
In dieser Anleitung erfahren Sie, wie Sie ein Transformer-Modell in das Open Neural Network Exchange (ONNX)-Format exportieren, das ONNX-Modell in ein BigQuery-Dataset importieren und dann das Modell verwenden, um Einbettungen aus einer SQL-Abfrage zu generieren.
In dieser Anleitung wird das sentence-transformers/all-MiniLM-L6-v2-Modell verwendet.
Dieses Sentence-Transformer-Modell ist für seine schnelle und effektive Leistung bei der Generierung von Satz-Embeddings bekannt. Mit Satz-Einbettungen können Aufgaben wie die semantische Suche, das Clustering und die Satzähnlichkeit ausgeführt werden, da die zugrunde liegende Bedeutung des Texts erfasst wird.
ONNX bietet ein einheitliches Format für die Darstellung von Frameworks für maschinelles Lernen (ML). Die BigQuery ML-Unterstützung für ONNX bietet folgende Möglichkeiten:
- Trainieren eines Modells mit Ihrem bevorzugten Framework.
- Konvertieren des Modells in das ONNX-Modellformat.
- ONNX-Modell in BigQuery importieren und Vorhersagen mit BigQuery ML treffen.
Ziele
- Verwenden Sie die Hugging Face Optimum-CLI, um das
sentence-transformers/all-MiniLM-L6-v2-Modell in ONNX zu exportieren. - Verwenden Sie die
CREATE MODEL-Anweisung, um das ONNX-Modell in BigQuery zu importieren. - Verwenden Sie die Funktion
ML.PREDICT, um Einbettungen mit dem importierten ONNX-Modell zu generieren.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Prüfen Sie, ob für Ihr Google Cloud Projekt die Abrechnung aktiviert ist.
Aktivieren Sie die BigQuery API und die Cloud Storage API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Weitere Informationen zum Zuweisen von Rollen- Prüfen Sie, ob Sie die erforderlichen Berechtigungen haben, um die Aufgaben in diesem Dokument ausführen zu können.
Erforderliche Rollen
Wenn Sie ein neues Projekt erstellen, sind Sie der Projektinhaber und erhalten alle erforderlichen IAM-Berechtigungen (Identity and Access Management), die Sie für diese Anleitung benötigen.
Wenn Sie ein vorhandenes Projekt verwenden, gehen Sie so vor.
Prüfen Sie, ob Sie die folgenden Rollen für das Projekt haben:
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage-Objekt-Ersteller (
roles/storage.objectCreator)
Rollen prüfen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
-
Suchen Sie in der Spalte Hauptkonto nach allen Zeilen, in denen Sie oder eine Gruppe, zu der Sie gehören, angegeben sind. Fragen Sie Ihren Administrator, zu welchen Gruppen Sie gehören.
- Prüfen Sie in allen Zeilen, in denen Sie angegeben oder enthalten sind, die Spalte Rolle, um zu sehen, ob die Liste der Rollen die erforderlichen Rollen enthält.
Rollen zuweisen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Klicken Sie auf Rolle auswählen und suchen Sie nach der Rolle.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
Weitere Informationen zu IAM-Berechtigungen in BigQuery finden Sie unter IAM-Berechtigungen.
Transformer-Modelldateien in ONNX konvertieren
Optional können Sie die Schritte in diesem Abschnitt ausführen, um das sentence-transformers/all-MiniLM-L6-v2-Modell und den Tokenizer manuell in ONNX zu konvertieren.
Andernfalls können Sie Beispieldateien aus dem öffentlichen Cloud Storage-Bucket gs://cloud-samples-data verwenden, die bereits konvertiert wurden.
Wenn Sie die Dateien manuell konvertieren möchten, benötigen Sie eine lokale Befehlszeilenumgebung, auf der Python installiert ist. Weitere Informationen zur Installation von Python finden Sie unter Python-Downloads.
Transformer-Modell in ONNX exportieren
Verwenden Sie die Hugging Face Optimum-Befehlszeile, um das sentence-transformers/all-MiniLM-L6-v2-Modell in ONNX zu exportieren.
Weitere Informationen zum Exportieren von Modellen mit der Optimum-CLI finden Sie unter Modell mit optimum.exporters.onnx in ONNX exportieren.
So exportieren Sie das Modell:
Installieren Sie die Optimum-Befehlszeile:
pip install optimum[onnx]Modell exportieren. Das Argument
--modelgibt die Hugging Face-Modell-ID an. Das Argument--opsetgibt die ONNXRuntime-Bibliotheksversion an und ist auf17festgelegt, um die Kompatibilität mit der von BigQuery unterstützten ONNXRuntime-Bibliothek aufrechtzuerhalten.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
Die Modelldatei wird als model.onnx in das Verzeichnis all-MiniLM-L6-v2 exportiert.
Quantisierung auf das Transformer-Modell anwenden
Verwenden Sie die Optimum-CLI, um das exportierte Transformer-Modell zu quantisieren. So können Sie die Modellgröße reduzieren und die Inferenz beschleunigen. Weitere Informationen finden Sie unter Quantisierung.
Führen Sie den folgenden Befehl in der Befehlszeile aus, um das Modell zu quantisieren:
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
Die quantisierte Modelldatei wird als model_quantized.onnx in das Verzeichnis all-MiniLM-L6-v2_quantized exportiert.
Tokenizer in ONNX konvertieren
Wenn Sie Einbettungen mit einem Transformer-Modell im ONNX-Format generieren möchten, verwenden Sie in der Regel einen Tokenizer, um zwei Eingaben für das Modell zu erstellen: input_ids und attention_mask.
Um diese Eingaben zu erstellen, konvertieren Sie den Tokenizer für das sentence-transformers/all-MiniLM-L6-v2-Modell mit der onnxruntime-extensions-Bibliothek in das ONNX-Format. Nachdem Sie den Tokenizer konvertiert haben, können Sie die Tokenisierung direkt für Rohtexteingaben ausführen, um ONNX-Vorhersagen zu generieren.
So konvertieren Sie den Tokenizer über die Befehlszeile:
Installieren Sie die Optimum-Befehlszeile:
pip install optimum[onnx]Erstellen Sie mit einem Texteditor Ihrer Wahl eine Datei mit dem Namen
convert-tokenizer.py. Im folgenden Beispiel wird der Texteditor „nano“ verwendet:nano convert-tokenizer.pyKopieren Sie das folgende Python-Skript in die Datei
convert-tokenizer.py:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())Speichern Sie die Datei
convert-tokenizer.py.Führen Sie das Python-Skript aus, um den Tokenizer zu konvertieren:
python convert-tokenizer.py
Der konvertierte Tokenizer wird als tokenizer.onnx in das Verzeichnis all-MiniLM-L6-v2_quantized exportiert.
Konvertierte Modelldateien in Cloud Storage hochladen
Nachdem Sie das Transformer-Modell und den Tokenizer konvertiert haben, gehen Sie so vor:
- Erstellen Sie einen Cloud Storage-Bucket zum Speichern der konvertierten Dateien.
- Konvertiertes Transformer-Modell und Tokenizer-Dateien in Ihren Cloud Storage-Bucket hochladen
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Multiregional und dann USA aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk --dataset.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorialund legen Sie den Datenspeicherort aufUSfest.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
ONNX-Modelle in BigQuery importieren
Importieren Sie den konvertierten Tokenizer und die Sentence Transformer-Modelle als BigQuery ML-Modelle.
Wählen Sie eine der folgenden Optionen aus:
Console
Öffnen Sie in der Google Cloud Console BigQuery Studio.
Führen Sie im Abfrageeditor die folgende
CREATE MODEL-Anweisung aus, um dastokenizer-Modell zu erstellen.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
Ersetzen Sie
TOKENIZER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTOKENIZER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Wenn der Vorgang abgeschlossen ist, wird im Bereich Abfrageergebnisse eine Meldung wie die folgende angezeigt:
Successfully created model named tokenizer.Klicken Sie auf Zum Modell, um den Bereich Details zu öffnen.
Im Abschnitt Feature Columns (Featurespalten) sehen Sie die Modelleingaben und in der Label Column (Labelspalte) die Modellausgaben.
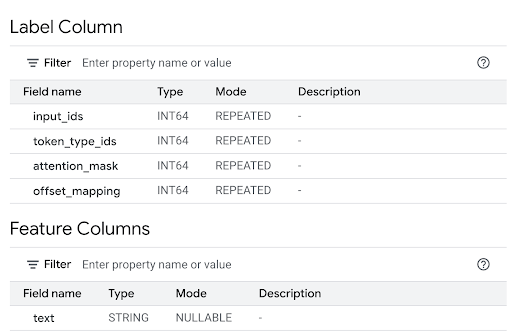
Führen Sie im Abfrageeditor die folgende
CREATE MODEL-Anweisung aus, um dasall-MiniLM-L6-v2-Modell zu erstellen.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
Ersetzen Sie
TRANSFORMER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTRANSFORMER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Wenn der Vorgang abgeschlossen ist, wird im Bereich Abfrageergebnisse eine Meldung wie die folgende angezeigt:
Successfully created model named all-MiniLM-L6-v2.Klicken Sie auf Zum Modell, um den Bereich Details zu öffnen.
Im Abschnitt Feature Columns (Featurespalten) sehen Sie die Modelleingaben und in der Label Column (Labelspalte) die Modellausgaben.
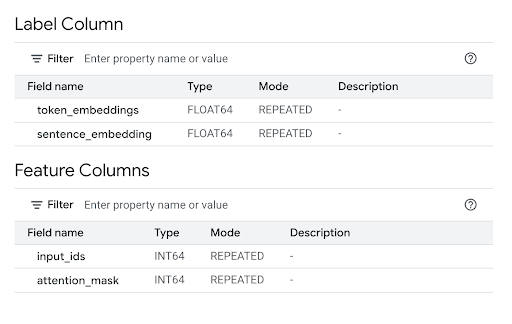
bq
Verwenden Sie den Befehl query des bq-Befehlszeilentools, um die CREATE MODEL-Anweisung auszuführen.
Führen Sie in der Befehlszeile den folgenden Befehl aus, um das Modell
tokenizerzu erstellen.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"Ersetzen Sie
TOKENIZER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTOKENIZER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Nach Abschluss des Vorgangs erhalten Sie in etwa folgende Meldung:
Successfully created model named tokenizer.Führen Sie in der Befehlszeile den folgenden Befehl aus, um das Modell
all-MiniLM-L6-v2zu erstellen.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"Ersetzen Sie
TRANSFORMER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTRANSFORMER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Nach Abschluss des Vorgangs erhalten Sie in etwa folgende Meldung:
Successfully created model named all-MiniLM-L6-v2.Prüfen Sie nach dem Import der Modelle, ob sie im Dataset angezeigt werden.
bq ls -m bqml_tutorial
Die Ausgabe sieht etwa so aus:
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
Verwenden Sie die jobs.insert-Methode, um die Modelle zu importieren. Füllen Sie den Parameter query der QueryRequest-Ressource im Anfragetext mit der CREATE MODEL-Anweisung aus.
Verwenden Sie den folgenden
query-Parameterwert, um dastokenizer-Modell zu erstellen.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }Ersetzen Sie Folgendes:
PROJECT_IDdurch Ihre Projekt-ID,TOKENIZER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTOKENIZER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.
Verwenden Sie den folgenden
query-Parameterwert, um dasall-MiniLM-L6-v2-Modell zu erstellen.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }Ersetzen Sie Folgendes:
PROJECT_IDdurch Ihre Projekt-ID,- Ersetzen Sie
TRANSFORMER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTRANSFORMER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Importieren Sie die Tokenizer- und Sentence Transformer-Modelle mit dem Objekt ONNXModel.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
Ersetzen Sie Folgendes:
PROJECT_IDdurch Ihre Projekt-ID,TOKENIZER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTOKENIZER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.- Ersetzen Sie
TRANSFORMER_BUCKET_PATHdurch den Pfad zum Modell, das Sie in Cloud Storage hochgeladen haben. Wenn Sie das Beispielmodell verwenden, ersetzen SieTRANSFORMER_BUCKET_PATHdurch den folgenden Wert:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
Einbettungen mit den importierten ONNX-Modellen generieren
Verwenden Sie den importierten Tokenizer und die Sentence-Transformer-Modelle, um Einbettungen basierend auf Daten aus dem öffentlichen Dataset bigquery-public-data.imdb.reviews zu generieren.
Wählen Sie eine der folgenden Optionen aus:
Console
Verwenden Sie die Funktion ML.PREDICT, um mit den Modellen Einbettungen zu generieren.
In der Abfrage wird ein verschachtelter ML.PREDICT-Aufruf verwendet, um Rohtext direkt über den Tokenizer und das Einbettungsmodell zu verarbeiten:
- Tokenisierung (innere Abfrage): Beim inneren
ML.PREDICT-Aufruf wird dasbqml_tutorial.tokenizer-Modell verwendet. Alstext-Eingabe wird die Spaltetitleaus dem öffentlichen Datasetbigquery-public-data.imdb.reviewsverwendet. Dastokenizer-Modell wandelt die Roh-Textstrings in die numerischen Token-Eingaben um, die das Hauptmodell benötigt, einschließlich derinput_ids- undattention_mask-Eingaben. - Generierung von Einbettungen (äußere Abfrage): Beim äußeren
ML.PREDICT-Aufruf wird dasbqml_tutorial.all-MiniLM-L6-v2-Modell verwendet. Die Abfrage verwendet die Spalteninput_idsundattention_maskaus der Ausgabe der inneren Abfrage als Eingabe.
Mit der SELECT-Anweisung wird die Spalte sentence_embedding abgerufen. Das ist ein Array von FLOAT-Werten, die das semantische Embedding des Texts darstellen.
Öffnen Sie in der Google Cloud Console BigQuery Studio.
Führen Sie im Abfrageeditor die folgende Abfrage aus.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
Das Ergebnis sieht etwa so aus:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
Verwenden Sie den query-Befehl des bq-Befehlszeilentools, um eine Abfrage auszuführen. In der Abfrage wird die Funktion ML.PREDICT verwendet, um Einbettungen mit den Modellen zu generieren.
In der Abfrage wird ein verschachtelter ML.PREDICT-Aufruf verwendet, um Rohtext direkt über den Tokenizer und das Einbettungsmodell zu verarbeiten:
- Tokenisierung (innere Abfrage): Beim inneren
ML.PREDICT-Aufruf wird dasbqml_tutorial.tokenizer-Modell verwendet. Alstext-Eingabe wird die Spaltetitleaus dem öffentlichen Datasetbigquery-public-data.imdb.reviewsverwendet. Dastokenizer-Modell wandelt die Roh-Textstrings in die numerischen Token-Eingaben um, die das Hauptmodell benötigt, einschließlich derinput_ids- undattention_mask-Eingaben. - Generierung von Einbettungen (äußere Abfrage): Beim äußeren
ML.PREDICT-Aufruf wird dasbqml_tutorial.all-MiniLM-L6-v2-Modell verwendet. Die Abfrage verwendet die Spalteninput_idsundattention_maskaus der Ausgabe der inneren Abfrage als Eingabe.
Mit der SELECT-Anweisung wird die Spalte sentence_embedding abgerufen. Das ist ein Array von FLOAT-Werten, die das semantische Embedding des Texts darstellen.
Führen Sie in der Befehlszeile den folgenden Befehl aus, um die Abfrage auszuführen.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
Das Ergebnis sieht etwa so aus:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Verwenden Sie die predict-Methode, um Einbettungen mit den ONNX-Modellen zu generieren.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
predictions.peek(5)
Die Ausgabe sieht etwa so aus:

Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
Console
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
gcloud
Google Cloud -Projekt löschen:
gcloud projects delete PROJECT_ID
Einzelne Ressourcen löschen
Alternativ können Sie die einzelnen Ressourcen, die in dieser Anleitung verwendet werden, so entfernen:
Optional: Dataset löschen
Nächste Schritte
- Informationen zum Verwenden von Texteinbettungen für die semantische Suche und Retrieval Augmented Generation (RAG)
- Weitere Informationen zum Konvertieren von Transformer-Modellen in ONNX finden Sie unter Modell mit
optimum.exporters.onnxin ONNX exportieren. - Weitere Informationen zum Importieren von ONNX-Modellen finden Sie unter
CREATE MODEL-Anweisung für ONNX-Modelle. - Weitere Informationen zum Ausführen von Vorhersagen finden Sie unter Die Funktion
ML.PREDICT. - Einführung in BigQuery ML
- Informationen zur Verwendung von BigQuery ML finden Sie unter Modelle für maschinelles Lernen in BigQuery ML erstellen.