
このチュートリアルでは、TensorFlow モデルを BigQuery ML データセットにインポートします。次に、SQL クエリを使用して、インポートしたモデルから予測を行います。
目標
CREATE MODELステートメントを使用して、TensorFlow モデルを BigQuery ML にインポートします。ML.PREDICT関数を使用して、インポートした TensorFlow モデルで予測を行います。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
BigQuery API が有効になっていることを確認します。
- このドキュメントのタスクを実行するために必要な権限が付与されていることを確認します。
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
[IAM] に移動 - プロジェクトを選択します。
- [ アクセスを許可] をクリックします。
-
[新しいプリンシパル] フィールドに、ユーザー ID を入力します。 これは通常、Google アカウントのメールアドレスです。
- [ロールを選択] リストでロールを選択します。
- 追加のロールを付与するには、 [別のロールを追加] をクリックして各ロールを追加します。
- [保存] をクリックします。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
「アクションを表示」> [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq lsGoogle Cloud コンソールで、[BigQuery] ページに移動します。
[新規作成] で [SQL クエリ] をクリックします。
クエリエディタで次の
CREATE MODELステートメントを入力し、[実行] をクリックします。CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
オペレーションが完了すると、
Successfully created model named imported_tf_modelのようなメッセージが表示されます。新しいモデルが [リソース] パネルに表示されます。モデルにはモデルアイコン
 がついています。
がついています。[リソース] パネルで新しいモデルを選択すると、そのモデルに関する情報がクエリエディタの下に表示されます。
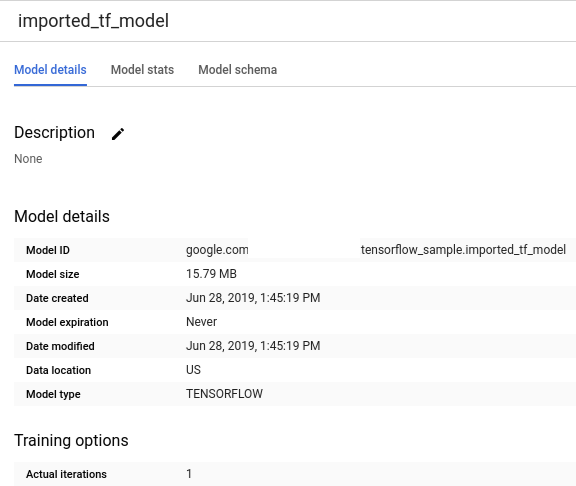
次の
CREATE MODELステートメントを入力して、TensorFlow モデルを Cloud Storage からインポートします。bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
モデルをインポートしたら、モデルがデータセットに表示されていることを確認します。
bq ls -m bqml_tutorial
出力は次のようになります。
tableId Type ------------------- ------- imported_tf_model MODEL
Google Cloud コンソールで、[BigQuery] ページに移動します。
[新規作成] で [SQL クエリ] をクリックします。
クエリエディタで、
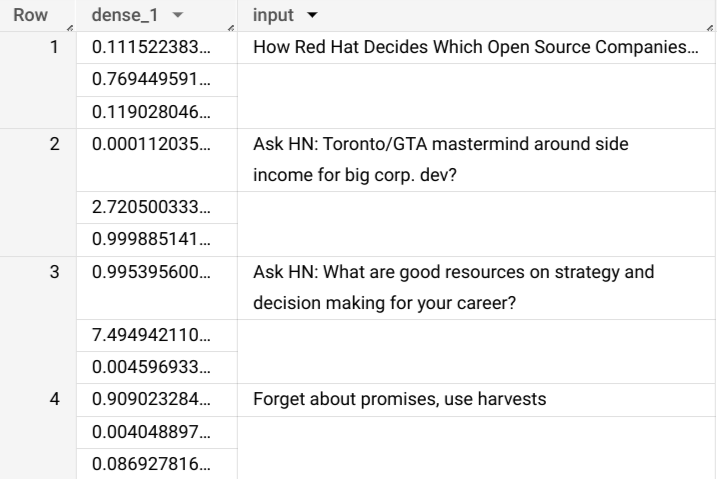
ML.PREDICT関数を使用する次のクエリを入力します。SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_tf_model`, ( SELECT title AS input FROM bigquery-public-data.hacker_news.full ) )
クエリの結果は次のようになります。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
インポートしたモデルを削除します。
省略可: データセットを削除します。
- BigQuery ML の概要で、BigQuery ML の概要を確認する。
- BigQuery ML の使用を開始するには、BigQuery ML で ML モデルを作成するをご覧ください。
- TensorFlow モデルのインポートの詳細については、TensorFlow モデルをインポートする
CREATE MODELステートメントをご覧ください。 - モデルの操作の詳細については、次のリソースをご覧ください。
- BigQuery ノートブックで BigQuery DataFrames API を使用する方法については、以下をご覧ください。
必要なロール
新しいプロジェクトを作成した場合、そのプロジェクトのオーナーとなり、このチュートリアルを完了するために必要な Identity and Access Management(IAM)権限がすべて付与されます。
既存のプロジェクトを使用している場合、BigQuery Studio 管理者(roles/bigquery.studioAdmin)ロールには、このチュートリアルの完了に必要なすべての権限が付与されています。
Make sure that you have the following role or roles on the project:
BigQuery Studio Admin (roles/bigquery.studioAdmin).
Check for the roles
Grant the roles
BigQuery の IAM 権限の詳細については、BigQuery の権限をご覧ください。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
TensorFlow モデルをインポートする
次の手順は、Cloud Storage からモデルをインポートする方法を示しています。モデルのパスは gs://cloud-training-demos/txtclass/export/exporter/1549825580/* です。インポートされたモデル名は imported_tf_model です。
Cloud Storage URI はワイルドカード文字(*)で終わることに注意してください。この文字は、BigQuery ML がモデルに関連付けられているアセットをインポートすることを示します。
インポートしたモデルは、特定の記事タイトルをどのウェブサイトが公開したかを予測する TensorFlow テキスト分類モデルです。
TensorFlow モデルをデータセットにインポートする手順は次のとおりです。
コンソール
bq
API
新しいジョブを挿入し、リクエスト本文に jobs#configuration.query プロパティを入力します。
{ "query": "CREATE MODEL `PROJECT_ID:bqml_tutorial.imported_tf_model` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')" }
PROJECT_ID は、プロジェクトとデータセットの名前に置き換えます。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
TensorFlowModel オブジェクトを使用してモデルをインポートします。
形式やストレージの要件など、BigQuery ML への TensorFlow モデルのインポートの詳細は、TensorFlow モデルをインポートするための CREATE MODEL ステートメントをご覧ください。
インポートした TensorFlow モデルを使用して予測を行う
TensorFlow モデルをインポートしたら、ML.PREDICT 関数を使用してモデルで予測を行います。
次のクエリでは、imported_tf_model を使用して、一般公開データセット hacker_news の full テーブルの入力データから予測を行います。このクエリでは、TensorFlow モデルの serving_input_fn 関数は、モデルが input という単一の入力文字列を想定することを指定しています。サブクエリは、サブクエリの SELECT ステートメントの title 列にエイリアス input を割り当てます。
インポートした TensorFlow モデルで予測を行う手順は次のとおりです。
コンソール
bq
次のコマンドを入力して、ML.PREDICT を使用するクエリを実行します。
bq query \ --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `bqml_tutorial.imported_tf_model`, (SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
結果は次のようになります。
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | dense_1 | input | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... | | ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? | | ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? | | ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
新しいジョブを挿入し、リクエスト本文に jobs#configuration.query プロパティを入力します。project_id は、プロジェクト名で置き換えます。
{ "query": "SELECT * FROM ML.PREDICT(MODEL `project_id.bqml_tutorial.imported_tf_model`, (SELECT * FROM input_data))" }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC を設定するをご覧ください。
predict 関数を使用して、TensorFlow モデルを実行します。
結果は次のようになります。
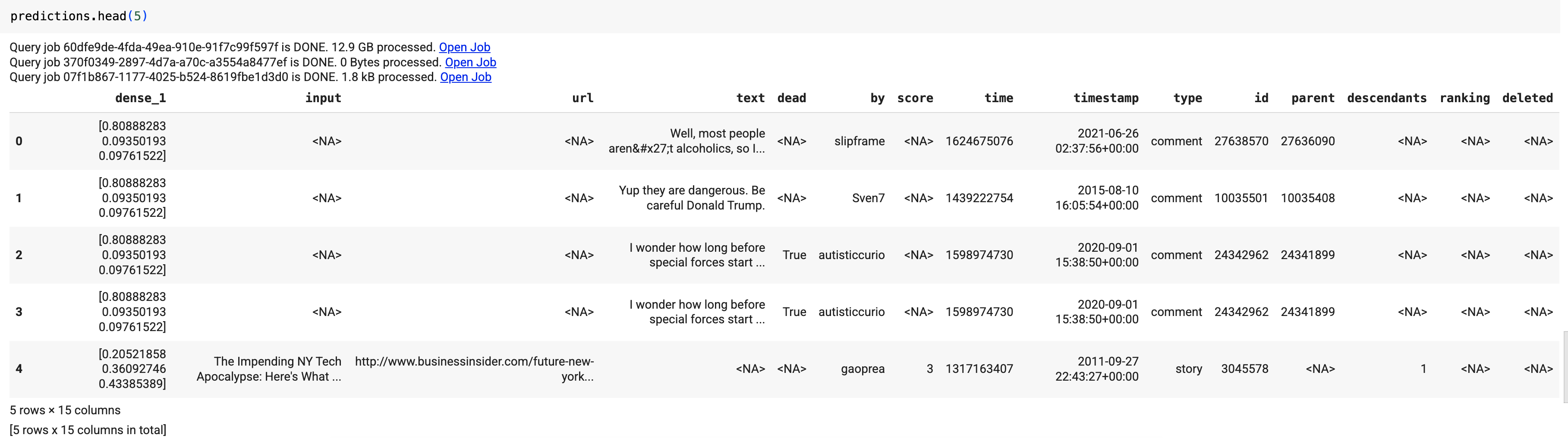
クエリ結果には dense_1 列には確率値の配列が含まれ、input 列には入力テーブルの対応する文字列値が含まれます。各配列要素の値は、対応する入力文字列が特定の公開物の記事タイトルである確率を表します。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトの削除
コンソール
gcloud
リソースを個別に削除する
または、このチュートリアルで使用した個々のリソースを削除します。