
本教程介绍了如何使用多变量时序模型根据多个输入特征的历史值来预测给定列的未来值。
本教程将预测单个时序。系统会针对输入数据中的每个时间点计算一次预测值。
本教程使用来自 bigquery-public-data.epa_historical_air_quality 公共数据集的数据。此数据集包含从美国多个城市收集的每日颗粒物 (PM2.5)、温度和风速信息。
目标
本教程将指导您完成以下任务:
- 使用
CREATE MODEL语句创建时序模型以预测 PM2.5 值。 - 使用
ML.ARIMA_EVALUATE函数评估模型中的自动回归集成移动平均线 (ARIMA) 信息。 - 使用
ML.ARIMA_COEFFICIENTS函数检查模型系数。 - 使用
ML.FORECAST函数从模型中检索预测的 PM2.5 值。 - 使用
ML.EVALUATE函数评估模型的准确率。 - 使用
ML.EXPLAIN_FORECAST函数检索时序的组成部分,例如季节性、趋势和特征归因。您可以检查这些时序组成部分,以解释预测值。
费用
本教程使用 Google Cloud的可计费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需详细了解 BigQuery 费用,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 新项目会自动启用 BigQuery。如需在预先存在的项目中激活 BigQuery,请前往
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 如需创建数据集,您需要拥有
bigquery.datasets.createIAM 权限。如需创建模型,您需要以下权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
如需运行推理,您需要以下权限:
bigquery.models.getDatabigquery.jobs.create
所需权限
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅 IAM 简介。
创建数据集
创建 BigQuery 数据集以存储机器学习模型。
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集
在 创建数据集 页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
保持其余默认设置不变,然后点击创建数据集。
bq
如需创建新数据集,请使用带有 --location 标志的 bq mk 命令。 如需查看完整的潜在参数列表,请参阅 bq mk --dataset 命令参考文档。
创建一个名为
bqml_tutorial的数据集,并将数据位置设置为US,说明为BigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
该命令使用的不是
--dataset标志,而是-d快捷方式。如果省略-d和--dataset,该命令会默认创建一个数据集。确认已创建数据集:
bq ls
API
使用已定义的数据集资源调用 datasets.insert 方法。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
创建输入数据表
创建一个数据表,您可以使用该数据表来训练和评估模型。此表合并了 bigquery-public-data.epa_historical_air_quality 数据集中多个表的列,以提供每日天气数据。您还可以创建以下列,以将其用作模型的输入变量:
date:观察的日期pm25:每天的平均 PM2.5 值wind_speed:每天的平均风速temperature:每天的最高温度
在以下 GoogleSQL 查询中,FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary 子句指示您正在查询 epa_historical_air_quality 数据集中的 *_daily_summary 表。这些表是分区表。
请按照以下步骤创建输入数据表:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date);
直观呈现输入数据
在创建模型之前,您可以选择直观呈现输入时序数据,以了解分布情况。您可以使用 Looker Studio 执行此操作。
请按照以下步骤直观呈现时序数据:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;
查询完成后,依次点击打开方式 > Looker Studio。Looker Studio 将在新标签页中打开。在该新标签页中完成以下步骤。
在 Looker Studio 中,依次点击插入 > 时序图表。
在图表窗格中,选择设置标签页。
在指标部分中,添加 pm25、temperature 和 wind_speed 字段,并移除默认的记录数指标。生成的图表如下所示:
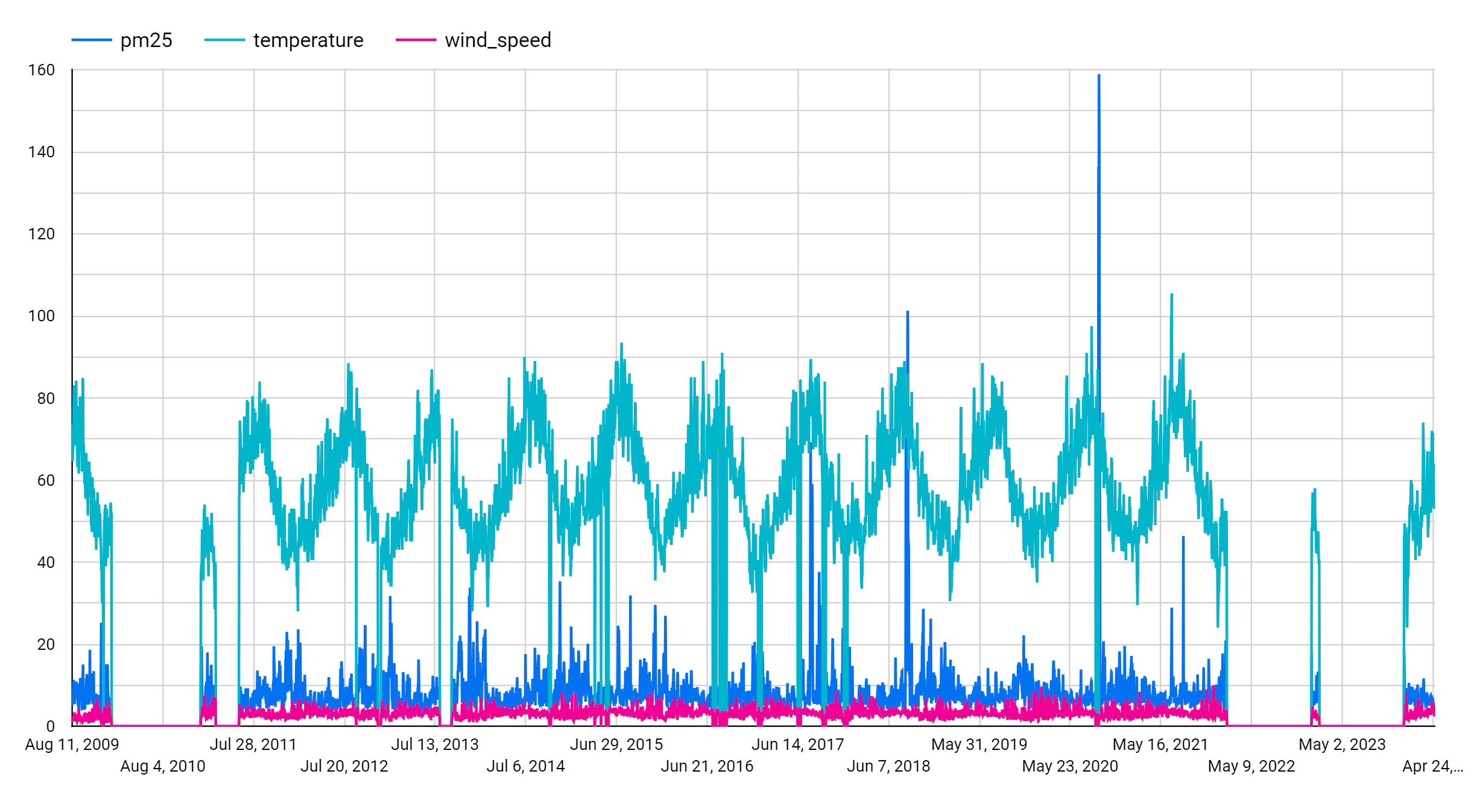
从图表中,您可以看到输入时序具有每周的季节性模式。
创建时序模型
使用 pm25、wind_speed 和 temperature 列值作为输入变量,创建一个时序模型来预测以 pm25 列表示的颗粒物值。使用 bqml_tutorial.seattle_air_quality_daily 表中的空气质量数据训练模型,选择 2012 年 1 月 1 日至 2020 年 12 月 31 日之间收集的数据。
在以下查询中,OPTIONS(model_type='ARIMA_PLUS_XREG',
time_series_timestamp_col='date', ...) 子句表示您正在使用外部回归器模型创建 ARIMA。CREATE MODEL 语句的 auto_arima 选项默认为 TRUE,因此 auto.ARIMA 算法会自动调整模型中的超参数。该算法会拟合数十个候选模型,并选择具有最低 Akaike 信息准则 (AIC) 的最佳模型。
CREATE MODEL 语句的 data_frequency 选项默认为 AUTO_FREQUENCY,因此训练过程会自动推断输入时序的数据频率。
请按照以下步骤创建模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', # Identifies the column that contains time points time_series_data_col = 'pm25') # Identifies the column to forecast AS SELECT date, # The column that contains time points pm25, # The column to forecast temperature, # Temperature input to use in forecasting wind_speed # Wind speed input to use in forecasting FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31');
查询大约需要 20 秒才能完成,之后您便可访问
seattle_pm25_xreg_model模型。由于查询使用CREATE MODEL语句来创建模型,因此您看不到查询结果。
评估候选模型
使用 ML.ARIMA_EVALUATE 函数评估时序模型。ML.ARIMA_EVALUATE 函数会显示自动超参数调整过程中评估的所有候选模型的评估指标。
请按照以下步骤评估模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
结果应如下所示:

non_seasonal_p、non_seasonal_d、non_seasonal_q和has_drift输出列定义了训练流水线中的 ARIMA 模型。log_likelihood、AIC和variance输出列与 ARIMA 模型拟合过程相关。auto.ARIMA算法使用 KPSS 测试来确定non_seasonal_d的最佳值,在本例中为1。当non_seasonal_d为1时,auto.ARIMA算法会并行训练 42 个不同的候选 ARIMA 模型。在此示例中,所有 42 个候选模型均有效,因此输出包含 42 行,每行对应一个候选 ARIMA 模型;如果某些模型无效,则会从输出中排除。这些候选模型将按照 AIC 升序返回。第一行中的模型具有最低的 AIC,它被视为最佳模型。最佳模型将保存为最终模型,并在您对模型调用ML.FORECAST等函数时使用。seasonal_periods列包含有关时序数据中识别出的季节性模式的信息。它与 ARIMA 建模无关,因此在所有输出行中都具有相同的值。它会报告每周模式,该模式与您选择直观呈现输入数据时看到的结果一致。has_holiday_effect、has_spikes_and_dips和has_step_changes列提供有关输入时序数据的信息,与 ARIMA 建模无关。之所以返回这些列,是因为CREATE MODEL语句中decompose_time_series选项的值为TRUE。这些列在所有输出行中也具有相同的值。error_message列显示auto.ARIMA拟合过程中发生的任何错误。错误的一个可能原因是所选non_seasonal_p、non_seasonal_d、non_seasonal_q和has_drift列无法稳定时序。如需检索所有候选模型的错误消息,请在创建模型时将show_all_candidate_models选项设置为TRUE。如需详细了解输出列,请参阅
ML.ARIMA_EVALUATE函数。
检查模型的系数
使用 ML.ARIMA_COEFFICIENTS 函数检查时序模型的系数。
请按照以下步骤检索模型的系数:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
结果应如下所示:
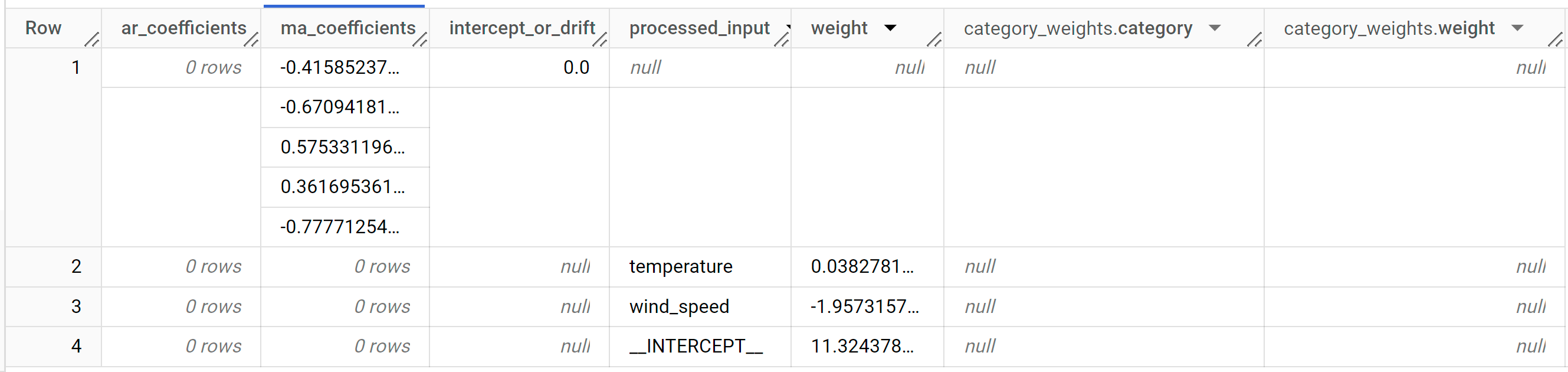
ar_coefficients输出列显示了 ARIMA 模型的自动回归 (AR) 部分的模型系数。同样,ma_coefficients输出列显示了 ARIMA 模型的移动平均值 (MA) 部分的模型系数。这两个列都包含数组值,其长度分别等于non_seasonal_p和non_seasonal_q。在ML.ARIMA_EVALUATE函数的输出中,您看到最佳模型的non_seasonal_p值为0,non_seasonal_q值为5。因此,在ML.ARIMA_COEFFICIENTS输出中,ar_coefficients值是一个空数组,而ma_coefficients值是一个 5 个元素的数组。intercept_or_drift值是 ARIMA 模型中的常量项。processed_input、weight和category_weights输出列显示线性回归模型中每个特征的权重和截距。如果特征是数值特征,则权重位于weight列中。如果特征是分类特征,则category_weights值是一个结构体值数组,其中每个结构体值都包含给定类别的名称和权重。如需详细了解输出列,请参阅
ML.ARIMA_COEFFICIENTS函数。
使用模型预测数据
使用 ML.FORECAST 函数预测未来的时序值。
在以下 GoogleSQL 查询中,STRUCT(30 AS horizon, 0.8 AS confidence_level) 子句指示查询会预测 30 个未来的时间点,并生成置信度为 80% 的预测区间。
请按照以下步骤使用模型预测数据:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
结果应如下所示:
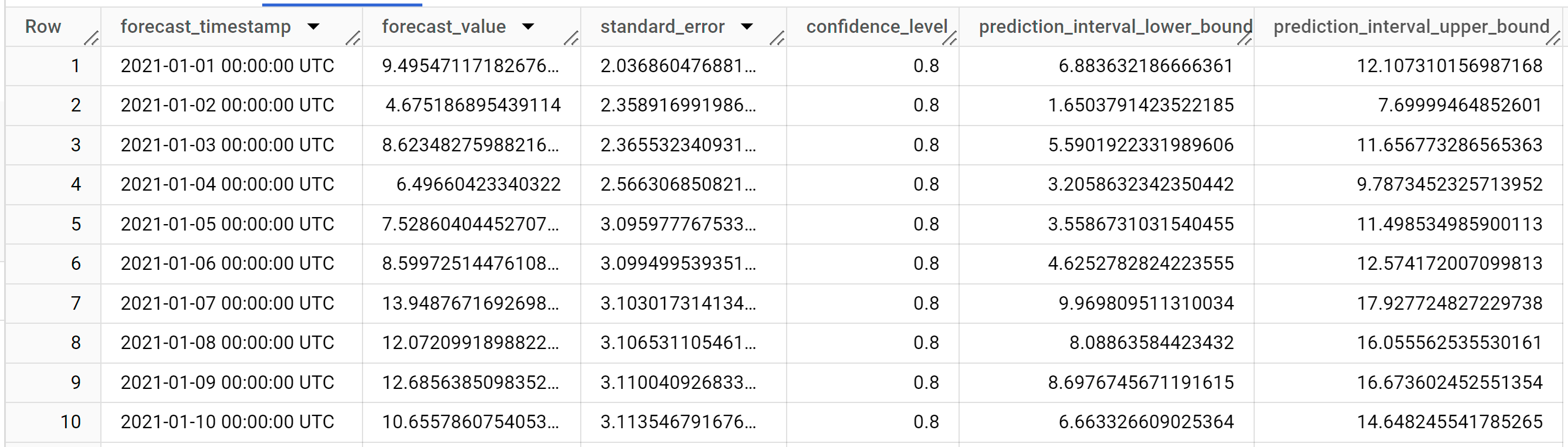
输出行按
forecast_timestamp列值的时间顺序排序。在时序预测中,由prediction_interval_lower_bound和prediction_interval_upper_bound列值表示的预测区间与forecast_value列值一样重要。forecast_value值是预测区间的中点。预测区间取决于standard_error和confidence_level列值。如需详细了解输出列,请参阅
ML.FORECAST函数。
评估预测准确率
使用 ML.EVALUATE 函数评估模型的预测准确率。
在以下 GoogleSQL 查询中,第二个 SELECT 语句提供具有未来特征的数据,这些内容用于预测未来值以与实际数据进行比较。
请按照以下步骤评估模型的准确率:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon));
结果应如下所示:

如需详细了解输出列,请参阅
ML.EVALUATE函数。
解释预测结果
除了预测数据,您还可以使用 ML.EXPLAIN_FORECAST 函数获取可解释性指标。ML.EXPLAIN_FORECAST 函数会预测未来的时序值,还会返回该时序的所有单独的组件。
与 ML.FORECAST 函数类似,ML.EXPLAIN_FORECAST 函数中使用的 STRUCT(30 AS horizon, 0.8 AS confidence_level) 子句指示查询会预测 30 个未来的时间点,并生成置信度为 80% 的预测区间。
请按照以下步骤解释模型的结果:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
结果应如下所示:

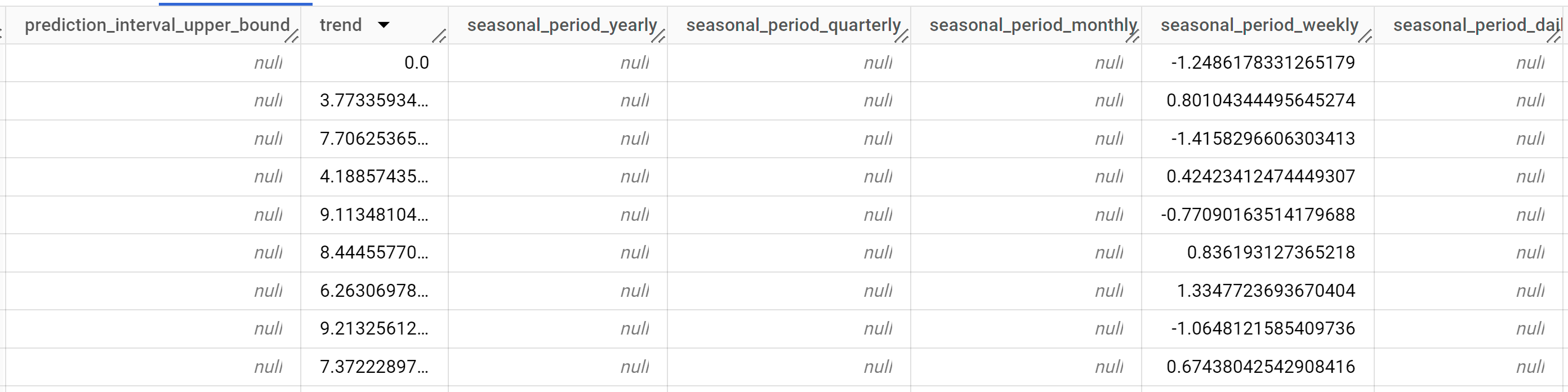
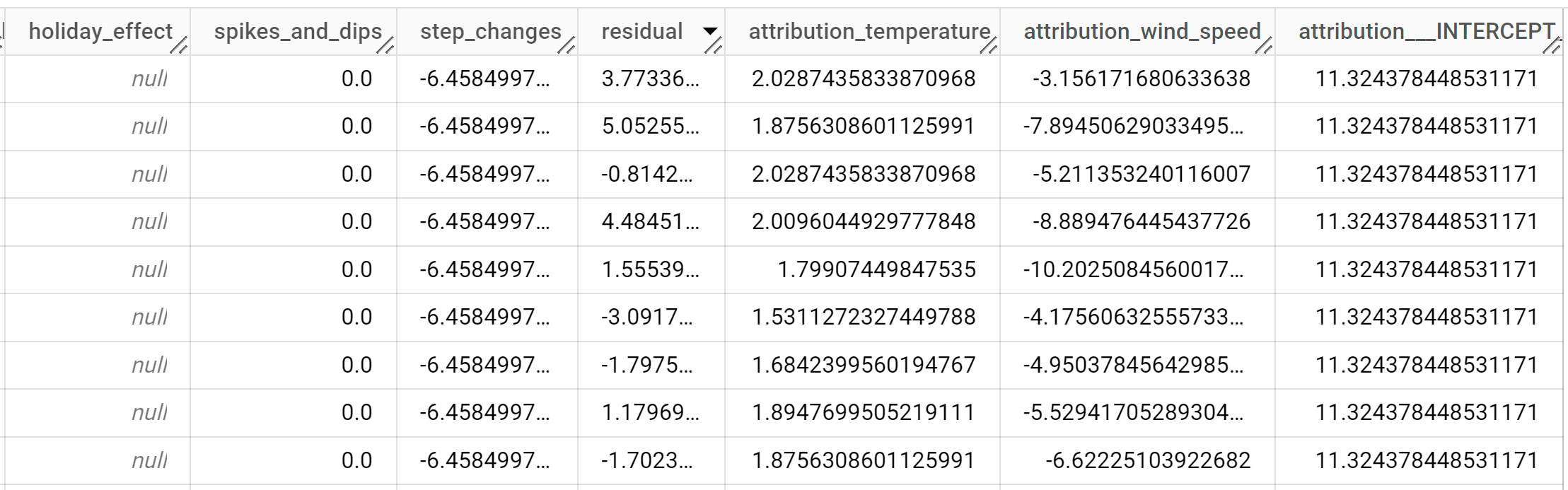
输出行按
time_series_timestamp列值的时间顺序排序。如需详细了解输出列,请参阅
ML.EXPLAIN_FORECAST函数。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除相关数据集、表和所有数据。
在删除数据集对话框中,通过输入数据集的名称 (
bqml_tutorial) 来确认该删除命令,然后点击删除。
删除项目
如需删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 了解如何使用单变量模型预测单个时序
- 了解如何使用单变量模型预测多个时序
- 了解如何在预测多行中的多个时序时扩展单变量模型。
- 了解如何使用单变量模型分层预测多个时序
- 如需大致了解 BigQuery ML,请参阅 BigQuery 中的 AI 和机器学习简介。