
コネクテッド シートの使用
コネクテッド シートは、BigQuery の大規模なデータを使い慣れた Google スプレッドシートのインターフェースで利用できるようにする機能です。コネクテッド シートを使用すると、BigQuery データをプレビューし、データセット全体から作成されたピボット テーブル、数式、グラフでデータを使用できます。
さらに、次のことも可能です。
使い慣れたスプレッドシートのインターフェースを使用して、パートナーやアナリストなどの関係者と共同編集する。
追加のスプレッドシートをエクスポートしなくても、信頼できる単一のデータ分析ソースを利用する。
レポートとダッシュボードのワークフローを効率化する。
コネクテッド シートは、リクエストまたは定義済みのスケジュールに従って、BigQuery クエリをユーザーに代わって実行します。クエリの結果はスプレッドシートに保存され、分析と共有に利用できます。
サンプル ユースケース
コネクテッド シートを使用すると、SQL の知識がなくてもシート内の大量のデータを分析できます。以下に、いくつかのユースケースを示します。
ビジネス プランニング: データセットを構築して準備し、他のユーザーがデータから分析情報を得られるようにします。たとえば、販売データを分析して、さまざまな地域での売れ筋商品を特定します。
カスタマー サービス: お客様 10,000 人あたりで苦情が最も多い店舗を特定します。
販売: 社内の財務レポートや販売レポートを作成し、営業担当者と収益レポートを共有します。
アクセス制御
BigQuery のデータセットとテーブルへの直接アクセスは、BigQuery 内で制御されます。ユーザーに Google スプレッドシートへのアクセスのみを許可する場合は、スプレッドシートを共有して、BigQuery へのアクセス権は付与しないでください。
Google スプレッドシートのみのアクセスを持つユーザーは、スプレッドシートでの分析や、他のスプレッドシート機能の使用はできますが、次のアクションは実行できません。
- スプレッドシート内の BigQuery データを手動で更新する。
- スプレッドシートのデータの更新をスケジュール設定する。
コネクテッド シートでデータをフィルタリングすると、選択したプロジェクトに対して BigQuery に送信するクエリが更新されます。実行されたクエリは、関連プロジェクトで次のログフィルタを使用して表示できます。
resource.type="bigquery_resource" protoPayload.metadata.firstPartyAppMetadata.sheetsMetadata.docId != NULL_VALUE
VPC Service Controls
VPC Service Controls を使用して、Google Cloud リソースへのアクセスを制限できます。VPC Service Controls ではスプレッドシートに対応していないため、VPC Service Controls が保護している BigQuery データにアクセスできない可能性があります。必要な権限があり、VPC Service Controls のアクセス制限を満たしている場合は、VPC Service Controls の境界を構成して、コネクテッド シートからのクエリを許可できます。これを行うには、以下を使用して境界を構成する必要があります。
- 境界外からの信頼できる IP アドレス、ID、信頼できるクライアント デバイスからのリクエストを許可するアクセスレベルまたは上り(内向き)ルール。
- クエリ結果をユーザーのスプレッドシートにコピーできるようにする下り(外向き)ルール。
上り(内向き)ポリシーと下り(外向き)ポリシーを構成する方法と、アクセスレベルを構成してルールを適切に構成する方法を学習します。必要なデータのコピーを許可するように境界を構成するには、次の YAML ファイルを使用します。
# Allows egress to Sheets through the Connected Sheets feature
- egressTo:
operations:
- serviceName: 'bigquery.googleapis.com'
methodSelectors:
- permission: 'bigquery.vpcsc.importData'
resources:
- projects/628550087766 # Sheets-owned Google Cloud project
egressFrom:
identityType: ANY_USER_ACCOUNT
始める前に
まず、Google Workspace のトピックの Google スプレッドシートで BigQuery データを使ってみるの「要件」セクションの説明に従って、スプレッドシートで BigQuery データにアクセスするための要件を満たしていることを確認します。
課金用に設定された Google Cloud プロジェクトがない場合は、次の手順を行います。
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、移動します。
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Google スプレッドシートのスプレッドシートを 1 つ作成または開きます。
[データ] をクリックし、[データコネクタ] をクリックしてから、[BigQuery に接続する] をクリックします。
課金が有効になっている Google Cloud プロジェクトを選択します。
[一般公開データセット] をクリックします。
検索ボックスに「chicago」と入力し、[chicago_taxi_trips] データセットを選択します。
[taxi_trips] テーブルを選択し、[接続] をクリックします。
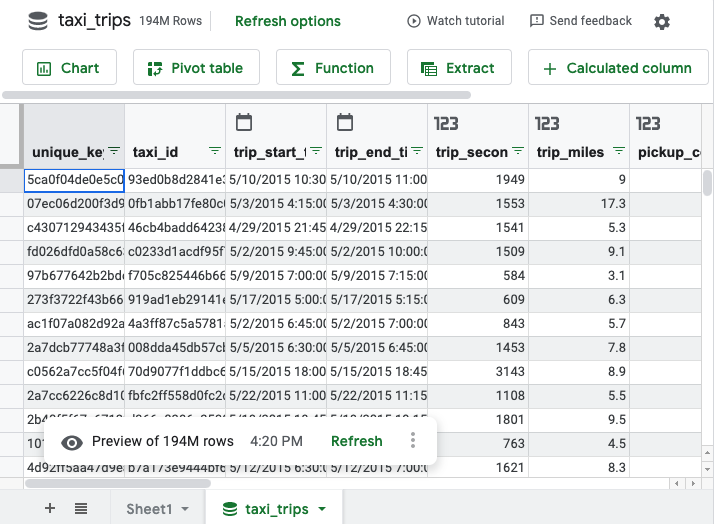
次のようなスプレッドシートが表示されます。
- 行数が 50,000 行以下の場合、セル数に制限はありません。
- 行数が 50,000 行より多く 500,000 行以下の場合、セル数は 500 万以下にする必要があります。
- 行数が 500,000 を超える場合、データは取得できません。
- 作成したセルまたはグラフを選択します。
- [更新] にポインタを合わせます。
- 省略可: コネクテッド シートのクエリ結果を更新するには、 [更新] をクリックします。
BigQuery でクエリを表示するには、[BigQuery のクエリの詳細] をクリックします。
Google Cloud コンソールでクエリが開きます。
Google Cloud コンソールで、[BigQuery] ページに移動します。
左側のペインで、 エクスプローラをクリックします。

左側のペインが表示されていない場合は、 [左ペインを開く] をクリックしてペインを開きます。
[エクスプローラ] ペインで、プロジェクトを開き、[データセット] をクリックして、Google スプレッドシートで開くテーブルを含むデータセットをクリックします。
[概要] > [テーブル] をクリックし、テーブル名の横にある [アクションを表示] をクリックして、[次で開く] > [コネクテッド シート] を選択します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
左側のペインで、 エクスプローラをクリックします。
[エクスプローラ] ペインで、プロジェクトを開き、[クエリ] をクリックします。コネクテッド シートで開く保存済みクエリを見つけます。
保存済みクエリの横にある [アクションを開く] をクリックし、[次で開く] > [コネクテッド シート] をクリックします。
または、保存済みクエリの名前をクリックして [詳細] ペインで開き、[次で開く] > [コネクテッド シート] をクリックします。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Google Workspace の Google スプレッドシートで BigQuery データを使ってみるで詳細をご覧ください。
YouTube のコネクテッド シート プレイリストを使用するの動画をご覧ください。
課金の継続を停止するには、作成したリソースを削除します。詳細については、クリーンアップをご覧ください。
コネクテッド シートから BigQuery データセットを開く
次の例では、一般公開データセットを使用して、Google スプレッドシートから BigQuery に接続する方法を説明しています。
スプレッドシートの使用を開始します。使い慣れた Google スプレッドシートの操作方法で、ピボット テーブル、数式、グラフ、計算された列、スケジュールされたクエリを作成できます。詳細については、コネクテッド シートのチュートリアルをご覧ください。
スプレッドシートでは 500 行しかプレビュー表示されませんが、ピボット テーブル、数式、グラフではデータセット全体が使用されます。ピボット テーブルに対して返される結果の最大行数は 200,000 行です。
データを Google スプレッドシートに抽出することもできます。データ抽出に対して返される結果の最大行数と最大セル数は、次の条件によって異なります。
コネクテッド シートを使用してデータからグラフ、ピボット テーブル、数式、その他の計算セルを作成する場合、コネクテッド シートはユーザーに代わって BigQuery でクエリを実行します。このクエリを表示するには、次の操作を行います。
コネクテッド シートでテーブルを開く
コネクテッド シートでテーブルを開く手順は次のとおりです。
コネクテッド シートで保存済みクエリを開く
保存済みクエリがあることを確認します。詳細については、保存済みクエリを作成するをご覧ください。
コネクテッド シートで保存済みクエリを開く手順は次のとおりです。
コネクテッド シートから BigQuery の使用状況をモニタリングする
BigQuery 管理者は、コネクテッド シートからリソースの使用状況のモニタリングと監査を行うことで、使用パターンを把握したり、費用を管理したり、頻繁に使用されるレポートを特定したりできます。次のセクションでは、組織レベルとプロジェクト レベルの両方で、使用状況をモニタリングするのに役立つ SQL クエリの例を示します。詳細については、JOBS ビューをご覧ください。
コネクテッド シートから発生したすべてのクエリには、一意のジョブ ID 接頭辞 sheets_dataconnector が割り当てられます。この接頭辞を使用して、INFORMATION_SCHEMA.JOBS ビューでジョブをフィルタできます。
ユーザーごとのコネクテッド シートの使用状況を組織レベルで集計する
次のクエリは、過去 30 日間に組織内で最も多くコネクテッド シートを使用したユーザーの概要を、課金対象データの合計でランク付けして返します。このクエリでは、各ユーザーのクエリの合計数、課金対象の合計バイト数、スロットの合計ミリ秒数が集計されます。これらの情報は、導入状況を把握し、リソースの主な消費者を特定するのに役立ちます。
SELECT
user_email,
COUNT(*) AS total_queries,
SUM(total_bytes_billed) AS total_bytes_billed,
SUM(total_slot_ms) AS total_slot_ms
FROM
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION`
WHERE
-- Filter for jobs created in the last 30 days
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
-- Filter for jobs originating from Connected Sheets
AND job_id LIKE 'sheets_dataconnector%'
-- Filter for completed jobs
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
GROUP BY
1
ORDER BY
total_bytes_billed DESC;
REGION_NAME は、プロジェクトのリージョンに置き換えます。例: region-us
結果は次のようになります。
+---------------------+---------------+--------------------+-----------------+ | user_email | total_queries | total_bytes_billed | total_slot_ms | +---------------------+---------------+--------------------+-----------------+ | alice@example.com | 152 | 12000000000 | 3500000 | | bob@example.com | 45 | 8500000000 | 2100000 | | charles@example.com | 210 | 1100000000 | 1800000 | +---------------------+---------------+--------------------+-----------------+
組織レベルのコネクテッド シートのクエリのジョブログを確認する
次のクエリは、コネクテッド シートで実行された個々のクエリの詳細なログを提供します。これらの情報は、監査やコストの高いクエリの特定に役立ちます。
SELECT
job_id,
creation_time,
user_email,
project_id,
total_bytes_billed,
total_slot_ms,
query
FROM
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION`
WHERE
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND job_id LIKE 'sheets_dataconnector%'
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
ORDER BY
creation_time DESC;
REGION_NAME は、プロジェクトのリージョンに置き換えます。例: region-us
結果は次のようになります。
+---------------------------------+---------------------------------+-----------------+------------+--------------------+---------------+--------------------------------+ | job_id | creation_time | user_email | project_id | total_bytes_billed | total_slot_ms | query | +---------------------------------+---------------------------------+-----------------+------------+--------------------+---------------+--------------------------------+ | sheets_dataconnector_bquxjob_1 | 2025-11-06 00:26:53.077000 UTC | abc@example.com | my_project | 12000000000 | 3500000 | SELECT ... FROM dataset.table1 | | sheets_dataconnector_bquxjob_2 | 2025-11-06 00:24:04.294000 UTC | xyz@example.com | my_project | 8500000000 | 2100000 | SELECT ... FROM dataset.table2 | | sheets_dataconnector_bquxjob_3 | 2025-11-03 23:17:25.975000 UTC | bob@example.com | my_project | 1100000000 | 1800000 | SELECT ... FROM dataset.table3 | +---------------------------------+---------------------------------+-----------------+------------+--------------------+---------------+--------------------------------+
ユーザーごとのコネクテッド シートの使用状況をプロジェクト レベルで集計する
組織レベルの権限がない場合や、特定のプロジェクトのみをモニタリングする必要がある場合は、次のクエリを実行して、過去 30 日間にプロジェクト内で最も多くコネクテッド シートを使用したユーザーを特定します。このクエリでは、各ユーザーのクエリの合計数、課金対象の合計バイト数、スロットの合計ミリ秒数が集計されます。これらの情報は、導入状況を把握し、リソースの主な消費者を特定するのに役立ちます。
SELECT
user_email,
COUNT(*) AS total_queries,
SUM(total_bytes_billed) AS total_bytes_billed,
SUM(total_slot_ms) AS total_slot_ms
FROM
-- This view queries the project you are currently running the query in.
`region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
-- Filter for jobs created in the last 30 days
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
-- Filter for jobs originating from Connected Sheets
AND job_id LIKE 'sheets_dataconnector%'
-- Filter for completed jobs
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
GROUP BY
user_email
ORDER BY
total_bytes_billed DESC
LIMIT
10;
REGION_NAME は、プロジェクトのリージョンに置き換えます。例: region-us
結果は次のようになります。
+---------------------+---------------+--------------------+-----------------+ | user_email | total_queries | total_bytes_billed | total_slot_ms | +---------------------+---------------+--------------------+-----------------+ | alice@example.com | 152 | 12000000000 | 3500000 | | bob@example.com | 45 | 8500000000 | 2100000 | | charles@example.com | 210 | 1100000000 | 1800000 | +---------------------+---------------+--------------------+-----------------+
プロジェクト レベルのコネクテッド シートのクエリのジョブログを確認する
組織レベルの権限がない場合や、特定のプロジェクトのみをモニタリングする必要がある場合は、次のクエリを実行して、現在のプロジェクトのすべてのコネクテッド シートのクエリの詳細なログを表示します。
SELECT
job_id,
creation_time,
user_email,
total_bytes_billed,
total_slot_ms,
query
FROM
-- This view queries the project you are currently running the query in.
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND job_id LIKE 'sheets_dataconnector%'
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
ORDER BY
creation_time DESC;
REGION_NAME は、プロジェクトのリージョンに置き換えます。例: region-us
結果は次のようになります。
+---------------------------------+---------------------------------+------------------+--------------------+-----------------+---------------------------------+ | job_id | creation_time | user_email | total_bytes_billed | total_slot_ms | query | +---------------------------------+---------------------------------+------------------+--------------------+-----------------+---------------------------------+ | sheets_dataconnector_bquxjob_1 | 2025-11-06 00:26:53.077000 UTC | abc@example.com | 12000000000 | 3500000 | SELECT ... FROM dataset.table1 | | sheets_dataconnector_bquxjob_2 | 2025-11-06 00:24:04.294000 UTC | xyz@example.com | 8500000000 | 2100000 | SELECT ... FROM dataset.table2 | | sheets_dataconnector_bquxjob_3 | 2025-11-03 23:17:25.975000 UTC | bob@example.com | 1100000000 | 1800000 | SELECT ... FROM dataset.table3 | +---------------------------------+---------------------------------+------------------+--------------------+-----------------+---------------------------------+
クリーンアップ
このチュートリアルで使用したリソースについて Google Cloud アカウントに課金されないようにするには: