
嵌入和向量搜索简介
本文档简要介绍了 BigQuery 中的嵌入和向量搜索。向量搜索是一种使用嵌入比较相似对象的技术,用于为 Google 产品(包括 Google 搜索、YouTube 和 Google Play)提供支持。您可以使用向量搜索大规模执行搜索。将向量索引与向量搜索搭配使用时,您可以利用倒排文件索引 (IVF) 和 ScaNN 算法等基础技术。
向量搜索基于嵌入式搜索。嵌入是表示给定实体(如一段文本或音频文件)的高维数字向量。机器学习 (ML) 模型使用嵌入对此类实体的语义进行编码,以便更轻松地推断和比较实体。例如,聚类、分类和推荐模型中的常见操作是测量嵌入空间中矢量之间的距离,以查找语义上最相似的项。
当您考虑如何绘制不同项时,就可以直观地理解嵌入空间中的语义相似性和距离的概念。例如,cat、dog 和 lion 等字词都代表动物类型,由于它们具有共享的语义特征,因此会在此空间中紧密分组。同样,car、truck 和更通用的字词vehicle 也会形成另一个集群。具体可见以下图片:
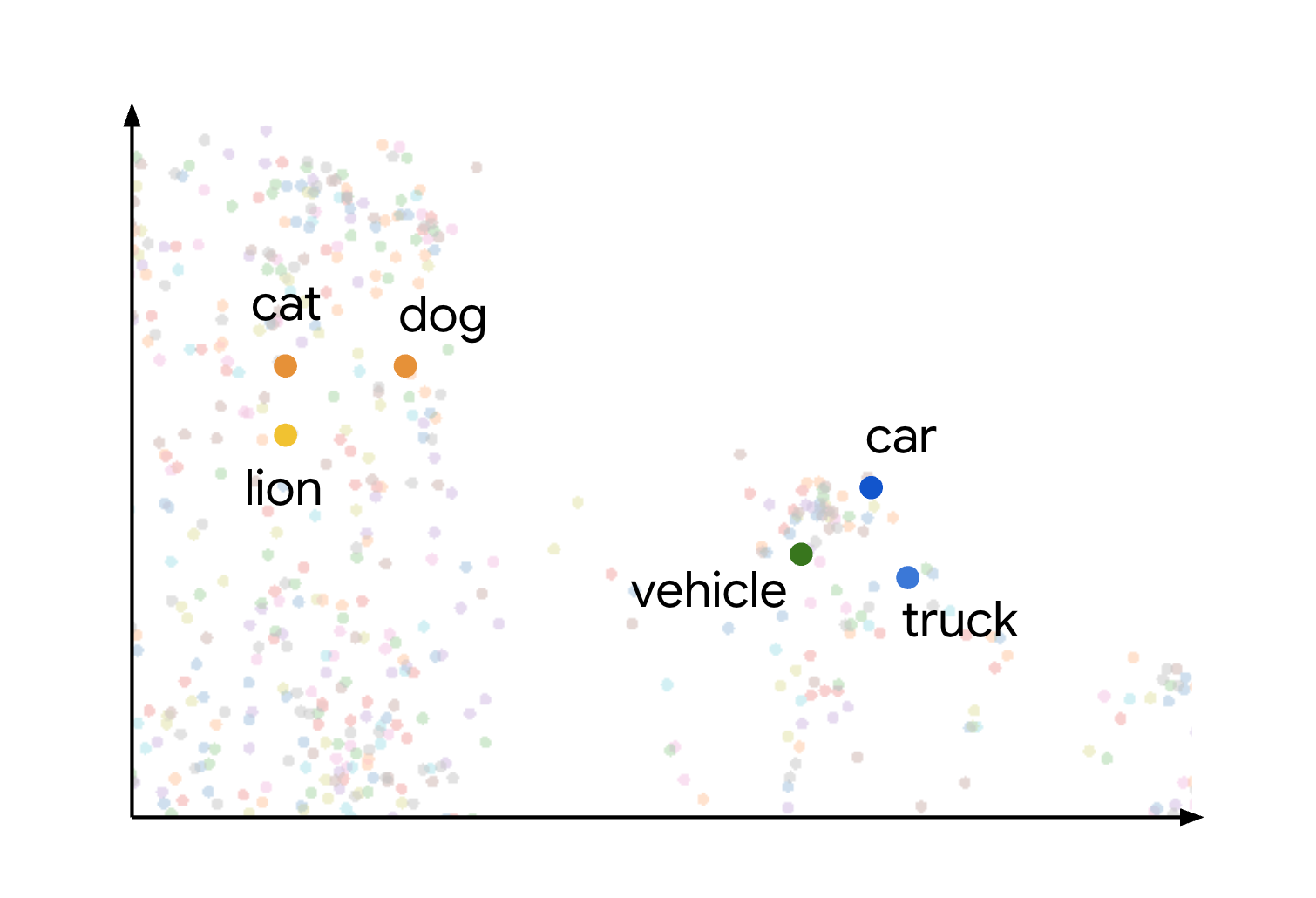
您可以看到,动物和车辆集群彼此相距甚远。各组之间的分离说明了以下原则:嵌入空间中对象之间的距离越近,它们的语义相似度就越高;距离越远,语义差异就越大。
使用场景
通过结合使用嵌入生成和向量搜索,可以实现许多有趣的用例。一些可能的用例如下:
- 检索增强生成 (RAG):在 BigQuery 中解析文档、对内容执行向量搜索,并使用 Gemini 模型生成对自然语言问题的摘要答案。如需查看说明此场景的笔记本,请参阅使用 BigQuery DataFrames 构建矢量搜索应用。
- 推荐替代商品或匹配商品:根据客户行为和商品相似性建议替代商品,从而提升电子商务应用的效果。
- 日志分析:帮助团队主动对日志中的异常进行分类,并加快调查进度。您还可以使用此功能来丰富 LLM 的上下文,以改进威胁检测、取证和问题排查工作流。如需查看演示此场景的笔记本,请参阅使用文本嵌入 + BigQuery Vector Search 对日志进行异常检测和调查。
- 聚类和定位:精确细分受众群。例如,连锁医院可以使用自然语言备注和结构化数据对患者进行分组,营销人员可以根据查询意图定位广告。如需查看说明此场景的笔记本,请参阅 Create-Campaign-Customer-Segmentation。
- 实体解析和去重:清理和整合数据。例如,广告公司可以对个人身份信息 (PII) 记录进行去重,房地产公司可以识别匹配的邮寄地址。
生成嵌入
以下部分介绍了 BigQuery 提供的可帮助您生成或处理嵌入内容的函数。
生成单个嵌入
您可以将 AI.EMBED 函数与 Vertex AI 嵌入模型搭配使用,以生成输入的单个嵌入。
AI.EMBED 函数支持以下类型的输入:
- 文本数据。
- 由
ObjectRef值表示的图片数据。(预览版) - 由
ObjectRefRuntime值表示的图片数据。
生成嵌入表
您可以使用 AI.GENERATE_EMBEDDING 创建一个表,其中包含输入表中某一列中所有数据的嵌入。对于所有类型的受支持模型,AI.GENERATE_EMBEDDING 适用于标准表中的结构化数据。对于多模态嵌入模型,AI.GENERATE_EMBEDDING 也适用于以下来源的视觉内容:包含 ObjectRef 值的标准表列或对象表。
对于远程模型,所有推理都在 Vertex AI 中进行。对于其他模型类型,所有推理都在 BigQuery 中进行。结果存储在 BigQuery 中。
您可以参考以下主题,尝试在 BigQuery ML 中生成嵌入:
- 使用
AI.GENERATE_EMBEDDING函数生成文本、图片或视频。 - 生成和搜索多模态嵌入
- 执行语义搜索和检索增强生成
自主嵌入生成
您可以使用自主生成嵌入内容来简化创建、维护和查询嵌入内容的过程。 BigQuery 会根据源列在您的表中维护一个嵌入向量列。当您在源列中添加或修改数据时,BigQuery 会使用 Vertex AI 嵌入模型自动为该数据生成或更新嵌入列。如果您希望在源数据定期更新时让 BigQuery 维护您的嵌入内容,此功能会很有帮助。
搜索
以下是可用的搜索功能:
VECTOR_SEARCH:使用 SQL 执行向量搜索。AI.SIMILARITY(预览版):通过计算两个输入内容嵌入之间的余弦相似度来比较这两个输入内容。如果您想执行少量比较,并且尚未预先计算任何嵌入内容,则此函数非常适用。当性能至关重要且您要处理大量嵌入时,应使用VECTOR_SEARCH。 比较它们的功能,以便为您的使用情形选择最佳函数。
(可选)您可以使用 CREATE VECTOR INDEX 语句创建向量索引。使用向量索引时,VECTOR_SEARCH 和 AI.SEARCH 函数会使用近似最近邻搜索技术来提高向量搜索性能,虽然降低召回率,但可返回更接近的结果。如果没有向量索引,这些函数会使用暴力搜索来衡量每条记录的距离。即使在向量索引可用时,您也可以选择使用暴力破解来获得精确的结果。
价格
VECTOR_SEARCH 和 AI.SEARCH 函数以及 CREATE VECTOR INDEX 语句使用 BigQuery 计算价格。
VECTOR_SEARCH和AI.SEARCH函数:您需要使用按需价格或版本价格为相似性搜索付费。- 按需:您需要为在基本表、索引和搜索查询中扫描的字节数付费。
版本价格:您需要为在预留版本中完成作业所需的槽付费。规模更大、更复杂的相似度计算会产生更多费用。
CREATE VECTOR INDEX声明:只要编入索引的表数据的总大小低于每个组织的限制,构建和刷新矢量索引所需的处理就无需付费。为支持超出此限制的索引,您必须提供自己的预留来处理索引管理作业。
存储空间也是嵌入和索引需要考虑的因素。以嵌入和索引形式存储的字节数会产生活跃存储费用。
- 矢量索引在处于活跃状态时会产生存储费用。
- 您可以使用
INFORMATION_SCHEMA.VECTOR_INDEXES视图查找索引存储空间大小。如果矢量索引尚未达到 100% 覆盖率,您仍需要为已编入索引的所有内容付费。您可以使用INFORMATION_SCHEMA.VECTOR_INDEXES视图检查索引涵盖范围。
配额和限制
如需了解详情,请参阅向量索引限制和生成式 AI 函数限制。
限制
BigQuery BI Engine 无法加速包含 VECTOR_SEARCH 或 AI.SEARCH 函数的查询。
后续步骤
- 详细了解如何创建矢量索引。
- 了解如何使用
VECTOR_SEARCH函数执行向量搜索。 - 了解如何使用
AI.SEARCH函数执行语义搜索。 - 详细了解自主生成嵌入内容。
- 完成使用向量搜索来搜索嵌入教程,了解如何创建向量索引,然后分别使用和不使用索引来执行嵌入的向量搜索。
完成执行语义搜索和检索增强生成教程,了解如何执行以下任务:
- 生成文本嵌入。
- 在嵌入上创建向量索引。
- 使用嵌入执行向量搜索,以搜索类似文本。
- 使用向量搜索结果执行检索增强生成 (RAG),以增强提示输入并改善结果。
请尝试在检索增强生成流水线中解析 PDF 教程,了解如何根据解析的 PDF 内容创建 RAG 流水线。
您还可以使用 Python 中的 BigQuery DataFrames 执行向量搜索。如需查看演示此方法的笔记本,请参阅使用 BigQuery DataFrames 构建向量搜索应用。