
Gerir etiquetas de políticas em várias localizações
Este documento descreve como gerir etiquetas de políticas em localizações regionais para a segurança ao nível da coluna e a ocultação de dados dinâmica no BigQuery.
O BigQuery oferece controlo de acesso detalhado e ocultação dinâmica de dados para colunas de tabelas confidenciais através de etiquetas de políticas, suportando a classificação de dados baseada em tipos.
Depois de criar uma taxonomia de classificação de dados e aplicar etiquetas de políticas aos seus dados, pode gerir ainda mais as etiquetas de políticas em várias localizações.
Considerações sobre a localização
As taxonomias são recursos regionais, como tabelas e conjuntos de dados do BigQuery. Quando cria uma taxonomia, especifica a região ou a localização da taxonomia.
Pode criar uma taxonomia e aplicar etiquetas de políticas a tabelas em todas as regiões onde o BigQuery está disponível. No entanto, para aplicar etiquetas de políticas de uma taxonomia a uma coluna de tabela, a taxonomia e a tabela têm de existir na mesma localização regional.
Embora não possa aplicar uma etiqueta de política a uma coluna de tabela que exista numa localização diferente, pode copiar a taxonomia para outra localização replicando-a explicitamente nessa localização.
Usar taxonomias em várias localizações
Pode copiar (ou replicar) explicitamente uma taxonomia e as respetivas definições de etiquetas de políticas para localizações adicionais sem ter de criar manualmente uma nova taxonomia em cada localização. Quando replica taxonomias, pode usar as mesmas etiquetas de políticas para a segurança ao nível da coluna em várias localizações, simplificando a respetiva gestão.
Quando as replica, a taxonomia e as etiquetas de políticas mantêm os mesmos IDs em cada localização.
A taxonomia e as etiquetas de políticas podem ser sincronizadas novamente para as manter unificadas em várias localizações. A replicação explícita de uma taxonomia é realizada através de uma chamada à API Data Catalog. As sincronizações futuras da taxonomia replicada usam o mesmo comando da API, que substitui a taxonomia anterior.
Para facilitar a sincronização da taxonomia, pode usar o Cloud Scheduler para fazer periodicamente uma sincronização da taxonomia em todas as regiões, de acordo com uma programação definida ou com um clique num botão manual. Para usar o Cloud Scheduler, tem de configurar uma conta de serviço.
Replicar uma taxonomia numa nova localização
Autorizações necessárias
As credenciais de utilizador ou a conta de serviço que replicam a taxonomia têm de ter a função de administrador de etiquetas de políticas do Data Catalog.
Leia mais sobre a concessão da função de administrador de etiquetas de políticas em Restringir o acesso com a segurança ao nível da coluna do BigQuery.
Para mais informações sobre as funções e as autorizações do IAM no BigQuery, consulte o artigo Funções e autorizações predefinidas.
Para replicar uma taxonomia em várias localizações:
API
Chame o método
projects.locations.taxonomies.import
da API Data Catalog, fornecendo um pedido POST e
o nome do projeto e da localização de destino na string HTTP.
POST https://datacatalog.googleapis.com/{parent}/taxonomies:import
O parâmetro de caminho parent é o projeto e a localização de destino
para os quais quer copiar a taxonomia. Exemplo:
projects/MyProject/locations/eu
Sincronizar uma taxonomia replicada
Para sincronizar uma taxonomia que já foi replicada em várias localizações, repita a chamada da API Data Catalog, conforme descrito em Replicar uma taxonomia numa nova localização.
Em alternativa, pode usar uma conta de serviço e o Cloud Scheduler para sincronizar a taxonomia de acordo com uma programação especificada. A configuração de uma conta de serviço no Cloud Scheduler também lhe permite acionar uma sincronização a pedido (não agendada) através da página do Cloud Scheduler na Google Cloud consola ou com a CLI do Google Cloud.
Sincronizar uma taxonomia replicada com o Cloud Scheduler
Para sincronizar uma taxonomia replicada em várias localizações com o Cloud Scheduler, precisa de uma conta de serviço.
Contas de serviço
Pode conceder autorizações para a sincronização da replicação a uma conta de serviço existente ou criar uma nova conta de serviço.
Para criar uma nova conta de serviço, consulte o artigo Criar contas de serviço.
Autorizações necessárias
A conta de serviço que está a sincronizar a taxonomia tem de ter a função de administrador de etiquetas de políticas do Data Catalog. Para mais informações, consulte o artigo Conceda a função de administrador de etiquetas de políticas.
Configurar uma sincronização de taxonomia com o Cloud Scheduler
Para sincronizar uma taxonomia replicada em várias localizações com o Cloud Scheduler:
Consola
Primeiro, crie a tarefa de sincronização e a respetiva programação.
Siga as instruções para criar uma tarefa no Cloud Scheduler.
Para Target, consulte as instruções em Criar uma tarefa do Scheduler com autenticação.
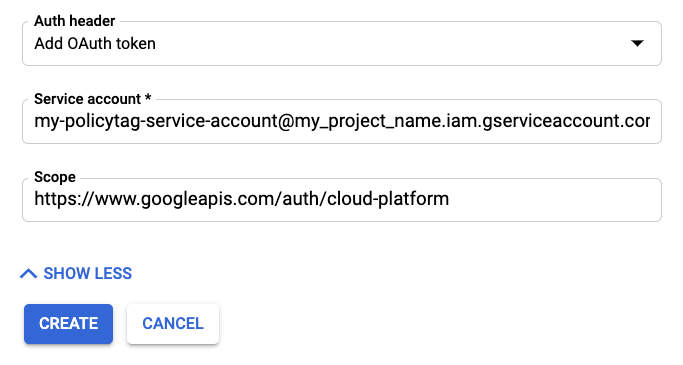
Em seguida, adicione a autenticação necessária para a sincronização agendada.
Clique em MOSTRAR MAIS para apresentar os campos de autenticação.
Para Cabeçalho de autorização, selecione "Adicionar token OAuth".
Adicione as informações da sua conta de serviço.
Para o Âmbito, introduza "https://www.googleapis.com/auth/cloud-platform".
Clique em Criar para guardar a sincronização agendada.
Agora, teste se a tarefa está configurada corretamente.
Depois de criar a tarefa, clique em Executar agora para testar se a tarefa está configurada corretamente. Posteriormente, o Cloud Scheduler aciona o pedido HTTP com base na programação que especificou.
gcloud
Sintaxe:
gcloud scheduler jobs create http "JOB_ID" --schedule="FREQUENCY" --uri="URI" --oath-service-account-email="CLIENT_SERVICE_ACCOUNT_EMAIL" --time-zone="TIME_ZONE" --message-body-from-file="MESSAGE_BODY"
Substitua o seguinte:
${JOB_ID}é um nome para a tarefa. Tem de ser exclusivo no projeto. Tenha em atenção que não pode reutilizar o nome de uma tarefa num projeto, mesmo que elimine a tarefa associada.${FREQUENCY}é o agendamento, também denominado intervalo da tarefa, da frequência com que a tarefa deve ser executada. Por exemplo, "a cada 3 horas". A string que fornece aqui pode ser qualquer string compatível com crontab. Em alternativa, os programadores familiarizados com o cron do App Engine antigo podem usar a sintaxe do cron do App Engine.${URI}é o URL totalmente qualificado do ponto final.--oauth-service-account-emaildefine o tipo de token. Tenha em atenção que as APIs Google alojadas em*.googleapis.comesperam um símbolo OAuth.${CLIENT_SERVICE_ACCOUNT_EMAIL}é o email da conta de serviço do cliente.${MESSAGE_BODY}é o caminho para o ficheiro que contém o corpo do pedido POST.
Estão disponíveis outros parâmetros de opções, que são descritos na referência da CLI gcloud do Google Cloud.
Exemplo:
gcloud scheduler jobs create http cross_regional_copy_to_eu_scheduler --schedule="0 0 1 * *" --uri="https://datacatalog.googleapis.com/v1/projects/my-project/locations/eu/taxonomies:import" --oauth-service-account-email="policytag-manager-service-acou@my-project.iam.gserviceaccount.com" --time-zone="America/Los_Angeles" --message-body-from-file=request_body.json
O que se segue?
- Para uma vista geral da segurança ao nível da coluna com etiquetas de políticas, consulte o artigo Introdução à segurança ao nível da coluna do BigQuery.
- Para mais informações sobre a criação e a aplicação de etiquetas de políticas, consulte o artigo Restringir o acesso com a segurança ao nível da coluna do BigQuery.
- Para saber mais sobre o impacto nas gravações quando usa a segurança ao nível da coluna do BigQuery, consulte o artigo Impacto nas gravações com a segurança ao nível da coluna do BigQuery.
- Para informações sobre as práticas recomendadas para usar etiquetas de políticas, consulte o artigo Usar etiquetas de políticas no BigQuery.