
המסמך הזה מיועד למפתחי תוכנה ולאדמינים של מסדי נתונים שרוצים להעביר אפליקציות קיימות או לתכנן אפליקציות חדשות לשימוש עם Bigtable כמסד נתונים. המסמך הזה מיועד למי שיש לו ידע ב-Apache Cassandra, ומתאר מושגים שחשוב להכיר לפני שמבצעים מיגרציה ל-Bigtable. מידע על כלים בקוד פתוח שאפשר להשתמש בהם כדי להשלים את ההעברה זמין במאמר העברה מ-Cassandra ל-Bigtable.
Bigtable ו-Cassandra הם מסדי נתונים מבוזרים. הם מטמיעים מאגרי נתונים של זוגות מפתח/ערך רב-ממדיים שיכולים לתמוך בעשרות אלפי שאילתות לשנייה (QPS), בקריאה ובכתיבה עם חביון נמוך, באחסון שניתן להרחבה עד פטה-בייט של נתונים ובסובלנות לכשלים בצמתים.
מתי Bigtable הוא יעד טוב לעומסי עבודה של Cassandra
השירות הטוב ביותר לעומס העבודה שלכם ב-Cassandra תלוי ביעדי ההעברה ובפונקציונליות של Cassandra שאתם צריכים אחרי ההעברה. Google Cloud
אם מתקיים אחד או יותר מהתנאים הבאים, Bigtable הוא הפתרון האופטימלי:
- אתם רוצים שירות מנוהל במלואו ללא חלונות תחזוקה ועם זמינות גבוהה.
- אתם צריכים התאמה דינמית לעומס (elastic scaling) שמגיבה לשינויים בתעבורת השרת באופן אוטומטי.
- אתם צריכים השהיה עקבית של מילי-שניות בודדות לקריאות ולכתיבות.
- אתם משתמשים בסוגי אוספים, בדלפקים או בתצוגות חומריות של Cassandra, בנוסף לסוגים סקלריים, ש-Bigtable מותאם להם.
- יש לכם אפליקציה שמשתמשת בפרמטר
USING TIMESTAMP. - קצב העברת הנתונים לכתיבה וזמן האחזור חשובים בדיוק כמו קצב העברת הנתונים לקריאה.
- אתם מסתמכים על אחד ממודלי השכפול העקביים בסופו של דבר של Cassandra.
- בתרחיש לדוגמה שלכם יש צורך באחסון חסכוני.
כדי להעביר אפליקציות בלי לבצע שינויים בקוד, אפשר לנהל את Cassandra ב-GKE באופן עצמאי או להשתמש בשותף כמו DataStax או ScyllaDB. Google Cloudאם האפליקציה שלכם מבצעת הרבה פעולות קריאה ואתם מוכנים לשכתב את הקוד כדי לקבל יכולות של מסד נתונים רלציוני ומודל עקביות חזק, כדאי לשקול שימוש ב-Spanner.
במאמר הזה מפורטים טיפים לגבי נקודות שכדאי להביא בחשבון כשמבצעים רפקטורינג באפליקציה, אם בוחרים ב-Bigtable כיעד להעברה של עומסי העבודה של Cassandra.
איך משתמשים במסמך הזה
לא צריך לקרוא את המסמך הזה מההתחלה ועד הסוף. במסמך הזה מוצגת השוואה בין שני מסדי הנתונים, אבל אפשר גם להתמקד בנושאים שרלוונטיים לתרחיש השימוש או לתחומי העניין שלכם.
כדי לעזור לכם להשוות בין Bigtable לבין Cassandra, המסמך הזה כולל את הפעולות הבאות:
- השוואה בין המינוחים, שיכולים להיות שונים בין שני בסיסי הנתונים.
- המאמר מספק סקירה כללית של שתי מערכות מסדי הנתונים.
- המודל בוחן איך כל מסד נתונים מטפל במידול נתונים כדי להבין שיקולי עיצוב שונים.
- השוואה בין הנתיב שבו הנתונים עוברים במהלך כתיבה וקריאה.
- בודק את פריסת הנתונים הפיזית כדי להבין היבטים של ארכיטקטורת מסד הנתונים.
- במאמר הזה מוסבר איך להגדיר שכפול גיאוגרפי בהתאם לדרישות שלכם, ואיך לגשת לקביעת הגודל של אשכול.
- סקירה של פרטים על ניהול אשכולות, מעקב ואבטחה.
השוואה בין מונחים
הרבה מהמושגים שמשמשים ב-Bigtable וב-Cassandra דומים, אבל לכל מסד נתונים יש מוסכמות שונות למתן שמות והבדלים קלים.
אחד מאבני הבניין המרכזיות של שני מסדי הנתונים הוא טבלת מחרוזות ממוינות (SSTable). בשתי הארכיטקטורות, נוצרים קבצי SSTable כדי לשמור נתונים שמשמשים למענה על שאילתות קריאה.
בפוסט בבלוג (2012), איליה גריגוריק כתב את הדברים הבאים: "SSTable הוא הפשטה פשוטה לאחסון יעיל של מספרים גדולים של זוגות של מפתח-ערך, תוך אופטימיזציה של תפוקה גבוהה, עומסי עבודה של קריאה או כתיבה רציפה".
בטבלה הבאה מפורטים מושגים משותפים והמינוח המתאים שבו משתמש כל מוצר:
| Cassandra | Bigtable |
|---|---|
|
מפתח ראשי: ערך ייחודי של שדה יחיד או של כמה שדות שקובע את המיקום והסדר של הנתונים. partition key: ערך של שדה יחיד או של כמה שדות שקובע את מיקום הנתונים באמצעות גיבוב עקבי. עמודת אשכולות: ערך של שדה יחיד או של כמה שדות שקובע את המיון הלקסיקוגרפי של הנתונים במחיצה. |
מפתח שורה: מחרוזת ייחודית של בייטאחד שקובעת את מיקום הנתונים באמצעות מיון לקסיקוגרפי. כדי לחקות מפתחות מורכבים, מאחדים את הנתונים של כמה עמודות באמצעות תו מפריד משותף – לדוגמה, הסמל של סולמית (#) או של אחוז (%). |
| node: מכונה שאחראית לקריאה ולכתיבה של נתונים שמשויכים לסדרה של טווחי גיבוב של מחיצות של מפתח ראשי. ב-Cassandra, הנתונים מאוחסנים באחסון ברמת הבלוק שמצורף לשרת הצומת. | node: משאב וירטואלי של מחשוב שאחראי על קריאה וכתיבה של נתונים שמשויכים לסדרה של טווחי מפתחות שורות. ב-Bigtable, הנתונים לא ממוקמים יחד עם צמתי החישוב. במקום זאת, הוא מאוחסן ב-Colossus, מערכת הקבצים המבוזרת של Google. לצמתים מוקצית אחריות זמנית להצגת טווחים שונים של נתונים על סמך עומס הפעולה והתקינות של צמתים אחרים באשכול. |
|
מרכז נתונים: דומה לאשכול Bigtable, אבל יש היבטים מסוימים של טופולוגיה ואסטרטגיית שכפול שאפשר להגדיר ב-Cassandra. rack: קבוצה של צמתים במרכז נתונים שמשפיעה על מיקום העותקים. |
אשכול: קבוצה של צמתים באותו אזור גיאוגרפיGoogle Cloud , שמוקמים יחד כדי לטפל בבעיות של השהיה ושכפול. |
| cluster: פריסת Cassandra שמורכבת מאוסף של מרכזי נתונים. | מופע: קבוצה של אשכולות Bigtable באזורים או באזורים שונים שמתבצעת ביניהם שכפול וניתוב של חיבורים. Google Cloud |
| vnode: טווח קבוע של ערכי גיבוב (hash) שמוקצה לצומת פיזי ספציפי. הנתונים ב-vnode מאוחסנים פיזית בצומת Cassandra בסדרה של SSTables. | tablet: קובץ SSTable שמכיל את כל הנתונים לטווח רציף של מפתחות שורות ממוינים לפי סדר מילוני. טבליות לא מאוחסנות בצמתים ב-Bigtable, אלא מאוחסנות בסדרה של SSTables ב-Colossus. |
| replication factor: the number of replicas of a vnode that are maintained across all nodes in the data center. גורם השכפול מוגדר בנפרד לכל מרכז נתונים. | שכפול: תהליך השכפול של הנתונים שמאוחסנים ב-Bigtable לכל האשכולות במופע. הרפליקציה באשכול אזורי מטופלת על ידי שכבת האחסון Colossus. |
| טבלה (לשעבר קבוצת עמודות): ארגון לוגי של ערכים שממוינים לפי המפתח הראשי הייחודי. | טבלה: ארגון לוגי של ערכים שמקבלים אינדקס לפי מפתח השורה הייחודי. |
| keyspace: מרחב שמות לוגי של טבלאות שמגדיר את גורם השכפול של הטבלאות שהוא מכיל. | לא רלוונטי. Bigtable מטפל בבעיות של מרחב מפתחות באופן שקוף. |
| map: סוג אוסף של Cassandra שמכיל צמדי מפתח-ערך. | משפחת עמודות: מרחב שמות שמוגדר על ידי המשתמש ומקבץ מזהי עמודות כדי לשפר את היעילות של פעולות קריאה וכתיבה. כשמבצעים שאילתה ב-Bigtable באמצעות SQL, column families מטופלים כמו מפות של Cassandra. |
| map key: מפתח שמזהה באופן ייחודי רשומה של מפתח-ערך במפת Cassandra | מגדיר העמודה: תווית של ערך שמאוחסן בטבלה שממוינת לפי מפתח השורה הייחודי. כשמבצעים שאילתה ב-Bigtable באמצעות SQL, העמודות מטופלות כמו מפתחות של מפה. |
| column: התווית של ערך שמאוחסן בטבלה שמקוטלגת לפי המפתח הראשי הייחודי. | column: התווית של ערך שמאוחסן בטבלה שמקוטלגת לפי מפתח השורה הייחודי. שם העמודה מורכב משילוב של קבוצת העמודות עם מגדיר העמודה. |
| cell: ערך של חותמת זמן בטבלה שמשויך לנקודת החיתוך של מפתח ראשי עם העמודה. | cell: ערך של חותמת זמן בטבלה שמשויך לנקודת החיתוך של מפתח שורה עם שם העמודה. אפשר לאחסן ולשחזר כמה גרסאות עם חותמת זמן לכל תא. |
| counter: סוג שדה שאפשר להגדיל אותו, שעבר אופטימיזציה לפעולות של סכום מספרים שלמים. | counters: תאים שמשתמשים בסוגי נתונים מיוחדים לפעולות של סכום מספרים שלמים. מידע נוסף זמין במאמר בנושא יצירה ועדכון של מוניטורים. |
| מדיניות איזון עומסים: מדיניות שמגדירים בלוגיקה של האפליקציה כדי להפנות פעולות לצומת מתאים באשכול. המדיניות מתייחסת לטופולוגיה של מרכז הנתונים ולטווחים של אסימוני vnode. | פרופיל אפליקציה: הגדרות שמנחות את Bigtable איך לנתב קריאה ל-API של לקוח לאשכול המתאים במופע. אפשר גם להשתמש בפרופיל האפליקציה כתג לפילוח מדדים. מגדירים את פרופיל האפליקציה בשירות. |
| CQL: Cassandra Query Language, שפה כמו SQL שמשמשת ליצירת טבלאות, לשינויים בסכימה, למוטציות בשורות ולשאילתות. | הלקוח של Cassandra ל-Bigtable ל-Java הוא תחליף חלק לדרייברים של Cassandra. לקוח Java מבין את שאילתות ה-CQL שלכם, ומאפשר לכם להשתמש ב-Bigtable באופן שקוף עם אפליקציה קיימת שמבוססת על Cassandra, בלי שתצטרכו לכתוב מחדש את הקוד. Cassandra to Bigtable proxy adapter היא שכבה עצמאית שאפשר להריץ במקביל לאפליקציה ולהתחבר ל-Bigtable כעוד צומת Cassandra. מתאם ה-proxy מספק תאימות ל-CQL ותומך בכתיבה כפולה ובהעברות בכמות גדולה. הפונקציונליות הזו דומה למה שמציע לקוח Cassandra ל-Bigtable עבור Java. Bigtable APIs הן ספריות הלקוח ו-gRPC APIs שמשמשות ליצירת מופעים ואשכולות, ליצירת טבלאות ומשפחות עמודות, לשינוי שורות ולהרצת שאילתות. משתמשי CQL ימצאו את Bigtable SQL API מוכר. |
תצוגה חומרית: הצהרת SELECT שמגדירה קבוצה של שורות שתואמות לשורות בטבלת מקור בסיסית. כשמבצעים שינויים בטבלת המקור, Cassandra מעדכן את התצוגה החומרית באופן אוטומטי.
|
תצוגה חומרית רציפה: תוצאה מחושבת מראש של שאילתת SQL שמנוהלת באופן מלא ומעודכנת באופן מצטבר ואוטומטי מטבלת מקור. מידע נוסף מופיע במאמר בנושא תצוגות חומריות רציפות. |
סקירות כלליות על מוצרים
בקטעים הבאים מופיעה סקירה כללית של פילוסופיית העיצוב והמאפיינים העיקריים של Bigtable ו-Cassandra.
Bigtable
Bigtable מספקת רבות מהתכונות העיקריות שמתוארות במאמר Bigtable: A Distributed Storage System for Structured Data. ב-Bigtable, צמתי המחשוב שמשרתים בקשות של לקוחות מופרדים מניהול האחסון הבסיסי. הנתונים מאוחסנים ב-Colossus. שכבת האחסון משכפלת את הנתונים באופן אוטומטי כדי לספק עמידות שגבוהה מהרמות שמסופקות על ידי שכפול תלת-כיווני של מערכת הקבצים המבוזרת של Hadoop (HDFS).
הארכיטקטורה הזו מספקת קריאות וכתיבות עקביות בתוך אשכול, מאפשרת הגדלה והקטנה של הקיבולת בלי עלות של חלוקה מחדש של האחסון, ויכולה לבצע איזון מחדש של עומסי עבודה בלי לשנות את האשכול או את הסכימה. אם יש בעיה באחד מצמתי עיבוד הנתונים, שירות Bigtable מחליף אותו באופן שקוף. Bigtable תומך גם בשכפול אסינכרוני.
בנוסף ל-gRPC ולספריות לקוח לשפות תכנות שונות, Bigtable שומר על תאימות ל-Apache HBase בקוד פתוח, ספריית לקוח Java, הטמעה חלופית של המנוע של מסד הנתונים בקוד פתוח של מאמר Bigtable.
בתרשים הבא אפשר לראות איך Bigtable מפריד פיזית בין צמתי העיבוד לשכבת האחסון:
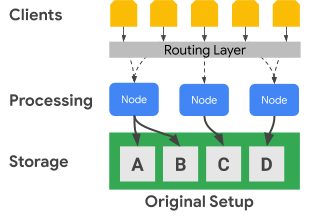
בתרשים הקודם, צומת העיבוד האמצעי אחראי רק על הצגת בקשות נתונים עבור מערך הנתונים C בשכבת האחסון. אם Bigtable מזהה שנדרש איזון מחדש של הקצאת טווחים עבור מערך נתונים, קל לשנות את טווחי הנתונים של צומת עיבוד כי שכבת האחסון מופרדת משכבת העיבוד.
בתרשים הבא מוצג, בצורה פשוטה, איזון מחדש של טווח מפתחות ושינוי גודל של אשכול:
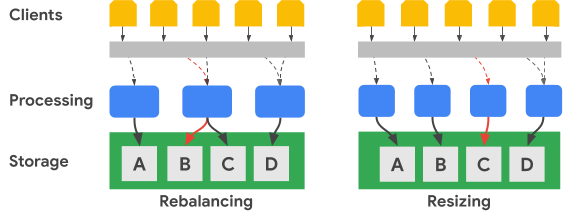
בתמונה Rebalancing מוצג המצב של אשכול Bigtable אחרי שצומת העיבוד הכי שמאלי מקבל מספר מוגדל של בקשות עבור מערך הנתונים A. אחרי האיזון מחדש, הצומת האמצעי, במקום הצומת הימני ביותר, אחראי להצגת בקשות נתונים עבור מערך הנתונים B. הצומת הכי ימני ממשיך לטפל בבקשות עבור קבוצת הנתונים A.
Bigtable יכול לסדר מחדש טווחי מפתחות שורות כדי לאזן את טווחי מערכי הנתונים בין מספר גדול יותר של צמתי עיבוד זמינים. בתמונה שינוי הגודל מוצג המצב של אשכול Bigtable אחרי שמוסיפים צומת.
Cassandra
Apache Cassandra הוא מסד נתונים בקוד פתוח שמושפע בחלקו ממושגים ממאמר בנושא Bigtable. היא מבוססת על ארכיטקטורת צמתים מבוזרת, שבה האחסון נמצא באותו מיקום עם השרתים שמגיבים לפעולות על הנתונים. סדרה של צמתים וירטואליים (vnodes) מוקצית באופן אקראי לכל שרת כדי לשרת חלק ממרחב המפתחות של האשכול.
הנתונים מאוחסנים ב-vnodes על סמך מפתח המחיצה. בדרך כלל, משתמשים בפונקציית גיבוב עקבית כדי ליצור אסימון לקביעת מיקום הנתונים. בדומה ל-Bigtable, אפשר להשתמש במחלק ששומר על הסדר כדי ליצור טוקנים, וכך גם כדי למקם נתונים. עם זאת, במסמכי התיעוד של Cassandra מומלץ שלא להשתמש בגישה הזו כי סביר להניח שהאשכול יהפוך ללא מאוזן, וקשה לתקן את המצב הזה. לכן, במסמך הזה אנחנו מניחים שאתם משתמשים באסטרטגיית גיבוב עקבית כדי ליצור אסימונים שמובילים להפצת נתונים בין הצמתים.
Cassandra מספקת סובלנות לשגיאות באמצעות רמות זמינות שקשורות לרמת העקביות שניתנת להתאמה, ומאפשרת לאשכול לשרת לקוחות בזמן שאחד או יותר מהצמתים פגומים. אתם מגדירים שכפול גיאוגרפי באמצעות אסטרטגיה של טופולוגיית שכפול נתונים שניתנת להגדרה.
מציינים רמת עקביות לכל פעולה. ההגדרה הטיפוסית היא QUORUM (או LOCAL_QUORUM בטופולוגיות מסוימות של מרכזי נתונים מרובים). הגדרת רמת העקביות הזו מחייבת שרוב צמתי העותקים יגיבו לצומת המתאם כדי שהפעולה תיחשב כמוצלחת. גורם השכפול, שמוגדר לכל מרחב מפתחות, קובע את מספר העותקים של הנתונים שמאוחסנים בכל מרכז נתונים באשכול. לדוגמה, בדרך כלל משתמשים בערך 3 של גורם השכפול כדי לספק איזון מעשי בין עמידות לבין נפח האחסון.
בתרשים הבא מוצג באופן פשוט אשכול של שישה צמתים, כאשר טווח המפתחות של כל צומת מחולק לחמישה צמתים וירטואליים. בפועל, יכולים להיות יותר צמתים, וסביר להניח שיהיו יותר צמתים וירטואליים.

בתרשים שלמעלה אפשר לראות את הנתיב של פעולת כתיבה, עם רמת עקביות של QUORUM, שמקורה באפליקציית לקוח או בשירות (Client). לצורך התרשים הזה, טווחי המפתחות מוצגים כטווחי אותיות. בפועל, האסימונים שנוצרים מגיבוב של המפתח הראשי הם מספרים שלמים חתומים גדולים מאוד.
בדוגמה הזו, הגיבוב של המפתח הוא M, והצמתים הווירטואליים של M נמצאים בצמתים 2, 4 ו-6. המתאם צריך ליצור קשר עם כל צומת שבו טווחי הגיבוב של המפתחות מאוחסנים באופן מקומי, כדי שהכתיבה תוכל להתבצע. מכיוון שרמת העקביות היא QUORUM, שני עותקים (רוב) צריכים להגיב לצומת המתאם לפני שהלקוח מקבל הודעה שהכתיבה הושלמה.
בניגוד ל-Bigtable, כדי להעביר או לשנות טווחי מפתחות ב-Cassandra צריך להעתיק פיזית את הנתונים מצומת אחד לצומת אחר. אם צומת אחד עמוס מדי בבקשות לטווח מסוים של גיבוב טוקנים, הוספת עיבוד לטווח הטוקנים הזה מורכבת יותר ב-Cassandra בהשוואה ל-Bigtable.
שכפול גיאוגרפי ועקביות
ב-Bigtable וב-Cassandra, שכפול ועקביות גיאוגרפיים (שנקראים גם multi-region) מטופלים באופן שונה. קלאסטר של Cassandra מורכב מצמתים לעיבוד שמקובצים למתלים, והמתלים מקובצים למרכזי נתונים. Cassandra משתמשת בשיטת טופולוגיה של רשת שאתם מגדירים כדי לקבוע איך עותקים של צמתים וירטואליים מופצים בין מארחים במרכז נתונים. האסטרטגיה הזו ממחישה את המקורות של Cassandra כבסיס נתונים שבתחילה נפרס במרכזי נתונים פיזיים מקומיים. בנוסף, ההגדרה הזו מציינת את מקדם השכפול לכל מרכז נתונים באשכול.
Cassandra משתמשת בהגדרות של מרכזי נתונים ומתלים כדי לשפר את הסבילות לשגיאות של העתקי הנתונים. במהלך פעולות קריאה וכתיבה, הטופולוגיה קובעת את צמתי המשתתפים שנדרשים כדי לספק עקביות. כשיוצרים או מרחיבים אשכול, צריך להגדיר ידנית את הצמתים, המתלים ומרכזי הנתונים. בסביבת ענן, פריסת Cassandra טיפוסית מתייחסת לאזור בענן כאל מתלה ולאזור בענן כאל מרכז נתונים.
אפשר להשתמש באמצעי הבקרה של קוורום ב-Cassandra כדי לשנות את ערבויות העקביות לכל פעולת קריאה או כתיבה. רמות החוזק של עקביות סופית יכולות להיות שונות, כולל אפשרויות שדורשות צומת שכפול יחיד (ONE), רוב של צומת שכפול במרכז נתונים יחיד (LOCAL_QUORUM) או רוב של כל צמתי השכפול בכל מרכזי הנתונים (QUORUM).
ב-Bigtable, אשכולות הם משאבים של אזור. מופע Bigtable יכול להכיל אשכול יחיד, או שהוא יכול להיות קבוצה של אשכולים משוכפלים באופן מלא. אפשר למקם אשכולות של מכונות וירטואליות בכל שילוב של אזורים בכל האזורים שבהם Google Cloud זמין. אפשר להוסיף אשכולות למופע ולהסיר אותם ממנו עם השפעה מינימלית על אשכולות אחרים במופע.
ב-Bigtable, פעולות כתיבה מתבצעות (עם עקביות של קריאה אחרי כתיבה) באשכול יחיד, והן יהיו עקביות בסופו של דבר באשכולות של מופעים אחרים. התאים הבודדים הם בעלי גרסאות שונות לפי חותמת הזמן, ולכן לא מתבצעים כתיבות שנעלמות, וכל אשכול מציג את התאים עם חותמות הזמן העדכניות ביותר שזמינות.
השירות חושף את סטטוס העקביות של האשכול. Cloud Bigtable API מספק מנגנון לקבלת אסימון עקביות ברמת הטבלה. אפשר להשתמש בטוקן הזה כדי לוודא שכל השינויים שבוצעו בטבלה לפני יצירת הטוקן שוכפלו באופן מלא.
תמיכה בעסקאות
למרות שאף אחת מהמסדי נתונים לא תומכת בעסקאות מורכבות של כמה שורות, לכל אחת מהן יש תמיכה מסוימת בעסקאות.
ל-Cassandra יש שיטה של טרנזקציה קלה (LWT) שמספקת אטומיות לעדכונים של ערכי עמודות במחיצה אחת. ל-Cassandra יש גם סמנטיקה של compare and set שמשלימה את פעולת הקריאה של השורה ואת השוואת הערכים לפני שמתחילה פעולת כתיבה.
Bigtable תומך בכתיבה עקבית לחלוטין בשורה אחת בתוך אשכול. טרנזקציות של שורה אחת מופעלות באמצעות הפעולות read-modify-write ו-check-and-mutate. פרופילים של אפליקציות לניתוב בין כמה אשכולות לא תומכים בעסקאות של שורה אחת.
מודל נתונים
גם Bigtable וגם Cassandra מארגנים את הנתונים בטבלאות שתומכות בחיפושים ובסריקות של טווחים באמצעות המזהה הייחודי של השורה. שתי המערכות מסווגות כמחסני נתונים מסוג wide-column של NoSQL.
ב-Cassandra, צריך להשתמש ב-CQL כדי ליצור מראש את סכימת הטבלה המלאה, כולל הגדרת המפתח הראשי, שמות העמודות והסוגים שלהן. מפתחות ראשיים ב-Cassandra הם ערכים מורכבים ייחודיים שמורכבים ממפתח מחיצה חובה וממפתח אשכול אופציונלי. המפתח של המחיצה קובע את מיקום השורה בצומת, והמפתח של האשכול קובע את סדר המיון בתוך המחיצה. כשיוצרים סכימות, חשוב להיות מודעים לפשרות הפוטנציאליות בין ביצוע סריקות יעילות במחיצה אחת לבין עלויות המערכת שקשורות לתחזוקה של מחיצות גדולות.
ב-Bigtable, צריך רק ליצור את הטבלה ולהגדיר מראש את משפחות העמודות שלה. העמודות לא מוצהרות כשיוצרים טבלאות, אבל הן נוצרות כשקריאות ל-API של האפליקציה מוסיפות תאים לשורות בטבלה.
מפתחות השורות מסודרים בסדר לקסיקוגרפי בכל אשכול Bigtable. הצמתים ב-Bigtable מאזנים באופן אוטומטי את האחריות של הצמתים לטווחים של מפתחות, שלרוב נקראים טאבלטים ולפעמים פיצולים. מפתחות שורות ב-Bigtable מורכבים לעיתים קרובות מכמה ערכי שדות שמצורפים באמצעות תו מפריד נפוץ שאתם בוחרים (למשל, סימן אחוז). כשמפרידים את הרכיבים של המחרוזת, הם מקבילים לשדות של מפתח ראשי ב-Cassandra.
עיצוב מפתח השורה
ב-Bigtable, המזהה הייחודי של שורה בטבלה הוא מפתח השורה. מפתח השורה חייב להיות ערך ייחודי יחיד בכל הטבלה. אפשר ליצור מפתחות מרובי חלקים על ידי שרשור של רכיבים שונים שמופרדים באמצעות מפריד משותף. מפתח השורה קובע את סדר המיון הגלובלי של הנתונים בטבלה. שירות Bigtable קובע באופן דינמי את טווחי המפתחות שמוקצים לכל צומת.
בניגוד ל-Cassandra, שבה הגיבוב של מפתח המחיצה קובע את מיקום השורה והעמודות של האשכול קובעות את הסדר, מפתח השורה ב-Bigtable מספק גם הקצאה צמתי וגם סדר. בדומה ל-Cassandra, צריך לתכנן מפתח שורה ב-Bigtable כך שהשורות שרוצים לאחזר ביחד יישמרו ביחד. עם זאת, ב-Bigtable, לא צריך לתכנן את מפתח השורה למיקום ולסדר לפני שמשתמשים בטבלה.
סוגי הנתונים
שירות Bigtable לא אוכף את סוגי הנתונים של העמודות שהלקוח שולח. הספריות לקוח מספקות שיטות עזר לכתיבת ערכי תאים כבייטים, כמחרוזות בקידוד UTF-8 וכמספרים שלמים בקידוד big-endian של 64 ביט (מספרים שלמים בקידוד big-endian נדרשים לפעולות של הגדלה אטומית).
קבוצת עמודות
ב-Bigtable, משפחת עמודות קובעת אילו עמודות בטבלה מאוחסנות ומאוחזרות יחד. לכל טבלה צריך להיות לפחות column family אחד, אבל לרוב יש יותר (ההגבלה היא 100 column families לכל טבלה). צריך ליצור באופן מפורש משפחות עמודות כדי שאפליקציה תוכל להשתמש בהן בפעולה.
מגדירי עמודות
כל ערך שמאוחסן בטבלה במפתח שורה משויך לתווית שנקראת מגדיר העמודה. מכיוון שמוספי העמודות הם רק תוויות, אין מגבלה מעשית על מספר העמודות שיכולות להיות במשפחת עמודות. ב-Bigtable, הרבה פעמים משתמשים במאפייני עמודה כדי לייצג נתונים של אפליקציות.
תאים
ב-Bigtable, תא הוא נקודת המפגש בין מפתח השורה לבין שם העמודה (קבוצת עמודות בשילוב עם מגדיר העמודה). כל תא מכיל ערך אחד או יותר עם חותמת זמן, שהלקוח יכול לספק או שהשירות יכול להחיל באופן אוטומטי. ערכי תאים ישנים נשמרים על סמך מדיניות איסוף אשפה שתצורתה מוגדרת ברמת משפחת העמודות.
אינדקסים משניים
אתם יכולים להשתמש בתצוגות חומריות רציפות כאינדקסים משניים אסינכרוניים לטבלאות כדי לשלוח שאילתות לאותם נתונים באמצעות תבניות או מאפיינים שונים של חיפוש. מידע נוסף מופיע במאמר בנושא יצירת אינדקס משני אסינכרוני.
מודלים של נתונים: גמישות עם אוספים
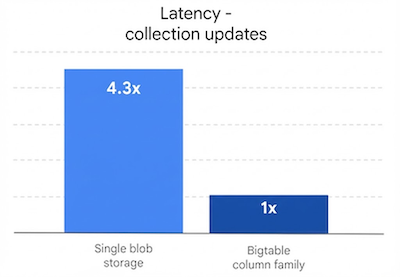
מתאם הפרוקסי של Cassandra ל-Bigtable הופך סוגי אוספים של Cassandra, כמו מפות, קבוצות ורשימות, למשפחות של עמודות ב-Bigtable. כך השימוש ב-Bigtable עם סוגי אוספים של Cassandra יעיל מאוד, כי אפשר לכתוב ולקרוא עמודות בודדות הרבה יותר מהר מאשר כתמים בינאריים גדולים (blobs).
בעזרת Bigtable, אפשר ליצור אפליקציות עם אוספים גדולים ודינמיים בלי להתפשר על הביצועים כמו שנדרש ב-Cassandra, מהסיבות הבאות:
- Bigtable מאחסן רכיבי אוסף כתאים נפרדים, כך שפעולות על רכיבים הן גרנולריות מאוד. כלומר, עדכון מפה יחיד מתורגם לכתיבה קלה לתא, מה שמספק ביצועים גבוהים וגמישות.
- אין מגבלת גודל מעשית לאוספים ב-Bigtable, מלבד מגבלות הגודל של השורות.
- ב-Bigtable יש השהיה נמוכה ועקבית, לא משנה כמה גדול האוסף, כפי שמוצג באיור 4.
לעומת זאת, במסמכי התיעוד של Cassandra מומלץ להגביל באופן משמעותי את השימוש בסוגי אוספים, ולעיתים קרובות להגביל את מספר הרכיבים למספרים קטנים בגלל ירידה בביצועים. מכיוון ש-Cassandra קורא עמודות של אוספים כיחידה אחת, אוספים גדולים גורמים בהכרח לעליות פתאומיות בזמן האחזור של הקריאה ולאי יציבות פוטנציאלית של הצומת.
אפשר לעקוף את המגבלות האלה באמצעות פתרונות עקיפים, כמו אוספים קפואים או אחסון נתונים כמחרוזות JSON, אבל הפתרונות האלה פוגעים בביצועים כי הם מוסיפים read-modify-write tax. התקורה הזו מחייבת את מסד הנתונים לקרוא, לבטל את הסדרות, לעדכן ולשכתב את האובייקט כולו בכל שינוי. בנוסף, מערכת Cassandra מתייחסת ל-blobs של JSON האלה כאל טקסט אטום, ולכן כל לוגיקת הניתוח צריכה להיות בשכבת האפליקציה. זה שונה מ-Bigtable, שבו יש עיבוד מובנה בצד השרת של מחרוזות JSON באמצעות פונקציות של SQL API.
Bigtable מאפשר לכם לשלב אלמנטים של סכימה קבועה עם אלמנטים דינמיים בלי להתפשר. כך האפליקציות שלכם יכולות לאכוף מבנה במקומות שבהם זה חשוב, ועדיין להיות גמישות. זה מאפשר לכם לפתח את מודל הנתונים בלי לבצע העברות נרחבות או להשבית את המערכת. הוא תומך גם בעומסי עבודה מודרניים, כמו למידת מכונה ו-AI, שדורשים איטרציה תכופה במאגרי תכונות והצגה בזמן אמת בקנה מידה גלובלי.
איזון עומסים ומעבר לגיבוי (failover) בצד הלקוח
ב-Cassandra, הלקוח שולט באיזון העומסים של הבקשות. מנהל ההתקן של הלקוח מגדיר מדיניות שמוגדרת כחלק מההגדרה או באופן פרוגרמטי במהלך יצירת הסשן. האשכול מודיע למדיניות על מרכזי נתונים שהכי קרובים לאפליקציה, והלקוח מזהה צמתים ממרכזי הנתונים האלה כדי לטפל בפעולה.
שירות Bigtable מעביר קריאות ל-API לאשכול יעד על סמך פרמטר (מזהה של פרופיל אפליקציה) שמסופק עם כל פעולה. פרופילי אפליקציות מתעדכנים בשירות Bigtable. פעולות של לקוחות שלא בוחרים פרופיל משתמשות בפרופיל ברירת מחדל.
ב-Bigtable יש שני סוגים של מדיניות ניתוב של פרופיל אפליקציה: single-cluster ו-multi-cluster. פרופיל מרובה אשכולות מנתב פעולות לאשכול הזמין הקרוב ביותר. אשכולות באותו אזור נחשבים למרוחקים באותה מידה מנקודת המבט של נתב הפעולות. אם הצומת שאחראי לטווח המפתחות המבוקש עמוס מדי או לא זמין זמנית באשכול, סוג הפרופיל הזה מספק מעבר גיבוי אוטומטי.
ב-Cassandra, מדיניות מרובת אשכולות מספקת את היתרונות של מעבר אוטומטי לגיבוי של מדיניות איזון עומסים שמודעת למרכזי נתונים.
פרופיל אפליקציה עם ניתוב לאשכול יחיד מפנה את כל התנועה לאשכול יחיד. עקביות חזקה בשורות ועסקאות בשורה אחת זמינות רק בפרופילים עם ניתוב לאשכול יחיד.
החיסרון בגישה של אשכול יחיד הוא שבמעבר לגיבוי, האפליקציה צריכה להיות מסוגלת לנסות שוב באמצעות מזהה פרופיל אפליקציה חלופי, או שצריך לבצע את המעבר לגיבוי באופן ידני של פרופילי ניתוב מושפעים של אשכול יחיד.
ניתוב פעולות
Cassandra ו-Bigtable משתמשות בשיטות שונות לבחירת צומת העיבוד לפעולות קריאה וכתיבה. ב-Cassandra, מזהים את מפתח המחיצה, ואילו ב-Bigtable משתמשים במפתח השורה.
ב-Cassandra, הלקוח בודק קודם את מדיניות איזון העומסים. האובייקט בצד הלקוח קובע את מרכז הנתונים שאליו הפעולה מנותבת.
אחרי שמזהים את מרכז הנתונים, Cassandra יוצר קשר עם צומת מתאם כדי לנהל את הפעולה. אם המדיניות מזהה טוקנים, הרכיב המתאם הוא צומת שמציג נתונים ממחיצת הצומת הווירטואלי (vnode) של היעד. אחרת, הרכיב המתאם הוא צומת אקראי. צומת המתאם מזהה את הצמתים שבהם נמצאות העתקי הנתונים של מפתח המחיצה של הפעולה, ואז הוא מורה לצמתים האלה לבצע את הפעולה.
ב-Bigtable, כמו שצוין קודם, כל פעולה כוללת מזהה של פרופיל אפליקציה. פרופיל האפליקציה מוגדר ברמת השירות. שכבת הניתוב של Bigtable בודקת את הפרופיל כדי לבחור את אשכול היעד המתאים לפעולה. שכבת הניתוב מספקת נתיב לפעולה כדי להגיע לצמתי העיבוד הנכונים באמצעות מפתח השורה של הפעולה.
תהליך כתיבת הנתונים
שני מסדי הנתונים מותאמים לכתיבה מהירה ומשתמשים בתהליך דומה כדי להשלים כתיבה. עם זאת, השלבים שמתבצעים במסדי הנתונים משתנים מעט, במיוחד ב-Cassandra, שבה, בהתאם לרמת העקביות של הפעולה, יכול להיות שיידרש תקשור עם צמתים נוספים של משתתפים.
אחרי שהבקשה לכתיבה מנותבת לצמתים המתאימים (Cassandra) או לצומת (Bigtable), הכתיבות נשמרות קודם בדיסק באופן רציף ביומן של פעולות (Cassandra) או ביומן משותף (Bigtable). לאחר מכן, הפעולות נכתבות לטבלה בזיכרון (שנקראת גם memtable) שמסודרת כמו SSTables.
אחרי שני השלבים האלה, הצומת מגיב כדי לציין שהכתיבה הושלמה. ב-Cassandra, מספר עותקים משוכפלים (בהתאם לרמת העקביות שצוינה לכל פעולה) צריכים להגיב לפני שהמתאם מודיע ללקוח שהכתיבה הסתיימה. ב-Bigtable, כל מפתח שורה מוקצה רק לצומת אחד בכל נקודת זמן, ולכן כדי לוודא שהכתיבה הצליחה, צריך רק לקבל תשובה מהצומת.
בשלב מאוחר יותר, אם יש צורך בכך, אפשר להעביר את ה-memtable לדיסק בצורה של SSTable חדש. ב-Cassandra, הפעולה flush מתרחשת כשיומן הטרנזקציות מגיע לגודל מקסימלי, או כש-memtable חורג מסף שהגדרתם. ב-Bigtable, מתבצעת פעולת flush כדי ליצור קובצי SSTable חדשים שאי אפשר לשנות כש-memtable מגיע לגודל מקסימלי שמוגדר על ידי השירות. מעת לעת, תהליך דחיסה ממזג SSTables עבור טווח מפתחות נתון לתוך SSTable יחיד.
עדכוני נתונים
בשני מסדי הנתונים, עדכוני הנתונים מתבצעים באופן דומה. עם זאת, ב-Cassandra אפשר להזין רק ערך אחד לכל תא, בעוד שב-Bigtable אפשר לשמור מספר גדול של ערכים עם גרסאות לכל תא.
כשמשנים את הערך בנקודת החיתוך של מזהה שורה ייחודי ועמודה, העדכון נשמר כמו שמתואר בקטע תהליך כתיבת הנתונים. חותמת הזמן של הכתיבה מאוחסנת לצד הערך במבנה SSTable.
אם לא ביצעתם פעולת Flush לתא מעודכן ב-SSTable, תוכלו לאחסן רק את ערך התא ב-Memtable, אבל בבסיסי הנתונים יש הבדלים לגבי מה שמאוחסן. Cassandra שומרת רק את הערך החדש ביותר ב-memtable, בעוד ש-Bigtable שומרת את כל הגרסאות ב-memtable.
לחלופין, אם מחקתם לפחות גרסה אחת של ערך תא לדיסק בטבלאות SST נפרדות, מסדי הנתונים מטפלים בבקשות לנתונים האלה בצורה שונה. כשמבקשים את התא מ-Cassandra, מוחזר רק הערך העדכני ביותר לפי חותמת הזמן. במילים אחרות, פעולת הכתיבה האחרונה היא הקובעת. ב-Bigtable, משתמשים במסננים כדי לקבוע אילו גרסאות של תאים יוחזרו בבקשת קריאה.
מחיקות של שורות
מכיוון שבשני מסדי הנתונים נעשה שימוש בקובצי SSTable בלתי ניתנים לשינוי כדי לשמור נתונים בדיסק, אי אפשר למחוק שורה באופן מיידי. כדי להבטיח שהשאילתות יחזירו את התוצאות הנכונות אחרי מחיקת שורה, שני מסדי הנתונים מטפלים במחיקות באמצעות אותו מנגנון. קודם כל, נוסף סמן (שנקרא tombstone ב-Cassandra) ל-memtable. בסופו של דבר, טבלת SSTable חדשה מכילה סמן עם חותמת זמן שמציין שהמזהה הייחודי של השורה נמחק ואין להחזיר אותו בתוצאות של שאילתות.
משך החיים (TTL)
היכולות של אורך החיים (TTL) בשני מסדי הנתונים דומות, למעט הבדל אחד. ב-Cassandra, אפשר להגדיר את ה-TTL לעמודה או לטבלה, אבל ב-Bigtable אפשר להגדיר את ה-TTL רק לקבוצת העמודות. קיימת שיטה ב-Bigtable שיכולה לדמות TTL ברמת התא .
איסוף אשפה
כמו שצוין קודם, אי אפשר לעדכן או למחוק נתונים באופן מיידי ב-SSTables שלא ניתן לשנות, ולכן מתבצע מנגנון איסוף במהלך תהליך שנקרא דחיסה. במהלך התהליך הזה, המערכת מסירה תאים או שורות שלא צריכים להופיע בתוצאות של שאילתות.
תהליך איסוף האשפה אינו כולל שורה או תא כאשר מתרחש מיזוג SSTable. אם יש סמן או מצבה לשורה, השורה הזו לא נכללת ב-SSTable שמתקבל. שני מסדי הנתונים יכולים להחריג תא מ-SSTable הממוזג. אם חותמת הזמן של התא חורגת מההסמכה של TTL, מסדי הנתונים לא כוללים את התא. אם יש שתי גרסאות עם חותמת זמן לתא נתון, Cassandra כוללת ב-SSTable הממוזג רק את הערך האחרון.
נתיב קריאת הנתונים
כשפעולת קריאה מגיעה לצומת העיבוד המתאים, תהליך הקריאה להשגת נתונים כדי לספק תוצאה של שאילתה זהה בשני מסדי הנתונים.
לכל SSTable בדיסק שעשוי להכיל תוצאות של שאילתות, נבדק מסנן Bloom כדי לקבוע אם כל קובץ מכיל שורות שצריך להחזיר. מכיוון שמסנני Bloom אף פעם לא מספקים תוצאה שלילית שגויה, כל טבלאות ה-SSTable שעומדות בדרישות מתווספות לרשימת מועמדים שייכללו בעיבוד נוסף של תוצאות הקריאה.
פעולת הקריאה מתבצעת באמצעות תצוגה מאוחדת שנוצרת מטבלת הזיכרון ומטבלאות ה-SSTable הפוטנציאליות בדיסק. מכיוון שכל המפתחות ממוינים לקסיקוגרפית, אפשר לקבל בקלות תצוגה מאוחדת שנסרקת כדי לקבל תוצאות של שאילתות.
ב-Cassandra, קבוצה של צמתי עיבוד שנקבעים לפי רמת העקביות של הפעולה חייבת להשתתף בפעולה. ב-Bigtable, צריך להתייעץ רק עם הצומת שאחראי לטווח המפתחות. ב-Cassandra, צריך לקחת בחשבון את ההשלכות של קביעת גודל המחשוב, כי סביר להניח שכמה צמתים יעבדו כל קריאה.
אפשר להגביל את תוצאות הקריאה בצורה קצת שונה בצומת העיבוד.
ב-Cassandra, סעיף WHERE בשאילתת CQL מגביל את השורות שמוחזרות. המגבלה היא שאפשר להשתמש בעמודות במפתח הראשי או בעמודות שכלולות באינדקס משני כדי להגביל את התוצאות.
Bigtable מציע מגוון רחב של מסננים שמשפיעים על השורות או התאים שמאוחזרים על ידי שאילתת קריאה.
יש שלוש קטגוריות של מסננים:
- מסננים מגבילים, שקובעים אילו שורות או תאים ייכללו בתשובה.
- שינוי מסננים, שמשפיעים על הנתונים או על המטא-נתונים של תאים ספציפיים.
- יצירת מסננים, שמאפשרת לכם לשלב כמה מסננים למסנן אחד.
מסננים מגבילים הם המסננים הנפוצים ביותר – לדוגמה, column family regular expression ו-column qualifier regular expression .
אחסון פיזי של נתונים
גם Bigtable וגם Cassandra מאחסנים נתונים ב-SSTables, שמתבצע בהם מיזוג באופן קבוע במהלך שלב הדחיסה. דחיסת נתונים ב-SSTable מציעה יתרונות דומים לצמצום גודל האחסון. עם זאת, הדחיסה מופעלת אוטומטית ב-Bigtable, והיא אפשרות הגדרה ב-Cassandra.
כשמשווים בין שני מסדי הנתונים, חשוב להבין איך כל מסד נתונים שומר את הנתונים באופן פיזי בצורה שונה בהיבטים הבאים:
- אסטרטגיית חלוקת הנתונים
- מספר הגרסאות הזמינות של התא
- סוג דיסק האחסון
- מנגנון העמידות והשכפול של הנתונים
חלוקת נתונים
ב-Cassandra, השיטה המומלצת לקביעת חלוקת הנתונים בין קובצי ה-SSTable השונים שמוצגים על ידי צמתי האשכול היא גיבוב עקבי של עמודות המחיצה של המפתח הראשי.
Bigtable משתמש בתחילית משתנה למפתח השורה המלא כדי למקם נתונים ב-SSTables בסדר לקסיקוגרפי.
גרסאות של תאים
ב-Cassandra נשמרת רק גרסה אחת של ערך תא פעיל. אם מתבצעות שתי פעולות כתיבה לתא, מדיניות 'הכתיבה האחרונה קובעת' מבטיחה שרק ערך אחד יוחזר.
ב-Bigtable אין הגבלה על מספר הגרסאות עם חותמת הזמן של כל תא. יכול להיות שיחולו מגבלות נוספות על גודל השורה. אם לא מוגדרת בקשת לקוח, חותמת הזמן נקבעת על ידי שירות Bigtable ברגע שצומת העיבוד מקבל את השינוי. ניתן לגזום גרסאות תאים באמצעות מדיניות איסוף אשפה שיכולה להיות שונה עבור כל משפחת עמודות של טבלה, או שניתן לסנן אותן מקבוצת תוצאות שאילתה דרך ה-API.
נפח אחסון בדיסק
Cassandra מאחסנת SSTables בדיסקים שמצורפים לכל צומת באשכול. כדי לאזן מחדש את הנתונים ב-Cassandra, צריך להעתיק את הקבצים פיזית בין השרתים.
Bigtable משתמש ב-Colossus כדי לאחסן SSTables. מכיוון ש-Bigtable משתמשת במערכת הקבצים המבוזרת הזו, שירות Bigtable יכול להקצות מחדש SSTables לצמתים שונים כמעט באופן מיידי.
עמידות ושכפול של נתונים
Cassandra מספקת עמידות נתונים באמצעות הגדרת פקטור השכפול. גורם השכפול קובע את מספר העותקים של SSTable שמאוחסנים בצמתים שונים באשכול. הגדרה אופיינית של גורם השכפול היא 3, שעדיין מאפשרת הבטחות עקביות חזקות יותר עם QUORUM או LOCAL_QUORUM גם אם מתרחשת כשל בצומת.
ב-Bigtable, עמידות גבוהה של הנתונים מובטחת באמצעות השכפול ש-Colossus מספק.
התרשים הבא מדגים את פריסת הנתונים הפיזית, את צמתי העיבוד של Bigtable ואת שכבת הניתוב:

בשכבת האחסון של Colossus, כל צומת מוקצה להצגת הנתונים שמאוחסנים בסדרת SSTables. ה-SSTables האלה מכילים את הנתונים של טווחי מפתחות השורות שמוקצים באופן דינמי לכל צומת. בתרשים מוצגים שלושה קובצי SSTable לכל צומת, אבל סביר להניח שיש יותר כי קובצי SSTable נוצרים באופן רציף כשהצמתים מקבלים שינויים חדשים בנתונים.
לכל צומת יש יומן משותף. פעולות כתיבה שמעובדות על ידי כל צומת נשמרות באופן מיידי ביומן המשותף לפני שהלקוח מקבל אישור כתיבה. מכיוון שפעולת כתיבה ב-Colossus משוכפלת מספר פעמים, העמידות מובטחת גם אם מתרחשת כשל בחומרה של הצומת לפני שהנתונים נשמרים ב-SSTable עבור טווח השורות.
ממשקי אפליקציות
במקור, הגישה למסד הנתונים של Cassandra נחשפה דרך Thrift API, אבל שיטת הגישה הזו הוצאה משימוש. האינטראקציה המומלצת עם הלקוח היא באמצעות CQL.
בדומה ל-Thrift API המקורי של Cassandra, הגישה למסד הנתונים של Bigtable מתבצעת דרך API שקורא וכותב נתונים על סמך מפתחות השורות שסופקו.
בדומה ל-Cassandra, ל-Bigtable יש גם ממשק שורת פקודה, שנקרא cbt CLI, וגם ספריות לקוח שתומכות בשפות תכנות נפוצות רבות. הספריות האלה מבוססות על ממשקי ה-API של gRPC ו-REST. אפליקציות שנכתבו עבור Hadoop ומסתמכות על ספריית הקוד הפתוח Apache HBase ל-Java יכולות להתחבר ל-Bigtable בלי שינויים משמעותיים. לאפליקציות שלא נדרשת בהן תאימות ל-HBase, מומלץ להשתמש בלקוח Java המובנה של Bigtable.
אמצעי הבקרה של ניהול זהויות והרשאות גישה (IAM) ב-Bigtable משולבים באופן מלא ב- Google Cloud, ואפשר גם להשתמש בטבלאות כמקור נתונים חיצוני מ-BigQuery.
הגדרת מסד נתונים
כשמגדירים אשכול Cassandra, צריך לקבל כמה החלטות לגבי ההגדרות ולבצע כמה שלבים. קודם צריך להגדיר את צמתי השרת כדי לספק קיבולת חישוב ולהקצות אחסון מקומי. כשמשתמשים בפקטור שכפול של שלוש, ההגדרה המומלצת והנפוצה ביותר, צריך להקצות נפח אחסון שיאפשר לאחסן פי שלושה מכמות הנתונים שרוצים לאחסן באשכול. צריך גם לקבוע ולהגדיר את ההגדרות של הצמתים הווירטואליים, המתלים והשכפול.
ההפרדה בין מחשוב לאחסון ב-Bigtable מפשטת את ההגדלה וההקטנה של אשכולות בהשוואה ל-Cassandra. בדרך כלל, כשמריצים אשכול, צריך להתייחס רק לנפח האחסון הכולל שבו נעשה שימוש בטבלאות המנוהלות, שקובע את המספר המינימלי של הצמתים, ולוודא שיש מספיק צמתים כדי לעמוד בקצב הנוכחי של שאילתות לשנייה.
אתם יכולים לשנות במהירות את הגודל של אשכול Bigtable אם האשכול גדול מדי או קטן מדי בהתאם לעומס הייצור.
אחסון ב-Bigtable
מלבד המיקום הגיאוגרפי של האשכול הראשוני, הבחירה היחידה שצריך לעשות כשיוצרים את מופע Bigtable היא סוג האחסון. ב-Bigtable יש שתי אפשרויות לאחסון: כונני SSD או דיסקים קשיחים (HDD). כל האשכולות במופע צריכים לחלוק את אותו סוג אחסון.
כשמתכננים את נפח האחסון ב-Bigtable, לא צריך לקחת בחשבון עותקים משוכפלים של האחסון, כמו שצריך לעשות כשמתכננים את הגודל של אשכול Cassandra. אין ירידה בצפיפות האחסון כדי להשיג סובלנות לתקלות, כמו שקורה ב-Cassandra. בנוסף, מכיוון שלא צריך להקצות נפח אחסון באופן מפורש, אתם מחויבים רק על נפח האחסון שבשימוש.
SSD
הקיבולת של צומת ה-SSD היא 5 TB, וזה עדיף לרוב עומסי העבודה. צפיפות האחסון גבוהה יותר בהשוואה להגדרה המומלצת למכונות Cassandra, שבה צפיפות האחסון המקסימלית היא פחות מ-2 TB לכל צומת. כשמעריכים את הקיבולת הנדרשת לאחסון, חשוב לזכור שב-Bigtable נספר עותק אחד בלבד של הנתונים. לשם השוואה, ברוב התצורות של Cassandra צריך להביא בחשבון שלושה עותקים של הנתונים.
למרות ש-QPS של כתיבה בכונן SSD דומה ל-QPS של כתיבה בכונן HDD, כונן SSD מספק QPS של קריאה גבוה משמעותית בהשוואה לכונן HDD. התמחור של אחסון SSD זהה או דומה לעלויות של דיסקים קשיחים מסוג SSD, והוא משתנה בהתאם לאזור.
HDD
סוג האחסון HDD מאפשר צפיפות אחסון משמעותית – 16 TB לכל צומת. החיסרון הוא שקריאות אקראיות איטיות משמעותית, ותומכות רק בקריאה של 500 שורות לשנייה לכל צומת. מומלץ להשתמש ב-HDD לעומסי עבודה (workloads) שכוללים הרבה פעולות כתיבה, שבהם פעולות הקריאה צפויות להיות סריקות טווח שקשורות לעיבוד באצווה. התמחור של אחסון ב-HDD דומה לעלות שמשויכת ל-Cloud Storage, והוא משתנה בהתאם לאזור.
שיקולים לגבי גודל האשכול
כשקובעים את הגודל של מופע Bigtable כדי להתכונן להעברת עומס עבודה של Cassandra, יש כמה שיקולים שצריך לקחת בחשבון כשמשווים בין אשכולות Cassandra של מרכז נתונים יחיד לבין מופעי Bigtable של אשכול יחיד, ובין אשכולות Cassandra של כמה מרכזי נתונים לבין מופעי Bigtable של כמה אשכולות. ההנחיות בקטעים הבאים מניחות שלא צריך לבצע שינויים משמעותיים במודל הנתונים כדי לבצע את ההעברה, ושיש דחיסה שוות ערך של נפח האחסון בין Cassandra לבין Bigtable.
קלאסטר של מרכז נתונים יחיד
כשמשווים בין קלאסטר של מרכז נתונים יחיד לבין מופע Bigtable של קלאסטר יחיד, צריך קודם לשקול את דרישות האחסון. כדי להעריך את הגודל של כל מרחב מפתחות שלא שוכפל, אפשר להשתמש בפקודה nodetool tablestats ולחלק את הגודל הכולל של האחסון שרוקן בפקטור השכפול של מרחב המפתחות. לאחר מכן, מחלקים את כמות האחסון שלא שוכפלה בכל מרחבי המפתחות ב-3.5 TB (5 TB * 0.70) כדי לקבוע את מספר צמתי ה-SSD המומלץ לטיפול באחסון בלבד. כמו
שצוין, Bigtable מטפל בשכפול ובאמינות האחסון
במסגרת רמה נפרדת ששקופה למשתמש.
בשלב הבא, צריך לקחת בחשבון את דרישות המחשוב למספר הצמתים. אפשר לעיין במדדים של שרת Cassandra ובמדדים של אפליקציית הלקוח כדי לקבל מספר משוער של פעולות קריאה וכתיבה שבוצעו. כדי להעריך את מספר צמתי ה-SSD המינימלי שנדרש לביצוע עומס העבודה, מחלקים את המדד הזה ב-10,000. כנראה שתצטרכו יותר צמתים לאפליקציות שדורשות תוצאות של שאילתות עם זמן אחזור נמוך. Google ממליצה לבדוק את הביצועים של Bigtable באמצעות נתונים ושאילתות מייצגים כדי לקבוע מדד של QPS לכל צומת שאפשר להשיג עבור עומס העבודה שלכם.
מספר הצמתים שנדרש לאשכול צריך להיות שווה לערך הגדול יותר מבין צורכי האחסון והחישוב. אם אתם לא בטוחים לגבי הצרכים שלכם מבחינת נפח אחסון או קצב העברת נתונים, אתם יכולים להתאים את מספר הצמתים של Bigtable למספר המכונות הטיפוסיות של Cassandra. אתם יכולים להגדיל או להקטין את הגודל של אשכול Bigtable בהתאם לצרכים של עומס העבודה, במינימום מאמץ וללא השבתה.
אשכול מרובה מרכזי נתונים
באשכולות עם כמה מרכזי נתונים, קשה יותר לקבוע את ההגדרה של מופע Bigtable. במצב אידיאלי, צריך שיהיה אשכול בכל מופע לכל מרכז נתונים בטופולוגיה של Cassandra. כל אשכול Bigtable במופע צריך לאחסן את כל הנתונים במופע, ולעמוד בקצב הכולל של הוספת נתונים באשכול. אפשר ליצור אשכולות במופע בכל אזור נתמך בענן ברחבי העולם.
הטכניקה להערכת צורכי האחסון דומה לגישה לאשכולות של מרכז נתונים יחיד. משתמשים בפקודה nodetool כדי לתעד את גודל האחסון של כל מרחב מפתחות באשכול Cassandra, ואז מחלקים את הגודל הזה במספר העותקים המשוכפלים. חשוב לזכור שלמרחב המפתחות של טבלה יכולים להיות גורמי שכפול שונים לכל מרכז נתונים.
מספר הצמתים בכל אשכול במופע צריך להיות מספיק כדי לטפל בכל פעולות הכתיבה באשכול ובכל פעולות הקריאה לפחות לשני מרכזי נתונים, כדי לשמור על יעדי רמת השירות (SLO) במהלך הפסקת פעילות של אשכול. גישה נפוצה היא להתחיל עם כל האשכולות עם קיבולת צמתים ששווה לקיבולת של מרכז הנתונים העמוס ביותר באשכול Cassandra. אפשר להגדיל או להקטין את הגודל של אשכולות Bigtable במופע באופן נפרד, כדי להתאים לצרכים של עומס העבודה בלי השבתה.
ניהול
Bigtable מספק רכיבים שמנוהלים במלואם לפונקציות ניהול נפוצות שמבוצעות ב-Cassandra.
גיבוי ושחזור
יש שתי שיטות ב-Bigtable שמתאימות לצרכי גיבוי נפוצים: גיבויים של Bigtable וייצוא נתונים מנוהל.
אפשר לחשוב על גיבויים של Bigtable כעל גרסה מנוהלת של תכונת הצילום של Cassandra nodetool. גיבויים של Bigtable יוצרים עותקים של טבלה שאפשר לשחזר, והם מאוחסנים כאובייקטים של חברים באשכול. אפשר לשחזר גיבויים כטבלה חדשה באשכול שממנו התחיל הגיבוי. הגיבויים נועדו ליצור נקודות שחזור אם מתרחשת השחתה ברמת האפליקציה. גיבויים שיוצרים באמצעות כלי השירות הזה לא צורכים משאבי צומת, והמחיר שלהם זהה למחירים של Cloud Storage או קרוב אליהם. אפשר להפעיל גיבויים של Bigtable באופן פרוגרמטי או דרך מסוף Google Cloud של Bigtable.
דרך נוספת לגבות את Bigtable היא באמצעות ייצוא נתונים מנוהל ל-Cloud Storage. אפשר לייצא לפורמטים Avro, Parquet או Hadoop Sequence. בהשוואה לגיבויים של Bigtable, ייצואים לוקחים יותר זמן לביצוע וכוללים עלויות מחשוב נוספות כי הייצואים משתמשים ב-Dataflow. עם זאת, הייצוא הזה יוצר קבצי נתונים ניידים שאפשר להריץ עליהם שאילתות במצב אופליין או לייבא אותם למערכת אחרת.
שינוי הגודל
מכיוון שב-Bigtable יש הפרדה בין האחסון לבין המחשוב, אפשר להוסיף או להסיר צמתים של Bigtable בתגובה לביקוש של שאילתות בצורה חלקה יותר מאשר ב-Cassandra. הארכיטקטורה ההומוגנית של Cassandra מחייבת אתכם לבצע איזון מחדש של הצמתים (או הצמתים הווירטואליים) במכונות באשכול.
אפשר לשנות את גודל האשכול באופן ידני במסוף Google Cloud או באופן פרוגרמטי באמצעות Cloud Bigtable API. הוספת צמתים לאשכול יכולה להניב שיפורים משמעותיים בביצועים תוך דקות. חלק מהלקוחות השתמשו בהצלחה בכלי לשינוי גודל אוטומטי שפותח על ידי Spotify.
תחזוקה פנימית
שירות Bigtable מטפל בצורה חלקה במשימות נפוצות של תחזוקה פנימית של Cassandra, כמו תיקון של מערכת ההפעלה, שחזור צמתים, תיקון צמתים, ניטור של דחיסת אחסון ורוטציה של אישורי SSL.
מעקב
החיבור של Bigtable להצגה חזותית של מדדים או להגדרת התראות לא דורש מאמץ מצד האדמין או המפתח. בדף המסוף של BigtableGoogle Cloud יש לוחות בקרה מוכנים מראש למעקב אחרי מדדי התפוקה והניצול ברמות המופע, האשכול והטבלה. אפשר ליצור תצוגות מותאמות אישית והתראות בלוחות הבקרה של Cloud Monitoring, שבהם המדדים זמינים באופן אוטומטי.
Key Visualizer של Bigtable היא תכונת מעקב במסוף Google Cloud שמאפשרת לכם לבצע כוונון מתקדם של הביצועים.
ניהול הזהויות והרשאות הגישה ואבטחה
ב-Bigtable, ההרשאה משולבת באופן מלא בGoogle Cloudמסגרת IAM, ונדרשת הגדרה ותחזוקה מינימליות. חשבונות משתמשים מקומיים וסיסמאות לא משותפים עם אפליקציות לקוח. במקום זאת, הרשאות ותפקידים מפורטים מוענקים למשתמשים ברמת הארגון ולחשבונות שירות.
ב-Bigtable כל הנתונים מוצפנים באופן אוטומטי גם כשהם באחסון וגם כשהם מועברים. אין אפשרות להשבית את התכונות האלה. כל הרשאת אדמין מתועדת באופן מלא. אתם יכולים להשתמש ב-VPC Service Controls כדי לשלוט בגישה למופעי Bigtable מחוץ לרשתות מאושרות.
המאמרים הבאים
- מידע נוסף על עיצוב סכימות ב-Bigtable
- מידע נוסף על Apache Cassandra
- אפשר לנסות את ה-codelab בנושא Bigtable למשתמשי Cassandra.
- מידע נוסף על אמולטור Bigtable
- כדאי להעמיק את הקריאה ולהכיר דוגמאות לארכיטקטורות, תרשימים ושיטות מומלצות בנושאי Google Cloud. כל אלה זמינים במרכז הארכיטקטורה של Cloud.