
このチュートリアルでは、1 つのクエリで複数の時系列予測を行うために、一連の ARIMA_PLUS 単変量時系列モデルのトレーニングを大幅に高速化する方法について説明します。また、予測精度を評価する方法についても確認します。
このチュートリアルでは、複数の時系列の予測を行います。予測値は、指定された 1 つ以上の列の値ごとに、各時点について計算されます。たとえば、天気を予測するため、都市データを含む列を指定した場合、予測データには、都市 A のすべての時点における予測値、都市 B のすべての時点における予測値などが含まれます。
このチュートリアルでは、公開されている bigquery-public-data.new_york.citibike_trips テーブルと iowa_liquor_sales.sales テーブルのデータを使用します。シティバイクの利用データには数百の時系列しか含まれていないため、モデルのトレーニングを高速化するさまざまな方法の説明に使用します。酒類販売データには 100 万を超える時系列があるため、大規模な時系列予測を示すために使用されます。
このチュートリアルを読む前に、単変量モデルを使用して複数の時系列を予測すると大規模な時系列予測のベスト プラクティスをご覧ください。
目標
このチュートリアルでは、以下を使用します。
CREATE MODELステートメントを使用して時系列モデルを作成します。ML.EVALUATE関数を使用してモデルの精度を評価します。CREATE MODELステートメントのAUTO_ARIMA_MAX_ORDER、TIME_SERIES_LENGTH_FRACTION、MIN_TIME_SERIES_LENGTH、MAX_TIME_SERIES_LENGTHオプションを使用して、モデルのトレーニング時間を大幅に短縮します。
話を簡単にするため、このチュートリアルでは ML.FORECAST 関数または ML.EXPLAIN_FORECAST 関数を使用して予測を生成する方法には触れません。これらの関数の使用方法については、単変量モデルを使用して複数の時系列を予測するをご覧ください。
費用
このチュートリアルでは、以下を含む、 Google Cloudの課金対象となるコンポーネントを使用します。
- BigQuery
- BigQuery ML
費用の詳細については、BigQuery の料金と BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. データセットを作成するには、
bigquery.datasets.createIAM 権限が必要です。モデルを作成するには、次の権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
推論を実行するには、次の権限が必要です。
bigquery.models.getDatabigquery.jobs.create
必要な権限
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
入力データのテーブルを作成する
次のクエリの SELECT ステートメントは、EXTRACT 関数を使用して、starttime 列から日付情報を抽出します。さらに、COUNT(*) 句を使用して、1 日あたりのシティバイクの合計利用回数を取得します。
table_1 には 679 の時系列があります。このクエリでは、追加の INNER JOIN ロジックを使用して、400 を超える時点を持つすべての時系列を選択し、時系列の合計は 383 になります。
入力データテーブルを作成するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
デフォルトのパラメータを使用して複数の時系列を予測するモデルを作成する
シティバイク ステーションごとのシティバイクの利用回数を予測するには、入力データに含まれるシティバイク ステーションごとに 1 つずつ、多くの時系列モデルが必要です。複数の CREATE MODEL クエリを作成してこれを行うことができますが、特に多数の時系列が存在する場合に、作成に手間や時間がかかる可能性があります。代わりに、1 つのクエリを使用し、一連の時系列モデルを作成して適合させると、複数の時系列を一度に予測できます。
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 句は、ARIMA ベースの一連の ARIMA_PLUS 時系列モデルを作成していることを示しています。time_series_timestamp_col オプションは時系列を含む列を指定します。time_series_data_col オプションは予測する列を指定します。time_series_id_col は、時系列を作成する対象のディメンションを 1 つ以上指定します。
この例では、2016 年 6 月 1 日以降の時系列の時点が除外されていますが、後でこれらの時点を使用して ML.EVALUATE 関数で予測精度を評価できます。
次の手順でモデルを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
クエリの完了には、約 15 分かかります。
各時系列の予測精度を評価する
ML.EVALUATE 関数を使用して、モデルの予測精度を評価します。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
このクエリは、次のような予測指標を報告します。
結果は次のようになります。
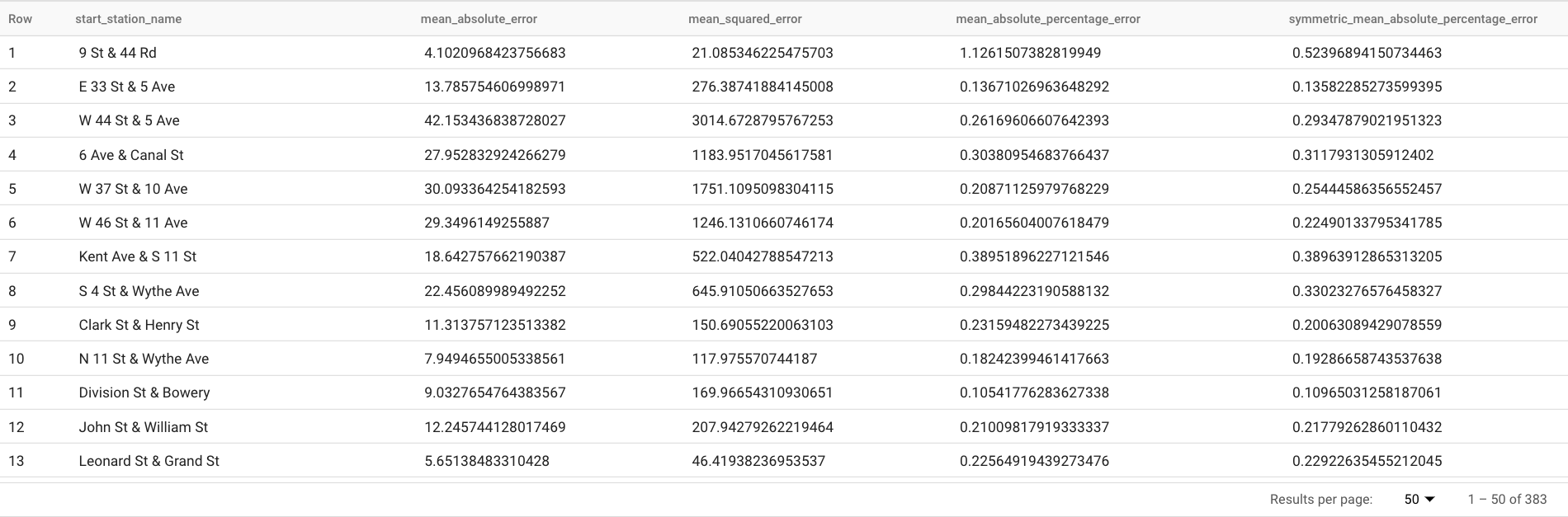
ML.EVALUATE関数のTABLE句は、グラウンド トゥルース データを含むテーブルを示します。予測結果をグラウンド トゥルース データと比較して、精度指標を計算します。この場合、nyc_citibike_time_seriesには 2016 年 6 月 1 日以前と以降の両方の時系列の時点が含まれます。2016 年 6 月 1 日以降の時点はグラウンド トゥルース データです。2016 年 6 月 1 日以前の時点は、その日付以降の予測を生成するためのモデルのトレーニングに使用されます。指標の計算に必要なのは、2016 年 6 月 1 日以降の時点のみです。2016 年 6 月 1 日以前の時点は、指標の計算では無視されます。ML.EVALUATE関数のSTRUCT句は、この関数のパラメータを指定しています。horizonの値は7で、このクエリが 7 点予測に基づいて予測精度を計算することを意味します。グラウンド トゥルース データで比較できる時点が 7 つ未満の場合、精度指標は使用可能な時点のみに基づいて計算されます。perform_aggregationの値はTRUEで、予測精度指標がその時点の指標に基づいて集計されることを意味します。perform_aggregationの値をFALSEに指定すると、予測された時点ごとに予測精度が返されます。出力列の詳細については、
ML.EVALUATE関数をご覧ください。
予測の総合的な精度を評価する
383 個の時系列すべての予測精度を評価します。
ML.EVALUATE によって返される予測指標のうち、平均絶対誤差率と対称平均絶対誤差率のみが時系列値に依存しません。したがって、一連の時系列の予測精度全体を評価するには、これら 2 つの指標の集計のみが有意となります。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
このクエリでは、MAPE の値は 0.3471、sMAPE の値は 0.2563 が返されます。
小さいハイパーパラメータ検索空間で複数の時系列を予測するモデルを作成する
デフォルトのパラメータを使用して複数の時系列のモデルを作成するセクションでは、auto_arima_max_order オプションを含むすべてのトレーニング オプションにデフォルト値を使用しました。このオプションは、auto.ARIMA アルゴリズムのハイパーパラメータ チューニングの検索空間を制御します。
次のクエリで作成されたモデルでは、auto_arima_max_order オプションの値をデフォルトの 5 から 2 に変更することで、ハイパーパラメータの検索空間を小さくしています。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
クエリの完了には、約 2 分かかります。以前のモデルでは、
auto_arima_max_orderの値が5のとき、完了までに約 15 分かかりました。すなわち、この変更によってモデルのトレーニング速度は約 7 倍向上します。速度の向上が5/2=2.5xでないのは、auto_arima_max_orderの値を大きくすると、候補モデルの数が増えるだけでなく、複雑さも増すためです。これにより、モデルのトレーニング時間が長くなります。
小さいハイパーパラメータ検索空間を使用するモデルの予測精度を評価する
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
このクエリでは、MAPE の値は 0.3337、sMAPE の値は 0.2337 が返されます。
予測の総合的な精度を評価するセクションでは、auto_arima_max_order オプションの値が 5 という大きなハイパーパラメータ検索空間を持つモデルを評価しました。これにより、MAPE の値は 0.3471、sMAPE の値は 0.2563 になりました。この場合、ハイパーパラメータ検索空間が小さいほど、実際には予測精度が高くなります。その理由の一つは、auto.ARIMA アルゴリズムが、モデリング パイプライン全体のトレンド モジュールに対してのみハイパーパラメータ チューニングを実行するためです。auto.ARIMA アルゴリズムによって選択された最良の ARIMA モデルが、パイプライン全体について最良の予測結果を生成するとは限りません。
小さいハイパーパラメータ検索空間とスマートな高速トレーニング戦略を使用して、複数の時系列を予測するモデルを作成する
このステップでは、小さいハイパーパラメータ検索空間と、1 つ以上の max_time_series_length、max_time_series_length、または time_series_length_fraction トレーニング オプションを使用したスマートな高速トレーニング戦略の両方を使用します。
季節性などの定期的なモデリングには一定数の時点が必要ですが、トレンド モデリングの場合、必要な時点は少なくなります。一方、トレンド モデリングは、季節性などの他の時系列コンポーネントよりも計算コストがはるかに高くなります。上記の高速トレーニング オプションを使用すると、他の時系列コンポーネントでは時系列全体を使用しながら、時系列のサブセットを使用してトレンド コンポーネントを効率的にモデル化できます。
次の例では、max_time_series_length オプションを使用して高速トレーニングを実現します。max_time_series_length オプションの値を 30 に設定すると、直近 30 の時点のみがトレンド コンポーネントのモデル化に使用されます。トレンド以外のコンポーネントのモデル化には、引き続き 383 個すべての時系列が使用されます。
次の手順でモデルを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
このクエリが完了するまでに 35 秒ほどかかります。これは、小さいハイパーパラメータ検索空間で複数の時系列を予測するモデルを作成するで使用したクエリと比較して 3 倍高速になっています。データの前処理など、クエリのトレーニング以外のオーバーヘッドは一定時間なので、この例よりも時系列の数がはるかに多い場合、速度ゲインは大幅に向上します。100 万の時系列の場合、速度ゲインは時系列の長さと
max_time_series_lengthオプションの値との比率に近づきます。この場合、速度ゲインは 10 倍以上になります。
小さいハイパーパラメータ検索空間とスマートな高速トレーニング戦略を使用して、モデルの予測精度を評価する
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
このクエリでは、MAPE の値は 0.3515、sMAPE の値は 0.2473 が返されます。
高速トレーニング戦略を使用しない場合、予測精度は MAPE の値が 0.3337、sMAPE の値が 0.2337 になります。2 つの指標値の差は 3% 以内で、統計的に有意ではありません。
つまり、小さいハイパーパラメータ検索空間とスマートな高速トレーニング戦略を使用することで、予測精度を犠牲にすることなく、モデルのトレーニングを 20 倍以上高速化しました。前述のように、時系列が多いほど、スマートな高速トレーニング戦略による速度ゲインは大幅に向上する可能性があります。さらに、ARIMA_PLUS モデルの基盤となる ARIMA ライブラリは、以前よりも 5 倍高速で実行されるよう最適化されています。これにより、数百万の時系列を数時間で予測できるようになります。
100 万の時系列を予測するモデルを作成する
このステップでは、公開されているアイオワ州の酒類販売データを使用して、さまざまな店舗での 100 万を超える酒類製品の酒類販売を予測します。ここでも、モデルのトレーニングでは小さいハイパーパラメータ検索空間と、スマートな高速トレーニング戦略を使用します。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
このクエリが完了するまでに 1 時間 16 分ほどかかります。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
[データセットの削除] をクリックして、データセット、テーブル、すべてのデータを削除します。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力し、[削除] をクリックして確定します。
プロジェクトの削除
プロジェクトを削除するには、次の操作を行います。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- 単変量モデルを使用して単一の時系列を予測する方法を学習する。
- 多変量モデルを使用して単一の時系列を予測する方法を学習する
- 単変量モデルを使用して複数の時系列を予測する方法を学習する
- 単変量モデルを使用して複数の時系列を階層的に予測する方法を学習する
- BigQuery ML の概要について、BigQuery の AI と ML の概要で確認する。