
En este tutorial, visualizarás datos de analíticas geoespaciales de BigQuery mediante un cuaderno de Colab.
En este tutorial se usan los siguientes conjuntos de datos públicos de BigQuery:
- San Francisco Ford GoBike Share
- Barrios de San Francisco
- Informes del Departamento de Policía de San Francisco (SFPD)
Para obtener información sobre cómo acceder a estos conjuntos de datos públicos, consulta Acceder a conjuntos de datos públicos en la consola Google Cloud .
Usa los conjuntos de datos públicos para crear las siguientes visualizaciones:
- Un gráfico de dispersión de todas las estaciones de bicicletas compartidas del conjunto de datos de Ford GoBike Share
- Polígonos del conjunto de datos Barrios de San Francisco
- Un mapa coroplético del número de estaciones de bicicletas compartidas por barrio
- Un mapa de calor de los incidentes del conjunto de datos de informes del Departamento de Policía de San Francisco
Objetivos
- Configura la autenticación con Google Cloud y, opcionalmente, Google Maps.
- Consulta datos en BigQuery y descarga los resultados en Colab.
- Usa herramientas de ciencia de datos de Python para realizar transformaciones y análisis.
- Crea visualizaciones, como gráficos de dispersión, polígonos, mapas coropléticos y mapas de calor.
Costes
En este documento, se utilizan los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costes basada en el uso previsto,
utiliza la calculadora de precios.
Cuando termines las tareas que se describen en este documento, puedes evitar que se te siga facturando eliminando los recursos que hayas creado. Para obtener más información, consulta la sección Limpiar.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Asegúrate de que tienes los permisos necesarios para realizar las tareas descritas en este documento.
- BigQuery User (
roles/bigquery.user) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Ir a Gestión de Identidades y Accesos - Selecciona el proyecto.
- Haz clic en Conceder acceso.
-
En el campo Nuevos principales, introduce tu identificador de usuario. Normalmente, se trata de la dirección de correo de una cuenta de Google.
- En la lista Selecciona un rol, elige un rol.
- Para conceder más roles, haz clic en Añadir otro rol y añade cada rol adicional.
- Haz clic en Guardar.
Abre Colab.
En el cuadro de diálogo Abrir cuaderno, haz clic en Nuevo cuaderno.
Haz clic en
Untitled0.ipynby cambia el nombre del cuaderno abigquery-geo.ipynb.Selecciona Archivo > Guardar.
Para insertar una celda de código, haz clic en Código.
Para autenticarte con tu proyecto, introduce el siguiente código:
# REQUIRED: Authenticate with your project. GCP_PROJECT_ID = "PROJECT_ID" #@param {type:"string"} from google.colab import auth from google.colab import userdata auth.authenticate_user(project_id=GCP_PROJECT_ID) # Set GMP_API_KEY to none GMP_API_KEY = None
Sustituye PROJECT_ID por el ID del proyecto.
Haz clic en Ejecutar celda.
Cuando se te solicite, haz clic en Permitir para dar acceso a Colab a tus credenciales, si estás de acuerdo.
En la página Iniciar sesión con Google, elige tu cuenta.
En la página Iniciar sesión en el código del cuaderno creado por terceros, haz clic en Continuar.
En Selecciona a qué puede acceder el código del cuaderno creado por terceros, haz clic en Seleccionar todo y, a continuación, en Continuar.
Una vez que hayas completado el flujo de autorización, no se generará ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para obtener tu clave de API de Google Maps, sigue las instrucciones de la página Usar claves de API de la documentación de Google Maps.
Cambia al cuaderno de Colab y haz clic en Secretos.
Haz clic en Añadir secreto nuevo.
En Nombre, escribe
GMP_API_KEY.En Valor, introduce el valor de la clave de API de Maps que has generado anteriormente.
Cierra el panel Secretos.
Para insertar una celda de código, haz clic en Código.
Para autenticarte con la API Maps, introduce el siguiente código:
# Authenticate with the Google Maps JavaScript API. GMP_API_SECRET_KEY_NAME = "GMP_API_KEY" #@param {type:"string"} if GMP_API_SECRET_KEY_NAME: GMP_API_KEY = userdata.get(GMP_API_SECRET_KEY_NAME) if GMP_API_SECRET_KEY_NAME else None else: GMP_API_KEY = None
Cuando se te pida, haz clic en Conceder acceso para dar acceso al cuaderno a tu clave, si estás de acuerdo.
Haz clic en Ejecutar celda.
Una vez que hayas completado el flujo de autorización, no se generará ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
geopandaspara ampliar los tipos de datos que usapandasy permitir operaciones espaciales en tipos geométricos.shapelypara manipular y analizar objetos geométricos planos.brancapara generar mapas de colores HTML y JavaScript.geemap.deckpara la visualización conpydeckyearthengine-api.Para insertar una celda de código, haz clic en Código.
Para instalar los paquetes
pydeckyh3, introduce el siguiente código:# Install pydeck and h3. !pip install pydeck>=0.9 h3>=4.2
Haz clic en Ejecutar celda.
Una vez que hayas completado la instalación, no se generará ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para importar las bibliotecas de Python, introduce el siguiente código:
# Import data science libraries. import branca import geemap.deck as gmdk import h3 import pydeck as pdk import geopandas as gpd import shapely
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para habilitar
pandasDataFrames, introduce el siguiente código:# Enable displaying pandas data frames as interactive tables by default. from google.colab import data_table data_table.enable_dataframe_formatter()
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para crear una rutina compartida para renderizar capas en un mapa, introduce el siguiente código:
# Set Google Maps as the base map provider. MAP_PROVIDER_GOOGLE = pdk.bindings.base_map_provider.BaseMapProvider.GOOGLE_MAPS.value # Shared routine for rendering layers on a map using geemap.deck. def display_pydeck_map(layers, view_state, **kwargs): deck_kwargs = kwargs.copy() # Use Google Maps as the base map only if the API key is provided. if GMP_API_KEY: deck_kwargs.update({ "map_provider": MAP_PROVIDER_GOOGLE, "map_style": pdk.bindings.map_styles.GOOGLE_ROAD, "api_keys": {MAP_PROVIDER_GOOGLE: GMP_API_KEY}, }) m = gmdk.Map(initial_view_state=view_state, ee_initialize=False, **deck_kwargs) for layer in layers: m.add_layer(layer) return m
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para consultar el conjunto de datos público de San Francisco Ford GoBike Share, introduce el siguiente código. Este código usa la función mágica
%%bigquerypara ejecutar la consulta y devolver los resultados en un DataFrame:# Query the station ID, station name, station short name, and station # geometry from the bike share dataset. # NOTE: In this tutorial, the denormalized 'lat' and 'lon' columns are # ignored. They are decomposed components of the geometry. %%bigquery gdf_sf_bikestations --project {GCP_PROJECT_ID} --use_geodataframe station_geom SELECT station_id, name, short_name, station_geom FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info`
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Para insertar una celda de código, haz clic en Código.
Para obtener un resumen del DataFrame, incluidas las columnas y los tipos de datos, introduce el siguiente código:
# Get a summary of the DataFrame gdf_sf_bikestations.info()
Haz clic en Ejecutar celda.
La salida debería tener este aspecto:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 472 entries, 0 to 471 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 station_id 472 non-null object 1 name 472 non-null object 2 short_name 472 non-null object 3 station_geom 472 non-null geometry dtypes: geometry(1), object(3) memory usage: 14.9+ KBPara insertar una celda de código, haz clic en Código.
Para obtener una vista previa de las cinco primeras filas del DataFrame, introduce el siguiente código:
# Preview the first five rows gdf_sf_bikestations.head()
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:

Para insertar una celda de código, haz clic en Código.
Para extraer los valores de longitud y latitud de la columna
station_geom, introduce el siguiente código:# Extract the longitude (x) and latitude (y) from station_geom. gdf_sf_bikestations["longitude"] = gdf_sf_bikestations["station_geom"].x gdf_sf_bikestations["latitude"] = gdf_sf_bikestations["station_geom"].y
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para representar el gráfico de dispersión de las estaciones de bicicletas compartidas en función de los valores de longitud y latitud que has extraído anteriormente, introduce el siguiente código:
# Render a scatter plot using pydeck with the extracted longitude and # latitude columns in the gdf_sf_bikestations geopandas.GeoDataFrame. scatterplot_layer = pdk.Layer( "ScatterplotLayer", id="bike_stations_scatterplot", data=gdf_sf_bikestations, get_position=['longitude', 'latitude'], get_radius=100, get_fill_color=[255, 0, 0, 140], # Adjust color as desired pickable=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([scatterplot_layer], view_state)
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
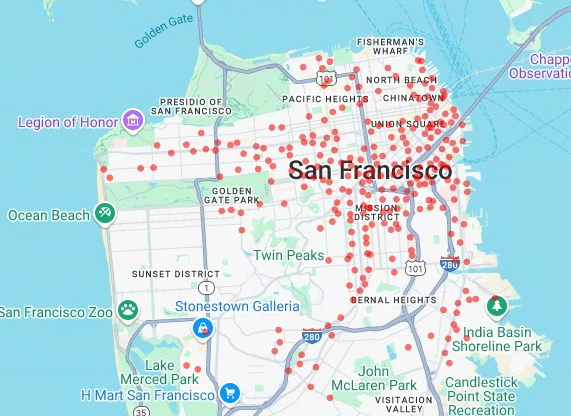
- Puntos
- Líneas
- Polígonos
- Multipolígonos
Para insertar una celda de código, haz clic en Código.
Para consultar los datos geográficos de la tabla
bigquery-public-data.san_francisco_neighborhoods.boundariesdel conjunto de datos San Francisco Neighborhoods, introduce el siguiente código. Este código usa la función mágica%%bigquerypara ejecutar la consulta y devolver los resultados en un DataFrame:# Query the neighborhood name and geometry from the San Francisco # neighborhoods dataset. %%bigquery gdf_sanfrancisco_neighborhoods --project {GCP_PROJECT_ID} --use_geodataframe geometry SELECT neighborhood, neighborhood_geom AS geometry FROM `bigquery-public-data.san_francisco_neighborhoods.boundaries`
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Para insertar una celda de código, haz clic en Código.
Para obtener un resumen del DataFrame, introduce el siguiente código:
# Get a summary of the DataFrame gdf_sanfrancisco_neighborhoods.info()
Haz clic en Ejecutar celda.
Los resultados deberían tener este aspecto:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 117 entries, 0 to 116 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 neighborhood 117 non-null object 1 geometry 117 non-null geometry dtypes: geometry(1), object(1) memory usage: 2.0+ KBPara previsualizar la primera fila del DataFrame, introduce el siguiente código:
# Preview the first row gdf_sanfrancisco_neighborhoods.head(1)
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:

En los resultados, observa que los datos son un polígono.
Para insertar una celda de código, haz clic en Código.
Para visualizar los polígonos, introduce el siguiente código.
pydeckse usa para convertir cada instancia de objetoshapelyde la columna de geometría al formatoGeoJSON:# Visualize the polygons. geojson_layer = pdk.Layer( 'GeoJsonLayer', id="sf_neighborhoods", data=gdf_sanfrancisco_neighborhoods, get_line_color=[127, 0, 127, 255], get_fill_color=[60, 60, 60, 50], get_line_width=100, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([geojson_layer], view_state)
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:

Para insertar una celda de código, haz clic en Código.
Para agregar y contar el número de estaciones por barrio, y crear una columna
polygonque contenga una matriz de puntos, introduce el siguiente código:# Aggregate and count the number of stations per neighborhood. gdf_count_stations = gdf_sanfrancisco_neighborhoods.sjoin(gdf_sf_bikestations, how='left', predicate='contains') gdf_count_stations = gdf_count_stations.groupby(by='neighborhood')['station_id'].count().rename('num_stations') gdf_stations_x_neighborhood = gdf_sanfrancisco_neighborhoods.join(gdf_count_stations, on='neighborhood', how='inner') # To simulate non-GeoJSON input data, create a polygon column that contains # an array of points by using the pandas.Series.map method. gdf_stations_x_neighborhood['polygon'] = gdf_stations_x_neighborhood['geometry'].map(lambda g: list(g.exterior.coords))
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para añadir una columna
fill_colorpara cada uno de los polígonos, introduce el siguiente código:# Create a color map gradient using the branch library, and add a fill_color # column for each of the polygons. colormap = branca.colormap.LinearColormap( colors=["lightblue", "darkred"], vmin=0, vmax=gdf_stations_x_neighborhood['num_stations'].max(), ) gdf_stations_x_neighborhood['fill_color'] = gdf_stations_x_neighborhood['num_stations'] \ .map(lambda c: list(colormap.rgba_bytes_tuple(c)[:3]) + [0.7 * 255]) # force opacity of 0.7
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para renderizar la capa de polígonos, introduce el siguiente código:
# Render the polygon layer. polygon_layer = pdk.Layer( 'PolygonLayer', id="bike_stations_choropleth", data=gdf_stations_x_neighborhood, get_polygon='polygon', get_fill_color='fill_color', get_line_color=[0, 0, 0, 255], get_line_width=50, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([polygon_layer], view_state)
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
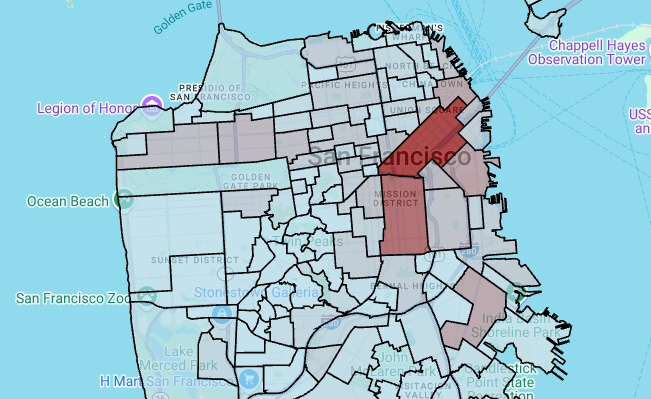
Para insertar una celda de código, haz clic en Código.
Para consultar los datos del conjunto de datos de informes del Departamento de Policía de San Francisco (SFPD), introduce el siguiente código. Este código usa la función mágica
%%bigquerypara ejecutar la consulta y devolver los resultados en un DataFrame:# Query the incident key and location data from the SFPD reports dataset. %%bigquery gdf_incidents --project {GCP_PROJECT_ID} --use_geodataframe location_geography SELECT unique_key, location_geography FROM ( SELECT unique_key, SAFE.ST_GEOGFROMTEXT(location) AS location_geography, # WKT string to GEOMETRY EXTRACT(YEAR FROM timestamp) AS year, FROM `bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents` incidents ) WHERE year = 2015
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Para insertar una celda de código, haz clic en Código.
Para calcular la celda de la latitud y la longitud de cada incidente, agregue los incidentes de cada celda, cree un
geopandasDataFrame y añada el centro de cada hexágono a la capa de mapa de calor. Para ello, introduzca el siguiente código:# Compute the cell for each incident's latitude and longitude. H3_RESOLUTION = 9 gdf_incidents['h3_cell'] = gdf_incidents.geometry.apply( lambda geom: h3.latlng_to_cell(geom.y, geom.x, H3_RESOLUTION) ) # Aggregate the incidents for each hexagon cell. count_incidents = gdf_incidents.groupby(by='h3_cell')['unique_key'].count().rename('num_incidents') # Construct a new geopandas.GeoDataFrame with the aggregate results. # Add the center of each hexagon for the HeatmapLayer to render. gdf_incidents_x_cell = gpd.GeoDataFrame(data=count_incidents).reset_index() gdf_incidents_x_cell['h3_center'] = gdf_incidents_x_cell['h3_cell'].apply(h3.cell_to_latlng) gdf_incidents_x_cell.info()
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 969 entries, 0 to 968 Data columns (total 3 columns): # Column Non-Null Count Dtype -- ------ -------------- ----- 0 h3_cell 969 non-null object 1 num_incidents 969 non-null Int64 2 h3_center 969 non-null object dtypes: Int64(1), object(2) memory usage: 23.8+ KBPara insertar una celda de código, haz clic en Código.
Para obtener una vista previa de las cinco primeras filas del DataFrame, introduce el siguiente código:
# Preview the first five rows. gdf_incidents_x_cell.head()
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:

Para insertar una celda de código, haz clic en Código.
Para convertir los datos a un formato JSON que pueda usar
HeatmapLayer, introduce el siguiente código:# Convert to a JSON format recognized by the HeatmapLayer. def _make_heatmap_datum(row) -> dict: return { "latitude": row['h3_center'][0], "longitude": row['h3_center'][1], "weight": float(row['num_incidents']), } heatmap_data = gdf_incidents_x_cell.apply(_make_heatmap_datum, axis='columns').values.tolist()
Haz clic en Ejecutar celda.
Después de ejecutar el código, no se genera ningún resultado en tu cuaderno de Colab. La marca de verificación situada junto a la celda indica que el código se ha ejecutado correctamente.
Para insertar una celda de código, haz clic en Código.
Para renderizar el mapa de calor, introduce el siguiente código:
# Render the heatmap. heatmap_layer = pdk.Layer( "HeatmapLayer", id="sfpd_heatmap", data=heatmap_data, get_position=['longitude', 'latitude'], get_weight='weight', opacity=0.7, radius_pixels=99, # this limitation can introduce artifacts (see above) aggregation='MEAN', ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([heatmap_layer], view_state)
Haz clic en Ejecutar celda.
El resultado debería ser similar al siguiente:

- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
En Colab, haz clic en Secretos.
Al final de la fila
GMP_API_KEY, haz clic en Eliminar.Opcional: Para eliminar el cuaderno, haz clic en Archivo > Mover a la papelera.
- Para obtener más información sobre las analíticas geoespaciales en BigQuery, consulta el artículo Introducción a las analíticas geoespaciales en BigQuery.
- Para obtener una introducción a la visualización de datos geoespaciales en BigQuery, consulta Visualizar datos geoespaciales.
- Para obtener más información sobre
pydecky otros tipos de gráficosdeck.gl, puedes consultar ejemplos en la galería depydeck, el catálogo de capas dedeck.gly el código fuente dedeck.glen GitHub. - Para obtener más información sobre cómo trabajar con datos geoespaciales en marcos de datos, consulta la página de introducción de GeoPandas y la guía de usuario de GeoPandas.
- Para obtener más información sobre la manipulación de objetos geométricos, consulta el manual de usuario de Shapely.
- Para obtener más información sobre cómo usar los datos de Google Earth Engine en BigQuery, consulta el artículo Exportar a BigQuery de la documentación de Google Earth Engine.
Roles obligatorios
Si creas un proyecto, serás el propietario y se te concederán todos los permisos de gestión de identidades y accesos necesarios para completar este tutorial.
Si usas un proyecto que ya tengas, necesitarás el siguiente rol a nivel de proyecto para ejecutar tareas de consulta.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Para obtener más información sobre los roles de BigQuery, consulta el artículo sobre los roles de gestión de identidades y accesos predefinidos.
Crear un cuaderno de Colab
En este tutorial se crea un cuaderno de Colab para visualizar datos de analíticas geoespaciales. Para abrir una versión precompilada del cuaderno en Colab, Colab Enterprise o BigQuery Studio, haz clic en los enlaces situados en la parte superior de la versión de GitHub del tutorial: Visualización geoespacial de BigQuery en Colab.
Autenticarse con Google Cloud y Google Maps
En este tutorial se consultan conjuntos de datos de BigQuery y se usa la API Google Maps JavaScript. Para usar estos recursos, debes autenticar el tiempo de ejecución de Colab con Google Cloud y la API Maps.
Autenticar con Google Cloud
Opcional: Autenticarse con Google Maps
Si usa Google Maps Platform como proveedor de mapas base, debe proporcionar una clave de API de Google Maps Platform. El cuaderno recupera la clave de tus secretos de Colab.
Este paso solo es necesario si usas la API Maps. Si no te autenticas con Google Maps Platform, pydeck usa el mapa carto.
Instalar paquetes de Python e importar bibliotecas de ciencia de datos
Además de los módulos de Python colabtools (google.colab), en este tutorial se usan otros paquetes de Python y bibliotecas de ciencia de datos.
En esta sección, instalarás los paquetes pydeck y h3. pydeck
proporciona renderización espacial a gran escala en Python, con la tecnología de deck.gl.
h3-py proporciona el sistema de indexación geoespacial jerárquico hexagonal H3 de Uber en Python.
A continuación, importa las bibliotecas h3 y pydeck, así como las siguientes bibliotecas geoespaciales de Python:
Después de importar las bibliotecas, habilita las tablas interactivas para pandas
DataFrames en Colab.
Instala los paquetes pydeck y h3.
Importar las bibliotecas de Python
Habilitar tablas interactivas para DataFrames de pandas
Crear una rutina compartida
En esta sección, crearás una rutina compartida que renderiza capas en un mapa base.
Crear un gráfico de dispersión
En esta sección, crearás un gráfico de dispersión de todas las estaciones de bicicletas compartidas del conjunto de datos público de San Francisco Ford GoBike Share. Para ello, obtendrás datos de la tabla bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info. El gráfico de dispersión se crea con una capa y una capa de dispersión del framework deck.gl.
Los gráficos de dispersión son útiles cuando necesitas revisar un subconjunto de puntos individuales (también conocido como comprobación puntual).
En el siguiente ejemplo se muestra cómo usar una capa y una capa de gráfico de dispersión para representar puntos individuales como círculos.
Para renderizar los puntos, debe extraer la longitud y la latitud como coordenadas x e y de la columna station_geom del conjunto de datos de bicicletas compartidas.
Como gdf_sf_bikestations es un geopandas.GeoDataFrame, se accede a las coordenadas directamente desde su columna de geometría station_geom. Puede obtener la longitud mediante el atributo .x de la columna y la latitud mediante el atributo .y. Después, puedes almacenarlos en columnas de longitud y latitud nuevas.
Visualizar polígonos
Las estadísticas geoespaciales te permiten analizar y visualizar datos geoespaciales en BigQuery mediante GEOGRAPHY tipos de datos y funciones geográficas de GoogleSQL.
El tipo de datos GEOGRAPHY
en la analítica geoespacial es una colección de puntos, cadenas de líneas y
polígonos, que se representa como un conjunto de puntos o un subconjunto de la superficie de la
Tierra. Un tipo GEOGRAPHY puede contener objetos como los siguientes:
Para ver una lista de todos los objetos admitidos, consulte la documentación del tipo GEOGRAPHY.
Si se le proporcionan datos geoespaciales sin saber las formas esperadas, puede visualizar los datos para descubrir las formas. Puedes visualizar las formas convirtiendo los datos geográficos al formato GeoJSON. Después, puedes visualizar los datos de GeoJSON con una capa de GeoJSON del framework deck.gl.
En esta sección, consultarás datos geográficos del conjunto de datos San Francisco Neighborhoods y, a continuación, visualizarás los polígonos.
Crear un mapa coroplético
Si estás analizando datos con polígonos que son difíciles de convertir al formato GeoJSON, puedes usar una capa de polígonos del framework deck.gl. Una capa de polígonos puede procesar datos de entrada de tipos específicos, como una matriz de puntos.
En esta sección, usarás una capa de polígonos para renderizar una matriz de puntos y usarás los resultados para renderizar un mapa coropleta. El mapa coroplético muestra la densidad de las estaciones de bicicletas compartidas por barrio. Para ello, se combinan los datos del conjunto de datos de barrios de San Francisco con los del conjunto de datos de bicicletas compartidas Ford GoBike de San Francisco.
Crear un mapa de calor
Los mapas coropletos son útiles cuando se conocen límites significativos. Si tienes datos sin límites significativos conocidos, puedes usar una capa de mapa de calor para representar su densidad continua.
En el siguiente ejemplo, se consultan datos de la tabla bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents del conjunto de datos San Francisco Police Department (SFPD) Reports. Los datos se usan para visualizar la distribución de incidentes en el 2015.
En el caso de los mapas de calor, se recomienda cuantificar y agregar los datos antes de representarlos. En este ejemplo, los datos se cuantifican y se agregan mediante la indexación espacial H3 de Carto.
El mapa de calor se crea con una capa de mapa de calor
del framework deck.gl.
En este ejemplo, la cuantización se realiza mediante la biblioteca de Python h3 para agregar los puntos de incidencia en hexágonos. La función h3.latlng_to_cell se usa para asignar la posición del incidente (latitud y longitud) a un índice de celda H3. Una resolución H3 de nueve proporciona suficientes hexágonos agregados para el mapa de calor.
La función h3.cell_to_latlng se usa para determinar el centro de cada hexágono.
Limpieza
Para evitar que los recursos utilizados en este tutorial se cobren en tu cuenta de Google Cloud, elimina el proyecto que contiene los recursos o conserva el proyecto y elimina los recursos.
Eliminar el proyecto
Consola
gcloud
Eliminar la clave de API de Google Maps y el cuaderno
Después de eliminar el Google Cloud proyecto, si has usado la API de Google Maps, elimina la clave de la API de Google Maps de tus secretos de Colab y, a continuación, elimina el cuaderno (opcional).