
Use o plug-in JupyterLab do BigQuery
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bigquery-ide-plugin@google.com.
Este documento mostra como instalar e usar o plug-in do BigQuery JupyterLab para fazer o seguinte:
- Explore os seus dados do BigQuery.
- Use a API BigQuery DataFrames.
- Implemente um bloco de notas do BigQuery DataFrames no Cloud Composer.
O plug-in JupyterLab do BigQuery inclui toda a funcionalidade do plug-in Dataproc JupyterLab, como a criação de um modelo de tempo de execução sem servidor do Dataproc, o lançamento e a gestão de blocos de notas, o desenvolvimento com o Apache Spark, a implementação do seu código e a gestão dos seus recursos.
Instale o plugin do BigQuery JupyterLab
Para instalar e usar o plug-in do BigQuery JupyterLab, siga estes passos:
No seu terminal local, verifique se tem o Python 3.8 ou posterior instalado no seu sistema:
python3 --versionNo seu terminal local, inicialize a CLI gcloud:
gcloud initInstale o Pipenv, uma ferramenta de ambiente virtual Python:
pip3 install pipenvCrie um novo ambiente virtual:
pipenv shellInstale o JupyterLab no novo ambiente virtual:
pipenv install jupyterlabInstale o plug-in do BigQuery JupyterLab:
pipenv install bigquery-jupyter-pluginSe a versão instalada do JupyterLab for anterior à 4.0.0, ative a extensão do plugin:
jupyter server extension enable bigquery_jupyter_pluginInicie o JupyterLab:
jupyter labO JupyterLab é aberto no navegador.
Atualize as definições do projeto e da região
Por predefinição, a sua sessão é executada no projeto e na região que definiu quando
executou gcloud init. Para alterar as definições do projeto e da região da sua sessão, faça o seguinte:
- No menu do JupyterLab, clique em Definições > Definições do Google BigQuery.
Tem de reiniciar o plug-in para que as alterações entrem em vigor.
Explorar dados
Para trabalhar com os seus dados do BigQuery no JupyterLab, faça o seguinte:
- Na barra lateral do JupyterLab, abra o painel Explorador de conjuntos de dados: clique no ícone de conjuntos de dados
 .
. Para expandir um projeto, no painel Explorador de conjuntos de dados, clique na seta de expansão junto ao nome do projeto.
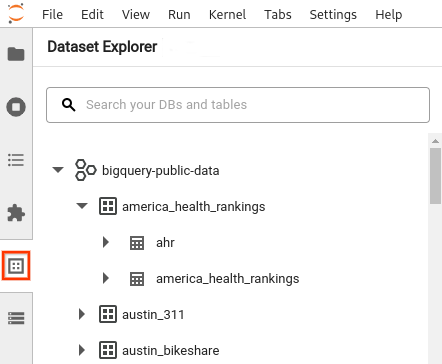
O painel Explorador de conjuntos de dados mostra todos os conjuntos de dados num projeto que estão localizados na região do BigQuery que configurou para a sessão. Pode interagir com um projeto e um conjunto de dados de várias formas:
- Para ver informações sobre um conjunto de dados, clique no nome do conjunto de dados.
- Para apresentar todas as tabelas num conjunto de dados, clique na seta de expansão junto ao conjunto de dados.
- Para ver informações sobre uma tabela, clique no nome da tabela.
- Para alterar o projeto ou a região do BigQuery, atualize as suas definições.
Execute notebooks
Para consultar os seus dados do BigQuery a partir do JupyterLab, faça o seguinte:
- Para abrir a página do Launcher, clique em Ficheiro > Novo Launcher.
- Na secção BigQuery Notebooks, clique no cartão BigQuery DataFrames. É aberto um novo bloco de notas que mostra como começar a usar os DataFrames do BigQuery.
Os blocos de notas do BigQuery DataFrames suportam o desenvolvimento em Python num kernel Python local. As operações de DataFrames do BigQuery são executadas remotamente no BigQuery, mas o resto do código é executado localmente no seu computador. Quando uma operação é executada no BigQuery, é apresentado um ID da tarefa de consulta e um link para a tarefa abaixo da célula de código.
- Para ver a tarefa na Google Cloud consola, clique em Abrir tarefa.
Implemente um bloco de notas do BigQuery DataFrames
Pode implementar um bloco de notas do BigQuery DataFrames no Cloud Composer usando um modelo de tempo de execução sem servidor do Dataproc. Tem de usar a versão 2.1 ou posterior do tempo de execução.
- No bloco de notas do JupyterLab, clique em calendar_monthAgendador de tarefas.
- Em Nome da tarefa, introduza um nome exclusivo para a tarefa.
- Para Ambiente, introduza o nome do ambiente do Cloud Composer no qual quer implementar a tarefa.
- Se o seu bloco de notas for parametrizado, adicione parâmetros.
- Introduza o nome do modelo de tempo de execução sem servidor.
- Para processar falhas de execução do bloco de notas, introduza um número inteiro para Contagem de repetições e um valor (em minutos) para Atraso na repetição.
Selecione as notificações de execução a enviar e, de seguida, introduza os destinatários.
As notificações são enviadas através da configuração SMTP do Airflow.
Selecione um agendamento para o bloco de notas.
Clique em Criar.
Quando agenda com êxito o seu bloco de notas, este é apresentado na lista de tarefas agendadas no ambiente do Cloud Composer selecionado.
O que se segue?
- Experimente o início rápido dos DataFrames do BigQuery.
- Saiba mais acerca da API Python BigQuery DataFrames.
- Use o JupyterLab para sessões de blocos de notas e em lote sem servidor com o Dataproc.