
Neste tutorial, vai visualizar dados de estatísticas geoespaciais do BigQuery através de um bloco de notas do Colab.
Este tutorial usa os seguintes conjuntos de dados públicos do BigQuery:
- San Francisco Ford GoBike Share
- Bairros de São Francisco
- Relatórios do Departamento de Polícia de São Francisco (SFPD)
Para obter informações sobre como aceder a estes conjuntos de dados públicos, consulte o artigo Aceda a conjuntos de dados públicos na Google Cloud consola.
Usa os conjuntos de dados públicos para criar as seguintes visualizações:
- Um gráfico de dispersão de todas as estações de partilha de bicicletas do conjunto de dados Ford GoBike Share
- Polígonos no conjunto de dados de bairros de São Francisco
- Um mapa coroplético do número de estações de partilha de bicicletas por bairro
- Um mapa de calor de incidentes do conjunto de dados San Francisco Police Department Reports
Objetivos
- Configure a autenticação com o Google Cloud e, opcionalmente, o Google Maps.
- Consultar dados no BigQuery e transferir os resultados para o Colab.
- Use ferramentas de ciência de dados Python para fazer transformações e análises.
- Crie visualizações, incluindo gráficos de dispersão, polígonos, mapas coropléticos e mapas de calor.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização prevista,
use a calculadora de preços.
Quando terminar as tarefas descritas neste documento, pode evitar a faturação contínua eliminando os recursos que criou. Para mais informações, consulte o artigo Limpe.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Certifique-se de que tem as autorizações necessárias para realizar as tarefas descritas neste documento.
- BigQuery User (
roles/bigquery.user) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Aceder ao IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos responsáveis, introduza o identificador do utilizador. Normalmente, este é o endereço de email de uma Conta Google.
- Clique em Selecionar uma função e, de seguida, pesquise a função.
- Para conceder funções adicionais, clique em Adicionar outra função e adicione cada função adicional.
- Clique em Guardar.
Abra o Colab.
Na caixa de diálogo Abrir bloco de notas, clique em Novo bloco de notas.
Clique em
Untitled0.ipynbe altere o nome do bloco de notas parabigquery-geo.ipynb.Selecione Ficheiro > Guardar.
Para inserir uma célula de código, clique em Código.
Para se autenticar com o seu projeto, introduza o seguinte código:
# REQUIRED: Authenticate with your project. GCP_PROJECT_ID = "PROJECT_ID" #@param {type:"string"} from google.colab import auth from google.colab import userdata auth.authenticate_user(project_id=GCP_PROJECT_ID) # Set GMP_API_KEY to none GMP_API_KEY = None
Substitua PROJECT_ID pelo ID do seu projeto.
Clique em Executar célula.
Quando lhe for pedido, clique em Permitir para conceder ao Colab acesso às suas credenciais, se concordar.
Na página Iniciar sessão com o Google, escolha a sua conta.
Na página Inicie sessão no código do bloco de notas criado por terceiros, clique em Continuar.
Em Selecione a que o código do bloco de notas criado por terceiros pode aceder, clique em Selecionar tudo e, de seguida, em Continuar.
Depois de concluir o fluxo de autorização, não é gerada nenhuma saída no seu bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Siga as instruções na página Usar chaves de API na documentação do Google Maps para obter a sua chave da API Google Maps.
Mude para o seu bloco de notas do Colab e, de seguida, clique em Segredos.
Clique em Adicionar novo segredo.
Em Nome, introduza
GMP_API_KEY.Em Valor, introduza o valor da chave da API Google Maps que gerou anteriormente.
Feche o painel Segredos.
Para inserir uma célula de código, clique em Código.
Para se autenticar com a API Maps, introduza o seguinte código:
# Authenticate with the Google Maps JavaScript API. GMP_API_SECRET_KEY_NAME = "GMP_API_KEY" #@param {type:"string"} if GMP_API_SECRET_KEY_NAME: GMP_API_KEY = userdata.get(GMP_API_SECRET_KEY_NAME) if GMP_API_SECRET_KEY_NAME else None else: GMP_API_KEY = None
Quando lhe for pedido, clique em Conceder acesso para dar ao bloco de notas acesso à sua chave, se concordar.
Clique em Executar célula.
Depois de concluir o fluxo de autorização, não é gerada nenhuma saída no seu bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
geopandaspara estender os tipos de dados usados porpandaspara permitir operações espaciais em tipos geométricos.shapelypara a manipulação e a análise de objetos geométricos planos individuais.brancapara gerar mapas de cores HTML e JavaScript.geemap.deckpara visualização compydeckeearthengine-api.Para inserir uma célula de código, clique em Código.
Para instalar os pacotes
pydeckeh3, introduza o seguinte código:# Install pydeck and h3. !pip install pydeck>=0.9 h3>=4.2
Clique em Executar célula.
Depois de concluir a instalação, não é gerada nenhuma saída no seu bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para importar as bibliotecas Python, introduza o seguinte código:
# Import data science libraries. import branca import geemap.deck as gmdk import h3 import pydeck as pdk import geopandas as gpd import shapely
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para ativar os
pandasDataFrames, introduza o seguinte código:# Enable displaying pandas data frames as interactive tables by default. from google.colab import data_table data_table.enable_dataframe_formatter()
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para criar uma rotina partilhada para renderizar camadas num mapa, introduza o seguinte código:
# Set Google Maps as the base map provider. MAP_PROVIDER_GOOGLE = pdk.bindings.base_map_provider.BaseMapProvider.GOOGLE_MAPS.value # Shared routine for rendering layers on a map using geemap.deck. def display_pydeck_map(layers, view_state, **kwargs): deck_kwargs = kwargs.copy() # Use Google Maps as the base map only if the API key is provided. if GMP_API_KEY: deck_kwargs.update({ "map_provider": MAP_PROVIDER_GOOGLE, "map_style": pdk.bindings.map_styles.GOOGLE_ROAD, "api_keys": {MAP_PROVIDER_GOOGLE: GMP_API_KEY}, }) m = gmdk.Map(initial_view_state=view_state, ee_initialize=False, **deck_kwargs) for layer in layers: m.add_layer(layer) return m
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para consultar o conjunto de dados público da San Francisco Ford GoBike Share, introduza o seguinte código. Este código usa a função mágica
%%bigquerypara executar a consulta e devolver os resultados num DataFrame:# Query the station ID, station name, station short name, and station # geometry from the bike share dataset. # NOTE: In this tutorial, the denormalized 'lat' and 'lon' columns are # ignored. They are decomposed components of the geometry. %%bigquery gdf_sf_bikestations --project {GCP_PROJECT_ID} --use_geodataframe station_geom SELECT station_id, name, short_name, station_geom FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info`
Clique em Executar célula.
O resultado é semelhante ao seguinte:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Para inserir uma célula de código, clique em Código.
Para obter um resumo do DataFrame, incluindo colunas e tipos de dados, introduza o seguinte código:
# Get a summary of the DataFrame gdf_sf_bikestations.info()
Clique em Executar célula.
O resultado deve ter o seguinte aspeto:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 472 entries, 0 to 471 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 station_id 472 non-null object 1 name 472 non-null object 2 short_name 472 non-null object 3 station_geom 472 non-null geometry dtypes: geometry(1), object(3) memory usage: 14.9+ KBPara inserir uma célula de código, clique em Código.
Para pré-visualizar as primeiras cinco linhas do DataFrame, introduza o seguinte código:
# Preview the first five rows gdf_sf_bikestations.head()
Clique em Executar célula.
O resultado é semelhante ao seguinte:

Para inserir uma célula de código, clique em Código.
Para extrair os valores de longitude e latitude da coluna
station_geom, introduza o seguinte código:# Extract the longitude (x) and latitude (y) from station_geom. gdf_sf_bikestations["longitude"] = gdf_sf_bikestations["station_geom"].x gdf_sf_bikestations["latitude"] = gdf_sf_bikestations["station_geom"].y
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para renderizar o gráfico de dispersão das estações de partilha de bicicletas com base nos valores de longitude e latitude que extraiu anteriormente, introduza o seguinte código:
# Render a scatter plot using pydeck with the extracted longitude and # latitude columns in the gdf_sf_bikestations geopandas.GeoDataFrame. scatterplot_layer = pdk.Layer( "ScatterplotLayer", id="bike_stations_scatterplot", data=gdf_sf_bikestations, get_position=['longitude', 'latitude'], get_radius=100, get_fill_color=[255, 0, 0, 140], # Adjust color as desired pickable=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([scatterplot_layer], view_state)
Clique em Executar célula.
O resultado é semelhante ao seguinte:
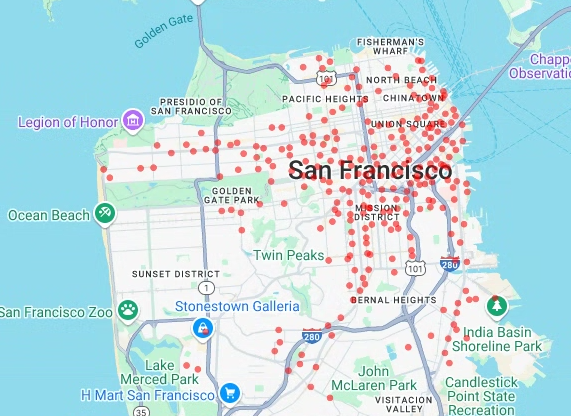
- Pontos
- Linhas
- Polígonos
- Vários polígonos
Para inserir uma célula de código, clique em Código.
Para consultar os dados geográficos da tabela
bigquery-public-data.san_francisco_neighborhoods.boundariesno conjunto de dados San Francisco Neighborhoods, introduza o seguinte código. Este código usa a função mágica%%bigquerypara executar a consulta e devolver os resultados num DataFrame:# Query the neighborhood name and geometry from the San Francisco # neighborhoods dataset. %%bigquery gdf_sanfrancisco_neighborhoods --project {GCP_PROJECT_ID} --use_geodataframe geometry SELECT neighborhood, neighborhood_geom AS geometry FROM `bigquery-public-data.san_francisco_neighborhoods.boundaries`
Clique em Executar célula.
O resultado é semelhante ao seguinte:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Para inserir uma célula de código, clique em Código.
Para obter um resumo do DataFrame, introduza o seguinte código:
# Get a summary of the DataFrame gdf_sanfrancisco_neighborhoods.info()
Clique em Executar célula.
Os resultados devem ter o seguinte aspeto:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 117 entries, 0 to 116 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 neighborhood 117 non-null object 1 geometry 117 non-null geometry dtypes: geometry(1), object(1) memory usage: 2.0+ KBPara pré-visualizar a primeira linha do DataFrame, introduza o seguinte código:
# Preview the first row gdf_sanfrancisco_neighborhoods.head(1)
Clique em Executar célula.
O resultado é semelhante ao seguinte:

Nos resultados, repare que os dados são um polígono.
Para inserir uma célula de código, clique em Código.
Para visualizar os polígonos, introduza o seguinte código.
pydecké usado para converter cada instância de objetoshapelyna coluna de geometria no formatoGeoJSON:# Visualize the polygons. geojson_layer = pdk.Layer( 'GeoJsonLayer', id="sf_neighborhoods", data=gdf_sanfrancisco_neighborhoods, get_line_color=[127, 0, 127, 255], get_fill_color=[60, 60, 60, 50], get_line_width=100, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([geojson_layer], view_state)
Clique em Executar célula.
O resultado é semelhante ao seguinte:
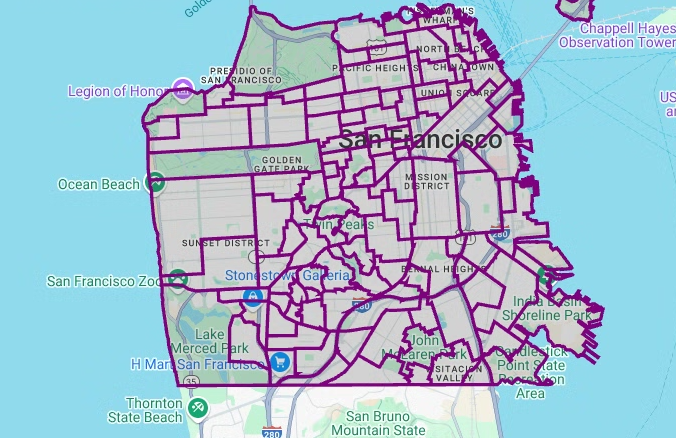
Para inserir uma célula de código, clique em Código.
Para agregar e contabilizar o número de estações por bairro e criar uma coluna
polygonque contenha uma matriz de pontos, introduza o seguinte código:# Aggregate and count the number of stations per neighborhood. gdf_count_stations = gdf_sanfrancisco_neighborhoods.sjoin(gdf_sf_bikestations, how='left', predicate='contains') gdf_count_stations = gdf_count_stations.groupby(by='neighborhood')['station_id'].count().rename('num_stations') gdf_stations_x_neighborhood = gdf_sanfrancisco_neighborhoods.join(gdf_count_stations, on='neighborhood', how='inner') # To simulate non-GeoJSON input data, create a polygon column that contains # an array of points by using the pandas.Series.map method. gdf_stations_x_neighborhood['polygon'] = gdf_stations_x_neighborhood['geometry'].map(lambda g: list(g.exterior.coords))
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para adicionar uma coluna
fill_colorpara cada um dos polígonos, introduza o seguinte código:# Create a color map gradient using the branch library, and add a fill_color # column for each of the polygons. colormap = branca.colormap.LinearColormap( colors=["lightblue", "darkred"], vmin=0, vmax=gdf_stations_x_neighborhood['num_stations'].max(), ) gdf_stations_x_neighborhood['fill_color'] = gdf_stations_x_neighborhood['num_stations'] \ .map(lambda c: list(colormap.rgba_bytes_tuple(c)[:3]) + [0.7 * 255]) # force opacity of 0.7
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para renderizar a camada de polígonos, introduza o seguinte código:
# Render the polygon layer. polygon_layer = pdk.Layer( 'PolygonLayer', id="bike_stations_choropleth", data=gdf_stations_x_neighborhood, get_polygon='polygon', get_fill_color='fill_color', get_line_color=[0, 0, 0, 255], get_line_width=50, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([polygon_layer], view_state)
Clique em Executar célula.
O resultado é semelhante ao seguinte:
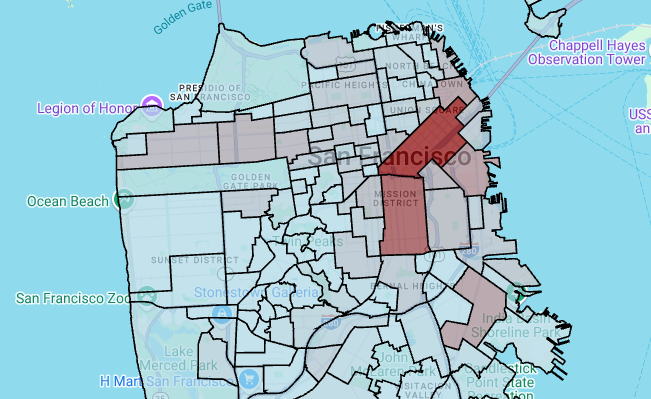
Para inserir uma célula de código, clique em Código.
Para consultar os dados no conjunto de dados San Francisco Police Department (SFPD) Reports, introduza o seguinte código. Este código usa a função mágica
%%bigquerypara executar a consulta e devolver os resultados num DataFrame:# Query the incident key and location data from the SFPD reports dataset. %%bigquery gdf_incidents --project {GCP_PROJECT_ID} --use_geodataframe location_geography SELECT unique_key, location_geography FROM ( SELECT unique_key, SAFE.ST_GEOGFROMTEXT(location) AS location_geography, # WKT string to GEOMETRY EXTRACT(YEAR FROM timestamp) AS year, FROM `bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents` incidents ) WHERE year = 2015
Clique em Executar célula.
O resultado é semelhante ao seguinte:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Para inserir uma célula de código, clique em Código.
Para calcular a célula para a latitude e a longitude de cada incidente, agregue os incidentes para cada célula, crie um
geopandasDataFrame e adicione o centro de cada hexágono para a camada de mapa de calor. Introduza o seguinte código:# Compute the cell for each incident's latitude and longitude. H3_RESOLUTION = 9 gdf_incidents['h3_cell'] = gdf_incidents.geometry.apply( lambda geom: h3.latlng_to_cell(geom.y, geom.x, H3_RESOLUTION) ) # Aggregate the incidents for each hexagon cell. count_incidents = gdf_incidents.groupby(by='h3_cell')['unique_key'].count().rename('num_incidents') # Construct a new geopandas.GeoDataFrame with the aggregate results. # Add the center of each hexagon for the HeatmapLayer to render. gdf_incidents_x_cell = gpd.GeoDataFrame(data=count_incidents).reset_index() gdf_incidents_x_cell['h3_center'] = gdf_incidents_x_cell['h3_cell'].apply(h3.cell_to_latlng) gdf_incidents_x_cell.info()
Clique em Executar célula.
O resultado é semelhante ao seguinte:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 969 entries, 0 to 968 Data columns (total 3 columns): # Column Non-Null Count Dtype -- ------ -------------- ----- 0 h3_cell 969 non-null object 1 num_incidents 969 non-null Int64 2 h3_center 969 non-null object dtypes: Int64(1), object(2) memory usage: 23.8+ KBPara inserir uma célula de código, clique em Código.
Para pré-visualizar as primeiras cinco linhas do DataFrame, introduza o seguinte código:
# Preview the first five rows. gdf_incidents_x_cell.head()
Clique em Executar célula.
O resultado é semelhante ao seguinte:

Para inserir uma célula de código, clique em Código.
Para converter os dados num formato JSON que possa ser usado por
HeatmapLayer, introduza o seguinte código:# Convert to a JSON format recognized by the HeatmapLayer. def _make_heatmap_datum(row) -> dict: return { "latitude": row['h3_center'][0], "longitude": row['h3_center'][1], "weight": float(row['num_incidents']), } heatmap_data = gdf_incidents_x_cell.apply(_make_heatmap_datum, axis='columns').values.tolist()
Clique em Executar célula.
Depois de executar o código, não é gerada nenhuma saída no bloco de notas do Colab. A marca de verificação junto à célula indica que o código foi executado com êxito.
Para inserir uma célula de código, clique em Código.
Para renderizar o mapa de calor, introduza o seguinte código:
# Render the heatmap. heatmap_layer = pdk.Layer( "HeatmapLayer", id="sfpd_heatmap", data=heatmap_data, get_position=['longitude', 'latitude'], get_weight='weight', opacity=0.7, radius_pixels=99, # this limitation can introduce artifacts (see above) aggregation='MEAN', ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([heatmap_layer], view_state)
Clique em Executar célula.
O resultado é semelhante ao seguinte:
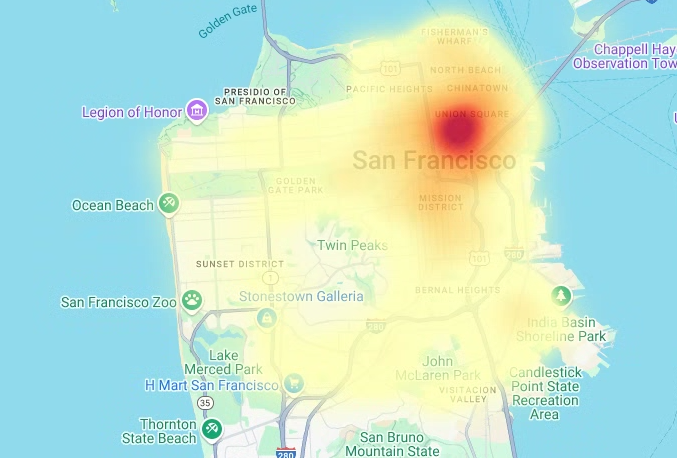
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
No Colab, clique em Segredos.
No final da linha
GMP_API_KEY, clique em Eliminar.Opcional: para eliminar o bloco de notas, clique em Ficheiro > Mover para o lixo.
- Para mais informações sobre estatísticas geoespaciais no BigQuery, consulte o artigo Introdução às estatísticas geoespaciais no BigQuery.
- Para uma introdução à visualização de dados geoespaciais no BigQuery, consulte o artigo Visualize dados geoespaciais.
- Para saber mais sobre o
pydecke outros tipos de gráficosdeck.gl, pode encontrar exemplos napydeckgaleria, nodeck.glcatálogo de camadas e nadeck.glorigem do GitHub. - Para mais informações sobre como trabalhar com dados geoespaciais em frames de dados, consulte a página Introdução ao GeoPandas e o manual do utilizador do GeoPandas.
- Para mais informações sobre a manipulação de objetos geométricos, consulte o manual do utilizador do Shapely.
- Para explorar a utilização de dados do Google Earth Engine no BigQuery, consulte o artigo Exportar para o BigQuery na documentação do Google Earth Engine.
Funções necessárias
Se criar um novo projeto, é o proprietário do projeto e são-lhe concedidas todas as autorizações de IAM necessárias para concluir este tutorial.
Se estiver a usar um projeto existente, precisa da seguinte função ao nível do projeto para executar tarefas de consulta.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Para mais informações sobre as funções no BigQuery, consulte o artigo Funções do IAM predefinidas.
Crie um bloco de notas do Colab
Este tutorial cria um bloco de notas do Colab para visualizar dados de estatísticas geoespaciais. Pode abrir uma versão pré-criada do bloco de notas no Colab, Colab Enterprise ou BigQuery Studio clicando nos links na parte superior da versão do tutorial no GitHub: Visualização geoespacial do BigQuery no Colab.
Faça a autenticação com o Google Cloud e o Google Maps
Este tutorial consulta conjuntos de dados do BigQuery e usa a API Google Maps JavaScript. Para usar estes recursos, autentique o tempo de execução do Colab com Google Cloud e a API Maps.
Autentique com Google Cloud
Opcional: autentique com o Google Maps
Se usar a Google Maps Platform como fornecedor de mapas para mapas base, tem de fornecer uma chave da API Google Maps Platform. O bloco de notas obtém a chave dos seus segredos do Colab.
Este passo só é necessário se estiver a usar a API Maps. Se não se autenticar com a Google Maps Platform, o pydeck usa o mapa carto.
Instale pacotes Python e importe bibliotecas de ciência de dados
Além dos módulos Python colabtools (google.colab), este tutorial usa vários outros pacotes Python e bibliotecas de ciência de dados.
Nesta secção, instala os pacotes pydeck e h3. pydeck
oferece uma renderização espacial de grande escala em Python, com tecnologia deck.gl.
h3-py fornece o sistema de indexação geoespacial hierárquica hexagonal H3 da Uber em Python.
Em seguida, importa as bibliotecas h3 e pydeck e as seguintes bibliotecas geoespaciais do Python:
Depois de importar as bibliotecas, ativa as tabelas interativas para pandas
DataFrames no Colab.
Instale os pacotes pydeck e h3
Importe as bibliotecas Python
Ative tabelas interativas para DataFrames do Pandas
Crie uma rotina partilhada
Nesta secção, cria uma rotina partilhada que renderiza camadas num mapa base.
Crie um gráfico de dispersão
Nesta secção, cria um gráfico de dispersão de todas as estações de partilha de bicicletas no conjunto de dados público do San Francisco Ford GoBike Share, obtendo dados da tabela bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info. O gráfico de dispersão é criado com uma camada e uma camada de gráfico de dispersão da framework deck.gl.
Os gráficos de dispersão são úteis quando precisa de rever um subconjunto de pontos individuais (também conhecido como verificação pontual).
O exemplo seguinte demonstra como usar uma camada e uma camada de gráfico de dispersão para renderizar pontos individuais como círculos.
A renderização dos pontos requer que extraia a longitude e a latitude
como coordenadas x e y da coluna station_geom no conjunto de dados de partilha de bicicletas.
Uma vez que gdf_sf_bikestations é um geopandas.GeoDataFrame, as coordenadas são acedidas diretamente a partir da respetiva coluna de geometria station_geom. Pode obter a longitude através do atributo .x da coluna e a latitude através do atributo .y. Em seguida, pode armazená-los em novas colunas de longitude e latitude.
Visualizar polígonos
As estatísticas geoespaciais permitem-lhe analisar e visualizar dados geoespaciais no BigQuery através de GEOGRAPHYtipos de dados e funções geográficas do GoogleSQL.
O GEOGRAPHYtipo de dados
na análise geoespacial é uma coleção de pontos, strings de linhas e
polígonos, que é representada como um conjunto de pontos ou um subconjunto da superfície da
Terra. Um tipo GEOGRAPHY pode conter objetos como os seguintes:
Para ver uma lista de todos os objetos suportados, consulte a documentação do tipo GEOGRAPHY.
Se lhe forem fornecidos dados geoespaciais sem saber as formas esperadas, pode
visualizar os dados para descobrir as formas. Pode visualizar formas
convertendo os dados geográficos para o formato GeoJSON. Em seguida, pode visualizar os dados GeoJSON através de uma GeoJSON camada da framework deck.gl.
Nesta secção, consulta dados geográficos no conjunto de dados San Francisco Neighborhoods e, em seguida, visualiza os polígonos.
Crie um mapa coroplético
Se estiver a explorar dados com polígonos difíceis de converter para o formato GeoJSON, pode usar uma camada de polígonos da framework deck.gl. Uma camada de polígono pode processar dados de entrada de tipos específicos, como uma matriz de pontos.
Nesta secção, usa uma camada de polígonos para renderizar uma matriz de pontos e usa os resultados para renderizar um mapa coroplético. O mapa coroplético mostra a densidade de estações de partilha de bicicletas por bairro, juntando dados do conjunto de dados de bairros de São Francisco com o conjunto de dados de partilha de bicicletas Ford GoBike de São Francisco.
Crie um mapa de calor
Os mapas coropléticos são úteis quando tem limites significativos conhecidos. Se tiver dados sem limites significativos conhecidos, pode usar uma camada de mapa de calor para renderizar a respetiva densidade contínua.
No exemplo seguinte, consulta dados na tabela bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents no conjunto de dados San Francisco Police Department (SFPD) Reports. Os dados são usados para visualizar a distribuição de incidentes em 2015.
Para mapas de calor, recomenda-se que quantifique e agregue os dados antes da renderização. Neste exemplo, os dados são quantizados e agregados através da indexação espacial H3 da Carto.
O mapa térmico é criado com uma camada do mapa térmico
da estrutura deck.gl.
Neste exemplo, a quantização é feita através da biblioteca h3 Python para agregar os pontos de incidentes em hexágonos. A função h3.latlng_to_cell é usada para mapear a posição do incidente (latitude e longitude) para um índice de célula H3. Uma resolução H3 de nove oferece hexágonos agregados suficientes para o mapa térmico.
A função h3.cell_to_latlng é usada para determinar o centro de cada hexágono.
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Elimine o projeto
Consola
gcloud
Elimine a chave da API Google Maps e o bloco de notas
Depois de eliminar o Google Cloud projeto, se usou a API Google Maps, elimine a chave da API Google Maps dos seus segredos do Colab e, em seguida, elimine opcionalmente o bloco de notas.