1.15 or later" exit 0 fi tstamp="\$CRM_alert_timestamp: " case \$CRM_alert_kind in resource) if [ \${CRM_alert_interval} = "0" ]; then CRM_alert_interval="" else CRM_alert_interval=" (\${CRM_alert_interval})" fi if [ \${CRM_alert_target_rc} = "0" ]; then CRM_alert_target_rc="" else CRM_alert_target_rc=" (target: \${CRM_alert_target_rc})" fi case \${CRM_alert_desc} in Cancelled) ;; *) echo "\${tstamp}Resource operation "\${CRM_alert_task}\${CRM_alert_interval}" for "\${CRM_alert_rsc}" on "\${CRM_alert_node}": \${CRM_alert_desc}\${CRM_alert_target_rc}" >> "\${CRM_alert_recipient}" if [ "\${CRM_alert_task}" = "stop" ] && [ "\${CRM_alert_desc}" = "Timed Out" ]; then echo "Executing recovering..." >> "\${CRM_alert_recipient}" pcs resource cleanup \${CRM_alert_rsc} fi ;; esac ;; *) echo "\${tstamp}Unhandled \$CRM_alert_kind alert" >> "\${CRM_alert_recipient}" env | grep CRM_alert >> "\${CRM_alert_recipient}" ;; esac EOF' sudo chmod 0755 /var/lib/pacemaker/drbd_cleanup.sh sudo touch /var/log/pacemaker_drbd_file.log sudo chown hacluster:haclient /var/log/pacemaker_drbd_file.log檢查 Corosync 叢集狀態:
sudo corosync-cmapctl | grep "members...ip"輸出如下所示:
runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(10.140.0.2) runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(10.140.0.3)
啟動叢集
- 透過 SSH 連線至
database2執行個體。 從
.varsrc檔案載入中繼資料變數:source ~/.varsrc針對叢集節點進行驗證:
sudo pcs cluster auth --name mysql_cluster ${DATABASE1_INSTANCE_NAME} ${DATABASE2_INSTANCE_NAME} -u hacluster -p haCLUSTER3啟動叢集:
sudo pcs cluster start --all驗證叢集狀態:
sudo pcs status輸出如下所示:
Cluster name: mysql_cluster WARNING: no stonith devices and stonith-enabled is not false Stack: corosync Current DC: database2 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sat Nov 3 07:24:53 2018 Last change: Sat Nov 3 07:17:17 2018 by hacluster via crmd on database2 2 nodes configured 0 resources configured Online: [ database1 database2 ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
設定 Pacemaker 以管理叢集資源
接下來,請使用 DRBD、磁碟、MySQL 和仲裁資源來設定 Pacemaker。
- 透過 SSH 連線至
database1執行個體。 使用 Pacemaker
pcs公用程式將多個變更排入檔案,然後自動將這些變更推送到 Cluster Information Base (CIB):sudo pcs cluster cib clust_cfg停用 STONITH,因為之後您將會部署仲裁裝置:
sudo pcs -f clust_cfg property set stonith-enabled=false停用仲裁相關設定。稍後會設定仲裁裝置節點。
sudo pcs -f clust_cfg property set no-quorum-policy=stop防止 Pacemaker 在復原後移回資源:
sudo pcs -f clust_cfg resource defaults resource-stickiness=200在叢集中建立 DRBD 資源:
sudo pcs -f clust_cfg resource create mysql_drbd ocf:linbit:drbd \ drbd_resource=r0 \ op monitor role=Master interval=110 timeout=30 \ op monitor role=Slave interval=120 timeout=30 \ op start timeout=120 \ op stop timeout=60確保只有一個主要角色指派給 DRBD 資源:
sudo pcs -f clust_cfg resource master primary_mysql mysql_drbd \ master-max=1 master-node-max=1 \ clone-max=2 clone-node-max=1 \ notify=true建立要掛接 DRBD 磁碟的檔案系統資源:
sudo pcs -f clust_cfg resource create mystore_FS Filesystem \ device="/dev/drbd0" \ directory="/srv" \ fstype="ext4"設定叢集以將 DRBD 資源與同一個 VM 上的磁碟資源並置:
sudo pcs -f clust_cfg constraint colocation add mystore_FS with primary_mysql INFINITY with-rsc-role=Master設定叢集只在升級 DRBD 主要執行個體後啟用磁碟資源:
sudo pcs -f clust_cfg constraint order promote primary_mysql then start mystore_FS建立 MySQL 服務:
sudo pcs -f clust_cfg resource create mysql_service ocf:heartbeat:mysql \ binary="/usr/bin/mysqld_safe" \ config="/etc/mysql/my.cnf" \ datadir="/var/lib/mysql" \ pid="/var/run/mysqld/mysql.pid" \ socket="/var/run/mysqld/mysql.sock" \ additional_parameters="--bind-address=0.0.0.0" \ op start timeout=60s \ op stop timeout=60s \ op monitor interval=20s timeout=30s設定叢集以將 MySQL 資源與同一個 VM 上的磁碟資源並置:
sudo pcs -f clust_cfg constraint colocation add mysql_service with mystore_FS INFINITY確認 DRBD 檔案系統的啟動順序在 MySQL 服務之前:
sudo pcs -f clust_cfg constraint order mystore_FS then mysql_service建立快訊代理程式,並將修補程式新增至記錄檔作為其接收者:
sudo pcs -f clust_cfg alert create id=drbd_cleanup_file description="Monitor DRBD events and perform post cleanup" path=/var/lib/pacemaker/drbd_cleanup.sh sudo pcs -f clust_cfg alert recipient add drbd_cleanup_file id=logfile value=/var/log/pacemaker_drbd_file.log修訂叢集的變更:
sudo pcs cluster cib-push clust_cfg驗證所有資源皆在線上:
sudo pcs status輸出如下所示:
Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1
設定仲裁裝置
- 透過 SSH 連線至
qdevice執行個體。 安裝
pcs和corosync-qnetd:sudo apt update && sudo apt -y install pcs corosync-qnetd啟動 Pacemaker 或 Corosync 設定系統精靈 (
pcsd) 服務,並在系統啟動時啟用該服務:sudo service pcsd start sudo update-rc.d pcsd enable設定叢集使用者密碼 (
haCLUSTER3) 以進行驗證:sudo bash -c "echo hacluster:haCLUSTER3 | chpasswd"檢查仲裁裝置狀態:
sudo pcs qdevice status net --full輸出如下所示:
QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytes
設定 database1 的仲裁裝置設定
- 透過 SSH 連線至
database1節點。 從
.varsrc檔案載入中繼資料變數:source ~/.varsrc驗證叢集的仲裁裝置節點:
sudo pcs cluster auth --name mysql_cluster ${QUORUM_INSTANCE_NAME} -u hacluster -p haCLUSTER3將仲裁裝置新增至叢集。使用
ffsplit演算法,確保會根據 50% 以上的投票結果決定有效節點:sudo pcs quorum device add model net host=${QUORUM_INSTANCE_NAME} algorithm=ffsplit將仲裁設定新增至
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE1_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"重新啟動
corosync服務,重新載入新的仲裁裝置設定:sudo service corosync restart啟動
corosync仲裁裝置精靈,並在系統啟動時將其啟用:sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
在 database2 上設定仲裁裝置設定
- 透過 SSH 連線至
database2節點。 從
.varsrc檔案載入中繼資料變數:source ~/.varsrc將仲裁設定新增至
corosync.conf:sudo bash -c "cat <<EOF > /etc/corosync/corosync.conf totem { version: 2 cluster_name: mysql_cluster transport: udpu interface { ringnumber: 0 Bindnetaddr: ${DATABASE2_INSTANCE_IP} broadcast: yes mcastport: 5405 } } quorum { provider: corosync_votequorum device { votes: 1 model: net net { tls: on host: ${QUORUM_INSTANCE_NAME} algorithm: ffsplit } } } nodelist { node { ring0_addr: ${DATABASE1_INSTANCE_NAME} name: ${DATABASE1_INSTANCE_NAME} nodeid: 1 } node { ring0_addr: ${DATABASE2_INSTANCE_NAME} name: ${DATABASE2_INSTANCE_NAME} nodeid: 2 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log timestamp: on } EOF"重新啟動
corosync服務,重新載入新的仲裁裝置設定:sudo service corosync restart啟動 Corosync 仲裁裝置精靈,並在系統啟動時將其啟用:
sudo service corosync-qdevice start sudo update-rc.d corosync-qdevice defaults
驗證叢集狀態
接下來要驗證叢集資源是否在線上。
- 透過 SSH 連線至
database1執行個體。 驗證叢集狀態:
sudo pcs status輸出如下所示:
Cluster name: mysql_cluster Stack: corosync Current DC: database1 (version 1.1.16-94ff4df) - partition with quorum Last updated: Sun Nov 4 01:49:18 2018 Last change: Sat Nov 3 15:48:21 2018 by root via cibadmin on database1 2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled顯示仲裁狀態:
sudo pcs quorum status輸出如下所示:
Quorum information ------------------ Date: Sun Nov 4 01:48:25 2018 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/24 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW database1 (local) 2 1 A,V,NMW database2 0 1 Qdevice顯示仲裁裝置狀態:
sudo pcs quorum device status輸出如下所示:
Qdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mysql_cluster QNetd host: qdevice:5403 Algorithm: Fifty-Fifty split Tie-breaker: Node with lowest node ID State: Connected
將內部負載平衡器設定為叢集 IP
開啟 Cloud Shell:
建立非代管執行個體群組,並將
database1執行個體新增至該群組:gcloud compute instance-groups unmanaged create ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --description="${DATABASE1_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE1_INSTANCE_NAME}-instance-group \ --zone=${DATABASE1_INSTANCE_ZONE} \ --instances=${DATABASE1_INSTANCE_NAME}建立非代管執行個體群組,並將
database2執行個體新增至該群組:gcloud compute instance-groups unmanaged create ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --description="${DATABASE2_INSTANCE_NAME} unmanaged instance group" gcloud compute instance-groups unmanaged add-instances ${DATABASE2_INSTANCE_NAME}-instance-group \ --zone=${DATABASE2_INSTANCE_ZONE} \ --instances=${DATABASE2_INSTANCE_NAME}為
port 3306建立健康狀態檢查:gcloud compute health-checks create tcp mysql-backend-healthcheck \ --port 3306建立地區性內部後端服務:
gcloud compute backend-services create mysql-ilb \ --load-balancing-scheme internal \ --region ${CLUSTER_REGION} \ --health-checks mysql-backend-healthcheck \ --protocol tcp將兩個執行個體群組新增至後端服務以作為後端使用:
gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE1_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE1_INSTANCE_ZONE} \ --region ${CLUSTER_REGION} gcloud compute backend-services add-backend mysql-ilb \ --instance-group ${DATABASE2_INSTANCE_NAME}-instance-group \ --instance-group-zone ${DATABASE2_INSTANCE_ZONE} \ --region ${CLUSTER_REGION}為負載平衡器建立轉寄規則:
gcloud compute forwarding-rules create mysql-ilb-forwarding-rule \ --load-balancing-scheme internal \ --ports 3306 \ --network default \ --subnet default \ --region ${CLUSTER_REGION} \ --address ${ILB_IP} \ --backend-service mysql-ilb建立防火牆規則以允許內部負載平衡器健康狀態檢查:
gcloud compute firewall-rules create allow-ilb-healthcheck \ --direction=INGRESS --network=default \ --action=ALLOW --rules=tcp:3306 \ --source-ranges=130.211.0.0/22,35.191.0.0/16 --target-tags=mysql如要檢查負載平衡器的狀態,請前往 Google Cloud 控制台的「Load balancing」(負載平衡) 頁面。
按一下
mysql-ilb:
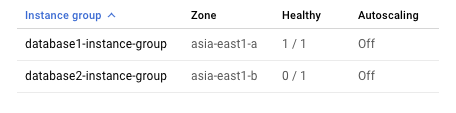
由於叢集在任何特定時間內都只允許一個執行個體執行 MySQL,因此對內部負載平衡器來說,只有一個執行個體則表示健康狀態良好。
從 MySQL 用戶端連線至叢集
- 透過 SSH 連線至
mysql-client執行個體。 更新套件定義:
sudo apt-get update安裝 MySQL 用戶端:
sudo apt-get install -y mysql-client建立指令碼檔案,以使用範例資料來建立並填入資料表:
cat <<EOF > db_creation.sql CREATE DATABASE source_db; use source_db; CREATE TABLE source_table ( id BIGINT NOT NULL AUTO_INCREMENT, timestamp timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, event_data float DEFAULT NULL, PRIMARY KEY (id) ); DELIMITER $$ CREATE PROCEDURE simulate_data() BEGIN DECLARE i INT DEFAULT 0; WHILE i < 100 DO INSERT INTO source_table (event_data) VALUES (ROUND(RAND()*15000,2)); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL simulate_data() EOF建立資料表:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -u root -pDRBDha2 "-h${ILB_IP}" < db_creation.sql
測試叢集
如要測試已部署叢集的高可用功能,您可以執行以下測試:
- 關閉
database1執行個體,測試主要資料庫是否可以容錯移轉到database2執行個體。 - 啟動
database1執行個體,查看database1是否可成功重新加入叢集。 - 關閉
database2執行個體,測試主要資料庫是否可以容錯移轉到database1執行個體。 - 啟動
database2執行個體,查看database2是否可成功重新加入叢集,以及database1執行個體是否仍保持主要執行個體角色。 - 在
database1和database2之間建立網路分區,以模擬核心分裂的問題。
開啟 Cloud Shell:
停止
database1執行個體:gcloud compute instances stop ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}檢查叢集的狀態:
gcloud compute ssh ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE} \ --command="sudo pcs status"輸出內容如下所示。請確認您所做的設定變更已經完成:
2 nodes configured 4 resources configured Online: [ database2 ] OFFLINE: [ database1 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Stopped: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled啟動
database1執行個體:gcloud compute instances start ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE}檢查叢集的狀態:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"輸出如下所示:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database2 ] Slaves: [ database1 ] mystore_FS (ocf::heartbeat:Filesystem): Started database2 mysql_service (ocf::heartbeat:mysql): Started database2 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled停止
database2執行個體:gcloud compute instances stop ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}檢查叢集的狀態:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"輸出如下所示:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled啟動
database2執行個體:gcloud compute instances start ${DATABASE2_INSTANCE_NAME} \ --zone=${DATABASE2_INSTANCE_ZONE}檢查叢集的狀態:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"輸出如下所示:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled在
database1和database2之間建立網路分區:gcloud compute firewall-rules create block-comms \ --description="no MySQL communications" \ --action=DENY \ --rules=all \ --source-tags=mysql \ --target-tags=mysql \ --priority=800請在幾分鐘之後檢查叢集的狀態。請注意,
database1仍維持其主要角色,原因是仲裁政策在網路分區的情況下是以最低 ID 節點為優先。與此同時,database2的 MySQL 服務已經停止。這個仲裁機制可避免在發生網路分區時出現核心分裂的問題。gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"輸出如下所示:
2 nodes configured 4 resources configured Online: [ database1 ] OFFLINE: [ database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Stopped: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1刪除網路防火牆規則以移除網路分區。 (請在系統提示時按下
Y。)gcloud compute firewall-rules delete block-comms確認叢集狀態恢復正常:
gcloud compute ssh ${DATABASE1_INSTANCE_NAME} \ --zone=${DATABASE1_INSTANCE_ZONE} \ --command="sudo pcs status"輸出如下所示:
2 nodes configured 4 resources configured Online: [ database1 database2 ] Full list of resources: Master/Slave Set: primary_mysql [mysql_drbd] Masters: [ database1 ] Slaves: [ database2 ] mystore_FS (ocf::heartbeat:Filesystem): Started database1 mysql_service (ocf::heartbeat:mysql): Started database1透過 SSH 連線至
mysql-client執行個體。在殼層中查詢您之前所建立的資料表:
ILB_IP=$(curl -s "http://metadata.google.internal/computeMetadata/v1/instance/attributes/ILB_IP" -H "Metadata-Flavor: Google") mysql -uroot "-h${ILB_IP}" -pDRBDha2 -e "select * from source_db.source_table LIMIT 10"輸出內容應列出下列表單中的 10 筆記錄,並驗證叢集中的資料一致性:
+----+---------------------+------------+ | id | timestamp | event_data | +----+---------------------+------------+ | 1 | 2018-11-27 21:00:09 | 1279.06 | | 2 | 2018-11-27 21:00:09 | 4292.64 | | 3 | 2018-11-27 21:00:09 | 2626.01 | | 4 | 2018-11-27 21:00:09 | 252.13 | | 5 | 2018-11-27 21:00:09 | 8382.64 | | 6 | 2018-11-27 21:00:09 | 11156.8 | | 7 | 2018-11-27 21:00:09 | 636.1 | | 8 | 2018-11-27 21:00:09 | 14710.1 | | 9 | 2018-11-27 21:00:09 | 11642.1 | | 10 | 2018-11-27 21:00:09 | 14080.3 | +----+---------------------+------------+
容錯移轉序列
如果叢集中的主要節點停止運作,則容錯移轉序列如下所示:
- 仲裁裝置和待命節點都失去與主要節點的連線。
- 仲裁設備會投票給待命節點,而待命節點則投票給自己。
- 待命節點會取得仲裁。
- 待命節點將升級為主要節點。
- 新的主要節點會執行下列操作:
- 將 DRBD 升級為主要執行個體
- 從 DRBD 掛接 MySQL 資料磁碟
- 啟動 MySQL
- 讓負載平衡器恢復健康狀態
- 負載平衡器會開始將流量傳送至新的主要節點。
清除所用資源
刪除專案
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
後續步驟
- 進一步瞭解 DRBD。
- 進一步瞭解 Pacemaker。
- 進一步瞭解 Corosync Cluster Engine。
- 如需瞭解更多 MySQL 伺服器 5.6 進階設定,請參閱 MySQL 伺服器管理手冊。
- 如要設定遠端存取 MySQL,請參閱如何在 Compute Engine 上設定遠端存取 MySQL。
- 如要進一步瞭解 MySQL,請參閱 MySQL 官方說明文件。
- 查看 Google Cloud 的參考架構、圖表和最佳做法。 歡迎瀏覽我們的 Cloud Architecture Center。