
In dieser Anleitung importieren Sie TensorFlow-Modelle in ein BigQuery ML-Dataset. Anschließend verwenden Sie eine SQL-Abfrage, um Vorhersagen aus den importierten Modellen zu treffen.
Ziele
- Verwenden Sie die
CREATE MODEL-Anweisung, um TensorFlow-Modelle in BigQuery ML zu importieren. - Verwenden Sie die Funktion
ML.PREDICT, um Vorhersagen mit den importierten TensorFlow-Modellen zu treffen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Prüfen Sie, ob für Ihr Google Cloud Projekt die Abrechnung aktiviert ist.
Die BigQuery API muss aktiviert sein.
- Prüfen Sie, ob Sie die erforderlichen Berechtigungen haben, um die Aufgaben in diesem Dokument ausführen zu können.
Erforderliche Rollen
Wenn Sie ein neues Projekt erstellen, sind Sie der Projektinhaber und erhalten alle erforderlichen IAM-Berechtigungen (Identity and Access Management), die Sie für dieses Tutorial benötigen.
Wenn Sie ein vorhandenes Projekt verwenden, gewährt die Rolle BigQuery Studio Admin (roles/bigquery.studioAdmin) alle Berechtigungen, die zum Durcharbeiten dieses Tutorials erforderlich sind.
Sie benötigen die folgende Rolle oder die folgenden Rollen für das Projekt:
BigQuery Studio Admin (roles/bigquery.studioAdmin).
Rollen prüfen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
-
Suchen Sie in der Spalte Hauptkonto nach allen Zeilen, in denen Sie oder eine Gruppe, zu der Sie gehören, angegeben sind. Fragen Sie Ihren Administrator, zu welchen Gruppen Sie gehören.
- Prüfen Sie in allen Zeilen, in denen Sie angegeben oder enthalten sind, die Spalte Rolle, um zu sehen, ob die Liste der Rollen die erforderlichen Rollen enthält.
Rollen zuweisen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Klicken Sie auf Rolle auswählen und suchen Sie nach der Rolle.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
Weitere Informationen zu IAM-Berechtigungen in BigQuery finden Sie unter BigQuery-Berechtigungen.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Multiregional und dann USA aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk --dataset.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorialund legen Sie den Datenspeicherort aufUSfest.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
TensorFlow-Modell importieren
In den folgenden Schritten wird beschrieben, wie Sie ein Modell aus Cloud Storage importieren.
Der Pfad zum Modell ist gs://cloud-training-demos/txtclass/export/exporter/1549825580/*. Der Name des importierten Modells ist imported_tf_model.
Der Cloud Storage-URI endet mit einem Platzhalterzeichen (*). Dieses Zeichen gibt an, dass BigQuery ML alle mit dem Modell verknüpften Assets importieren soll.
Das importierte Modell ist ein TensorFlow-Textklassifizierungsmodell, das vorhersagt, auf welcher Website ein bestimmter Artikeltitel veröffentlicht wurde.
So importieren Sie das TensorFlow-Modell in Ihr Dataset:
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie unter Neu erstellen auf SQL-Abfrage.
Geben Sie im Abfrageeditor diese
CREATE MODEL-Anweisung ein und klicken Sie dann auf Ausführen.CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
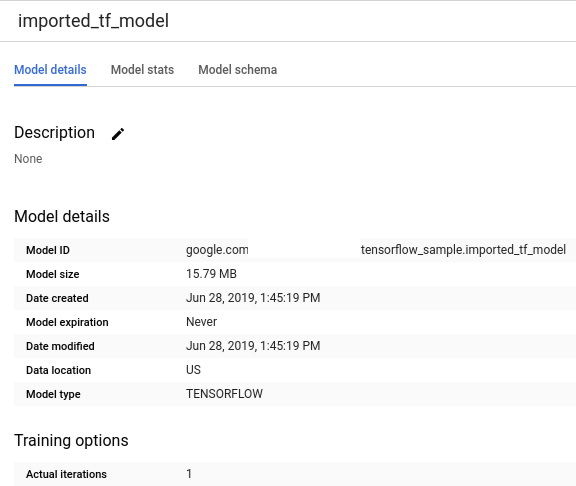
Wenn der Vorgang abgeschlossen ist, sollte eine Meldung wie
Successfully created model named imported_tf_modelangezeigt werden.Ihr neues Modell wird im Bereich Ressourcen angezeigt. Modelle sind am Modellsymbol
 zu erkennen.
zu erkennen.Wenn Sie das neue Modell im Feld Ressourcen auswählen, werden Informationen zum Modell unter dem Abfrageeditor angezeigt.
bq
Importieren Sie das TensorFlow-Modell aus Cloud Storage, indem Sie die folgende
CREATE MODEL-Anweisung eingeben.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
Prüfen Sie nach dem Import des Modells, ob es im Dataset angezeigt wird.
bq ls -m bqml_tutorial
Die Ausgabe sieht etwa so aus:
tableId Type ------------------- ------- imported_tf_model MODEL
API
Fügen Sie einen neuen Job ein und geben Sie das Attribut jobs#configuration.query im Anfragetext an.
{ "query": "CREATE MODEL `PROJECT_ID:bqml_tutorial.imported_tf_model` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')" }
Ersetzen Sie PROJECT_ID durch den Namen Ihres Projekts und Datasets.
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Importieren Sie das Modell mit dem TensorFlowModel-Objekt.
Weitere Informationen zum Importieren von TensorFlow-Modellen in BigQuery ML, einschließlich Format- und Speicheranforderungen, finden Sie unter CREATE MODEL-Anweisung zum Importieren von TensorFlow-Modellen.
Vorhersagen mit dem importierten TensorFlow-Modell treffen
Nachdem Sie das TensorFlow-Modell importiert haben, verwenden Sie die Funktion ML.PREDICT, um Vorhersagen mit dem Modell zu treffen.
In der folgenden Abfrage wird imported_tf_model verwendet, um Vorhersagen anhand von Eingabedaten aus der Tabelle full im öffentlichen Dataset hacker_news zu treffen. In der Abfrage gibt die Funktion serving_input_fn des TensorFlow-Modells an, dass das Modell einen einzelnen Eingabestring mit dem Namen input erwartet. Mit der Unterabfrage wird der Alias input der Spalte title in der SELECT-Anweisung der Unterabfrage zugewiesen.
Führen Sie die folgenden Schritte aus, um Vorhersagen mit dem importierten TensorFlow-Modell zu treffen.
Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie unter Neu erstellen auf SQL-Abfrage.
Geben Sie im Abfrageeditor diese Abfrage mit der Funktion
ML.PREDICTein.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_tf_model`, ( SELECT title AS input FROM bigquery-public-data.hacker_news.full ) )
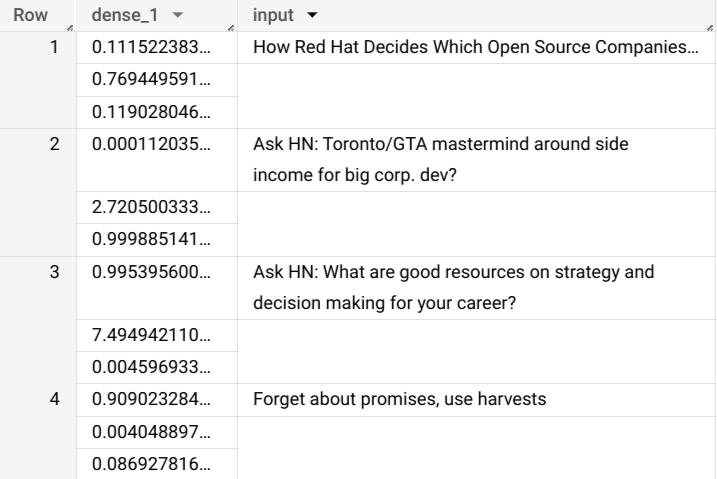
Die Abfrageergebnisse sollten so aussehen:
bq
Geben Sie den folgenden Befehl ein, um die Abfrage mit ML.PREDICT auszuführen.
bq query \ --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `bqml_tutorial.imported_tf_model`, (SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
Die Ergebnisse sollten so aussehen:
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | dense_1 | input | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... | | ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? | | ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? | | ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
Fügen Sie einen neuen Job ein und geben Sie das Attribut jobs#configuration.query wie im Anfragetext an. Ersetzen Sie project_id durch den Namen Ihres Projekts.
{ "query": "SELECT * FROM ML.PREDICT(MODEL `project_id.bqml_tutorial.imported_tf_model`, (SELECT * FROM input_data))" }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Verwenden Sie die Funktion predict, um das TensorFlow-Modell auszuführen:
Die Ergebnisse sollten so aussehen:
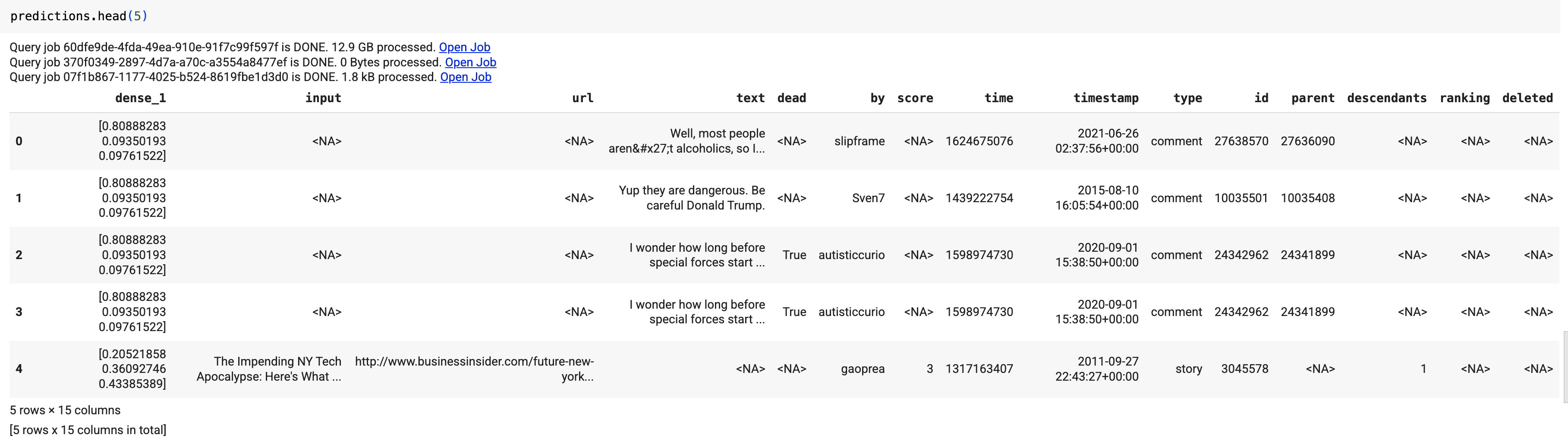
In den Abfrageergebnissen enthält die Spalte dense_1 ein Array von Wahrscheinlichkeitswerten und die Spalte input die entsprechenden Stringwerte aus der Eingabetabelle. Jeder Elementwert des Arrays stellt die Wahrscheinlichkeit dar, dass der entsprechende Eingabestring ein Artikeltitel aus einer bestimmten Publikation ist.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
Console
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
gcloud
Google Cloud -Projekt löschen:
gcloud projects delete PROJECT_ID
Einzelne Ressourcen löschen
Alternativ können Sie die einzelnen Ressourcen entfernen, die in dieser Anleitung verwendet werden:
Optional: Dataset löschen
Nächste Schritte
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in BigQuery ML.
- Informationen zur Verwendung von BigQuery ML finden Sie unter Modelle für maschinelles Lernen in BigQuery ML erstellen.
- Weitere Informationen zum Importieren von TensorFlow-Modellen finden Sie unter
CREATE MODEL-Anweisung zum Importieren von TensorFlow-Modellen. - Weitere Informationen zum Arbeiten mit Modellen finden Sie in folgenden Ressourcen:
- Weitere Informationen zur Verwendung der BigQuery DataFrames API in einem BigQuery-Notebook finden Sie unter: