
このチュートリアルでは、BigQuery ML の線形回帰モデルを使用し、ペンギンの属性情報に基づいてペンギンの体重を予測します。線形回帰は、入力する特徴量の線型結合から連続値を生成する回帰モデルです。
このチュートリアルでは、bigquery-public-data.ml_datasets.penguins データセットを使用します。
目標
このチュートリアルでは、次のタスクを行います。
- 線形回帰モデルを作成する。
- モデルを評価する。
- モデルを使用して予測を行う。
費用
このチュートリアルでは、 Google Cloudの課金対象となる以下のコンポーネントを使用しています。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
必要な権限
BigQuery ML を使用してモデルを作成するには、次の IAM 権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
推論を実行するには、次の権限が必要です。
- モデルに対する
bigquery.models.getData bigquery.jobs.create
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
モデルを作成する
BigQuery 用のアナリティクス サンプル データセットを使用して、線形回帰モデルを作成します。
SQL
線形回帰モデルを作成するには、CREATE MODEL ステートメントを使用し、モデルタイプに LINEAR_REG を指定します。モデルの作成にはモデルのトレーニングも含まれます。
CREATE MODEL ステートメントについては、次の点に注意してください。
input_label_colsオプションは、SELECTステートメントでラベル列として使用する列を指定します。ここで、ラベル列はbody_mass_gです。線形回帰モデルの場合、ラベル列は実数にする必要があります。つまり、列の値は実数でなければなりません。このクエリの
SELECTステートメントでは、bigquery-public-data.ml_datasets.penguinsテーブルの次の列を使用して、ペンギンの体重を予測します。species: ペンギンの種類。island: ペンギンが生息する島。culmen_length_mm: ペンギンのくちばしの長さ(ミリメートル)。culmen_depth_mm: ペンギンのくちばしの高さ(ミリメートル)。flipper_length_mm: ペンギンの翼の長さ(ミリメートル)。sex: ペンギンの性別。
このクエリの
SELECTステートメントのWHERE句(WHERE body_mass_g IS NOT NULL)は、body_mass_g列がNULLである行を除外します。
線形回帰モデルを作成するクエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
penguins_modelモデルの作成には約 30 秒かかります。モデルを表示する手順は次のとおりです。
左側のペインで、 [エクスプローラ] をクリックします。

左側のペインが表示されていない場合は、 [左ペインを開く] をクリックしてペインを開きます。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックします。
bqml_tutorialデータセットをクリックします。[モデル] タブをクリックします。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
モデルの作成には約 30 秒かかります。モデルを表示する手順は次のとおりです。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックします。
bqml_tutorialデータセットをクリックします。[モデル] タブをクリックします。
トレーニングの統計情報を取得する
モデルのトレーニング結果を確認するには、ML.TRAINING_INFO 関数を使用するか、 Google Cloud コンソールで統計情報を表示します。このチュートリアルでは Google Cloud コンソールを使用します。
ML アルゴリズムは、多くのサンプルを検査し、損失を最小限に抑えるモデルを見つけることでモデルを構築します。このプロセスを経験損失最小化と呼びます。
損失は、精度の低い予測に対するペナルティです。これは、1 つのサンプルでモデルが行った予測の精度がどのくらい低いかで表します。モデルの予測が完璧であれば、損失はゼロになります。それ以外の場合、精度に応じて損失が大きくなります。モデルをトレーニングする目的は、すべてのサンプルで平均的に損失の少ない重みとバイアスの組み合わせを見つけることです。
CREATE MODEL クエリで生成したモデルのトレーニング統計を確認します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックします。
bqml_tutorialデータセットをクリックします。[モデル] タブをクリックします。
モデル情報ペインを開くには、[penguins_model] をクリックします。
[トレーニング] タブをクリックしてから、[テーブル] をクリックします。結果は次のようになります。
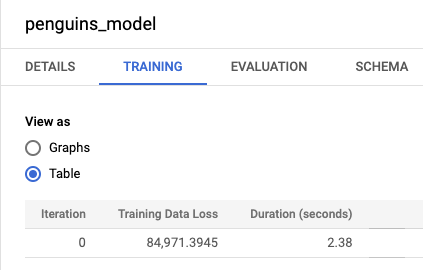
[トレーニング データの損失] 列は、トレーニング データセットでモデルのトレーニングを行った後に計算された損失指標を表します。線形回帰を行ったので、この列には平均二乗誤差の値が表示されます。このトレーニングでは normal_equation の最適化戦略が自動的に使用されるため、最終モデルに変換するために必要な反復処理は 1 回だけです。モデルの最適化戦略の設定の詳細については、
optimize_strategyをご覧ください。
モデルを評価する
モデルを作成したら、ML.EVALUATE 関数または score BigQuery DataFrames 関数を使用して、モデルによって生成された予測値と実際のデータを比較して、モデルの性能を評価します。
SQL
入力では、ML.EVALUATE 関数はトレーニング済みモデルと、モデルのトレーニングに使用したデータのスキーマに一致するデータセットを取得します。本番環境では、モデルのトレーニングに使用したデータとは異なるデータでモデルを評価する必要があります。入力データを提供せずに ML.EVALUATE を実行すると、関数はトレーニング中に計算された評価指標を取得します。これらの指標は、自動的に予約された評価データセットを使用して計算されます。
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
ML.EVALUATE クエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
結果は次のようになります。
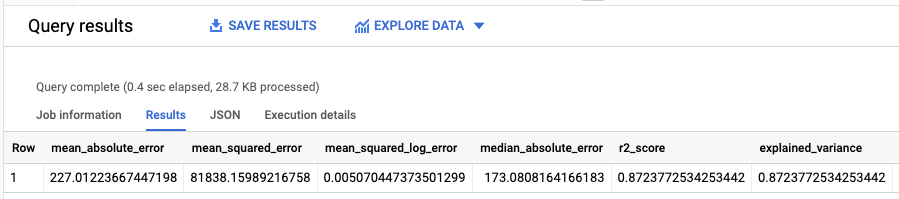
線形回帰を使用しているため、結果には次の列が含まれます。
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
評価結果における重要な測定指標は、R2 スコアです。R2 スコアは、線形回帰予測が実際のデータに近似するかどうかを決定する統計的尺度です。0 の値は、平均値周辺のレスポンス データにばらつきがないことを示しています。1 の値は、平均値周辺のレスポンス データにばらつきがあることを示しています。
Google Cloud コンソールのモデル情報ペインで、評価指標を確認することもできます。

モデルを使用して結果を予測する
モデルの評価を行ったので、モデルを使用して結果を予測します。モデルに ML.PREDICT 関数または predict BigQuery DataFrames 関数を実行すると、ビスコー諸島に生息するすべてのペンギンの体重をグラム単位で予測できます。
SQL
入力では、ML.PREDICT 関数はラベル列を除き、トレーニング済みモデルと、モデルのトレーニングに使用したデータのスキーマに一致するデータセットを取得します。
ML.PREDICT クエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
結果は次のようになります。

予測結果について説明する
SQL
モデルがこれらの予測結果を生成する理由を理解するには、ML.EXPLAIN_PREDICT 関数を使用します。
ML.EXPLAIN_PREDICT は、ML.PREDICT 関数の拡張バージョンです。ML.EXPLAIN_PREDICT は、予測結果だけでなく、予測結果の説明に使用する追加の列も出力します。実際には、ML.PREDICT の代わりに ML.EXPLAIN_PREDICT を実行できます。詳細については、BigQuery ML Explainable AI の概要をご覧ください。
ML.EXPLAIN_PREDICT クエリを実行します。
- Google Cloud コンソールで、[BigQuery] ページに移動します。
- [クエリエディタ] ペインで、次のクエリを実行します。
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
結果は次のようになります。
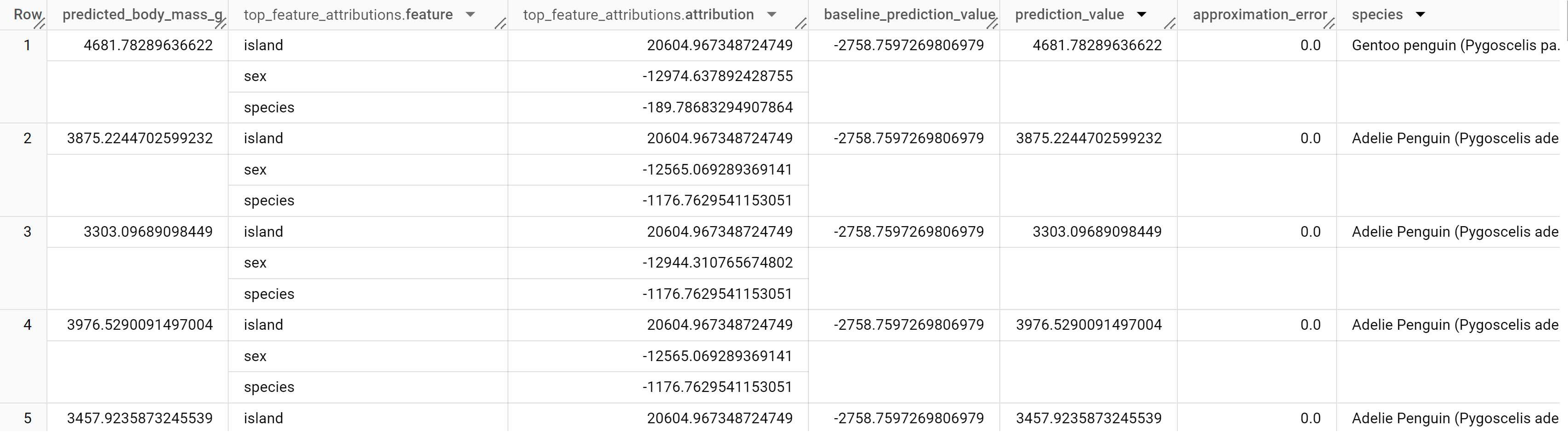
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
線形回帰モデルでは、Shapley 値を使用して、モデル内の各特徴の特徴アトリビューション値を生成します。top_k_features が 3 に設定されているため、出力には penguins テーブルの行ごとに上位 3 つの特徴アトリビューションが含まれます。これらのアトリビューションは、アトリビューションの絶対値の降順で並べ替えられます。すべての例で、特徴量 sex が予測全体に最も貢献しています。
モデルをグローバルに説明する
SQL
一般的にペンギンの体重を決定するうえで最も重要な特徴を特定するには、ML.GLOBAL_EXPLAIN 関数を使用します。ML.GLOBAL_EXPLAIN を使用するには、ENABLE_GLOBAL_EXPLAIN オプションを TRUE に設定してモデルを再トレーニングする必要があります。
モデルを再トレーニングしてグローバルな説明を取得します。
- Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで、次のクエリを実行してモデルを再トレーニングします。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
クエリエディタで次のクエリを実行して、グローバルな説明を取得します。
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
結果は次のようになります。
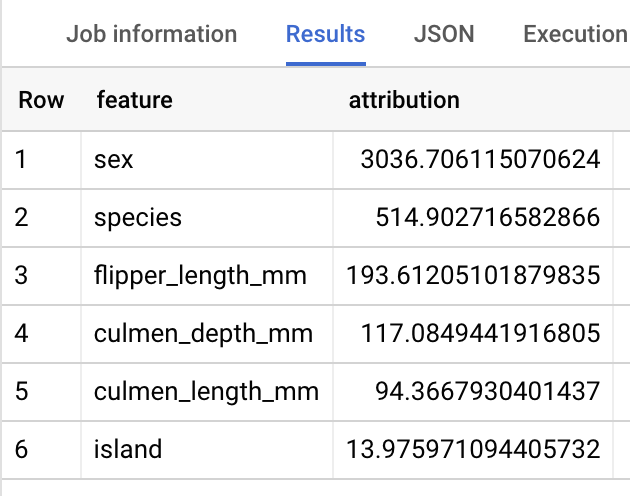
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセット、テーブル、すべてのデータが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力して、[削除] をクリックします。
プロジェクトを削除する
プロジェクトを削除するには、次の操作を行います。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- BigQuery ML の概要で BigQuery ML の概要を確認する。
CREATE MODEL構文ページでモデルの作成方法を確認する。