
Este tutorial mostra como exportar um modelo de transformador para o formato Open Neural Network Exchange (ONNX), importar o modelo ONNX para um conjunto de dados do BigQuery e, em seguida, usar o modelo para gerar incorporações a partir de uma consulta SQL.
Este tutorial usa o modelo sentence-transformers/all-MiniLM-L6-v2.
Este modelo de transformador de frases é conhecido pelo seu desempenho rápido e eficaz na geração de incorporações de frases. A incorporação de frases permite tarefas como a pesquisa semântica, o agrupamento e a semelhança de frases, captando o significado subjacente do texto.
O ONNX oferece um formato uniforme concebido para representar qualquer framework de aprendizagem automática (AA). O suporte do BigQuery ML para ONNX permite-lhe fazer o seguinte:
- Prepare um modelo com a sua framework favorita.
- Converta o modelo no formato de modelo ONNX.
- Importe o modelo ONNX para o BigQuery e faça previsões com o BigQuery ML.
Objetivos
- Use a
CLI Hugging Face Optimum
para exportar o modelo
sentence-transformers/all-MiniLM-L6-v2para ONNX. - Use a declaração
CREATE MODELpara importar o modelo ONNX para o BigQuery. - Use a
função
ML.PREDICTpara gerar incorporações com o modelo ONNX importado.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização prevista,
use a calculadora de preços.
Quando terminar as tarefas descritas neste documento, pode evitar a faturação contínua eliminando os recursos que criou. Para mais informações, consulte o artigo Limpe.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Certifique-se de que tem as autorizações necessárias para realizar as tarefas descritas neste documento.
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Aceder ao IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos responsáveis, introduza o identificador do utilizador. Normalmente, este é o endereço de email de uma Conta Google.
- Clique em Selecionar uma função e, de seguida, pesquise a função.
- Para conceder funções adicionais, clique em Adicionar outra função e adicione cada função adicional.
- Clique em Guardar.
Instale a CLI Optimum:
pip install optimum[onnx]Exporte o modelo. O argumento
--modelespecifica o ID do modelo do Hugging Face. O argumento--opsetespecifica a versão da biblioteca ONNXRuntime e está definido como17para manter a compatibilidade com a biblioteca ONNXRuntime suportada pelo BigQuery.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/Instale a CLI Optimum:
pip install optimum[onnx]Com o editor de texto à sua escolha, crie um ficheiro denominado
convert-tokenizer.py. O exemplo seguinte usa o editor de texto nano:nano convert-tokenizer.pyCopie e cole o seguinte script Python no ficheiro
convert-tokenizer.py:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())Guarde o ficheiro
convert-tokenizer.py.Execute o script Python para converter o tokenizador:
python convert-tokenizer.py- Crie um contentor do Cloud Storage para armazenar os ficheiros convertidos.
- Carregue o modelo transformador convertido e os ficheiros do tokenizador para o seu contentor do Cloud Storage.
Na Google Cloud consola, aceda à página BigQuery.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
bqml_tutorial.Em Tipo de localização, selecione Várias regiões e, de seguida, selecione EUA (várias regiões nos Estados Unidos).
Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.
Crie um conjunto de dados com o nome
bqml_tutorialcom a localização dos dados definida comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se omitir-de--dataset, o comando cria um conjunto de dados por predefinição.Confirme que o conjunto de dados foi criado:
bq lsNa Google Cloud consola, abra o BigQuery Studio.
No editor de consultas, execute a seguinte declaração
CREATE MODELpara criar o modelotokenizer.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
Substitua
TOKENIZER_BUCKET_PATHpelo caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTOKENIZER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Quando a operação estiver concluída, vê uma mensagem semelhante à seguinte:
Successfully created model named tokenizerno painel Resultados da consulta.Clique em Aceder ao modelo para abrir o painel Detalhes.
Reveja a secção Colunas de funcionalidades para ver as entradas do modelo e a Coluna de etiquetas para ver as saídas do modelo.
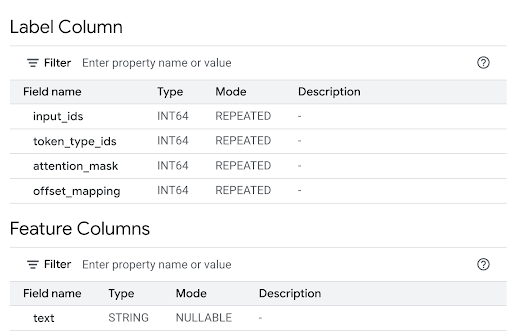
No editor de consultas, execute a declaração
CREATE MODELseguinte para criar o modeloall-MiniLM-L6-v2.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
Substitua
TRANSFORMER_BUCKET_PATHpelo caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTRANSFORMER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Quando a operação estiver concluída, vê uma mensagem semelhante à seguinte:
Successfully created model named all-MiniLM-L6-v2no painel Resultados da consulta.Clique em Aceder ao modelo para abrir o painel Detalhes.
Reveja a secção Colunas de funcionalidades para ver as entradas do modelo e a Coluna de etiquetas para ver as saídas do modelo.
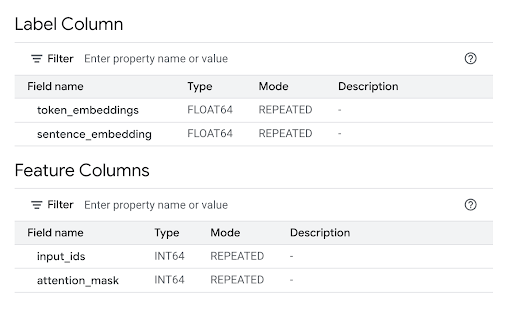
Na linha de comandos, execute o seguinte comando para criar o modelo
tokenizer.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"Substitua
TOKENIZER_BUCKET_PATHpelo caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTOKENIZER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Quando a operação estiver concluída, é apresentada uma mensagem semelhante à seguinte:
Successfully created model named tokenizer.Na linha de comandos, execute o seguinte comando para criar o modelo
all-MiniLM-L6-v2.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"Substitua
TRANSFORMER_BUCKET_PATHpelo caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTRANSFORMER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Quando a operação estiver concluída, é apresentada uma mensagem semelhante à seguinte:
Successfully created model named all-MiniLM-L6-v2.Depois de importar os modelos, verifique se estes aparecem no conjunto de dados.
bq ls -m bqml_tutorial
O resultado é semelhante ao seguinte:
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
Use o seguinte valor do parâmetro
querypara criar o modelotokenizer.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }Substitua o seguinte:
PROJECT_IDcom o ID do seu projeto.TOKENIZER_BUCKET_PATHcom o caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTOKENIZER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.
Use o seguinte valor do parâmetro
querypara criar o modeloall-MiniLM-L6-v2.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }Substitua o seguinte:
PROJECT_IDcom o ID do seu projeto.TRANSFORMER_BUCKET_PATHcom o caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTRANSFORMER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
PROJECT_IDcom o ID do seu projeto.TOKENIZER_BUCKET_PATHcom o caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTOKENIZER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.TRANSFORMER_BUCKET_PATHcom o caminho para o modelo que carregou para o Cloud Storage. Se estiver a usar o modelo de exemplo, substituaTRANSFORMER_BUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.- Tokenização (consulta interna): a chamada
ML.PREDICTinterna usa o modelobqml_tutorial.tokenizer. Usa a colunatitledo conjunto de dados públicobigquery-public-data.imdb.reviewscomo entradatext. O modelotokenizerconverte as strings de texto não processadas nas entradas de tokens numéricas que o modelo principal requer, incluindo as entradasinput_idseattention_mask. - Geração de incorporações (consulta externa): a chamada
ML.PREDICTexterna usa o modelobqml_tutorial.all-MiniLM-L6-v2. A consulta usa as colunasinput_idseattention_maskdo resultado da consulta interna como entrada. Na Google Cloud consola, abra o BigQuery Studio.
No editor de consultas, execute a seguinte consulta.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
O resultado é semelhante ao seguinte:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
- Tokenização (consulta interna): a chamada
ML.PREDICTinterna usa o modelobqml_tutorial.tokenizer. Usa a colunatitledo conjunto de dados públicobigquery-public-data.imdb.reviewscomo entradatext. O modelotokenizerconverte as strings de texto não processadas nas entradas de tokens numéricas que o modelo principal requer, incluindo as entradasinput_idseattention_mask. - Geração de incorporações (consulta externa): a chamada
ML.PREDICTexterna usa o modelobqml_tutorial.all-MiniLM-L6-v2. A consulta usa as colunasinput_idseattention_maskdo resultado da consulta interna como entrada. - In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Saiba como usar incorporações de texto para pesquisa semântica e geração aumentada de recuperação (RAG).
- Para mais informações sobre como converter modelos de transformadores em ONNX, consulte o artigo
Exporte um modelo para ONNX com o
optimum.exporters.onnx. - Para mais informações sobre a importação de modelos ONNX, consulte
A declaração
CREATE MODELpara modelos ONNX. - Para mais informações sobre como fazer previsões, consulte
A função
ML.PREDICT. - Para uma vista geral do BigQuery ML, consulte o artigo Introdução ao BigQuery ML.
- Para começar a usar o BigQuery ML, consulte o artigo Crie modelos de aprendizagem automática no BigQuery ML.
Funções necessárias
Se criar um novo projeto, é o proprietário do projeto e são-lhe concedidas todas as autorizações de gestão de identidade e de acesso (IAM) necessárias para concluir este tutorial.
Se estiver a usar um projeto existente, faça o seguinte.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Para mais informações sobre as autorizações de IAM no BigQuery, consulte Autorizações de IAM.
Converta os ficheiros do modelo Transformer para ONNX
Opcionalmente, pode seguir os passos nesta secção para converter manualmente o modelo e o tokenizador para ONNX.sentence-transformers/all-MiniLM-L6-v2
Caso contrário, pode usar ficheiros de exemplo do contentor do gs://cloud-samples-dataCloud Storage público que já foram convertidos.
Se optar por converter manualmente os ficheiros, tem de ter um ambiente de linha de comandos local com o Python instalado. Para mais informações sobre a instalação do Python, consulte Transferências do Python.
Exporte o modelo de transformador para ONNX
Use a CLI Hugging Face Optimum para exportar o modelo sentence-transformers/all-MiniLM-L6-v2para ONNX.
Para mais informações sobre a exportação de modelos com a CLI Optimum, consulte o artigo
Exporte um modelo para ONNX com optimum.exporters.onnx.
Para exportar o modelo, abra um ambiente de linha de comandos e siga estes passos:
O ficheiro do modelo é exportado para o diretório all-MiniLM-L6-v2 como model.onnx.
Aplique a quantização ao modelo Transformer
Use a CLI Optimum para aplicar a quantização ao modelo de transformador exportado de forma a reduzir o tamanho do modelo e acelerar a inferência. Para mais informações, consulte Quantização.
Para aplicar a quantização ao modelo, execute o seguinte comando na linha de comandos:
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
O ficheiro do modelo quantizado é exportado para o diretório all-MiniLM-L6-v2_quantized
como model_quantized.onnx.
Converta o tokenizador para ONNX
Normalmente, para gerar incorporações através de um modelo Transformer no formato ONNX, usa um tokenizador para produzir duas entradas para o modelo: input_ids e attention_mask.
Para produzir estas entradas, converta o tokenizador para o formato ONNX através da biblioteca onnxruntime-extensions.sentence-transformers/all-MiniLM-L6-v2 Depois de converter o tokenizador, pode realizar a tokenização diretamente nas entradas de texto não processado para gerar previsões ONNX.
Para converter o tokenizador, siga estes passos na linha de comandos:
O tokenizador convertido é exportado para o diretório all-MiniLM-L6-v2_quantized
como tokenizer.onnx.
Carregue os ficheiros do modelo convertidos para o Cloud Storage
Depois de converter o modelo Transformer e o tokenizador, faça o seguinte:
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo de ML.
Consola
bq
Para criar um novo conjunto de dados, use o comando
bq mk
com a flag --location. Para uma lista completa de parâmetros possíveis, consulte a referência do comando
bq mk --dataset.
API
Chame o método datasets.insert
com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Importe os modelos ONNX para o BigQuery
Importe os modelos de transformador de frases e tokenizador convertidos como modelos do BigQuery ML.
Selecione uma das seguintes opções:
Consola
bq
Use a ferramenta de linhas de comando bq
comando query
para executar a declaração CREATE MODEL.
API
Use o método jobs.insert para importar os modelos.Preencha o parâmetro query do recurso QueryRequest no corpo do pedido com a declaração CREATE MODEL.
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Importe os modelos de transformadores de frases e tokenizadores através do objeto ONNXModel.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
Substitua o seguinte:
Gere incorporações com os modelos ONNX importados
Use o tokenizador importado e os modelos de transformadores de frases para gerar incorporações com base em dados do conjunto de dados público bigquery-public-data.imdb.reviews.
Selecione uma das seguintes opções:
Consola
Use a
função ML.PREDICT
para gerar incorporações com os modelos.
A consulta usa uma chamada ML.PREDICT aninhada para processar texto não processado diretamente através do tokenizador e do modelo de incorporação, da seguinte forma:
A declaração SELECT obtém a coluna sentence_embedding, que é uma matriz de valores FLOAT que representam a incorporação semântica do texto.
bq
Use a ferramenta de linhas de comando bq
comando query
para executar uma consulta. A consulta usa a função ML.PREDICT para gerar incorporações com os modelos.
A consulta usa uma chamada ML.PREDICT aninhada para processar texto não processado diretamente através do tokenizador e do modelo de incorporação, da seguinte forma:
A declaração SELECT obtém a coluna sentence_embedding, que é uma matriz de valores FLOAT que representam a incorporação semântica do texto.
Na linha de comandos, execute o seguinte comando para executar a consulta.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
O resultado é semelhante ao seguinte:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Use o método predict
para gerar incorporações com os modelos ONNX.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
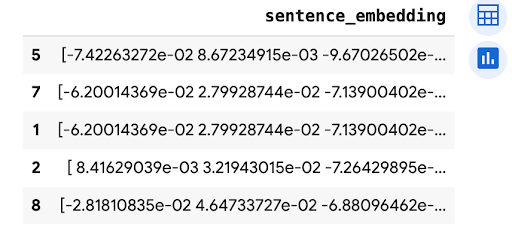
predictions.peek(5)
O resultado é semelhante ao seguinte:
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
Elimine o projeto
Consola
gcloud
Elimine recursos individuais
Em alternativa, para remover os recursos individuais usados neste tutorial, faça o seguinte: